【数据结构与算法】字符串匹配(Rabin-Karp 算法和KMP 算法)
Rabin-Karp 算法
概念
用于在 一个字符串 中查找 另外一个字符串 出现的位置。
与暴力法不同,基本原理就是比较字符串的 哈希码 ( HashCode ) , 快速的确定子字符串是否等于被查找的字符串
比较哈希值采用的是滚动哈希法
- 如何计算哈希值:
如 : “abcde” 的哈希码值为
\]
滚动哈希法:
母串是"abcde",子串是"cde"
则母串先计算"abc"的哈希值:\[a×31^2+b×31^1+c×31^0
\]而子串"cde"的哈希值是:
\[c×31^2+d×31^1+e×31^0
\]与母串哈希值不匹配,于是母串向后继续计算哈希值,下标i=3指向字母d,
\[(a×31^2+b×31^1+c×31^0)×31+d-a×31^3
\]前n个字符的hash * 31-前n字符的第一字符 * 31的n次方(n是子串长度)
可以计算出母串中"bcd"的哈希值,再与子串哈希值进行比较
代码实现
public static void main(String[] args) {
String s = "ABABABA";
String p = "ABA";
match(p, s);
}
//p是母串,s是子串
private static void match(String p, String s) {
long hash_p = hash(p);//p的hash值
long[] hashOfS = hash(s, p.length());
match(hash_p, hashOfS);
}
private static void match(long hash_p, long[] hash_s) {
for (int i = 0; i < hash_s.length; i++) {
if (hash_s[i] == hash_p) {
System.out.println(i);
}
}
}
final static long seed = 31;
/**
* n是子串的长度
* 用滚动方法求出s中长度为n的每个子串的hash,组成一个hash数组
*/
static long[] hash(final String s, final int n) {
long[] res = new long[s.length() - n + 1];
//前m个字符的hash
res[0] = hash(s.substring(0, n));
for (int i = n; i < s.length(); i++) {
char newChar = s.charAt(i);
char ochar = s.charAt(i - n);
//前n个字符的hash*seed-前n字符的第一字符*seed的n次方
long v = (res[i - n] * seed + newChar - pow(seed, n) * ochar) % Long.MAX_VALUE; //防止溢出
res[i - n + 1] = v;
}
return res;
}
static long pow(long a,int b){
long ans = 1;
while(b>0){
ans*=a;
b--;
}
return ans;
}
/**
* 使用100000个不同字符串产生的冲突数,大概在0~3波动,使用100百万不同的字符串,冲突数大概110+范围波动。
* 如果数据量非常大,可以在子串和母串哈希值匹配成功的时候多进行一步朴素的字符串比较,以防万一。
*/
static long hash(String str) {
long h = 0;
for (int i = 0; i != str.length(); ++i) {
h = seed * h + str.charAt(i);
}
return h % Long.MAX_VALUE;
}
时间复杂度分析
设母串长度为m,子串长度为n。
则滚动计算母串哈希值复杂度是O(m)
计算子串哈希值复杂度是O(n)
遍历母串进行哈希值匹配的复杂度是O(m)
综上,Rabin-Karp算法的时间复杂度是O(m+n)
KMP 算法
概念
KMP算法是一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt同时发现,因此人们称它为克努特——莫里斯——普拉特操作(简称KMP算法)。
主要用于在文本串S中查找模式串P出现的位置。
- KMP和暴力匹配的不同
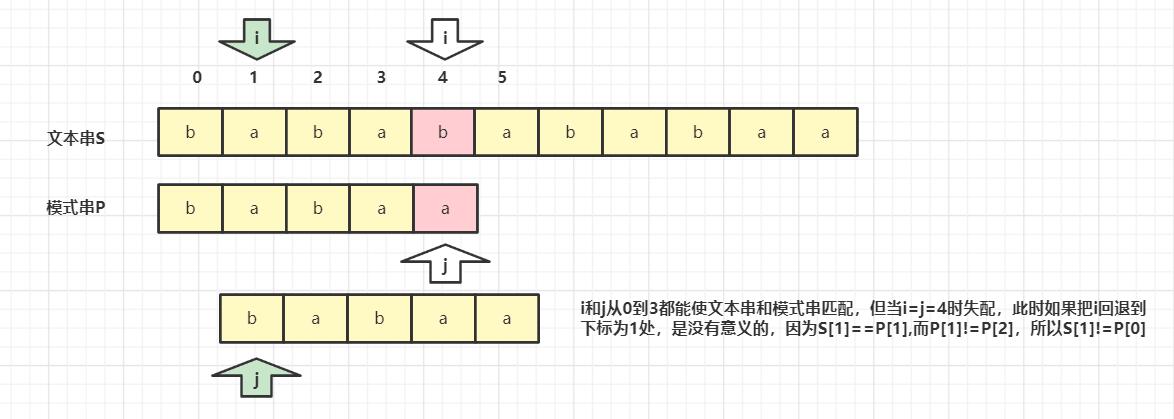
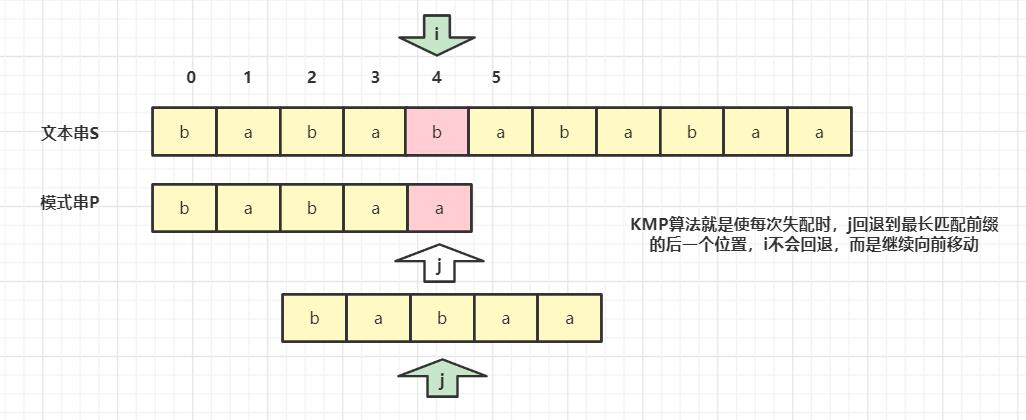
- 如何求解next数组

代码实现
public static void main(String[] args) {
String src = "babababcbabababb";
String p = "bababb";
int index = kmp(src, p);
System.out.println(index);
}
//s是文本串,p是模式串
private static int kmp(String s, String p) {
if (s.length() == 0 || p.length() == 0) return -1;
if (p.length() > s.length()) return -1;
int[] next = next(p);
int i = 0; //文本串的下标
int j = 0; //模式串的下标
int slength = s.length();
int plength = p.length();
while (i < slength) {
//①如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++
//j=-1,因为next[0]=-1,说明p的第一位和i这个位置无法匹配,这时i,j都增加1,i移位,j从0开始
if (j == -1 || s.charAt(i) == p.charAt(j)) {
i++;
j++;
} else {
//②如果j != -1,且当前字符匹配失败(即S[i] != P[j]),则令 i 不变,j = next[j]回退
//next[j]即为j所对应的next值
j = next[j];
}
if (j == plength) { //匹配成功了
return i - j;
}
}
return -1;
}
private static int[] next(String p) {
int[] next = new int[p.length() + 1];
int left = -1;
int right = 0;
next[0] = -1;
while (right < p.length()) {
if (left == -1 || p.charAt(left) == p.charAt(right)) {
next[++right] = ++left; //最长匹配位置加一
} else {
left = next[left]; //前缀回退到上一个最长匹配位置
}
}
return next;
}
KMP算法改进(nextval数组)
可以把next数组改造成nextval数组
| 下标(j) | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|---|
| 模式串(P) | a | b | c | d | a | b | d |
| next | -1 | 0 | 0 | 0 | 0 | 1 | 2 |
| nextval | -1 | 0 | 0 | 0 | -1 | 0 | 2 |
当 j 处模式串字符不等于next[j]处模式串字符时,nextval[j]=next[j]
当 j 处模式串字符等于next[j]处模式串字符时,nextval[j]=nextval[next[j]]
比如:

下标为j=4处的模式串字符是a,而下标为next[j]处的模式串字符也是a,则nextval[4]拷贝nextval[next[4]]处的值,也就是-1
解释一下,按照next数组回退的话,下标为4处next[4]=0,会回退到下标为0处,而下标为0处next[0]=-1,会回退到下标为-1处,回退了两次。
但是如果应用改进的nextval数组,下标为4处next[4]=-1,直接回退到下标为-1处,只需要回退一次。
当遇到有大量连续重复元素的数组时,性能提升最为明显。
比如:
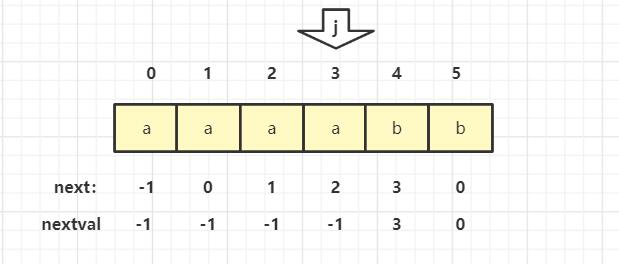
当 j=3 时,通过next数组回退需要先退到下标为2,再退到下标为1,在退到下标为0,最后退到下标为-1。
而通过nextval数组回退,一次就可以回退到下标为-1处。
//求nextval数组
private static int[] nextval(String p, int[] nextval) {
int right = 0, left = -1; //left是前缀,right是后缀
nextval[0] = -1;
while (right < p.length()) {
if (left == -1 || p.charAt(right) == p.charAt(left)) {
left++;
right++; //多加了一次判断比较 nextval[right] 和 nextval[left]
if (nextval[right] != nextval[left]) {
nextval[right] = left;
} else {
nextval[right] = nextval[left]; //注意
}
} else {
left = nextval[left]; //回退
}
}
return nextval;
}
【数据结构与算法】字符串匹配(Rabin-Karp 算法和KMP 算法)的更多相关文章
- 字符串匹配的BF算法和KMP算法学习
引言:关于字符串 字符串(string):是由0或多个字符组成的有限序列.一般写作`s = "123456..."`.s这里是主串,其中的一部分就是子串. 其实,对于字符串大小关系 ...
- 字符串匹配(BF算法和KMP算法及改进KMP算法)
#include <stdio.h> #include <string.h> #include <stdlib.h> #include<cstring> ...
- 字符串匹配-BF算法和KMP算法
声明:图片及内容基于https://www.bilibili.com/video/av95949609 BF算法 原理分析 Brute Force 暴力算法 用来在主串中查找模式串是否存以及出现位置 ...
- 数据结构(十六)模式匹配算法--Brute Force算法和KMP算法
一.模式匹配 串的查找定位操作(也称为串的模式匹配操作)指的是在当前串(主串)中寻找子串(模式串)的过程.若在主串中找到了一个和模式串相同的子串,则查找成功:若在主串中找不到与模式串相同的子串,则查找 ...
- BF算法和KMP算法
这两天复习数据结构(严蔚敏版),记录第四章串中的两个重要算法,BF算法和KMP算法,博主主要学习Java,所以分析采用Java语言,后面会补上C语言的实现过程. 1.Brute-Force算法(暴力法 ...
- 串匹配模式中的BF算法和KMP算法
考研的专业课以及找工作的笔试题,对于串匹配模式都会有一定的考察,写这篇博客的目的在于进行知识的回顾与复习,方便遇见类似的题目不会纠结太多. 传统的BF算法 传统算法讲的是串与串依次一对一的比较,举例设 ...
- 串的模式匹配 BF算法和KMP算法
设有主串s和子串t,子串t的定位就是要在主串中找到一个与子串t相等的子串.通常把主串s称为目标串,把子串t称为模式串,因此定位也称为模式匹配. 模式匹配成功是指在目标串s中找到一个模式串t: 不成功则 ...
- BF算法和KMP算法 python实现
BF算法 def Index(s1,s2,pos = 0): """ BF算法 """ i = pos j = 0 while(i < ...
- 软件设计师_朴素模式匹配算法和KMP算法
1.从主字符串中匹配模式字符串(暴力匹配) 2. KMP算法
随机推荐
- ceph-csi源码分析(2)-组件启动参数分析
更多ceph-csi其他源码分析,请查看下面这篇博文:kubernetes ceph-csi分析目录导航 ceph-csi源码分析(2)-组件启动参数分析 ceph-csi组件的源码分析分为五部分: ...
- 12、elk的使用(2)
12.8.收集日志: 因为logstash安装在从节点上,所以这里收集的主要是从节点上的服务日志: 1.收集系统日志: (1)配置文件: vim /etc/logstash/conf.d/system ...
- promise的基本使用
// 什么情况下适用promise? // 一般情况下是有异步请求操作时,使用promise对这个异步操作进行封装 // new ->构造函数(1.保存了一些状态信息 2.执行传入的函数) // ...
- [心得体会]spring事务源码分析
spring事务源码分析 1. 事务的初始化注册(从 @EnableTransactionManagement 开始) @Import(TransactionManagementConfigurati ...
- Hibernate框架(四)缓存策略+lazy
Hibernate作为和数据库数据打交道的框架,自然会设计到操作数据的效率问题,而对于一些频繁操作的数据,缓存策略就是提高其性能一种重要手段,而Hibernate框架是支持缓存的,而且支持一级和二级两 ...
- Redis为什么变慢了?常见延迟问题定位与分析
Redis作为内存数据库,拥有非常高的性能,单个实例的QPS能够达到10W左右.但我们在使用Redis时,经常时不时会出现访问延迟很大的情况,如果你不知道Redis的内部实现原理,在排查问题时就会一头 ...
- Acunetix与WAF集成:Acunetix和F5 BigIP ASM
该的Acunetix API让您有机会来实现任务自动化,从而提高效率-尤其是当你可以用加速您的工作流程的其他组件的功能整合.在此示例中,我们将在上一篇文章的基础上,向您展示如何在Bash脚本中使用Ac ...
- mysql,mongodb,redis区别
MongoDB: 它是一个内存数据库,数据都是放在内存里面的. 对数据的操作大部分都在内存中,但 MongoDB 并不是单纯的内存数据库. MongoDB 是由 C++ 语言编写的,是一个基于分布式文 ...
- 网站图片无缝兼容 WebP/AVIF
前言 WebP 格式发布已有十余年,但不少站点至今仍未使用,只为兼顾极少数低版本浏览器.至于去年发布的 AVIF 格式,使用的站点就更少了. 然而图片往往是流量大户,与其费尽心机优化脚本体积,可能还不 ...
- 将gitlab内置node_exporter提供外部prometheus使用
目录 修改gitlab的配置 重新初始化配置 gitlab服务已经包含了node_exporter服务,但是配置文件限制了9100端口的访问,所以主机信息不能直接被外部的prometheus收集 修改 ...