Flume对接Kafka
一.简单实现
需求:根据 flume 监控 exec 文件的追加数据,写入 kafka 的 test-demo 分区,然后启用 kafka-consumer 消费 test-demo 分区数据。
需求分析
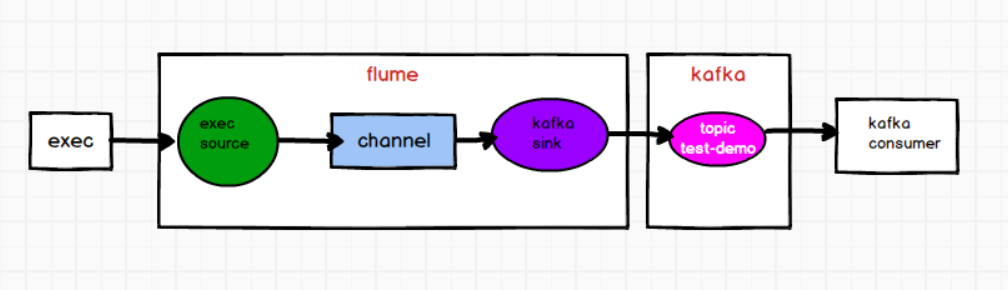
1)flume的配置文件
在hadoop102上创建flume的配置文件
# define
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/module/testdata/3.txt
# sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
#kafka的broker主机和端口
a1.sinks.k1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
#kafka sink发送数据的topic
a1.sinks.k1.kafka.topic = test-demo
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
# channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# bind
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2)启动 zk、kafka集群
3)创建 test-demo 主题
bin/kafka-topics.sh --create --bootstrap-server hadoop102:9092 --topic test-demo --partitions 2 --replication-factor 2
4)启动 kafka consumer 去消费 test-demo 主题
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic test-demo
aaa
5)启动 flume,并且往 3.txt 中追加数据
bin/flume-ng agent -c conf/ -f job/flume-kafka/flume-exec-kafka.conf -n a1
echo hello >> /opt/module/testdata/3.txt
6)观察 kafka consumer 的消费情况
二.自定义interceptor(使用kafka sink)
需求:flume监控 exec 文件的追加数据,将flume采集的数据按照不同的类型输入到不同的topic中
将日志数据中带有的 hello 的,输入到kafka的 first 主题中,
将日志数据中带有 good 的,输入到kafka的 second 主题中,
其他的数据输入到kafka的 third 主题中
需求分析
通过自定义 flume 的拦截器,往 header 增加 topic 信息 ,配置文件中 kafka sink 增加 topic 配置,实现将数据按照指定 topic 发送。
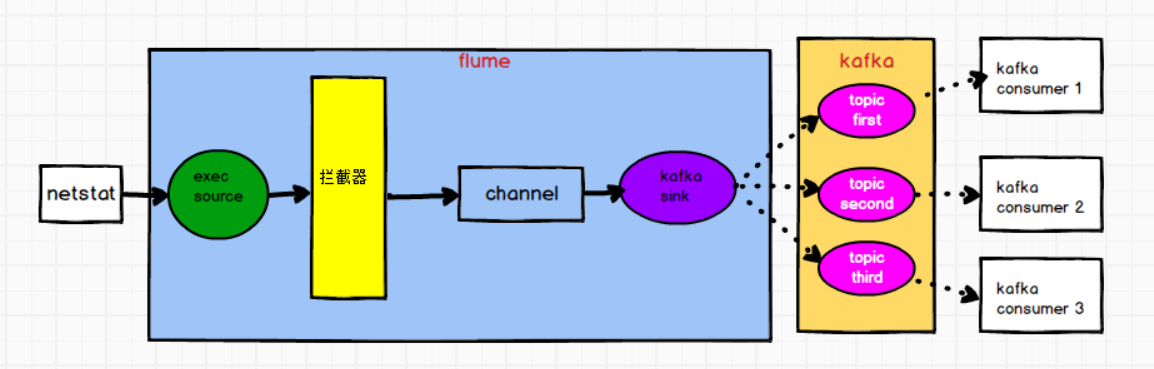
1)自定义 flume 拦截器
创建工程,pom依赖
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
自定义拦截器类,并打包上传至/opt/module/flume/lib包下
package com.bigdata.intercepter;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
/**
* @description: TODO 自定义flume拦截器
* @author: HaoWu
* @create: 2020/7/7 20:32
*/
public class FlumeKafkaInterceptorDemo implements Interceptor {
private List<Event> events;
//初始化
@Override
public void initialize() {
events = new ArrayList<>();
}
@Override
public Event intercept(Event event) {
// 获取event的header
Map<String, String> header = event.getHeaders();
// 获取event的boby
String body = new String(event.getBody());
// 根据body中的数据设置header
if (body.contains("hello")) {
header.put("topic", "first");
} else if (body.contains("good")) {
header.put("topic", "second");
}
return event;
}
@Override
public List<Event> intercept(List<Event> events) {
// 对每次批数据进来清空events
events.clear();
// 循环处理单个event
for (Event event : events) {
events.add(intercept(event));
}
return events;
}
@Override
public void close() {
}
// 静态内部类创建自定义拦截器对象
public static class Builder implements Interceptor.Builder{
@Override
public Interceptor build() {
return new FlumeKafkaInterceptorDemo();
}
@Override
public void configure(Context context) {
}
}
}
2)编写 flume 的配置文件
flume-netstat-kafka.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
#Interceptor
a1.sources.r1.interceptors = i1
#自定义拦截器全类名+$Builder
a1.sources.r1.interceptors.i1.type = com.bigdata.intercepter.FlumeKafkaInterceptorDemo$Builder
# Describe the sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
#默认发往的topic
a1.sinks.k1.kafka.topic = third
a1.sinks.k1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
# # Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
3)创建topic
在kafka中创建 first , second , third 这3个topic
[hadoop@hadoop102 kafka]$ bin/kafka-topics.sh --list --bootstrap-server hadoop102:9092
__consumer_offsets
first
second
test-demo
third
4)启动各组件
启动3个 kafka consumer 分别消费 first , second , third 中的数据
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic second
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic third
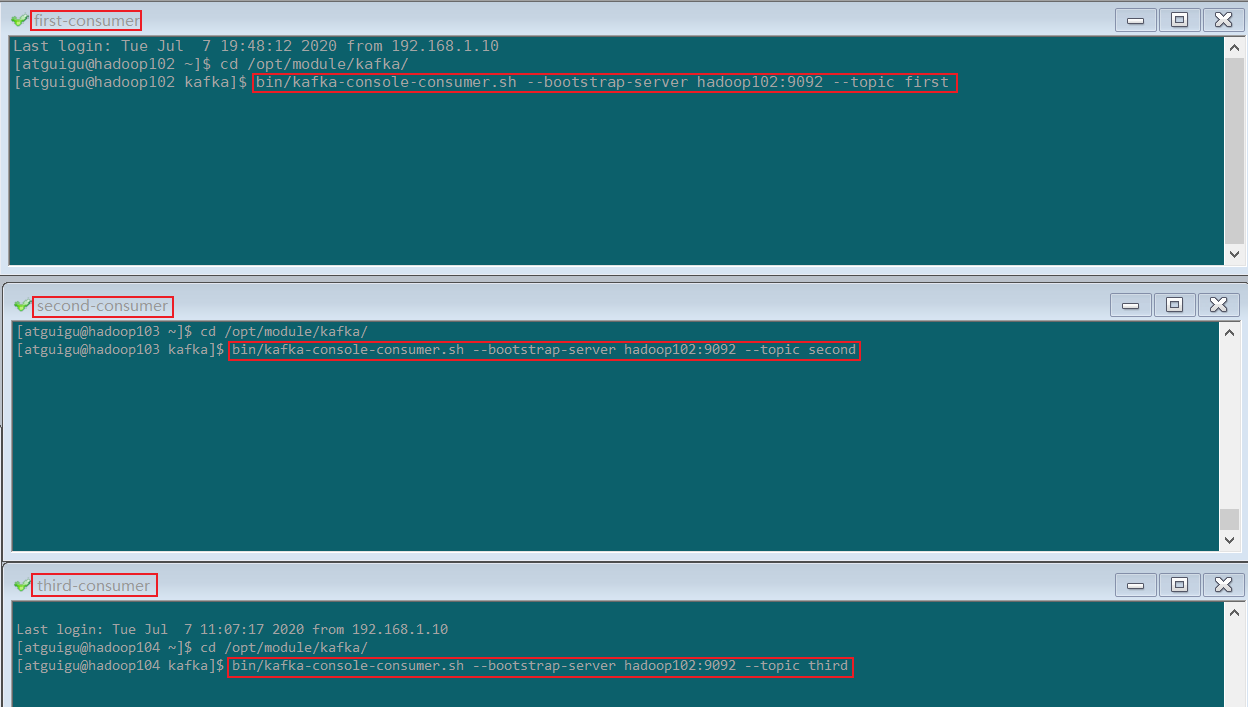
5)启动 flume,通过netstat发送数据到flume
bin/flume-ng agent -c conf/ -f job/flume-kafka/flume-netstat-kafka.conf -n a1
nc localhost 44444
6)观察消费者的消费情况
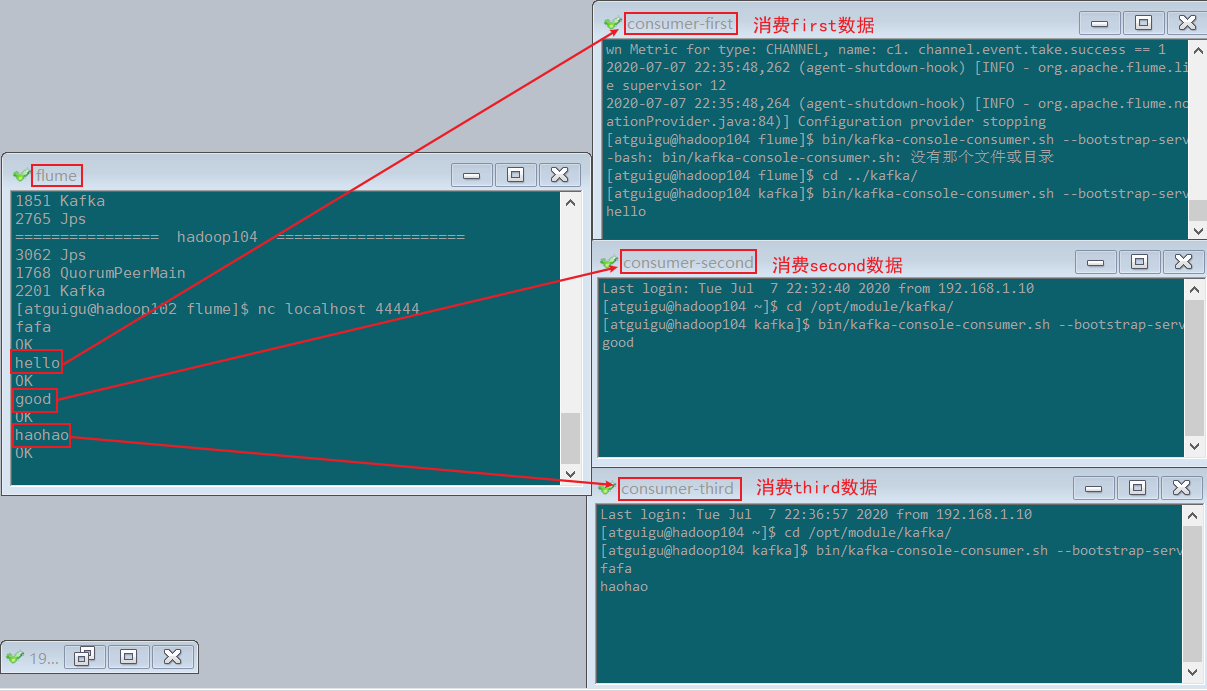
三.自定义interceptor(使用kafka channel)
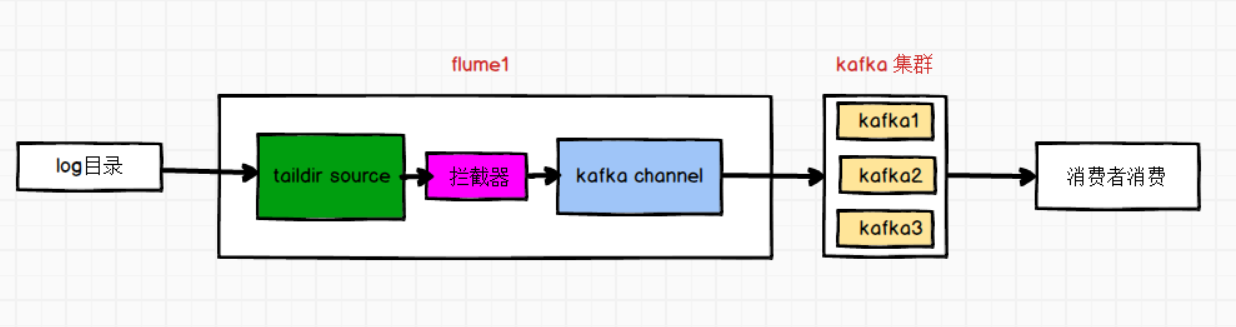
需求:使用taildir source监控/opt/module/applog/log文件夹下的文件,使用拦截器过滤非json的数据,使用kafka channel对接 kafka,将数据发往指定topic。
需求分析
使用kafka channel不需要sink
1)自定义拦截器
创建maven工程
pom文件
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
编写拦截器类:ETLInterceptor.java
package com.bigdata;
import com.alibaba.fastjson.JSON;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.util.Iterator;
import java.util.List;
/**
* @description: TODO 自定义拦截器,简单的ETL清洗
* @author: HaoWu
* @create: 2020/7/10 18:14
*/
public class ETLInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
String s = new String(event.getBody());
try {
JSON.toJSON(s);
return event;
} catch (Exception e) {
return null;
}
}
@Override
public List<Event> intercept(List<Event> events) {
Iterator<Event> iterator = events.iterator();
while (iterator.hasNext()){
Event e = iterator.next();
if(e==null){
iterator.remove();
}
}
return events;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder{
@Override
public Interceptor build() {
return new ETLInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
打包,将有依赖的包上传到%Flume_HOME%/lib目录下
2)flume配置
bigdata-applog-kafka.conf
#描述agent
a1.sources = r1
a1.channels = c1
#描述source
a1.sources.r1.type = TAILDIR
a1.sources.r1.positionFile = /opt/module/flume/taildir_position.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/module/applog/log/app.*
#拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.bigdata.ETLInterceptor$Builder
#描述channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.channels.c1.kafka.topic = applog
a1.channels.c1.parseAsFlumeEvent = false
#关联source->channel->sink
a1.sources.r1.channels = c1
3)启动各组件
启动zookeeper、kafka-->启动消费者消费applog主题-->启动flume-->观察消费者
#消费者消费applog
kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic applog --from-beginning
#启动flume
bin/flume-ng agent -n a1 -c conf/ -f job/bigdata-applog-kafka.conf
consumer消费到数据
Flume对接Kafka的更多相关文章
- 基于Flume+LOG4J+Kafka的日志采集架构方案
本文将会介绍如何使用 Flume.log4j.Kafka进行规范的日志采集. Flume 基本概念 Flume是一个完善.强大的日志采集工具,关于它的配置,在网上有很多现成的例子和资料,这里仅做简单说 ...
- Flume+LOG4J+Kafka
基于Flume+LOG4J+Kafka的日志采集架构方案 本文将会介绍如何使用 Flume.log4j.Kafka进行规范的日志采集. Flume 基本概念 Flume是一个完善.强大的日志采集工具, ...
- 大数据平台架构(flume+kafka+hbase+ELK+storm+redis+mysql)
上次实现了flume+kafka+hbase+ELK:http://www.cnblogs.com/super-d2/p/5486739.html 这次我们可以加上storm: storm-0.9.5 ...
- Kafka实战-Flume到Kafka
1.概述 前面给大家介绍了整个Kafka项目的开发流程,今天给大家分享Kafka如何获取数据源,即Kafka生产数据.下面是今天要分享的目录: 数据来源 Flume到Kafka 数据源加载 预览 下面 ...
- flume+kafka+hbase+ELK
一.架构方案如下图: 二.各个组件的安装方案如下: 1).zookeeper+kafka http://www.cnblogs.com/super-d2/p/4534323.html 2)hbase ...
- flume到kafka和hbase配置
# Flume test file# Listens via Avro RPC on port 41414 and dumps data received to the logagent.channe ...
- flume从kafka中读取数据
a1.sources = r1 a1.sinks = k1 a1.channels = c1 #使用内置kafka source a1.sources.r1.type = org.apache.flu ...
- flume整合kafka
# Please paste flume.conf here. Example: # Sources, channels, and sinks are defined per # agent name ...
- spark streaming 对接kafka记录
spark streaming 对接kafka 有两种方式: 参考: http://group.jobbole.com/15559/ http://blog.csdn.net/kwu_ganymede ...
随机推荐
- LoadRunner12回放与录制
系统版本 本人的操作系统是win10 版本是loadrunner12. 开启loadrunner自带的机票预订服务器 找到loadrunner自带的机票预订测试服务器下图中点击启动 如下图所示代表启动 ...
- pip 常用命令小结
pip 常用命令小结 pip这个工具我们经常会用到,毕竟python 是一门以第三方库庞大而著名的编程语言,所以我们总会用pip 安装一些依赖库,当然这只是pip 最常用的一个命令,下面就来介绍一下 ...
- [python]pytest实现WEB UI自动化
前言:其实这篇写的是pytest的测试框架运用,实现自动化和https://www.cnblogs.com/Jack-cx/p/9357658.html 原理一致 1.为啥不用unittest Pyt ...
- 大一C语言学习笔记(2)---快捷键篇
大家好,博主呢,是一位刚刚步入大一的软件工程专业的大学生,之所以写博客,是想要与同样刚刚接触程序员一行的朋友们一起讨论,进步,在这里记录我的一些学习笔记及心得,希望通过这些点点滴滴的努力,可以让我们离 ...
- 跟着老猫来搞GO-容器(1)
前期回顾 前面的一章主要和大家分享了GO语言的函数的定义,以及GO语言中的指针的简单用法,那么本章,老猫就和大家一起来学习一下GO语言中的容器. 数组 数组的定义 说到容器,大家有编程经验的肯定第一个 ...
- 菜鸡的Java笔记 - java 线程的同步与死锁 (同步 synchronization,死锁 deadlock)
线程的同步与死锁 (同步 synchronization,死锁 deadlock) 多线程的操作方法 1.线程同步的产生与解决 2.死锁的问题 ...
- php 数组(2)
数组排序算法 冒泡排序,是一种计算机科学领域的较简单的排序算法.它重复地访问要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们减缓过来.走访数列的工作室重复的进行直到没有再需要交换,也就是说该 ...
- dart系列之:dart中的异步编程
目录 简介 为什么要用异步编程 怎么使用 Future 异步异常处理 在同步函数中调用异步函数 总结 简介 熟悉javascript的朋友应该知道,在ES6中引入了await和async的语法,可以方 ...
- Dapr-状态管理
前言: 前一篇对Dapr的服务调用方式进行了解,本篇继续对状态管理进行了解. 一.状态管理-解决的问题 在分布式应用程序中跟踪状态存在一下问题: 应用程序可能需要不同类型的数据存储. 访问和更新数据时 ...
- ☕【Java深层系列】「技术盲区」让我们一起完全吃透针对于时间和日期相关的API指南
技术简介 java中的日期处理一直是个问题,没有很好的方式去处理,所以才有第三方框架的位置比如joda.文章主要对java日期处理的详解,用1.8可以不用joda. 时间概念 首先我们对一些基本的概念 ...