Flink学习笔记(详细待补充)
简单入门
- 安装nc:https://eternallybored.org/misc/netcat/ ,下载解压,配置到环境变量path,cmd使用
nc -lp port即可。linux使用nc -lk port - 批处理WordCount:获取环境、获取批数据、操作数据
- 流处理WordCount:获取环境、获取流数据、操作数据、提交执行
- 设置并行度
ParameterTool.fromArgs(args)从args获取参数- 设置共享组,默认default,同一个共享组的使用同一个slot,后一步没有设置则使用与前一个相同的共享组。
任务需要的slot是所有不同共享组的最大并行度的和
Flink安装部署
Standalone模式
- 解压缩flink-1.10.1-bin-scala_2.12 .tgz
- 修改flink-conf.yaml文件(jobmanager地址)
- 修改slaves为其他节点(master节点默认为localhost:8081),注意所有节点配置要一致
./start-cluster.sh启动集群,./stop-cluster.sh停止集群- 提交任务:配置优先级
代码 > 提交 > flink-conf.yaml- 前端提交,默认master的配置localhost:8081端口
- 命令行提交
flink run -c MainClass -p 2 xxx.jar --host localhost --port 7777
flink list查看运行的job
flink list -a列出所有job,包括取消的
flink cancel JobId取消job
缺点:当有任务的并行度大于现有可用的slot时,job提交会一直卡在create,直到有足够的slot
Yarn模式
要求flink是有hadoop支持的版本,Hadoop环境在2.2以上,并且集群中有HDFS服务。flink1.7之前自带Hadoop的jar包,之后需要自行下载,放入lib目录下
-- session-Cluster模式
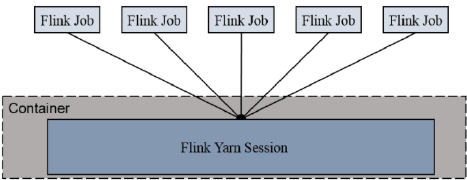
需要先启动flink集群,然后再提交作业,接着会向yarn申请一块空间,资源保持不变。如果资源满了下一个作业就无法提交,只能等到yarn中的某些作业执行完,释放了资源,下个作业才会正常提交。所有作业共享Dispatcher和ResourceManager,共享资源,适合规模小执行时间短的作业。
在yarn中初始化一个flink集群,开辟指定的资源,以后提交任务都向这里提交,这个flink集群会常驻在yarn集群,除非手动停止。
- 启动Hadoop集群
- 启动yarn-session
yarn-session.sh -n 2 -s 2 -jm 1024 -tm 1024 -nm test -d
-n(--container) taskmanager的数量(在现在的版本上不起作用)
-s(--slots)每个taskmanager的slot的数量,默认一个slot一个core,默认每个taskmanager的slot的个数为1,优势可以多一些taskmanager,做冗余
-jm JobManager的内存,MB
-tm 每个taskmanager的内存,MB
-nm yarn的appName,yarn的ui上的名字
-d 后台执行 - 提交任务与Standalone模式相同,启动yarn-session后默认向yarn-session提交,之后在yarn8088上即可查看
- 取消yarn-session
yarn application --kill application_xxxx
-- Per-Job-Cluster模式
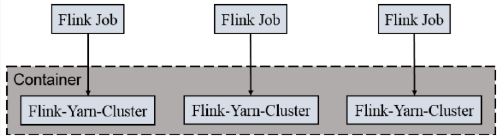
一个Job会对应一个集群,每提交一个作业会根据自身的情况,都会单独向yarn申请资源,直到作业执行完成,一个作业的失败与否并不会影响下一个作业的正常提交和运行。独享Dispatcher和ResourceManager,按需接受资源申请;适合规模大长时间运行的作业。
每次提交都会创建一个新的flink 集群,任务之间互相独立,互不影响,方便管理。任务执行完成之后创建的集群也会消失。
- 启动Hadoop集群
- 不启动yarn-session,直接执行job
fink run -m yarn-cluster ...
Kubernetes部署
flink在最近的版本中支持了k8s部署模式。在k8s上构建flink session cluster,需要将flink集群的组件对应的docker镜像分别在k8s上启动,包括jobmanager、taskmanager、jobmanagerservice三个镜像服务,每个镜像服务都可以从中央镜像仓库获取。
- 搭建k8s集群
- 配置各组件的yaml文件
- 启动Flink Session Cluster
kubectl create -f jobmanager-service.yaml启动jobmanager-service服务
kubectl create -f jobmanager-deployment.yaml启动jobmanager-deployment服务
kubectl create -f taskmanager-deployment.yaml启动taskmanager-deployment服务 - 访问Flink UI界面
集群启动后,就可以通过JobManagerServicers 中配置的 WebUI 端口,用浏览器输入以下 url 来访问 Flink UI 页面了http://{JobManager Host:Port}:Port}/api/v1/namespaces/default/services/flink-jobmanager:ui/proxy
Flink运行架构
运行时四大组件
-- JobManager
控制一个应用程序执行的主进程,也就是说,每个应用程序都会被一个不同的JobManager 所控制执行。 JobManager 会先接收到要执行的应用程序, 这个应用程序会包括:作业图( JobGraph )、逻辑数据流图 logical dataflow graph )和打包了所有的类、库和其它资源的 JAR 包。 JobManager 会把 JobGraph 转换成一个物理层面的数据流图,这个图被叫做“执行图 ExecutionGraph ),包含了所有可以并发执行的任务。 JobManager 会向资源管理器( ResourceManager )请求执行任务必要的资源,也就是任务管理器 TaskManager )上的插槽( slot )。一旦它获取到了足够的资源,就会将执行图分发到真正运行它们的TaskManager 上。而在运行过程中, JobManager 会负责所有需要中央协调的操作,比如说检查点( checkpoints )的协调。
-- TaskManager
Flink中的工作进程。通常在 Flink 中会有多个 TaskManager 运行,每一个 TaskManager都包含了一定数量的插槽(slots )。插槽的数量限制了 TaskManager 能够执行的任务数量。启动之后, TaskManager 会向资源管理器注册它的插槽;收到资源管理器的指令后,TaskManager 就会将一个或者多个插槽提供给 JobManager 调用。 JobManager 就可以向插槽分配任务( tasks )来执行了。在执行过程中,一个 TaskManager 可以跟其它运行同一应 用程序的 TaskManager 交换数据。
-- ResourceManager
主要负责管理任务管理器(TaskManager )的插槽 slot TaskManger 插槽是 Flink 中定义的处理资源单元。 Fli nk 为不同的环境和资源管理工具提供了不同资源管理器,比如YARN 、 Mesos 、 K8s ,以及 standalone 部署。当 JobManager 申请插槽资源时, ResourceManager会将有空闲插槽的 TaskManager 分配给 JobManager 。如果 ResourceManager 没有足够的插槽来满足 JobManager 的请求,它还可以向资源提供平台发起会话,以提供启动 TaskManager进程的容器。另外, ResourceManager 还负责终止空闲的 TaskManager ,释放计算资源。
-- Dispacher
可以跨作业运行,它为应用提交提供了REST 接口。当一个应用被提交执行时,分发器就会启动并将应用移交给一个 JobManager 。由于是 REST 接口,所以 Dispatcher 可以作为集群的一个 HTTP 接入点,这样就能够不受防火墙阻挡。 Dispatcher 也会启动一个 Web UI ,用来方便地展示和监控作业执行的信息。 Dispatcher 在架构中可能并不是必需的,这取决于应用提交运行的方式。
任务提交流程


任务调度原理

-- taskmanager与slot
一个taskManager是一个jvm进程,slot表示这个taskManager能接收多少task,是静态的概念,表示taskManager具有的并发执行能力
-- 程序与数据流(DataFlow)
-- 执行图(ExecutionGraph)
-- 并行度(Parallelism)
-- 任务链(Operator Chain)
Flink流处理API
批处理与流处理类似,执行环境获取不同
执行环境Environment
- 批处理环境
- 流处理环境
- LocalEnvironment
- RemoteEnvironment
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();批处理执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();流处理执行环境
也可以自己创建本地环境或使用远程环境:
StreamExecutionEnvironment.createLocalEnvironment(1);
StreamExecutionEnvironment.createRemoteEnvironment("jobManager-host", 6123, "path/to/your/jar");
数据源Source
- 集合
- 文件
- kafka
- 自定义
转换算子Transform
- 基本转换:map/flatMap/filter
- 分组聚合:keyBy/sum/min/max/minBy/maxBy
- 规约:reduce
- 多流:split-select/connect-CoMap-CoFlatMap/union,侧输出流
支持的数据类型
Java和Scala的基本数据类型,Java和Scala元组,Scala样例类,Java简单对象(必须有空参构造),其他(Arrays, Lists, Maps, Enum等等)
实现UDF - 更细粒度的控制流
- 函数类(Function Classes):Flink暴露了所有的udf的接口(实现方式为接口或抽象类,富函数的为抽象类)
- 匿名函数(Lambda Function)
- 富函数(Rich Functions):富函数是DataStreamAPI提供的一个函数类的接口,所有的Flink函数类都有Rich版本,与常规函数的不同在于,可以获取运行时的上下文,并拥有一些声明周期方法,可以实现更复杂的功能。(比如map前的open、执行后的close,简单的map只能一条数据调用一次,而声明周期方法是只执行一次,还可以获取上下文信息,比如并行度,任务名字,state状态等待)
富函数的使用与基本函数类似,只是是继承相应的接口
Sink
flink流数据写入kafka/redis/es/jdbc,以及其他官方的连接器,也可以自定义sink
Flink Window API
window是无限数据流处理的核心,window将一个无限的stream拆分成有限大小的bucket,我们可以在这些bucket上做计算操作。
窗口分类
- 时间窗口(Time Window):滚动时间窗口(Tumbling)、滑动时间窗口(Sliding)、会话窗口
- 计数窗口(Count Window):滚动时间窗口、滑动时间窗口
滚动窗口(按时间或数据个数滚动)、滑动窗口(按时间或数据个数,根据步长滑动)、会话窗口(只有时间类型的,多久未收到数据后结束当前窗口)
Window使用前必须先keyBy,再进行Window操作(窗口分配器),后面必须再跟上类似聚合的窗口操作(窗口函数)
窗口分配器(Window assigner)
window()方法接收的输入参数是一个windowAssigner,它负责把每条数据分发到正确的window中,flink提供了通用的windowAssigner:
- 滚动窗口
- 滑动窗口
- 会话窗口
- 全局窗口


窗口函数(Window function)
- 增量聚合函数:来一条数据计算一次,保持一个简单的状态,ReduceFunction,AggregateFunction
- 全窗口函数:先把窗口所有数据收集起来,计算时遍历所有数据(比如求中位数),ProcessWindowFunction,WindowFunction

Flink时间语义与Watermark(水印)
时间语义
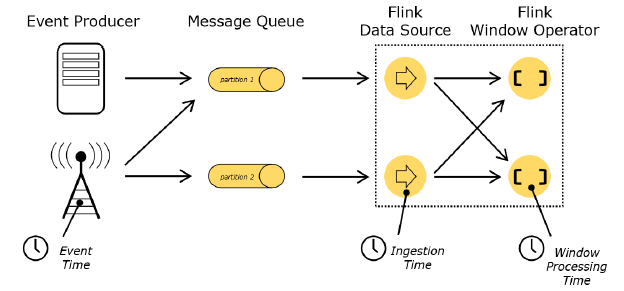
Event Time:是事件创建的时间。它通常由事件中的时间戳描述,例如采集的日志数据中,每一条日志都有生成时间,Flink通过时间戳分配器访问事件时间戳。如果使用kafka,自动使用kafka的时间
Ingestion Time:是数据进入 Flink 的时间。
Processing Time:是每一个执行基于时间操作的算子的本地系统时间,与机器相关,默认的时间属性就是 Processing Time
Watermark
- Watermark 是一种衡量 Event Time 进展的机制 。
- Watermark 是用于处理乱序事件的 ,而正确的处理乱序事件,通常用Watermark 机制结合 window 来实现。
- 数据流中的 Watermark 用于表示 timestamp 小于 Watermark 的数据,都已经到达了,因此, window 的执行也是由 Watermark 触发的。
- Watermark 可以理解成一个延迟触发机制,我们可以设置 Watermark 的延时时长 t ,每次系统会校验已经到达的数据中最大 的 max E vent T ime ,然后认定 eventTime小于 max Event Time t 的所有数据都已经到达,如果有窗口的停止时间等于max Event Time t ,那么这个窗口被触发执行。
水印有两种类型:
- AssignerWithPeriodicWatermarks,周期性生成watermark,默认200ms,可以在env设置时间语义的源码上看到(适合数据量大)
- AssignerWithPunctuatedWatermarks,每条数据后都插入一个水印(适合数据量小)
以上两个接口都继承自TimestampAssigner
水印的传递

当前分区的水印只取上游所有分区的最小值,只有当前分区的水印更新后,会向下游所有分区发送当前水印。
Flink状态管理
- 算子状态(Operator State)
- 键控状态(Keyed State)
- 状态后端(State Backends):状态的存储、访问、维护,由一个可插入的组件决定,这个组件叫状态后端,负责两件事,本地状态的管理,以及将检查点状态写入远程存储


ProcessFunction API(底层API)
可以访问时间戳、watermark、注册定时事件、输出特定事件。ProcessFunction用来构建事件驱动的应用以及实现自定义的业务逻辑(之前的算子和window无法实现)
- ProcessFunction 处理单个元素
- KeyedProcessFunction 处理分组后的单个元素
- CoProcessFunction
- ProcessJoinFunction
- BroadcastProcessFunction
- KeyedBroadcastProcessFunction
- ProcessWindowFunction 窗函数
- ProcessAllWindowFunction
Flink容错机制
- 一致性检查点(checkpoints):所有任务的状态,在所有任务都恰好处理完一个相同输入数据时候,进行保存状态,同步保存,检查点分界线之后的数据先缓存,等所有检查点保存完成之后再进行计算
- 从检查点恢复状态:从最近的检查点恢复应用状态,重新启动处理流程
- Flink检查点算法:基于Chandy-Lamport算法的分布式快照,检查点的保存和数据处理分离开,不暂停整个应用。
- 检查点分界线(Checkpoint Barrier):一种特殊数据,用于把一条流上的数据按照不同的检查点分开。
- 保存点:自定义保存检查点
Flink的状态一致性
端到端的一致性需要source可以使用偏移量查询历史数据、sink可以回滚。
- 状态一致性:AT MOST ONCE (最多一次)、AT LEAST ONCE (至少一次)、EXACTLY ONCE (精确一次)
- 一致性检查点:使用轻量级快照机制检查点保证exactly-once语义
- 端到端状态一致性:每个组件都要保证自己的一致性,取决于所有组件中一致性最弱的组件
- 端到端exactly-once保证:内部checkpoint、source可以重设数据读取位置、sink故障恢复时,数据不会重复写如外部系统(幂等写入、事务写入)。
- 事务写入的实现方式有两种:预写日志wal、两阶段提交(要求外部系统提供事务支持、提交事务必须幂等)
- Flink + Kafka端到端状态一致性的保证:内部利用checkpoint机制、source:消费者保存偏移量、sink:生产者采用两阶段提交
Table API 和 Flink SQL
- 创建TableEnvironment
- 创建表
- 表的查询:Table API、SQL
- 输出表
- 更新模式:追加模式、撤回模式、更新插入模式
- Table与DataStream的转换
- 创建临时视图
- 查看执行计划
- 动态表和持续查询
- 时间特性:事件时间和处理时间
- 窗口:group window、over window(有界和无界)、滚动窗口、滑动窗口、会话窗口
- 函数:比较函数、逻辑函数、算数函数、字符串函数、时间函数、聚合函数、用户自定义函数(标量函数、聚合函数、表函数、表聚合函数)
问题:
- keyBy的java POJO类所有字段必须是public的,必须有默认的无参构造器
- 侧输出流标签必须时实现类,要加{}
Flink学习笔记(详细待补充)的更多相关文章
- Apache Flink学习笔记
Apache Flink学习笔记 简介 大数据的计算引擎分为4代 第一代:Hadoop承载的MapReduce.它将计算分为两个阶段,分别为Map和Reduce.对于上层应用来说,就要想办法去拆分算法 ...
- Flink学习笔记-新一代Flink计算引擎
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- flink学习笔记-快速生成Flink项目
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- java多线程学习笔记——详细
一.线程类 1.新建状态(New):新创建了一个线程对象. 2.就绪状态(Runnable):线程对象创建后,其他线程调用了该对象的start()方法.该状态的线程位于可运行线程池中, ...
- Flink学习笔记:Flink Runtime
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:Flink开发环境搭建
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:Flink API 通用基本概念
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- flink学习笔记:DataSream API
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:Operators串烧
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:Time的故事
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
随机推荐
- Spring boot + Vue axios 文件下载
后端代码: @GetMapping("/{sn}") @ApiOperation(value = "获取文件",notes = "获取文件" ...
- Azure Terraform(十)利用 Azure DevOps 的条件语句选择发布环境
一,引言 之前我讲过的所有的案例中,都是将整个Azure Resource 部署到同一个订阅下,没有做到灵活的在 Azure Pipeline 在运行前选择需要部署的环境.在实际的项目开发中,我们也会 ...
- Servlet-ServletConfig类使用介绍
ServletConfig类(Servlet程序的配置信息类) Servlet 程序和 ServletConfig对象都是由 Tomcat负责创建,我们负责使用. Servlet 程序默认是第一次访问 ...
- 详解ElasticAPM实现微服务的链路追踪(NET)
前言 Elastic APM实现链路追踪,首先要引用开源的APMAgent(APM代理),然后将监控的信息发送到APMServer,然后在转存入ElasticSearch,最后有Kibana展示:具体 ...
- Shell 脚本进阶,经典用法及其案例
一.条件选择.判断 1.条件选择if (1)用法格式 if 判断条件 1 ; then 条件为真的分支代码 elif 判断条件 2 ; then 条件为真的分支代码 elif 判断条件 3 ; the ...
- Java反射机制及原理
一.概念 java程序运行时动态的创建类并调用类的方法和属性 二.原理简介 Class<?> clz = Class.forName("java.util.ArrayList ...
- Azure MFA 守护你的账户安全
一,引言 MFA 又名 "多因素身份认证",指用户在登录的时候提示输入其他形式的标识.如果只使用密码对用户进行身份验证,是特别不安全的,尤其是在密码泄露的情况下.为了提高安全性,启 ...
- rabbitmq-direct(直接交换模式)
生产者和消费者,具有相同的交换机名称(Exchange).交换机类型和相同的密匙(routingKey),那么消费者即可成功获取到消息.(PS:相对比只要交换机名称即可接收到消息的广播模式(fanou ...
- art 模式 android runtime
空间换时间的概念. art:程序在安装时需要预编译读取,将代码转换为机器码 好处:程序运行时,无需时时转换,运行速度快 : 缺点:安装时间稍长,由于转换机器码,所以占用略高的存储空间.
- @property中的copy关键字
1.@property中的copy的作用 防止外界修改内部的值 @interface Person : NSObject @property (nonatomic, retain) NSString ...