Redis中的布隆过滤器及其应用
什么是布隆过滤器
布隆过滤器(Bloom Filter)是由Howard Bloom在1970年提出的一种比较巧妙的概率型数据结构,它可以告诉你某种东西一定不存在或者可能存在。当布隆过滤器说,某种东西存在时,这种东西可能不存在;当布隆过滤器说,某种东西不存在时,那么这种东西一定不存在。
布隆过滤器相对于Set、Map 等数据结构来说,它可以更高效地插入和查询,并且占用空间更少,它也有缺点,就是判断某种东西是否存在时,可能会被误判。但是只要参数设置的合理,它的精确度也可以控制的相对精确,只会有小小的误判概率。
Redis中布隆过滤器
之前的布隆过滤器可以使用Redis中的位图操作实现,直到Redis4.0版本提供了插件功能,Redis官方提供的布隆过滤器才正式登场。布隆过滤器作为一个插件加载到Redis Server中,就会给Redis提供了强大的布隆去重功能。
布隆过滤器的基本使用
在Redis中,布隆过滤器有两个基本命令,分别是:
bf.add:添加元素到布隆过滤器中,类似于集合的sadd命令,不过bf.add命令只能一次添加一个元素,如果想一次添加多个元素,可以使用bf.madd命令。bf.exists:判断某个元素是否在过滤器中,类似于集合的sismember命令,不过bf.exists命令只能一次查询一个元素,如果想一次查询多个元素,可以使用bf.mexists命令。
比如:
> bf.add one-more-filter fans1
(integer) 1
> bf.add one-more-filter fans2
(integer) 1
> bf.add one-more-filter fans3
(integer) 1
> bf.exists one-more-filter fans1
(integer) 1
> bf.exists one-more-filter fans2
(integer) 1
> bf.exists one-more-filter fans3
(integer) 1
> bf.exists one-more-filter fans4
(integer) 0
> bf.madd one-more-filter fans4 fans5 fans6
1) (integer) 1
2) (integer) 1
3) (integer) 1
> bf.mexists one-more-filter fans4 fans5 fans6 fans7
1) (integer) 1
2) (integer) 1
3) (integer) 1
4) (integer) 0
上面的例子中,没有发现误判的情况,是因为元素数量比较少。当元素比较多时,可能就会发生误判,怎么才能减少误判呢?
布隆过滤器的高级使用
上面的例子中使用的布隆过滤器只是默认参数的布隆过滤器,它在我们第一次使用bf.add命令时自动创建的。Redis还提供了自定义参数的布隆过滤器,想要尽量减少布隆过滤器的误判,就要设置合理的参数。
在使用bf.add命令添加元素之前,使用bf.reserve命令创建一个自定义的布隆过滤器。bf.reserve命令有三个参数,分别是:
key:键error_rate:期望错误率,期望错误率越低,需要的空间就越大。capacity:初始容量,当实际元素的数量超过这个初始化容量时,误判率上升。
比如:
> bf.reserve one-more-filter 0.0001 1000000
OK
如果对应的key已经存在时,在执行bf.reserve命令就会报错。如果不使用bf.reserve命令创建,而是使用Redis自动创建的布隆过滤器,默认的error_rate是 0.01,capacity是 100。
布隆过滤器的error_rate越小,需要的存储空间就越大,对于不需要过于精确的场景,error_rate设置稍大一点也可以。布隆过滤器的capacity设置的过大,会浪费存储空间,设置的过小,就会影响准确率,所以在使用之前一定要尽可能地精确估计好元素数量,还需要加上一定的冗余空间以避免实际元素可能会意外高出设置值很多。总之,error_rate和 capacity都需要设置一个合适的数值。
布隆过滤器的原理简介
了解了布隆过滤器的使用,我们再来介绍一下布隆过滤器的原理,做到“知其然,知其所以然”。
Redis中布隆过滤器的数据结构就是一个很大的位数组和几个不一样的无偏哈希函数(能把元素的哈希值算得比较平均,能让元素被哈希到位数组中的位置比较随机)。如下图,A、B、C就是三个这样的哈希函数,分别对“OneMoreStudy”和“万猫学社”这两个元素进行哈希,位数组的对应位置则被设置为1: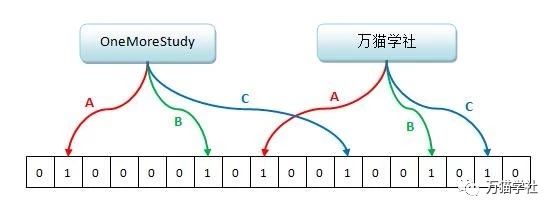
向布隆过滤器中添加元素时,会使用多个无偏哈希函数对元素进行哈希,算出一个整数索引值,然后对位数组长度进行取模运算得到一个位置,每个无偏哈希函数都会得到一个不同的位置。再把位数组的这几个位置都设置为1,这就完成了bf.add命令的操作。
向布隆过滤器查询元素是否存在时,和添加元素一样,也会把哈希的几个位置算出来,然后看看位数组中对应的几个位置是否都为1,只要有一个位为0,那么就说明布隆过滤器里不存在这个元素。如果这几个位置都为1,并不能完全说明这个元素就一定存在其中,有可能这些位置为1是因为其他元素的存在,这就是布隆过滤器会出现误判的原因。
布隆过滤器的应用
解决缓存穿透的问题
一般情况下,先查询缓存是否有该条数据,缓存中没有时,再查询数据库。当数据库也不存在该条数据时,每次查询都要访问数据库,这就是缓存穿透。缓存穿透带来的问题是,当有大量请求查询数据库不存在的数据时,就会给数据库带来压力,甚至会拖垮数据库。
可以使用布隆过滤器解决缓存穿透的问题,把已存在数据的key存在布隆过滤器中。当有新的请求时,先到布隆过滤器中查询是否存在,如果不存在该条数据直接返回;如果存在该条数据再查询缓存查询数据库。
黑名单校验
发现存在黑名单中的,就执行特定操作。比如:识别垃圾邮件,只要是邮箱在黑名单中的邮件,就识别为垃圾邮件。假设黑名单的数量是数以亿计的,存放起来就是非常耗费存储空间的,布隆过滤器则是一个较好的解决方案。把所有黑名单都放在布隆过滤器中,再收到邮件时,判断邮件地址是否在布隆过滤器中即可。
Redis中的布隆过滤器及其应用的更多相关文章
- 详细解析Redis中的布隆过滤器及其应用
欢迎关注微信公众号:万猫学社,每周一分享Java技术干货. 什么是布隆过滤器 布隆过滤器(Bloom Filter)是由Howard Bloom在1970年提出的一种比较巧妙的概率型数据结构,它可以告 ...
- 基于Redis扩展模块的布隆过滤器使用
什么是布隆过滤器?它实际上是一个很长的二进制向量和一系列随机映射函数.把一个目标元素通过多个hash函数的计算,将多个随机计算出的结果映射到不同的二进制向量的位中,以此来间接标记一个元素是否存在于一个 ...
- Redis()- 布隆过滤器
一.布隆过滤器 布隆过滤器:一种数据结构.由二进制数组(很长的二进制向量)组成的.布隆过滤器可以用于检索一个元素是否在一个集合中.它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识 ...
- Golang中的布隆过滤器
目录 1. 布隆过滤器的概念 2. 布隆过滤器应用场景 3. 布隆过滤器工作原理 4. 布隆过滤器的优缺点 5. 布隆过滤器注意事项 6. Go实现布隆过滤器 1. 布隆过滤器的概念 布隆过滤器(Bl ...
- 一道腾讯面试题:如何快速判断某 URL 是否在 20 亿的网址 URL 集合中?布隆过滤器
何为布隆过滤器 还是以上面的例子为例: 判断逻辑: 多次哈希: Guava的BloomFilter 创建BloomFilter 最终还是调用: 使用: 算法特点 使用场景 假设遇到这样一个问题:一个网 ...
- 09 redis中布隆过滤器的使用
我们在使用新闻客户端看新闻时,它会给我们不停地推荐新的内容,它每次推荐时要去重,去掉那些已经看过的内容.问题来了,新闻客户端推荐系统如何实现推送去重的? 会想到服务器记录了用户看过的所有历史记录,当推 ...
- 浅谈redis的HyperLogLog与布隆过滤器
首先,HyperLogLog与布隆过滤器都是针对大数据统计存储应用场景下的知名算法. HyperLogLog是在大数据的情况下关于数据基数的空间复杂度优化实现,布隆过滤器是在大数据情况下关于检索一个元 ...
- 布隆过滤器(Bloom Filter)简要介绍
一种节省空间的概率数据结构 布隆过滤器可以理解为一个不怎么精确的 set 结构,当你使用它的 contains 方法判断某个对象是否存在时,它可能会误判.但是布隆过滤器也不是特别不精确,只要参数设置的 ...
- 布隆过滤器(Bloom Filter)原理以及应用
应用场景 主要是解决大规模数据下不需要精确过滤的场景,如检查垃圾邮件地址,爬虫URL地址去重,解决缓存穿透问题等. 布隆过滤器(Bloom Filter)是1970年由布隆提出的.它实际上是一个很长的 ...
随机推荐
- 微信引流的方式 PC控制手机的方式
http://www.yunjing100.cn/ 云鲸一百 小萝卜 http://www.xiaoluobei.com/
- 什么是FOC
https://zhidao.baidu.com/question/354536332.html FOC简述 磁场定向控制系统(FOC)又称为矢量控制系统,他是选择电机某一旋转磁场轴作为特定的同步旋转 ...
- CSS(2)盒子模型、定位浮动
盒子模型 盒子模型:一个盒子中主要的属性就5个.width与height.padding.border.margin.盒子模型标准有两种为标准盒模型和IE盒模型.学习上以标准盒子模型为主 width和 ...
- MySQL中InnoDB存储引擎的实现和运行原理
InnoDB 存储引擎作为我们最常用到的存储引擎之一,充分熟悉它的的实现和运行原理,有助于我们更好地创建和维护数据库表. InnoDB 体系架构 InnoDB 主要包括了: 内存池.后台线程以及存储文 ...
- Redis持久化锦囊在手,再也不会担心数据丢失了
大家好,我是小羽. Redis 的读写都是在内存中进行的,所以它的性能高.而当我们的服务器断开或者重启的时候,数据就会消失,那么我们该怎么解决这个问题呢? 其实 Redis 已经为我们提供了一种持久化 ...
- 快速导入GitHub上面的公钥
有时候新装了一台linux机器, 又要找公钥导进去, 或者在自己电脑上执行ssh-copy-id, 有时候手边没有电脑就比较麻烦, 我们可以将GitHub上配置的公钥导入到机器里 首先包装GitHub ...
- AI推理与Compiler
AI推理与Compiler AI芯片编译器能加深对AI的理解, AI芯片编译器不光涉及编译器知识,还涉及AI芯片架构和并行计算如OpenCL/Cuda等.如果从深度学习平台获得IR输入,还需要了解深度 ...
- Visual SLAM
Visual SLAM 追求直接SLAM技术,而不是使用关键点,直接操作图像强度的跟踪和映射. 作为直接方法,LSD-SLAM使用图像中的所有信息,包括边缘,而基于关键点的方法只能在拐角处使用小块.这 ...
- CUDA运行时 Runtime(二)
CUDA运行时 Runtime(二) 一. 概述 下面的代码示例是利用共享内存的矩阵乘法的实现.在这个实现中,每个线程块负责计算C的一个方子矩阵C sub,块内的每个线程负责计算Csub的一个元素.如 ...
- Python分析离散心率信号(下)
Python分析离散心率信号(下) 如何使用动态阈值,信号过滤和离群值检测来改善峰值检测. 一些理论和背景 到目前为止,一直在研究如何分析心率信号并从中提取最广泛使用的时域和频域度量.但是,使用的信号 ...