elasticsearch算法之词项相似度算法(二)
六、莱文斯坦编辑距离
前边的几种距离计算方法都是针对相同长度的词项,莱文斯坦编辑距离可以计算两个长度不同的单词之间的距离;莱文斯坦编辑距离是通过添加、删除、或者将一个字符替换为另外一个字符所需的最小编辑次数;
我们假设两个单词u、v的长度分别为i、j,则其可以分以下几种情况进行计算
当有一个单词的长度为0的时候,则编辑距离为不为零的单词的长度;
\]
从编辑距离的定义上来看,在单词的变化过程中,每个字符的变化都可以看做是在其前缀子字符串的编辑距离基础上,进行当前字符的删除、添加、替换操作;
name当u和v的长度都不为0的时候,存在三种转化的可能
u的不包含最后一个字符的前缀转化为v的前提下,这是删除字符的情形;
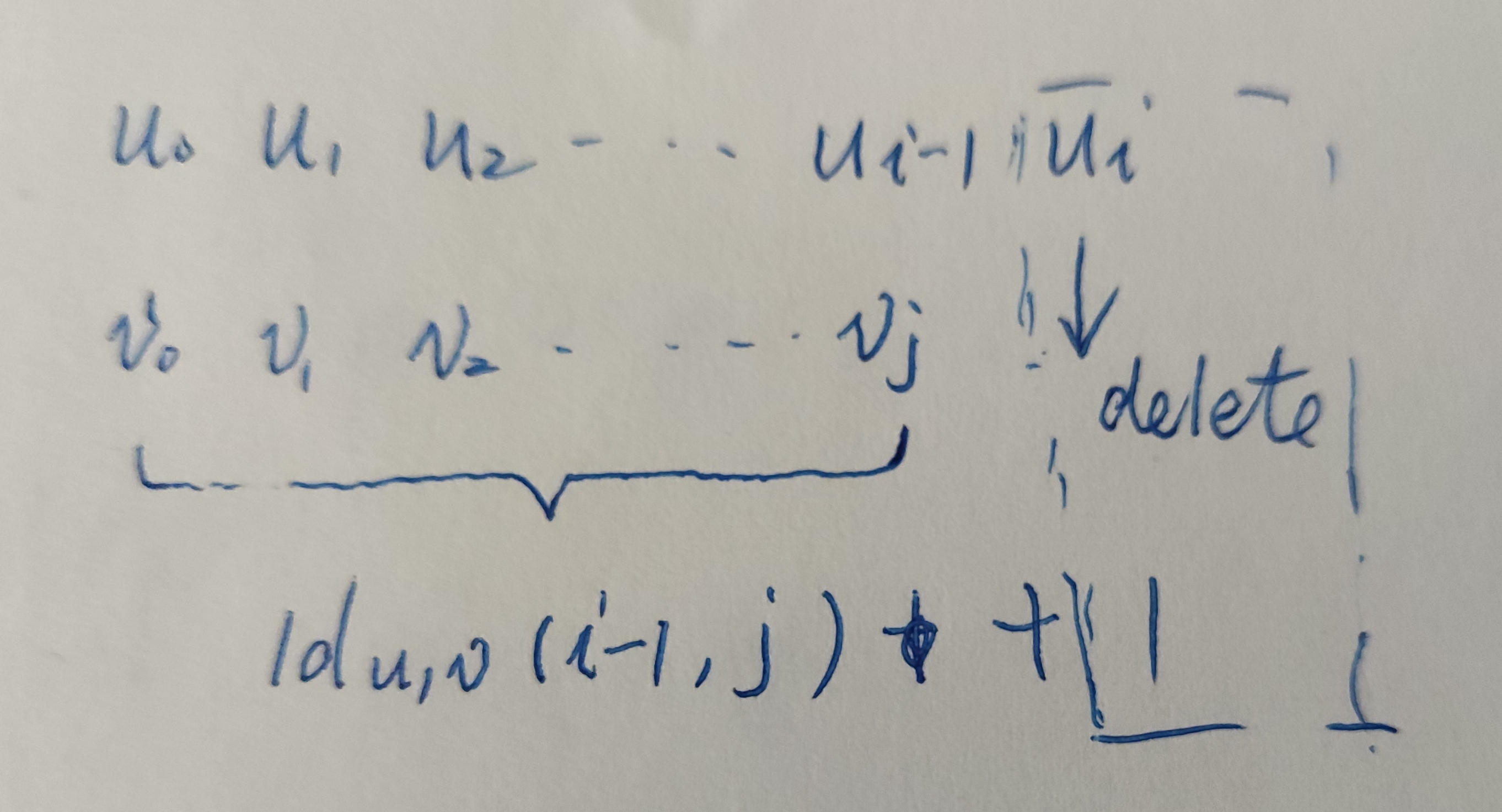
此时的数学公式为
\]
u已经整个转化为v不包含最后一个字符的前缀的前提下,这是添加字符的情形;
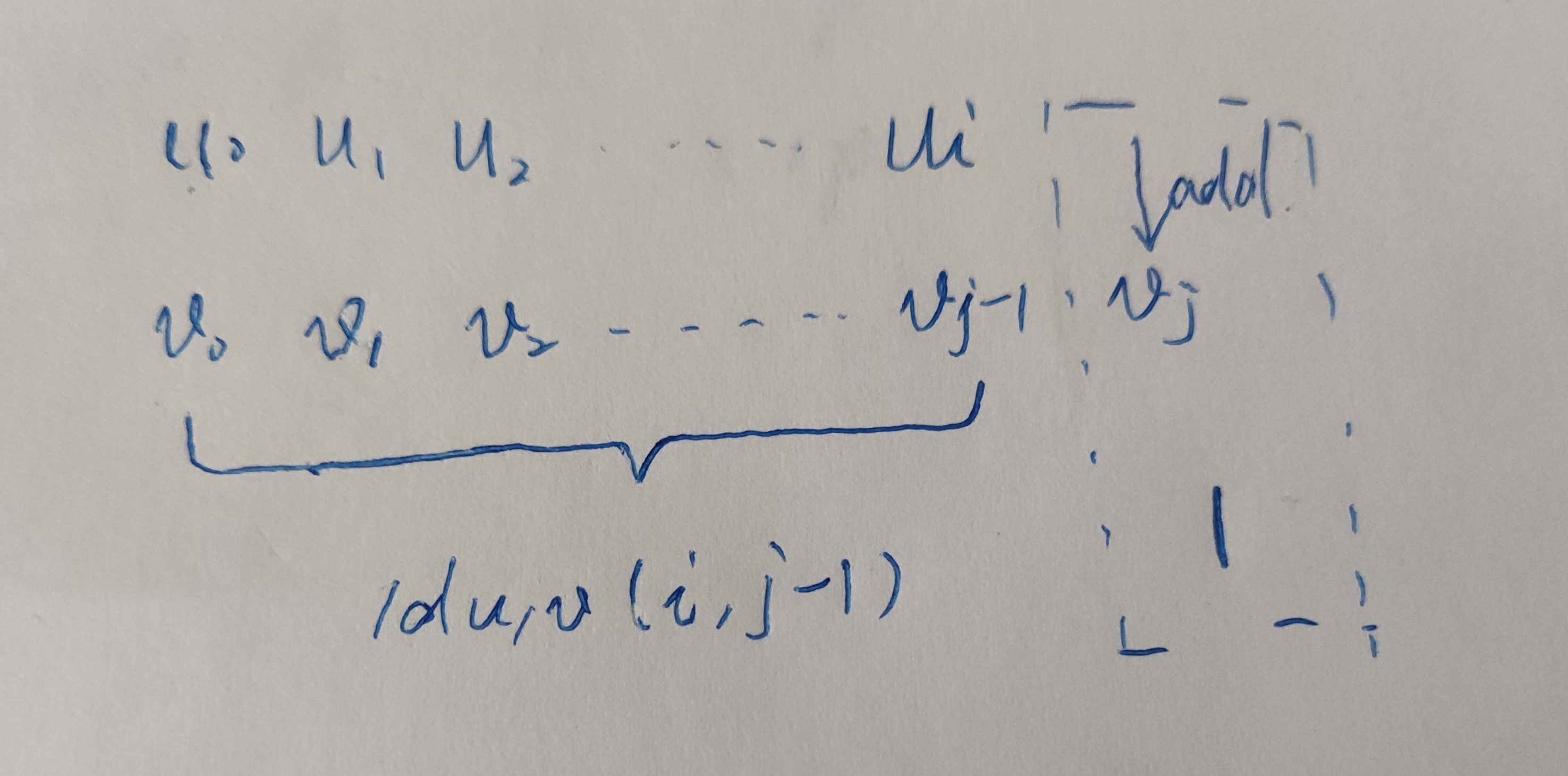
此时的数学公式为
\]
u前缀已经转化为v的前缀的前提下,这个时候需要根据两个词的最后一个字符是否相等,如果不等的话就需要替换;
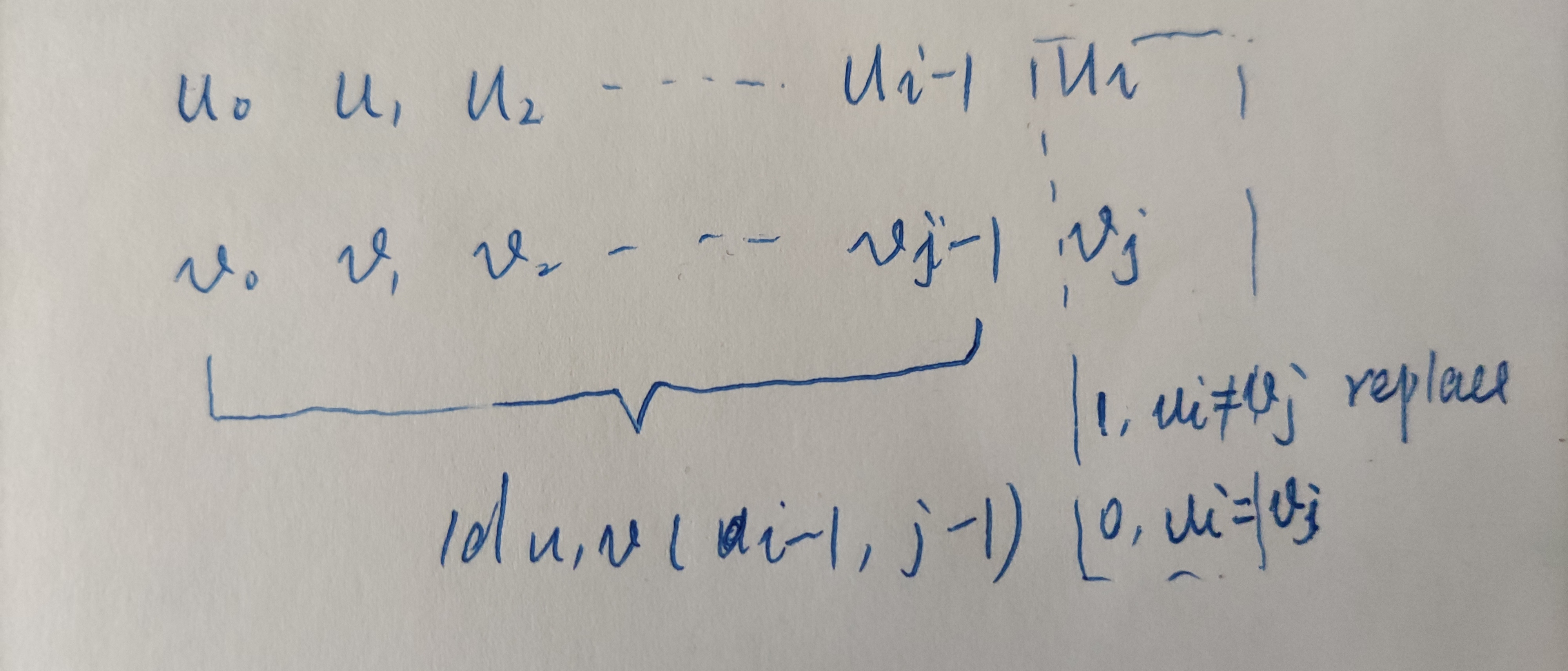
此时的数学公式为
C_{u_{i}\ne{v_{i}}} = \left\{\begin{matrix}
1, u_{i}\ne v_{i} \\
0, u_{i}=v_{i} \\
\end{matrix}\right.
\]
然后取三种情况里最小的值作为编辑距离即可;
以上都是从递归的角度进行的抽象描述,可能直接理解起来有点困难;我们还是通过vlna转变为vlan为例,使用矩阵了直观的了解一下这个算法;
矩阵的第一行可以理解为vlna的前缀子串转化为v的编辑距离;
v => v,编辑距离为0;
vl => v,编辑距离为1;
同样的道理,矩阵的第一列是vlna的子串v分别转化为vlan的所有前缀子串的编辑距离;
接下来我们就可以看看第二行第二列的编辑距离是怎么计算的;
第二行第一列表示v=>vl的编辑距离为1,即
\]
此时只需要在这个基础上删除l即可;这就是对应删除字符的情况,此时编辑距离为2;
\]
第一行第二列表示vl=>v的编辑距离为1,即
\]
此时只需要在这个基础上增加字符l即可;这就是对应新增字符的情况,此时编辑距离为2;
\]
第一行第一列表示v=>v的编辑距离为0,即
\]
由于此时由于两个单词里的字符都是l,所以字符不需要替换,这就是对应字符替换的情况,此时编辑距离为0;
\]
通过以上分析我们可以知道编辑距离为0;同时我们也可以发现矩阵中每个位置的编辑距离是跟其左边、左上、上边的编辑距离有关的,只需要计算三者中的最小者作为编辑距离即可;
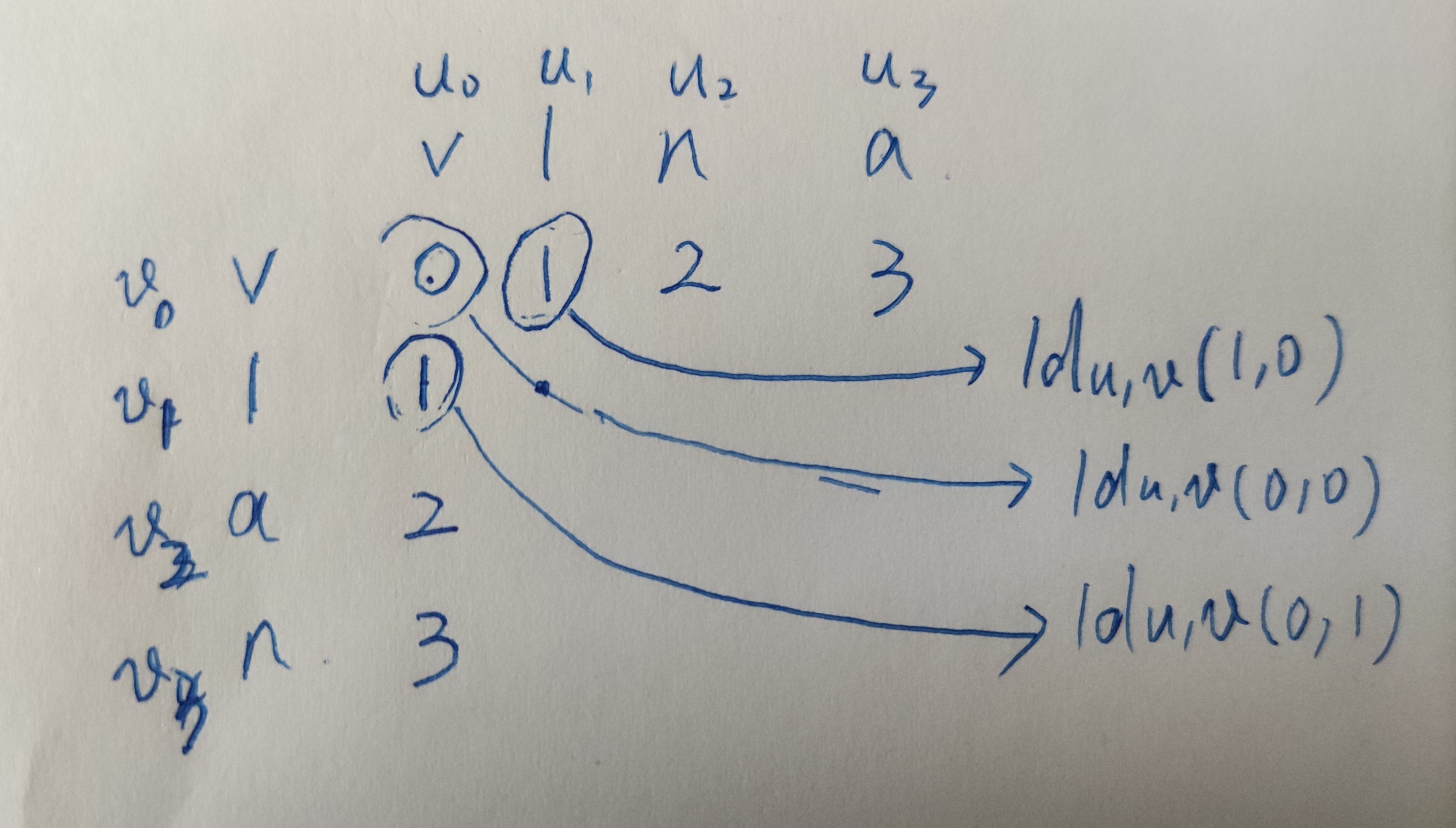
通过以上的编辑距离矩阵,我们最终只关注最后一个单元格的值,而其计算只需要关注其上一行和当前行的编辑距离;
为了计算方便,我们可以在u和v前边分别加一个空白占位符,这样对每个字符都存在三个方向位置的编辑距离了;
我们使用如下的方法计算编辑距离和编辑距离矩阵;
import copy
import pandas as pd
def levenshtein_edit_distance(u, v):
u = u.lower()
v = v.lower()
distance = 0
if len(u) == 0:
distance = len(v)
elif len(v) == 0:
distance = len(u)
else:
edit_matrix = []
pre_row = [0] * (len(v) + 1)
current_row = [0] * (len(v) + 1)
# 初始化补白行的编辑距离
for i in range(len(u) +1):
pre_row[i] = i
for i in range(len(u)):
current_row[0] = i + 1
for j in range(len(v)):
cost = 0 if u[i] == v[j] else 1
current_row[j+1] = min(current_row[j] + 1, pre_row[j+1] + 1, pre_row[j] + cost)
for j in range(len(pre_row)):
pre_row[j] = current_row[j]
edit_matrix.append(copy.copy(current_row))
distance = current_row[len(v)]
edit_matrix = np.array(edit_matrix)
edit_matrix = edit_matrix.T
edit_matrix = edit_matrix[1:,]
edit_matrix = pd.DataFrame(data = edit_matrix, index=list(v), columns=list(u))
return distance,edit_matrix
我们使用相同的关键字,使用如下代码进行测试
vlan = 'vlan'
vlna = 'vlna'
http='http'
words = [vlan, vlna, http]
input_word = 'vlna'
for word in words:
distance, martrix = levenshtein_edit_distance(input_word, word)
print(f"{input_word} and {word} levenshtein edit distance is {distance}")
print('the complate edit distance matrix')
print(martrix)
vlna and vlan levenshtein edit distance is 2
the complate edit distance matrix
v l n a
v 0 1 2 3
l 1 0 1 2
a 2 1 1 1
n 3 2 1 2
vlna and vlna levenshtein edit distance is 0
the complate edit distance matrix
v l n a
v 0 1 2 3
l 1 0 1 2
n 2 1 0 1
a 3 2 1 0
vlna and http levenshtein edit distance is 4
the complate edit distance matrix
v l n a
h 1 2 3 4
t 2 2 3 4
t 3 3 3 4
p 4 4 4 4
七、余弦距离
余弦距离是一个跟余弦相似度关联的的概念;我们可以使用向量来表示不同的单词,而两个不同单词向量之间的余弦值便是余弦相似度;两者之间的夹角越小则余弦值越小,则两者约相似;
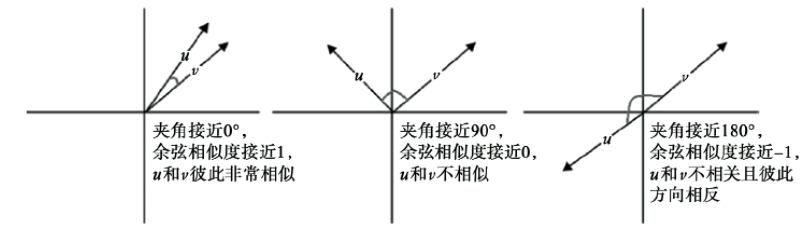
根据向量的內积公式可以得到如下的余弦相似度公式;
\]
余弦相似度越大,则两个单词越相似,而距离则正好相反,则可得余弦距离为
\]
要计算余弦距离就需要首先将单词转化为向量,我们可以通过scipy.stats.itemfreq来将单词进行字符袋向量化;我们通过以下方法计算每个词中的每个字符出现的次数;
from scipy.stats import itemfreq
def boc_term_vectors(words):
words = [word.lower() for word in words]
unique_chars = np.unique(np.hstack([list(word) for word in words]))
word_term_counts = [{char:count for char,count in itemfreq(list(word))} for word in words]
boc_vectors = [np.array([
int(word_term_count.get(char, 0)) for char in unique_chars])
for word_term_count in word_term_counts
]
return list(unique_chars), boc_vectors
使用以下代码测试一下
vlan = 'vlan'
vlna = 'vlna'
http='http'
words = [vlan, vlna, http]
chars, (boc_vlan,boc_vlna,boc_http) = boc_term_vectors(words)
print(f'all chars {chars}')
print(f"vlan {boc_vlan}")
print(f"vlna {boc_vlna}")
print(f"http {boc_http}")
all chars ['a', 'h', 'l', 'n', 'p', 't', 'v']
vlan [1 0 1 1 0 0 1]
vlna [1 0 1 1 0 0 1]
http [0 1 0 0 1 2 0]
我们可以根据公式使用以下方法计算余弦距离;
def cosin_distance(u, v):
distance = 1.0 - np.dot(u,v)/(np.sqrt(sum(np.square(u))) * np.sqrt(sum(np.square(v))))
return distance
使用相同的关键字,使用以下代码测试余弦距离;
vlan = 'vlan'
vlna = 'vlna'
http='http'
words = [vlan, vlna, http]
chars, boc_words = boc_term_vectors(words)
input_word =vlna
boc_input = boc_words[1]
for word, boc_word in zip(words, boc_words):
print(f'{input_word} and {word} cosine distance id {cosin_distance(boc_input, boc_word)}')
vlna and vlan cosine distance id 0.0
vlna and vlna cosine distance id 0.0
vlna and http cosine distance id 1.0
elasticsearch算法之词项相似度算法(二)的更多相关文章
- elasticsearch算法之词项相似度算法(一)
一.词项相似度 elasticsearch支持拼写纠错,其建议词的获取就需要进行词项相似度的计算:今天我们来通过不同的距离算法来学习一下词项相似度算法: 二.数据准备 计算词项相似度,就需要首先将词项 ...
- elasticsearch算法之推荐系统的相似度算法(一)
一.推荐系统简介 推荐系统主要基于对用户历史的行为数据分析处理,寻找得到用户可能感兴趣的内容,从而实现主动向用户推荐其可能感兴趣的内容: 从物品的长尾理论来看,推荐系统通过发掘用户的行为,找到用户的个 ...
- ElasticStack学习(九):深入ElasticSearch搜索之词项、全文本、结构化搜索及相关性算分
一.基于词项与全文的搜索 1.词项 Term(词项)是表达语意的最小单位,搜索和利用统计语言模型进行自然语言处理都需要处理Term. Term的使用说明: 1)Term Level Query:Ter ...
- elasticsearch高亮之词项向量
一.什么是词项向量 词项向量(term vector)是有elasticsearch在index document的时候产生,其包含对document解析过程中产生的分词的一些信息,例如分词在字段值中 ...
- 百度面试题 字符串相似度 算法 similar_text 和页面相似度算法
在百度的面试,简直就是花样求虐. 首先在面试官看简历的期间,除了一个自己定义字符串相似度,并且写出求相似度的算法. ...这个确实没听说过,php的similar_text函数也是闻所未闻的.之前看s ...
- 关联规则—频繁项集Apriori算法
频繁模式和对应的关联或相关规则在一定程度上刻画了属性条件与类标号之间的有趣联系,因此将关联规则挖掘用于分类也会产生比较好的效果.关联规则就是在给定训练项集上频繁出现的项集与项集之间的一种紧密的联系.其 ...
- Spark/Scala实现推荐系统中的相似度算法(欧几里得距离、皮尔逊相关系数、余弦相似度:附实现代码)
在推荐系统中,协同过滤算法是应用较多的,具体又主要划分为基于用户和基于物品的协同过滤算法,核心点就是基于"一个人"或"一件物品",根据这个人或物品所具有的属性, ...
- python 下的数据结构与算法---2:大O符号与常用算法和数据结构的复杂度速查表
目录: 一:大O记法 二:各函数高阶比较 三:常用算法和数据结构的复杂度速查表 四:常见的logn是怎么来的 一:大O记法 算法复杂度记法有很多种,其中最常用的就是Big O notation(大O记 ...
- FP-Growth算法之频繁项集的挖掘(python)
前言: 关于 FP-Growth 算法介绍请见:FP-Growth算法的介绍. 本文主要介绍从 FP-tree 中提取频繁项集的算法.关于伪代码请查看上面的文章. FP-tree 的构造请见:FP-G ...
随机推荐
- MySQL实现主从库,AB复制配置
AB复制是一种数据复制技术,是myslq数据库提供的一种高可用.高性能的解决方案. AB复制的模式:一主一从 .一主多从.双主.多主多从 复制的工作原理:要想实现ab复制,那么前提是master上必须 ...
- JAVA实现map集合转Xml格式
import java.util.Iterator; import java.util.SortedMap; import java.util.TreeMap; public class MainTe ...
- windows10源码编译llvm
准备 cmake, 我目前使用的版本是3.18 llvm 源码, 我下载的是 11.0 我已经具备Vs2015和Vs2017的开发环境. debug模式编译需要较多内存和较多硬盘存储空间. (debu ...
- 【LeetCode】198. House Robber 打家劫舍 解题报告(Java & Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 递归 递归 + 记忆化 动态规划 优化动态规划空间 ...
- 【LeetCode】1021. Best Sightseeing Pair 最佳观光组合(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 日期 题目地址:https://leetcode.c ...
- PowerDotNet平台化软件架构设计与实现系列(10):文件平台
很多业务系统少不了需要进行文件管理,比如各种图片.excel.pdf.压缩包等等,为了高度可复用,我们抽象出文件平台,加强对文件进行管理. PowerDotNet文件平台目前支持阿里云OSS.Fast ...
- [error]Flask Address already in use
在Python的Flask框架下Address already in use [地址已在使用中] 出现这种错误提示, 说明你已经有一个流程绑定到默认端口(5000).如果您之前已经运行过相同的模块,则 ...
- 元宇宙(metaverse)中文社区-工程实践
欢迎访问元宇宙中文社区,在这里大家可以提问,回答,分享,诉说,一起构建一个元宇宙社区. 2021年"元宇宙"的这个词的火热程度在业内绝对不亚于疫情,趁着这个热度,本文记录了如何搭建 ...
- 使用 jQuery对象设置页面中 <ul> 元素的标记类型,并使用 DOM 对象设置 <li> 元素的浮动属性和右边距。使用jQuery 对象和 DOM 对象设置页面元素属性
查看本章节 查看作业目录 需求说明: 使用 jQuery对象设置页面中 <ul> 元素的标记类型,并使用 DOM 对象设置 <li> 元素的浮动属性和右边距.使用jQuery ...
- CentOS7 防火墙firewalld 和 CentOS6 防火墙iptables 开放zabbix-agent端口的方法
我们在生产环境中,一般都是把防火墙打开的,不像测试环境,可以直接关闭掉.最近安装zabbix ,由于公司服务器既有centos 7又有centos 6,遇到了一些防火墙的问题,现在正好把centos防 ...