信息论估计工具jidt基本使用
JIDT基本介绍
- JIDT是 Java Information Dynamics Toolkit的简称,用于研究复杂系统中信息论相关度量的计算,它是一个基于java的开源工具库,也可以在Matlab、Octave、Python、R、Julia和Clojure中使用;
- JIDT提供了如下计算工具:
- 信息熵、互信息、转移熵
- 条件互信息、条件转移熵
- 多变量互信息和多变量转移熵
- 信息存储
- JIDT同时支持离散型数据和连续型数据
- JIDT提供多种估计算子
主页:https://github.com/jlizier/jidt
安装
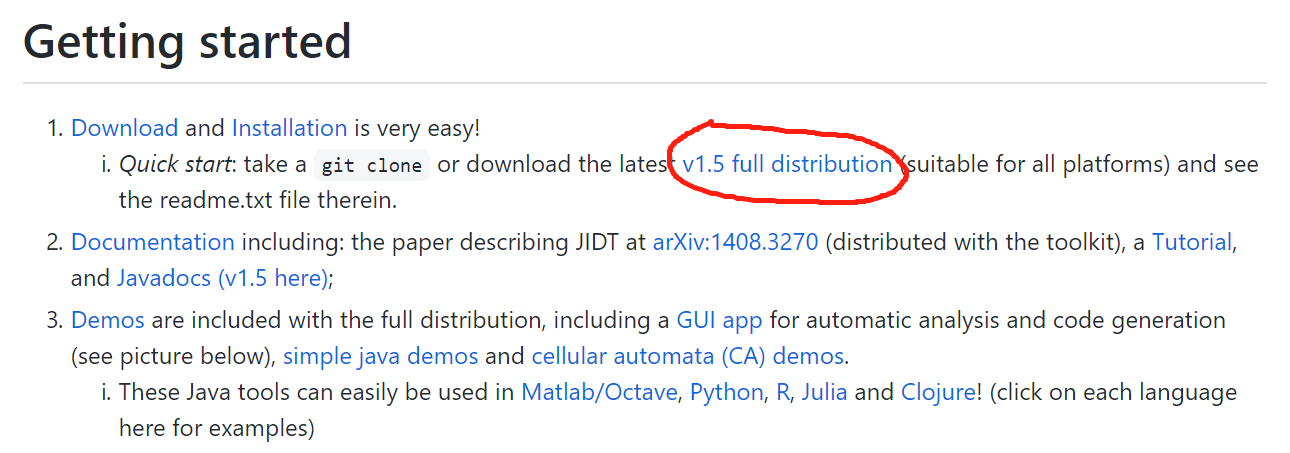
第一步:下载编译好的版本,图中的
v1.5 full distribution,然后解压放到合适的目录,如~/software/infodynamics,我们只需要里面的infodynamics.jar文件。第二步:熟悉Java的同学应该知道这个jar文件是个什么东东,这就是所有信息论度量计算所需要的函数哈,所以现在需要安装配置Java环境,这里不再赘述。
第三步:由于需要在python环境中使用java计算,所以需要安装
jpype,安装命令:pip install jpype1
配置好环境之后,在使用jidt之前加入如下一段代码:
import jpypefrom jpype import *try:jarLocation = "~/software/infodynamics/infodynamics.jar"jpype.startJVM(jpype.getDefaultJVMPath(), "-ea", "-Djava.class.path=" + jarLocation)except:print("JVM has already started !")
注: 需要把jarLocation换成自己的路径!
接下来就能够调用jidt中各种封装好的信息论估计算子了:
转移熵估计
转移熵估计作者提供了多种估计方法:
- TransferEntropyCalculator
- TransferEntropyCalculatorDiscrete
- TransferEntropyCalculatorGaussian
- TransferEntropyCalculatorKernel
- TransferEntropyCalculatorKernelPlain
- TransferEntropyCalculatorKernelPlainIterators
- TransferEntropyCalculatorKernelSeparate
- TransferEntropyCalculatorKraskov
- TransferEntropyCalculatorMultiVariate
- TransferEntropyCalculatorMultiVariateGaussian
- TransferEntropyCalculatorMultiVariateKernel
- TransferEntropyCalculatorMultiVariateKraskov
- TransferEntropyCalculatorMultiVariateSingleObservationsKernel
- TransferEntropyCalculatorMultiVariateViaCondMutualInfo
- TransferEntropyCalculatorSymbolic
- TransferEntropyCalculatorViaCondMutualInfo
- TransferEntropyCommon
- TransferEntropyKernelCounts
例:TransferEntropyCalculatorMultiVariateKraskov
我们以这个多变量转移熵的ksg估计算子为例来介绍如何使用jidt估计转移熵,首先使用如下代码打开JVM:
import jpypefrom jpype import *try:jarLocation = "~/software/infodynamics/infodynamics.jar"jpype.startJVM(jpype.getDefaultJVMPath(), "-ea", "-Djava.class.path=" + jarLocation)except:print("JVM has already started !")
然后安装如下方式,实例化一个计算子:
calcClass = JPackage("infodynamics.measures.continuous.kraskov").TransferEntropyCalculatorMultiVariateKraskovcalc = calcClass()
对于其他的估计子,只须替换上面的相应名称即可,具体名称可以查看官方文档,然后我们就可以用这个calc
来搞一些具体计算了哈,先生成一些数据:
start, end = "1996", "1996"columns = ["Electric_field"]x = data.loc[start:end, columns].interpolate().valuesy = data.loc[start:end, ["Dst"]].interpolate().valuesfig, axs = plt.subplots(2, 1, figsize=(6, 4))axs[0].plot(x, label="Electric_field", color="blue")axs[0].legend()axs[1].plot(y, label="Dst", color="red")axs[1].legend()plt.show()
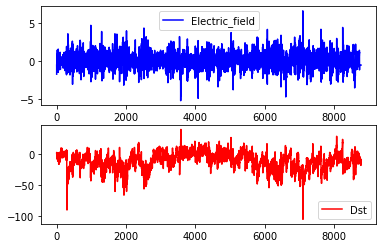
这里使用的是1996年卫星观测的行星际电场数据和磁暴指数Dst数据,注意x和y都是二维矩阵:x.shape=(8784,1); y.shape=(8784,1)
然后设置一些calc的参数:
calc.setProperty("k_HISTORY", str(k_HISTORY))calc.setProperty("k_TAU", str(k_TAU))calc.setProperty("l_HISTORY", str(l_HISTORY))calc.setProperty("l_TAU", str(l_TAU))calc.setProperty("DELAY", str(DELAY))
注: 这里的DELAY是平常计算转移熵所设置的延迟\(\tau\)
设置好参数之后就可以直接计算了:
m,n = 1,1calc.initialise(m,n)calc.setObservations(JArray(JDouble, 2)(x), JArray(JDouble, 2)(y))result = calc.computeAverageLocalOfObservations()
由于x和y都是一维变量,所以初始化的时候m和n都设置成1即可,JArray(JDouble, 2)(x)是通过jpype将python中的矩阵转化成java中的数据类型,result即为计算出的转移熵。
如需评估所计算转移熵的重要性,只需要进一步计算p值即可:
sig_num = 100measDist = calc.computeSignificance(self.sig_num)mean = (measDist.getMeanOfDistribution(),)std = (measDist.getStdOfDistribution(),)pVal = measDist.pValue
这里使用的是替代数据检验法,生成sig_num条与x尺寸相同的随机数据,然后计算到y的转移熵,计算sig_num个统计值的均值、标准差以及相应的p值即可评估上面计算得到的result是否可信。
为避免每次都需要这么设置,可以将上述过程封装成一个类,具体如下:
import os, sysimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom pathlib import PathPath.ls = lambda x: list(x.iterdir())from tqdm import tqdm"""多变量转移熵计算"""import os, sysimport numpy as npimport pandas as pdimport jpypefrom jpype import *# mUtils = JPackage("infodynamics.utils").MatrixUtilsclass TransferEntropyCalculatorMultiVariateKraskov:"""Description:"""def __init__(self,source=None,destination=None,sourceDimensions=2,destDimensions=2,k_HISTORY=1,k_TAU=1,l_HISTORY=1,l_TAU=1,DELAY=1,k=4,NOISE_LEVEL_TO_ADD=1e-8,ALG_NUM=1,cal_sig=False,sig_num=100,):self.source = sourceself.destination = destinationself.sourceDimensions = sourceDimensionsself.destDimensions = destDimensionsself.k_HISTORY = k_HISTORYself.k_TAU = k_TAUself.l_HISTORY = l_HISTORYself.l_TAU = l_TAUself.DELAY = DELAYself.k = kself.cal_sig = cal_sigself.sig_num = sig_numself.NOISE_LEVEL_TO_ADD = NOISE_LEVEL_TO_ADDself.ALG_NUM = ALG_NUMdef __call__(self, source, destination, tau, m=1, n=1):self.source = sourceself.destination = destinationself.sourceDimensions = np.min(source.shape)self.destDimensions = np.min(destination.shape)self.DELAY = taucalcClass = JPackage("infodynamics.measures.continuous.kraskov").TransferEntropyCalculatorMultiVariateKraskovcalc = calcClass()calc.setProperty("sourceDimensions", str(self.sourceDimensions))calc.setProperty("destDimensions", str(self.destDimensions))calc.setProperty("k_HISTORY", str(self.k_HISTORY))calc.setProperty("k_TAU", str(self.k_TAU))calc.setProperty("l_HISTORY", str(self.l_HISTORY))calc.setProperty("l_TAU", str(self.l_TAU))calc.setProperty("DELAY", str(self.DELAY))calc.setProperty("k", str(self.k))calc.setProperty("NOISE_LEVEL_TO_ADD", str(self.NOISE_LEVEL_TO_ADD))calc.setProperty("ALG_NUM", str(self.ALG_NUM))calc.initialise(m,n)self.calc = calcself.calc.setObservations(JArray(JDouble, 2)(source), JArray(JDouble, 2)(destination))result = self.calc.computeAverageLocalOfObservations()if not self.cal_sig:return resultelse:measDist = self.calc.computeSignificance(self.sig_num)mean = (measDist.getMeanOfDistribution(),)std = (measDist.getStdOfDistribution(),)pVal = measDist.pValuereturn result, [mean, std, pVal]# estimator_ksg = TransferEntropyCalculatorMultiVariateKraskov()
然后计算就很简单了:
# 实例化一个估计子estimator_ksg = TransferEntropyCalculatorMultiVariateKraskov()# 生成测试数据start, end = "1996", "1996"columns = ["Electric_field"]x = data.loc[start:end, columns].interpolate().valuesy = data.loc[start:end, ["Dst"]].interpolate().valuesfig, axs = plt.subplots(2, 1, figsize=(6, 4))axs[0].plot(x, label="Electric_field", color="blue")axs[0].legend()axs[1].plot(y, label="Dst", color="red")axs[1].legend()plt.show()# 计算转移熵结果,并绘制图像result = []taus = 168for tau in tqdm(range(taus)):result.append(estimator_ksg(source=x, destination=y, tau=tau))plt.figure(figsize=(8, 3))plt.plot(range(taus), result)
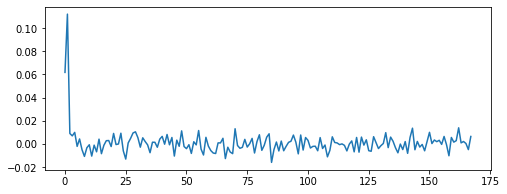
大概几秒之后就计算完毕了,速度还是非常可以的,计算结果如下:
今天的部分到这里就结束了,后期作者会在介绍一下其他方法和信息论度量的计算,并将完整代码总结发布到github上面,敬请关注。
信息论估计工具jidt基本使用的更多相关文章
- 【转载】FPGA功耗的那些事儿
在项目设计初期,基于硬件电源模块的设计考虑,对FPGA设计中的功耗估计是必不可少的. 笔者经历过一个项目,整个系统的功耗达到了100w,而单片FPGA的功耗估计得到为20w左右, 有点过高了,功耗过高 ...
- FPGA功耗那些事儿(转载)
在项目设计初期,基于硬件电源模块的设计考虑,对FPGA设计中的功耗估计是必不可少的.笔者经历过一个项目,整个系统的功耗达到了100w,而单片FPGA的功耗估计得到为20w左右,有点过高了,功耗过高则会 ...
- MMDetection 使用示例:从入门到出门
前言 最近对目标识别感兴趣,想做一些有趣目标识别项目自己玩耍,本来选择的是 YOLOV5 的,但无奈自己使用 YOLOV5 环境训练模型时,不管训练多少次 mAP 指标总是为 0,而其它 pytorc ...
- 【机器学习】ICA 原理以及相关概率论,信息论知识简介
看完了sparse coding,开始看ICA模型,本来ng的教程上面就只有一个简短的介绍,怎奈自己有强迫症,爱钻牛角尖,于是乎就搜索了一些ICA的介绍文章(都是从百度文库中搜来的),看完之后感觉这个 ...
- dll文件32位64位检测工具以及Windows文件夹SysWow64的坑
自从操作系统升级到64位以后,就要不断的需要面对32位.64位的问题.相信有很多人并不是很清楚32位程序与64位程序的区别,以及Program Files (x86),Program Files的区别 ...
- 10个最好用的HTML/CSS 工具、插件和资料库
大家在使用HTML/CSS开发项目的过程中,有使用过哪些工具,插件和库?下面介绍的10种HTML/CSS工具,插件和资料库,是国外程序员经常用到的. Firebug Lite FirebugLite ...
- 使用Oracle官方巡检工具ORAchk巡检数据库
ORAchk概述 ORAchk是Oracle官方出品的Oracle产品健康检查工具,可以从MOS(My Oracle Support)网站上下载,免费使用.这个工具可以检查Oracle数据库,Gold ...
- 【翻译】Awesome R资源大全中文版来了,全球最火的R工具包一网打尽,超过300+工具,还在等什么?
0.前言 虽然很早就知道R被微软收购,也很早知道R在统计分析处理方面很强大,开始一直没有行动过...直到 直到12月初在微软技术大会,看到我软的工程师演示R的使用,我就震惊了,然后最近在网上到处了解和 ...
- 一篇文章看懂TPCx-BB(大数据基准测试工具)源码
TPCx-BB是大数据基准测试工具,它通过模拟零售商的30个应用场景,执行30个查询来衡量基于Hadoop的大数据系统的包括硬件和软件的性能.其中一些场景还用到了机器学习算法(聚类.线性回归等).为了 ...
随机推荐
- C++知识点案例 笔记-4
1.纯虚函数 2.抽象类 3.内部类 4.运算符重载 5.类的函数重载 6.友元的函数重载 1.纯虚函数 ==纯虚函数== //有时基类中无法给出函数的具体体现,定义纯虚函数可以为派生函数保留一个函数 ...
- LTC3780 工作原理分析
流程分析 当 CV调节 调节顺时针调节CV的时候 接入电路部分的电阻变大 Vosense变小 LTC内部的误差放大器 输出的变大 LTC内部逻辑调节 增大电压 我估计最终电压还是大约800mv左右 可 ...
- 高德Serverless平台建设及实践
导读 高德启动Serverless建设已经有段时间了,目前高德Serverless业务的峰值早已超过十万QPS量级,平台从0到1,QPS从零到超过十万,成为阿里集团内Serverless应用落地规模最 ...
- 使用指定源安装python包
对于经常需要按照那个python包的同学,外网下载比较慢的话,可以使用公司内部的镜像进行安装 eg: pip install django -i http://mirrors.***.com.cn/p ...
- scrapy使用response.body时编码问题
scrapy使用response.body时编码问题 摘要:scrapy使用response.body时编码问题.如果在使用responses.body获取数据时,需要将其编码转换成unicode,即 ...
- Nginx 配置实例-配置动静分离
Nginx 配置实例-配置动静分离 1. 静态资源的创建 2. nginx 动静分离的配置 3. 验证 1. 静态资源的创建 这里使用的静态资源主要为 HTML 静态文件和图片. mkdir -vp ...
- grasshopper | 通过图层引用线条 报错:“ Data conversion failed from Guid to Curve ”的避免方法
需求:通过 LunchBox - > layer reference 电池 可以快速选中图层所在的线条,但是选择的数据流错误 直接选择会报错--"Data conversion fai ...
- 可视化反投射:坍塌尺寸的概率恢复:ICCV9论文解读
可视化反投射:坍塌尺寸的概率恢复:ICCV9论文解读 Visual Deprojection: Probabilistic Recovery of Collapsed Dimensions 论文链接: ...
- 立体显示与BCN双稳态手性向列相
立体显示与BCN双稳态手性向列相 狭缝光栅立体显示 技术介绍: 人的左右眼间距大约是65MM,左右眼透过视差光栅看到不同的视角图像,经大脑融合形成立体视觉. 技术优点: 2D/3D可切换: 低成本: ...
- 用NVIDIA NsightcComputeRoofline分析加速高性能HPC的应用
用NVIDIA NsightcComputeRoofline分析加速高性能HPC的应用 编写高性能的软件不是一件简单的任务.当有了可以编译和运行的代码之后,当您尝试并理解它在可用硬件上的执行情况时,将 ...