内存吞金兽(Elasticsearch)的那些事儿 -- 认识一下
背景及常见术语
背景
Elasticsearch 是一个开源的搜索引擎,建立在一个全文搜索引擎库 Apache Lucene 基础之上。 Lucene 可以说是当下最先进、高性能、全功能的搜索引擎库—无论是开源还是私有。
但是 Lucene 仅仅只是一个库。为了充分发挥其功能,你需要使用 Java 并将 Lucene 直接集成到应用程序中。 更糟糕的是,您可能需要获得信息检索学位才能了解其工作原理。Lucene 非常 复杂。
Elasticsearch 也是使用 Java 编写的,它的内部使用 Lucene 做索引与搜索,但是它的目的是使全文检索变得简单, 通过隐藏 Lucene 的复杂性,取而代之的提供一套简单一致的 RESTful API。
然而,Elasticsearch 不仅仅是 Lucene,并且也不仅仅只是一个全文搜索引擎。 它可以被下面这样准确的形容:
- 一个分布式的实时文档存储,每个字段 可以被索引与搜索
- 一个分布式实时分析搜索引擎
- 能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据
Elasticsearch 将所有的功能打包成一个单独的服务,可以通过程序与它提供的简单的 RESTful API 进行通信, 可以使用自己喜欢的编程语言充当 web 客户端,甚至可以使用命令行(去充当这个客户端)。
面向文档
Elasticsearch 是 面向文档 的,意味着它存储整个对象或 文档。Elasticsearch 不仅存储文档,而且 索引 每个文档的内容,使之可以被检索。在 Elasticsearch 中,我们对文档进行索引、检索、排序和过滤—而不是对行列数据。这是一种完全不同的思考数据的方式,也是 Elasticsearch 能支持复杂全文检索的原因。
几个关键词
- 实时
- 分布式
- 搜索
- 分析
优势
- Elasticsearch对模糊搜索非常擅长(搜索速度很快)
- 从Elasticsearch搜索到的数据可以根据评分过滤掉大部分的,只要返回评分高的给用户就好了(原生就支持排序)
- 没有那么准确的关键字也能搜出相关的结果(能匹配有相关性的记录)
常见术语
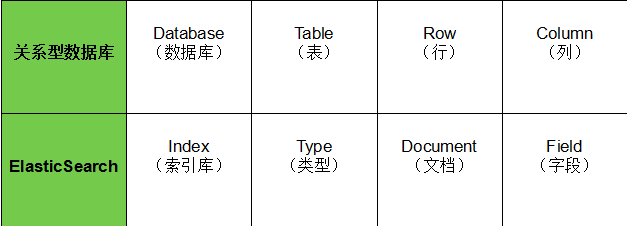
- Index:Elasticsearch的Index相当于数据库的Table
- Type:这个在新的Elasticsearch版本已经废除(在以前的Elasticsearch版本,一个Index下支持多个Type--有点类似于消息队列一个topic下多个group的概念)
- Document:Document相当于数据库的一行记录
- Field:相当于数据库的Column的概念
- Mapping:相当于数据库的Schema的概念(个人感觉这个解释不太合理,说白了其实就是静态类型映射)
- DSL:相当于数据库的SQL(给我们读取Elasticsearch数据的API)
- cluster:一组拥有共同的 cluster name 的节点
- node:集群中的一个 实例
- primary shard: 索引的子集,索引可以切分成多个分片,分布在不同的节点,分片对应的是lucene中的索引
- replica shard:每个主分片可以有一个或者多个副本
- allocation:将分片分配给某个节点的过程,包括分配主分片或副本。如果是副本,还包括从主分片复制数据的过程
客户端
节点客户端(Node client)
节点客户端作为一个非数据节点加入到本地集群中。换句话说,它本身不保存任何数据,但是它知道数据在集群中的哪个节点中,并且可以把请求转发到正确的节点。
传输客户端(Transport client)
轻量级的传输客户端可以将请求发送到远程集群。它本身不加入集群,但是它可以将请求转发到集群中的一个节点上。
注意️
两个 客户端都是通过 端口并使用 Elasticsearch 的原生 传输 协议和集群交互。集群中的节点通过端口 彼此通信。如果端口没有打开,节点将无法形成一个集群。
客户端作为节点必须和 Elasticsearch 有相同的 主要 版本;否则,它们之间将无法互相理解。
应用场景
如果要将应用程序和 Elasticsearch 集群进行解耦,传输客户端是一个理想的选择。例如,如果您的应用程序需要快速的创建和销毁到集群的连接,传输客户端比节点客户端”轻”,因为它不是一个集群的一部分。
类似地,如果您需要创建成千上万的连接,你不想有成千上万节点加入集群。传输客户端( TC )将是一个更好的选择。
另一方面,如果你只需要有少数的、长期持久的对象连接到集群,客户端节点可以更高效,因为它知道集群的布局。但是它会使你的应用程序和集群耦合在一起,所以从防火墙的角度,它可能会构成问题。
RESTful API with JSON over HTTP
可以使用 RESTful API 通过端口 和 Elasticsearch 使用类GraphQL语义进行通信,可以用任何一个 web 客户端访问 Elasticsearch
java - spring接入方式
https://spring.io/projects/spring-data-elasticsearch
内存吞金兽(Elasticsearch)的那些事儿 -- 认识一下的更多相关文章
- 内存吞金兽(Elasticsearch)的那些事儿 -- 常见问题痛点及解决方案
1.大数据量的查询效率如何保证: 查询的流程:往 ES 里写的数据,实际上都写到磁盘文件里去了,查询的时候,操作系统会将磁盘文件里的数据自动缓存到 Filesystem Cache 里面去 最佳的情况 ...
- Plan B
王兴曾经说过: 2019 年是过去 10 年中最差的一年,也是未来 10 年中最好的一年. 之前我希望王兴预判错了,但现在我发现这位掌控着生活消费类数据的大佬应该不是扯淡. 今年的内部和外部环境真的很 ...
- Elasticsearch内存分配设置详解
Elasticsearch默认安装后设置的内存是1GB,对于任何一个现实业务来说,这个设置都太小了.如果你正在使用这个默认堆内存配置,你的集群配置可能会很快发生问题. 这里有两种方式修改Elastic ...
- elasticsearch.in.sh优化内存
elasticsearch.in.sh文件主要是内存优化 ES_MIN_MEM=24g(24g是物理内存的一半) ES_MAX_MEM=24g ES调优: 1.Java层面的调优,加大JVM的可用内存 ...
- ElasticSearch优化系列二:机器设置(内存)
预留一半内存给Lucene使用 一个常见的问题是配置堆太大.你有一个64 GB的机器,觉得JVM内存越大越好,想给Elasticsearch所有64 GB的内存. 当然,内存对于Elasticsear ...
- [翻译]Elasticsearch重要文章之二:堆内存的大小和swapping
Elasticsearch默认安装后设置的内存是1GB,对于任何一个业务部署来说,这个都太小了.如果你正在使用这些默认堆内存配置,你的集群配置可能有点问题. 这里有两种方式修改Elasticsearc ...
- Elasticsearch内存分配设置详解(转)
Elasticsearch默认安装后设置的内存是1GB,对于任何一个现实业务来说,这个设置都太小了.如果你正在使用这个默认堆内存配置,你的集群配置可能会很快发生问题.这里有两种方式修改Elastics ...
- 关于ElasticSearch的堆内存设置与优化
1.什么是堆内存?Java 中的堆是 JVM 所管理的最大的一块内存空间,主要用于存放各种类的实例对象.在 Java 中,堆被划分成两个不同的区域:- 新生代 ( Young ).- 老年代 ( Ol ...
- Elasticsearch 堆内存
转载自:https://www.lbbniu.com/6148.html 1.什么是堆内存? Java 中的堆是 JVM 所管理的最大的一块内存空间,主要用于存放各种类的实例对象. 在 Java 中, ...
随机推荐
- Maven | 把jar包安装到本地仓库
使用的场景 自己写的工具类想安装到本地 从Maven仓库中下载不下来的jar 使用的步骤 首先要保证自己的Maven配置全局环境变量,如果没有配置过maven全局变量,可以按照下面的步骤配置一下: 先 ...
- Pandas高级教程之:window操作
目录 简介 滚动窗口 Center window Weighted window 加权窗口 扩展窗口 指数加权窗口 简介 在数据统计中,经常需要进行一些范围操作,这些范围我们可以称之为一个window ...
- AgileTC linux部署
简介 AgileTC是一套敏捷的测试用例管理平台,支持测试用例管理.执行计划管理.进度计算.多人实时协同等能力,方便测试人员对用例进行管理和沉淀.产品以脑图方式编辑可快速上手,用例关联需求形成流程闭环 ...
- MongoDB 基础学习
1.MongoDB 概念解析 SQL术语/概念 MongoDB术语/概念 解释/说明 database database 数据库 table collection 数据库表/集合 row docume ...
- Jmeter性能测试指标分析
一.Aggregate Report 是 JMeter 常用的一个 Listener,中文被翻译为"聚合报告 如果大家都是做Web应用的性能测试,例如访问百度请求为例,线程10,循环10次, ...
- 如何进行TIDB优化之Grafana(TiDB 3.0)关注监控指标
前言 在对数据库进行优化前,我们先要思考一下数据库系统可能存在的瓶颈所在之外.数据库服务是运行在不同的硬件设备上的,优化即通过参数配置(不考虑应用客户端程序的情况下),而实现硬件资源的最大利用化.那么 ...
- 基于小熊派Hi3861鸿蒙开发的IoT物联网学习【一】
基于小熊派鸿蒙季BearPi-HM_Nano HarmonyOS 鸿蒙系统Hi3861开发板NFC 开发步骤:1.购买开发板:某宝上购买就行 2.安装开发环境 3.下载源码 4.编写案例并执行 开发 ...
- 用 JavaScript 刷 LeetCode 的正确姿势【进阶】
之前写了篇文章 用JavaScript刷LeetCode的正确姿势,简单总结一些用 JavaScript 刷力扣的基本调试技巧.最近又刷了点题,总结了些数据结构和算法,希望能对各为 JSer 刷题提供 ...
- WebRTC 用例和性能
WebRTC 用例和性能 实现低延迟.点对点传输是一项艰巨的工程挑战:有 NAT 遍历和连接检查.信令.安全.拥塞控制和无数其他细节需要处理.WebRTC 代表我们处理以上所有内容,这就是为什么它可以 ...
- SpringBoot @ModelAttribute 用法
前言 项目中遇到这么一个使用场景,用户的登录信息给予token保存,在需要有登录信息的地方,每次都要去获取用户Id,但每次在请求方法中去获取用户信息,代码重复,冗余,很low于是想到了用@ModelA ...