【集成学习】:Stacking原理以及Python代码实现
Stacking集成学习在各类机器学习竞赛当中得到了广泛的应用,尤其是在结构化的机器学习竞赛当中表现非常好。今天我们就来介绍下stacking这个在机器学习模型融合当中的大杀器的原理。并在博文的后面附有相关代码实现。
总体来说,stacking集成算法主要是一种基于“标签”的学习,有以下的特点:
用法:模型利用交叉验证,对训练集进行预测,从而实现二次学习
优点:可以结合不同的模型
缺点:增加了时间开销,容易造成过拟合
关键点:模型如何进行交叉训练?
下面我们来看看stacking的具体原理是如何进行实现的,stacking又是如何实现交叉验证和训练的。
一.使用单个机器学习模型进行stacking
第一种stacking的方法,为了方便大家理解,因此只使用一个机器学习模型进行stacking。stacking的方式如下图所示:

我们可以边看图边理解staking过程。我们先看training data,也就是训练数据(训练集)。我们使用同一个机器学习model对训练数据进行了5折交叉验证(当然在实际进行stacking的时候,你也可以使用k折交叉验证,k等于多少都可以,看你自己,一般k=5或者k=10,k=5就是五折交叉验证),也就是每次训练的时候,将训练数据拆分成5份。其中四份用于训练我们的模型,另外剩下的一份将训练好的模型,在这部分上对数据进行预测predict出相应的label。由于使用了5折交叉验证,这样不断训练,一共经过5次交叉验证,我们就产生了模型对当前训练数据进行预测的一列label。而这些label也可以当作我们的新的训练特征,将预测出来的label作为一列新的特征插入到我们的训练数据当中。
插入完成后,将我们新的tranning set再次进行训练,得到我们新,也是最后的model,也就是图中的model6。这样就完成了第一次stacking,对于testing set而言,我们使用model 1/2/3/4/5分别对图中下面所对应的testing data进行预测,然后得到testing set的新的一列feature,或者称之为label。
这样,我们就完成了一次stacking的过程。
然而,我们不仅可以stacking仅仅一次,我们还可以对当前训练出来的模型再次进行stacking,也就是重复刚才的过程,这样我们的训练集又会多出一个新的一列,每stacking一次,数据就会多出一列。但是如果仅仅用一个模型进行stakcing,效果往往没有那么好,因为这样我们的数据和模型并不具备多样性,也就无法从数学上保证我们数据的“独立性”,树模型比如bagging能够达到很好的效果,包括我们的stacking,模型的多样性越大,差异越大,集成之后往往会得到更好的收益,这个在数学上有严格的证明的,可以通过binomial distribution的方法来证明,大家了解即可。
因此这里介绍,如何使用多个机器学习模型进行stacking,这种方法在机器学习竞赛当中也更加常见。
二.使用多个机器模型进行stacking
使用多个机器学习模型进行stacking其实就是每使用一个模型进行训练,就多出一个训练集的feature,也就是将训练集多出一列。如下图所示:
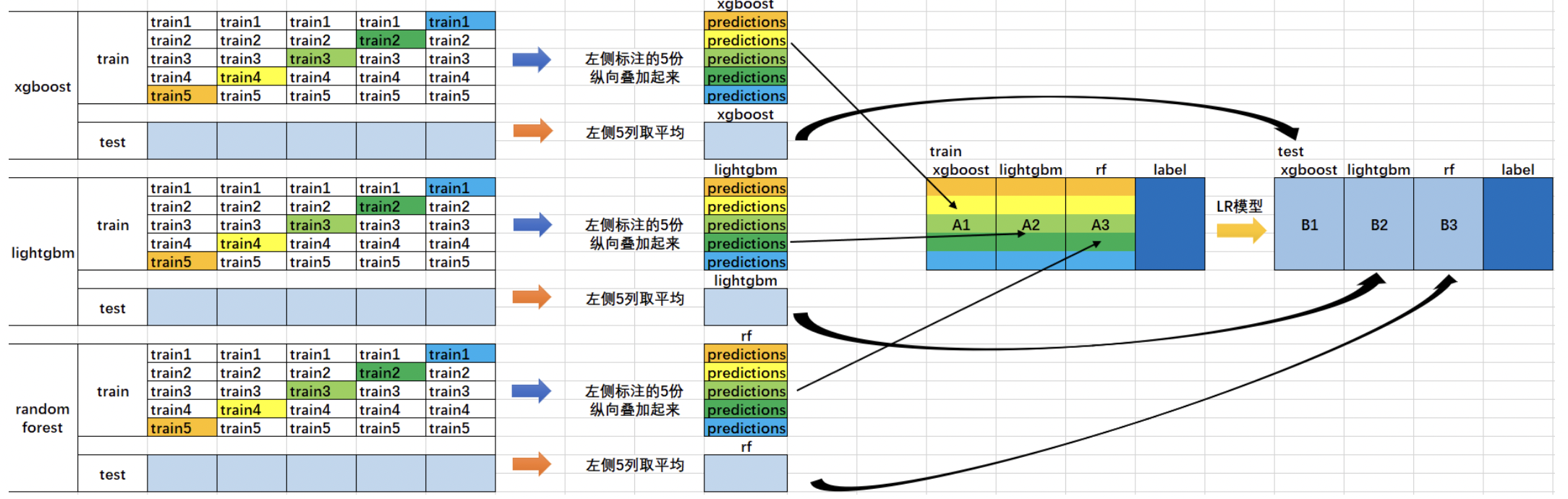
在这张图当中,我们使用了xgboost,lightgbm,random forest分别对同一个数据集做了训练,xgboost训练完后,trainning set多出一列,lightgbm训练完成后,又多出一列random forest训练完成后,又多出一列。因此我们的traning set一共多出了三列。这样我们再用多出这三列的数据重新使用新的机器学习模型进行训练,就可以得到一个更加完美的模型啦!这也就是多个不同机器学习模型进行stacking的原理。同时 ,我们也可以对多个机器学习模型进行多次堆叠,也就是进行多次stakcing的操作。
三.stacking模型代码实现(基本实现)
由于sklearn并没有直接对Stacking的方法,因此我们需要下载mlxtend工具包(pip install mlxtend)
# 1. 简单堆叠3折CV分类
from sklearn import datasets iris = datasets.load_iris()
X, y = iris.data[:, 1:3], iris.target
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import StackingCVClassifier RANDOM_SEED = 42 clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=RANDOM_SEED)
clf3 = GaussianNB()
lr = LogisticRegression() # Starting from v0.16.0, StackingCVRegressor supports
# `random_state` to get deterministic result.
sclf = StackingCVClassifier(classifiers=[clf1, clf2, clf3], # 第一层分类器
meta_classifier=lr, # 第二层分类器,并非表示第二次stacking,而是通过logistic regression对新的训练特征数据进行训练,得到predicted label
random_state=RANDOM_SEED) print('3-fold cross validation:\n') for clf, label in zip([clf1, clf2, clf3, sclf], ['KNN', 'Random Forest', 'Naive Bayes','StackingClassifier']):
scores = cross_val_score(clf, X, y, cv=3, scoring='accuracy')
print("Accuracy: %0.2f (+/- %0.2f) [%s]" % (scores.mean(), scores.std(), label))
输出:
3-fold cross validation: Accuracy: 0.91 (+/- 0.01) [KNN]
Accuracy: 0.95 (+/- 0.01) [Random Forest]
Accuracy: 0.91 (+/- 0.02) [Naive Bayes]
Accuracy: 0.93 (+/- 0.02) [StackingClassifier]
画出决策边界:
# 我们画出决策边界
from mlxtend.plotting import plot_decision_regions
import matplotlib.gridspec as gridspec
import itertools gs = gridspec.GridSpec(2, 2)
fig = plt.figure(figsize=(10,8))
for clf, lab, grd in zip([clf1, clf2, clf3, sclf],
['KNN',
'Random Forest',
'Naive Bayes',
'StackingCVClassifier'],
itertools.product([0, 1], repeat=2)):
clf.fit(X, y)
ax = plt.subplot(gs[grd[0], grd[1]])
fig = plot_decision_regions(X=X, y=y, clf=clf)
plt.title(lab)
plt.show()

如果想要更加清楚地指定,我们的多个机器学习学到的数据输出的概率(假设我们的label为概率),是否会被平均,按照多个模型的平均值来变成我们的训练数据的列(个人不太推荐这么干,因为一旦平均之后,其实就缺失了一些模型差异性的信息和特征,这样在某些情况下反而得不太好的结果)。因此我们使用以下的代码:
# 使用概率作为元特征
clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
lr = LogisticRegression() sclf = StackingCVClassifier(classifiers=[clf1, clf2, clf3],
use_probas=True,
average_probas = False,
meta_classifier=lr,
random_state=42)
#average_probas = False 表示不对概率进行平均 print('3-fold cross validation:\n') for clf, label in zip([clf1, clf2, clf3, sclf],
['KNN',
'Random Forest',
'Naive Bayes',
'StackingClassifier']): scores = cross_val_score(clf, X, y,
cv=3, scoring='accuracy')
print("Accuracy: %0.2f (+/- %0.2f) [%s]"
% (scores.mean(), scores.std(), label))
输出:
3-fold cross validation: Accuracy: 0.91 (+/- 0.01) [KNN]
Accuracy: 0.95 (+/- 0.01) [Random Forest]
Accuracy: 0.91 (+/- 0.02) [Naive Bayes]
Accuracy: 0.95 (+/- 0.02) [StackingClassifier]
四.Stacking配合grid search网格搜索实现超参数调整
# 3. 堆叠5折CV分类与网格搜索(结合网格搜索调参优化)
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
from mlxtend.classifier import StackingCVClassifier # Initializing models clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=RANDOM_SEED)
clf3 = GaussianNB()
lr = LogisticRegression() sclf = StackingCVClassifier(classifiers=[clf1, clf2, clf3],
meta_classifier=lr,
random_state=42) params = {'kneighborsclassifier__n_neighbors': [1, 5],
'randomforestclassifier__n_estimators': [10, 50],
'meta_classifier__C': [0.1, 10.0]} grid = GridSearchCV(estimator=sclf,
param_grid=params,
cv=5,
refit=True)
grid.fit(X, y) cv_keys = ('mean_test_score', 'std_test_score', 'params') for r, _ in enumerate(grid.cv_results_['mean_test_score']):
print("%0.3f +/- %0.2f %r"
% (grid.cv_results_[cv_keys[0]][r],
grid.cv_results_[cv_keys[1]][r] / 2.0,
grid.cv_results_[cv_keys[2]][r])) print('Best parameters: %s' % grid.best_params_)
print('Accuracy: %.2f' % grid.best_score_)
输出:
0.947 +/- 0.03 {'kneighborsclassifier__n_neighbors': 1, 'meta_classifier__C': 0.1, 'randomforestclassifier__n_estimators': 10}
0.933 +/- 0.02 {'kneighborsclassifier__n_neighbors': 1, 'meta_classifier__C': 0.1, 'randomforestclassifier__n_estimators': 50}
0.940 +/- 0.02 {'kneighborsclassifier__n_neighbors': 1, 'meta_classifier__C': 10.0, 'randomforestclassifier__n_estimators': 10}
0.940 +/- 0.02 {'kneighborsclassifier__n_neighbors': 1, 'meta_classifier__C': 10.0, 'randomforestclassifier__n_estimators': 50}
0.953 +/- 0.02 {'kneighborsclassifier__n_neighbors': 5, 'meta_classifier__C': 0.1, 'randomforestclassifier__n_estimators': 10}
0.953 +/- 0.02 {'kneighborsclassifier__n_neighbors': 5, 'meta_classifier__C': 0.1, 'randomforestclassifier__n_estimators': 50}
0.953 +/- 0.02 {'kneighborsclassifier__n_neighbors': 5, 'meta_classifier__C': 10.0, 'randomforestclassifier__n_estimators': 10}
0.953 +/- 0.02 {'kneighborsclassifier__n_neighbors': 5, 'meta_classifier__C': 10.0, 'randomforestclassifier__n_estimators': 50}
Best parameters: {'kneighborsclassifier__n_neighbors': 5, 'meta_classifier__C': 0.1, 'randomforestclassifier__n_estimators': 10}
Accuracy: 0.95
得到最后最好的参数如上。当然如果,你想要更好的搜索参数,可以使用贝叶斯搜索参数,或者随机参数搜索法,对参数进行搜索。
结语:在这篇博文当中,我论述了stacking的原理和python的代码实现,希望大家读完后会有收获。如果觉得看了有收获的同学,请在下方点个赞,推荐一下,谢谢啦!
参考文献:
1.https://github.com/Geeksongs/ensemble-learning/blob/main/CH5-%E9%9B%86%E6%88%90%E5%AD%A6%E4%B9%A0%E4%B9%8Bblending%E4%B8%8Estacking/Stacking.ipynb
2.https://www.cnblogs.com/Christina-Notebook/p/10063146.html
【集成学习】:Stacking原理以及Python代码实现的更多相关文章
- 一文看懂Stacking!(含Python代码)
一文看懂Stacking!(含Python代码) https://mp.weixin.qq.com/s/faQNTGgBZdZyyZscdhjwUQ
- 《机器学习Python实现_10_10_集成学习_xgboost_原理介绍及回归树的简单实现》
一.简介 xgboost在集成学习中占有重要的一席之位,通常在各大竞赛中作为杀器使用,同时它在工业落地上也很方便,目前针对大数据领域也有各种分布式实现版本,比如xgboost4j-spark,xgbo ...
- catboost原理以及Python代码
原论文: http://learningsys.org/nips17/assets/papers/paper_11.pdf catboost原理: One-hot编码可以在预处理阶段或在训练期间 ...
- lightgbm原理以及Python代码
原论文: http://papers.nips.cc/paper/6907-lightgbm-a-highly-efficient-gradient-boosting-decision-tree.pd ...
- MD5( 信息摘要算法)的概念原理及python代码的实现
简述: message-digest algorithm 5(信息-摘要算法).经常说的“MD5加密”,就是它→信息-摘要算法. md5,其实就是一种算法.可以将一个字符串,或文件,或压缩包,执行md ...
- KNN算法原理(python代码实现)
kNN(k-nearest neighbor algorithm)算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性 ...
- 《机器学习Python实现_10_09_集成学习_bagging_stacking原理及实现》
介绍 前面对模型的组合主要用了两种方式: (1)一种是平均/投票: (2)另外一种是加权平均/投票: 所以,我们有时就会陷入纠结,是平均的好,还是加权的好,那如果是加权,权重又该如何分配的好?如果我们 ...
- 深度学习模型stacking模型融合python代码,看了你就会使
话不多说,直接上代码 def stacking_first(train, train_y, test): savepath = './stack_op{}_dt{}_tfidf{}/'.format( ...
- Python学习:50 行 Python 代码,带你追到最心爱的人
程序员世纪难题 人们一提到程序员第一反应就是:我知道!他们工资很高啊!但大部分都是单身狗,不懂得幽默风趣,只是每天穿格子 polo 衫的宅男一个.甚至程序员自己也这样形容自己:钱多话少死的早.程序员总 ...
随机推荐
- 八款优秀Linux浏览器推荐
#1.Firefox:互联网革命的新典范 众所周知,Firefox最大的优点就是拥有数以千计的插件,能够使得用户个性化自己的浏览器.与此同时,Firefox还是一款时尚.快捷.创新.高效的浏览器, ...
- Linux centos7 mysql 的安装配置
2021-07-21 1. 创建用户 # 创建用户useradd mysql# 修改密码 passwd mysql 2. 下载 wget 网址 3. 解压 # 创建安装文件夹mkdir app# 解压 ...
- 【HMS Core 6.0全球上线】Network Kit全链路网络加速技术,应用无惧网络拥塞
HMS Core 6.0已于7月15日全球上线,本次版本向广大开发者开放了众多全新能力与技术.其中HMS Core Network Kit开放了全链路网络加速技术,助力开发者为用户提供低时延的畅快网络 ...
- 云原生 AI 前沿:Kubeflow Training Operator 统一云上 AI 训练
分布式训练与 Kubeflow 当开发者想要讲深度学习的分布式训练搬上 Kubernetes 集群时,首先想到的往往就是 Kubeflow 社区中形形色色的 operators,如 tf-operat ...
- RabbitMQ之消息模式2
消费端限流 什么是消费端的限流? 假设一个场景,首先,我们RabbitMQ服务器有上万条未处理的消息,我们随便打开一个消费者客户端,会出现下面情况: 巨量的消息瞬间全部推送过来,但是我们单个客户端无法 ...
- Docker(40)- docker 实战三之安装 ES+Kibana
背景 参考了狂神老师的 Docker 教程,非常棒! https://www.bilibili.com/video/BV1og4y1q7M4?p=16 es 前言 es 暴露的端口很多 es 十分耗内 ...
- python库--pymysql
方法/类 返回值 参数 说明 .connect() ct 建立与mysql数据库的连接 host 数据库服务器所在的主机 user 用户名 password 密码 database 要 ...
- C# 获取应用程序内存
double usedMemory = 0; Process p = Process.GetProcesses().Where(x => x.ProcessName.Co ...
- 安装Centos7,出现无法联网的问题-----解决办法
安装Centos7,出现无法联网的问题-----解决办法 我安装的是centos7的版本 在我照着centos7安装教程-CentOS-PHP中文网这个教程安装完后 我发现我的centOS无法联网,在 ...
- form表单提交失败
在使用一个登录/注册模板的时候,发现form表单不了,但是删除模板引用的js后就正常了,查看js文件的源码,有一个 const firstForm = document.getElementById( ...