【C语言】整型在内存中的存储
整型在内存中的存储
1.整型的归类
- char
- short
- int
- long
以上都分为有符号(signed)与无符号(unsigned)的类型
2.原码、反码和补码
2.1 定义
计算机在表示一个数字时,是采用二进制的方式,所以为了准确表示一个数的正负,每一个有符号数都将其最高位视作是符号位,最高位为0表示正数,最高位为1表示负数。我们接下来以有符号整型int的数字进行分析。
一个有符号整数由符号位+数值位组成,数值位是其最高位,分别以0/1表示正/负
对于正数来说,反码补码都与原码相同;
对于负数来说,符合以下3条规则:
- 原码:将十进制数字直接翻译为二进制数
- 反码:原码的符号位不变,其他位按位取反
- 补码:反码+1
而对于整型来说,整型在内存中实际上是以补码的形式进行存储的。
2.2 补码的意义
有的同学可能就会问了,为什么计算机要发展出原码、反码、补码这么多种码呢?
这就与计算机对于整数的运算有关了。
CPU只有加法器,减法在运算时也会被视作一个数加另一个负数。考虑到整数的最高位是符号位,两个整数中若包含负数,以原码直接相加得到的数一定是不对的。所以问题就变成了如何使得运算简单而精确,既要处理符号位,又要只进行加法运算,达到以某一种二进制形式的“码”直接相加就能得到正确结果。
下面,我们以60+(-18)为例,分别用原码、反码、补码直接进行二进制的运算。
原码运算
00000000 00000000 00000000 00111100( 60的原码)
+ 10000000 00000000 00000000 00010010(-18的原码)
-------------------------------------------
10000000 00000000 00000000 01001110(某个数的原码)
显然,得到了的原码转化为10进制是-78,并非正确答案42。
反码运算
00000000 00000000 00000000 00111100( 60的反码)
+ 11111111 11111111 11111111 11101101(-18的反码)
-------------------------------------------
100000000 00000000 00000000 00101001
截取后32位:
00000000 00000000 00000000 00101001(某个数的反码)
显然,得到了的反码转化为10进制原码是41,并非正确答案42,但是只与正确答案相差(+1),于是,我们就想将负数的反码+1,即变成“补码”来进行运算,而又正数的补码是原码本身,这时候我们看看会怎么样呢?
补码运算
00000000 00000000 00000000 00111100( 60的补码)
+ 11111111 11111111 11111111 11101110(-18的反码)
-------------------------------------------
100000000 00000000 00000000 00101010
截取后32位:
00000000 00000000 00000000 00101010(某个数的补码)
显然,得到了的补码转化为10进制原码是42,我们得到了正确结果。
2.3 结论
综上,我们发现,只要将两个整数使用补码进行运算,就不需要考虑它们的符号位了,将它们的所有位直接简单相加即可,就能得到正确的结果。
2.4* 负数二进制补码的快速转化
对于char类型整数,-1用二进制补码表示为
11111111
当我们已知一个负数的二进制补码时,用比这个数多一位的、最高位为1、其他位全0、这里应为9位的二进制数
100000000
直接减去-1的二进制补码得
00000001
得到的数就是十进制(-1)的绝对值,也就是1,只要加上负号,就能快速得到这个负数二进制补码的十进制原码。
原理十分简单,一个负数的原码加上补码 =原码+反码+1 = 所有二进制位全1再加1 = 多一位的、最高位为1、其他位全0
3. 大小端字节序
3.1 什么是大小端
在内存中,数据的大小端存储是在字节尺度上进行讨论的
大端存储模式:数据的低位保存在内存的高地址,数据的高位保存在内存的低地址
小端存储模式:数据的低位保存在内存的低地址,数据的高位保存在内存的高地址
3.2 为什么有大端和小端之分
在计算机系统中,我们通常是以字节为单位存储数据的,每个地址对应一个字节。
一个字节为8bit,但是在C语言中除了8bit的char之外,还有16bit的short,32bit的int。另外,对于位数大于8位的处理器,例如16位和32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着如何将多个字节安排的问题。这边导致了大小端存储模式的诞生。
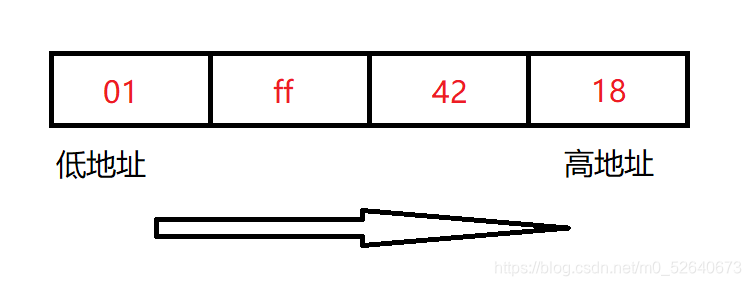
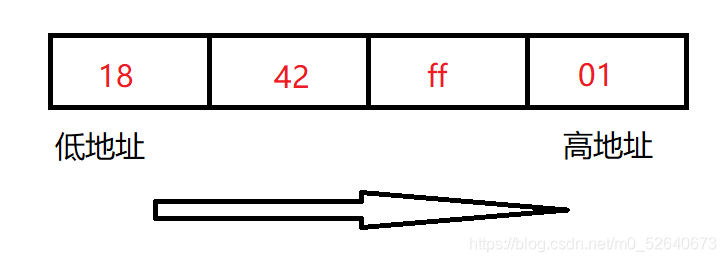
我们以int类型的数0x01ff4218为例(两个十六进制位即为1个字节),看一下在大小端下这4个字节分别是如何分配的
- 大端存储模式
- 小端存储模式
3.3 写一段代码来判断你的机器的大小端字节序
算法简单概括:截取4个字节大小的int整型的1个字节的低位。若机器为大端字节序,该字节存储0x00;若机器为小端字节序,该字节存储0x01;
#include<stdio.h>
//实现方法1
int check1()
{
int i = 1;
return *(char*)&i;
}
//实现方法2
int check2()
{
union check
{
int i;
char c;
}ch = {1};
return ch.c;
}
int main()
{
int ret = check1();
if (ret == 1)
{
printf("小端\n");
}
else
{
printf("大端\n");
}
return 0;
}
4.参考文献
- C Primer Plus, 第六版, p494
【C语言】整型在内存中的存储的更多相关文章
- C语言之数据在内存中的存储
C语言之数据在内存中的存储 在我们学习此之前,我们先来回忆一下C语言中都有哪些数据类型呢? 首先我们来看看C语言中的基本的内置类型: char //字符数据类型 short //短整型 int //整 ...
- 【C语言】浮点型在内存中的存储
1. 摘要 在了解到C语言中整型是以二进制补码形式存储在内存中后,我们不禁很好奇:那么浮点型的数据是以什么形式存储在内存中的呢? 实际上,早在1985年,电气电子工程师学会就制定了IEEE 754标准 ...
- C语言结构体在内存中的存储情况探究------内存对齐
条件(先看一下各个基本类型都占几个字节): void size_(){ printf("char类型:%d\n", sizeof(char)); printf("int类 ...
- C语言中浮点数在内存中的存储方式
关于多字节数据类型在内存中的存储问题 //////////////////////////////////////////////////////////////// int ,short 各自是4. ...
- <转载>浅谈C/C++的浮点数在内存中的存储方式
C/C++浮点数在内存中的存储方式 任何数据在内存中都是以二进制的形式存储的,例如一个short型数据1156,其二进制表示形式为00000100 10000100.则在Intel CPU架构的系统中 ...
- 数据在内存中的存储方式( Big Endian和Little Endian的区别 )(x86系列则采用little endian方式存储数据)
https://www.cnblogs.com/renyuan/archive/2013/05/26/3099766.html 1.故事的起源 “endian”这个词出自<格列佛游记>.小 ...
- QList介绍(QList比QVector更快,这是由它们在内存中的存储方式决定的。QStringList是在QList的基础上针对字符串提供额外的函数。at()操作比操作符[]更快,因为它不需要深度复制)非常实用
FROM:http://apps.hi.baidu.com/share/detail/33517814 今天做项目时,需要用到QList来存储一组点.为此,我对QList类的说明进行了如下翻译. QL ...
- 一个 -100.01 的double 在内存中怎么存储的. 一个中文String 在内存中占多少直接 utf-8 / GBK
一.-100.01 的double 在内存中怎么存储的 double双精度数据类型存储格式IEEE 双精度格式为8字节64位,由三个字段组成:52 位小数 f : 11 位偏置指数 e :以及 1 位 ...
- float 在内存中如何存储的
float类型数字在计算机中用4个字节存储.遵循IEEE-754格式标准: 一个浮点数有2部分组成:底数m和指数e 底数部分 使用二进制数来表示此浮点数的实际值指数部分 占用8bit的二进制数, ...
随机推荐
- ffmpeg实践
将mov视频解码300帧,并保存为1024:576分辨率,yuv420格式 ffmpeg -i Community_SneakAttack.mov -aspect 16:9 -vf scale=102 ...
- C++ primer plus读书笔记——第12章 类和动态内存分配
第12章 类和动态内存分配 1. 静态数据成员在类声明中声明,在包含类方法的文件中初始化.初始化时使用作用域运算符来指出静态成员所属的类.但如果静态成员是整形或枚举型const,则可以在类声明中初始化 ...
- C++ primer plus读书笔记——第8章 函数探幽
第8章 函数探幽 1. 对于内联函数,编译器将使用相应的函数代码替换函数调用,程序无需跳到一个位置执行代码,再调回来.因此,内联函数的运行速度比常规函数稍快,但代价是需要占用更多内存. 2. 要使用内 ...
- laravel 批量删除
<button id="delAll">批量删除</button>//给按钮一个id属性 <input type="checkbox&quo ...
- JAVA基础——包机制
包机制 包的语法格式package pkg1[.pkg2[.pkg3...]] 一般利用 公司域名倒置 作为包名; 例如www.baidu.com,则建立报的名字com.baidu.www 一般不要让 ...
- RHEL高级磁盘管理—Stratis
2. Stratis 本地存储管理工具,通过Stratis可以便捷的使用Thin Provisioning.Snapshots.Pool-based的管理和监控等高级存储功能. Stratis 基于x ...
- n/a或N/A是英语“不适用”(Not applicable)
n/a或N/A是英语"不适用"(Not applicable)等类似单词的缩写,常可在各种表格中看到. N/A比较多用在填写表格的时候,表示"本栏目(对我)不适用&quo ...
- Linux_网络进阶管理
一.链路聚合 1.什么是链路聚合? 网卡的链路聚合就是将多块网卡连接起来,当-块网卡损坏,网络依旧可以正常运行,可以有效的防止因为网卡损坏带来的损失,同时也可以提高网络访问速度. 2.链路聚合方式: ...
- win10家庭版升级 到win10企业版
成功升级3小时 20200124 拿到电脑 win10家庭版 不会用 找admin都找不到只能用企业版 升级win10家庭版 到win10企业版 在msdn下载win10企业版iso iso 文件管 ...
- openresty - nginx - 配置
local function local_print(str) local dbg = io.open("conf/lua/logs/output.txt", "a+&q ...