【翻译】拟合与高斯分布 [Curve fitting and the Gaussian distribution]
参考与前言
- 英文原版 Original English Version:https://fabiandablander.com/r/Curve-Fitting-Gaussian.html
- 如何通俗易懂地介绍 Gaussian Process?: https://www.zhihu.com/question/46631426/answer/1735470753
- 如何通俗易懂地介绍 Gaussian Process? - 蒟蒻王的回答 - 知乎
- A Visual Exploration of Gaussian Processes:https://distill.pub/2019/visual-exploration-gaussian-processes/
注意:此文主要是 英文原版的自制中文翻译 (已征得原作者同意),而且可能进行了一定的压缩/添加操作,请学有余力者跳转至原版链接
Note: This post was originally published on https://fabiandablander.com/
没错,这里是我看大佬的杰作,一开始提出的问题,其实类似于回顾吧 回顾为什么之旅:为什么在拟合中是高斯分布?高斯过程又在干什么?而这篇主要是针对前者的回复,拟合和高斯分布 然后这篇英文文章真的超赞!作者还有其他系列的也超赞!主要是看的过程还可以学历史hhhh 由浅入深,看看我有没有精力再把第二篇关于高斯的翻完。
省流版:中心极限定理
拟合的过程
一条线在平面坐标系的表示主要是斜率(\(b_1\))和截距(\(b_0\))(也就是x=0时,y的那个点)
\]
那么假设我们拥有很多个点后去得到 \(b_1\) 和 \(b_0\) 。先从简单的来吧
- 假设只有一个点的时候,我们的拟合结果可能像第一幅,也就是无数条线,无法确定 \(b_1\) 和 \(b_0\)
- 当我们有两个点时 我们可以唯一确定下来这条直线是谁
- 当我们有三个点时,我们无法找到一条直线把三个点都穿过,但是可以想想,是否画出来的线中 有较好的线(拟合误差较小)
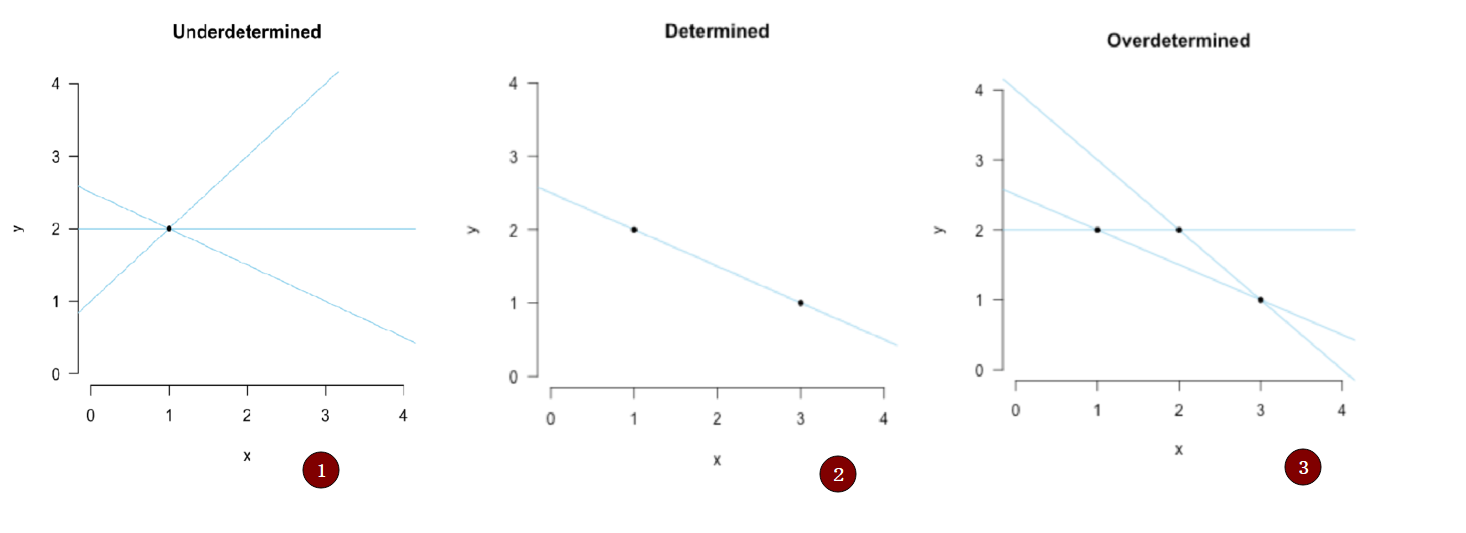
那么接下来,让我们继续思考,第三幅图我们应该怎样去拟合?或许是再加一个参数 \(b_2\) ?那 \(b_2\) 乘什么呢?还是简单起见,我们就直接按 \(x\) 的指数上去把给他乘一个 \(x^2\) ,那现在线方程变成了这样:
\]
现在是否发现了一些事情,在绝对的情况下,两个参数 \((b_0,b_1)\) 用两个点 \(P_1,P_2\) ,三个参数\((b_0, b_1, b_2)\) 用三个点 \(P_1,P_2, P_3\)
另外,如果我们同时可以这么去看点 \(P'=(y,x_1,x_1^2)\) ,还是第三幅图的点坐标,我们可以用线性代数里的矩阵形式去表示等式:
\mathbf{y} &=\mathbf{X} \mathbf{b} \\
\left(\begin{array}{l}
2 \\
1 \\
2
\end{array}\right) &=\left(\begin{array}{ccc}
1 & 1 & 1 \\
1 & 3 & 9 \\
1 & 2 & 4
\end{array}\right) \cdot\left(\begin{array}{l}
b_{0} \\
b_{1} \\
b_{2}
\end{array}\right)
\end{aligned}
\]
而这也就是上面的拟合结果,然后我们再思考一下:这样的结果有什么缺点?
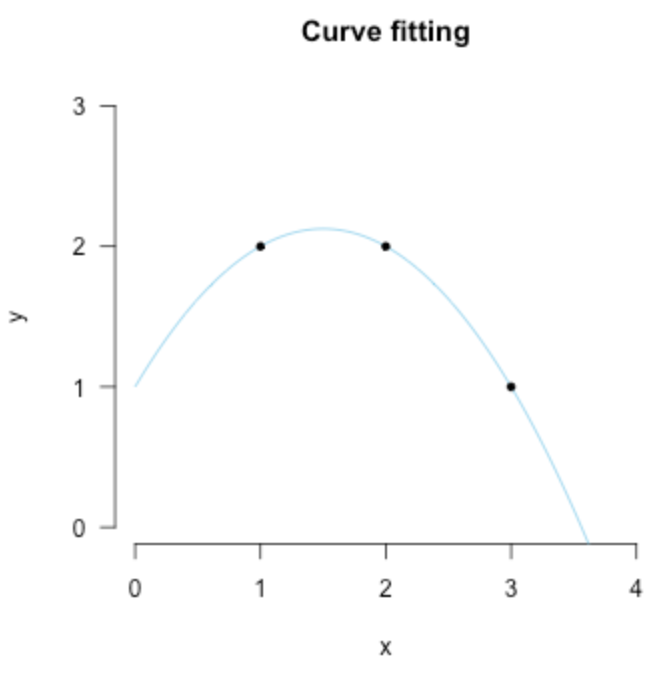
过拟合:对现在已知的数据点拟合完美,但是对未来的数据点可能就不OK了
这个数据的意义是什么:we haven’t really explained anything
引用Fisher的话:
The objective of statistical methods is the reduction of data. A quantity of data, which usually by its mere bulk is incapable of entering the mind, is to be replaced by relatively few quantities which shall adequately represent […] the relevant information contained in the original data. (Fisher, 1922, p. 311)
总结起来就是:没错 我们拟合了这条线,但是我们并没有降低数据量,三个点还是需要对应的三个参数,那是否n哥点就需要对应的n个参数呢?所以引出了回答上面的高亮部分:哪条直线更好?
"最好"的拟合
将超定(overdetermined)减小到确定(determined)情况并不可以。但是可以将超定转到欠定。为了达到这一目的呢,我们需要做出合理的假设说明观测点(数据点)是有对应的误差的,例如这样子:
&1=b_{0}+4 b_{1}+\epsilon_{1} \\
&4=b_{0}+2 b_{1}+\epsilon_{2} \\
&3=b_{0}+1 b_{1}+\epsilon_{3}
\end{aligned}
\]
而这里的 \((\epsilon_{1}, \epsilon_{2}, \epsilon_{3})\) 是unobserved quantities 未知误差值。而这一步没错又引入了未知量,所以我们再次以少的数据(少的方程)去解多的参数量,所以我们的之前的超定就变成了欠定系统求解了
正如前面所说,只有一个点时,如果没有其他限制,我们就有无数条直线说 我们拟合成功了。一样的道理在这里,我们需要添加限制,例如前面例子我需要经过这个点的线同时尽可能平行x轴,这就是一个限制。而对于现在这个问题 法国数学家Adrien-Marie Legendre 提出了著名的 最小二乘法
在上面那个例子中,通过最小二乘的误差限制,只会出现一条线满足最小的误差。因此,对于所有的其他欠定系统我们都可以这样:添加最小二乘误差的限制,例如下图:
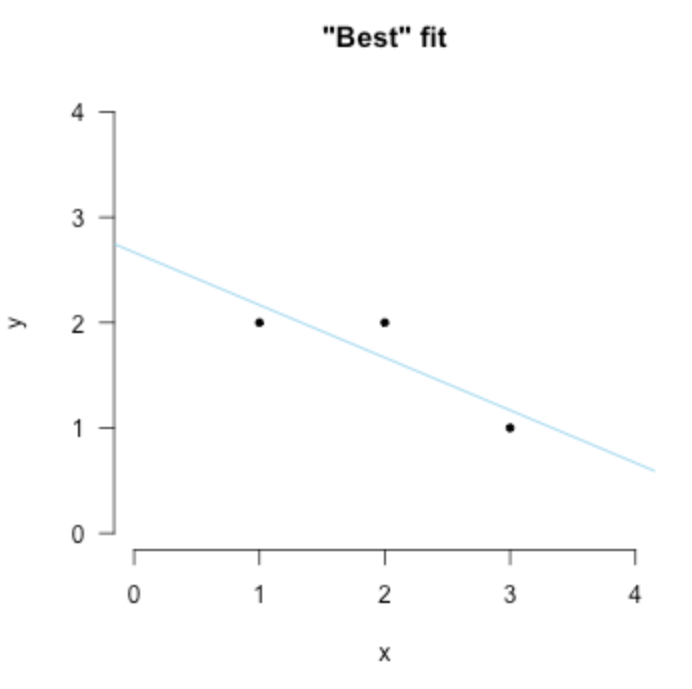
同时最小二乘法的发展也是数理统计的分水岭——Stephen Stigler 将其重要性比作数学中微积分的发展。那么理论上我们已经知道可以这样去找到最好的拟合。那数学上我们怎么知道是具体哪一条,这里提到了两种,一种是由Legendre提出的优化;另外一种是几何意义上的直观insight
Least squares I: Optimization
首先我们的目标是找到最小的均方误差。从简单入手呢,就是直接求数据的平均值,然后再去减他们,类似于这样:
y'&=y-\frac{1}{n}\sum_{i=1}^n y_i \\
x'&=x-\frac{1}{n}\sum_{i=1}^n x_i
\end{aligned}
\]
因为这样的最小化误差和 \(b_0\) 无关,所以我们就可以不去预估 \(b_0\) 是多少了
首先我们观测到数据点 \(y_i\) 我们直线给出的预估是 \(x_ib_1\) ,所以误差就是: \(\epsilon_{i}=y_{i}-x_{i} b_{1}\),我们把有的所有数据都加起来 那总误差就是这样的:
\[\sum_{i=1}^{n} \epsilon_{i}^{2}=\sum_{i=1}^{n}\left(y_{i}-x_{i} b_{1}\right)^{2}
\]现在我们就去找哪一个 \(b_1\) 可以得到最小的总误差,这里用 \(\hat b_1\) 表示
\[\hat{b}_{1}=\underbrace{\operatorname{argmin}}_{b_{1}}\left(\sum_{i=1}^{n}\left(y_{i}-x_{i} b_{1}\right)^{2}\right)
\]就像我们找曲线的最低点一样,求导,导数等于0,值小于其周围值的地方就是我们想要的点。那么在这个问题中,我们就是这样子做:
\[\begin{aligned}
0 &=\frac{\partial}{\partial b_{1}}\left(\sum_{i=1}^{n}\left(y_{i}-x_{i} b_{1}\right)^{2}\right) \\
0 &=\frac{\partial}{\partial b_{1}}\left(\sum_{i=1}^{n} y_{i}^{2}-2 \sum_{i=1}^{n} y_{i} x_{i} b_{1}+\sum_{i=1}^{n} x_{i}^{2} b_{1}^{2}\right) \\
0 &=0-2 \sum_{i=1}^{n} y_{i} x_{i}+2 \sum_{i=1}^{n} x_{i}^{2} b_{1} \\
2 \sum_{i=1}^{n} x_{i}^{2} b_{1} &=2 \sum_{i=1}^{n} y_{i} x_{i} \\
\hat{b}_{1} &=\frac{\sum_{i=1}^{n} y_{i} x_{i}}{\sum_{i=1}^{n} x_{i}^{2}}
\end{aligned}
\]其中 \(\sum_{i=1}^n y_i x_i\) 是\(x,y\) 之间的协方差 (scaled by \(n\)), and \(\sum_{i=1}^n x_i^2\) 是\(x\)自身的方差
Least squares II: Projection
从其他角度去看这个最好的拟合线,就是几何了,首先,直接把点投影到拟合线上,计算这个y轴上的差距作为误差 这个误差是垂直于x轴的,就像下面这幅图一样
\left(\begin{array}{c}
\epsilon_{1} \\
\epsilon_{2} \\
\vdots \\
\epsilon_{n}
\end{array}\right) &=\left(\begin{array}{c}
y_{1} \\
y_{2} \\
\vdots \\
y_{n}
\end{array}\right)-\left(\begin{array}{c}
x_{1} \\
x_{2} \\
\vdots \\
z_{n}
\end{array}\right) b_{1} \\
& \epsilon=\mathbf{y}-\mathbf{x} b_{1}
\end{aligned}
\]
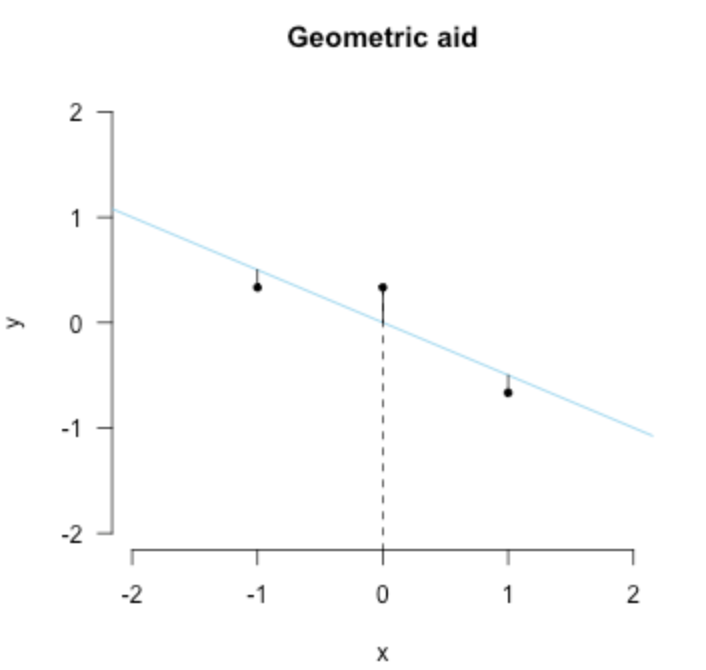
然后我们所希望的就是垂直于x轴的这个误差很小,用数学来表示呢就是点乘加起来等于0,简单版就是 \(\mathbf{x}^T \mathbf{\epsilon} = 0\)
x_{1} & x_{2} & \ldots & x_{n}
\end{array}\right)\left(\begin{array}{c}
\epsilon_{1} \\
\epsilon_{2} \\
\vdots \\
\epsilon_{n}
\end{array}\right)=0
\]
然后就又是最小二乘的方程式了:
\mathbf{x}^{T} \epsilon &=0 \\
\mathbf{x}^{T}\left(\mathbf{y}-\mathbf{x} b_{1}\right) &=0 \\
\mathbf{x}^{T} \mathbf{x} b_{1} &=\mathbf{x}^{T} \mathbf{y} \\
b_{1} &=\frac{\mathbf{x}^{T} \mathbf{y}}{\mathbf{x}^{T} \mathbf{x}} \\
b_{1} &=\frac{\sum_{i=1}^{n} x_{i} y_{i}}{\sum_{i=1}^{n} x_{i}^{2}}
\end{aligned}
\]
咦 这是不是长的很像我们在方法一 优化里得到的结果,没错就是一模一样的。
最后,可以注意到我们一直没有对 \(b_0\) 进行估计,知道最小二乘结束后 \(b_0\) 还是未知的,所以最后我们处理的方式是 \(\bar y = b_0\) 也就是 \(y\) 的平均值。也正是因为这一事实,高斯曾经将高斯分布证明是误差的分布。
“多好才是最好” 高斯, 拉普拉斯
虽然呢,最小二乘给出了怎样去拟合出“最好”的曲线来缩小误差,但是他并没说明
- 误差 \(\epsilon\) 的随机性
- “多好才是最好” How good is best?
1809年是高斯将最小二乘放在了概率的角度去考虑。他做出了这样一个假设:每一个误差项 \(\epsilon_i\) 都是服从某个分布 \(\phi\) 的
利用这分布,当 \(\epsilon_i\) 很小时,\(\epsilon_i\) 分布整体概率很大,而这个情况也就是观测和预测值十分接近的时候。然后我们再进一步假设所有误差分布都是 独立同分布 ,他想找到能够最大化概率 即最小化整体误差
\]
所以呢,现在我们就要去找到这样的一个分布 $\phi $。接着高斯大哥就发现我可以对 $\phi $ 做出一些说明,比如他一定是对称的而且在等于误差值=0的时候概率最大。接着他做出假设:平均值处应该就是能够最好概括总结 \(n\) 个观测值的地方 \((y_1,\dots,y_n)\) 所以,他假设最大化整个 \(\Omega\) 应该就和最小化整个均方误差的和是一个性质
[x] 这里有一点点不太能理解,He then assumed that the mean should be the best value for summarizing \(n\) measurements
作者在注释里写了 the mean predicts the data best
[ ] 这里还有一个 should lead to the same solution as minimizing the sum of squared errors when we have one unknown
为啥是当我们有一个未知时?是指 \(b_0\) 嘛?
然后绕完这个圈后,高斯就证明最小二乘的误差分布应该是这样子的:
\]
其中 \(\sigma^{2}\) 是方差 (其实一开始高斯提出来的时候还不长这样 最终为人所知的其实是Fisher修改了后方差后的版本) 这也就是为人所知的高斯分布,虽然呢 他一开始是Stigler's law of eponomy,同时Karl Pearson也叫其正态分布,虽然他对此有丝丝后悔:
“Many years ago I called the Laplace–Gaussian curve the normal curve, which name, while it avoids an international question of priority, has the disadvantage of leading people to believe that all other distributions of frequency are in one sense or another ‘abnormal’.” (Pearson, 1920, p. 25)
分布图如下:(虽然大家都知道了)
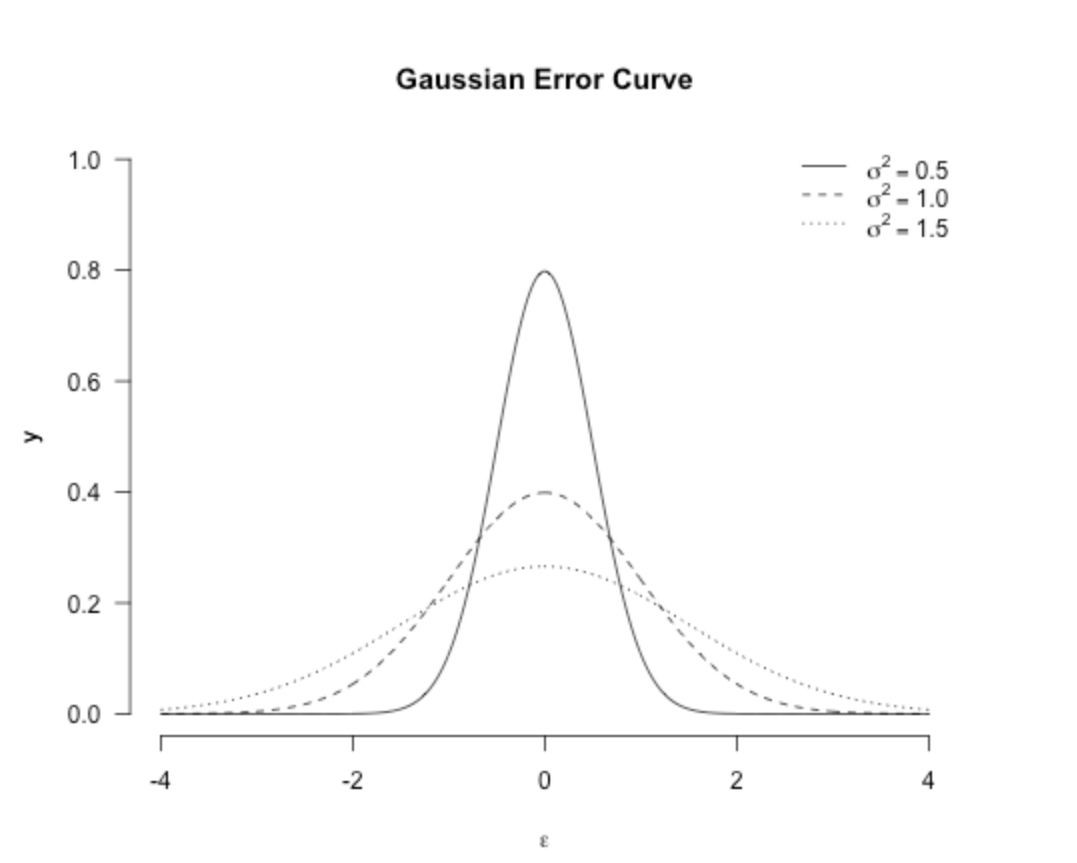
使用高斯分布后,我们的最大化问题就变成了这样子:
\]
注意:能使 \(\Omega\) 最大的值并不会随其他的东西改变,比如添删常数值,或者对其取对数log;
\(-\sum_{i=1}^{n} \epsilon_{i}^{2}\) 这是我们想要最大化的东西
因为上面式子有负号,所以去掉负号的话是: \(\sum_{i=1}^{n} \epsilon_{i}^{2}\) ,同时最大化最小化这个
最后再看一遍这个 \(\sum_{i=1}^{n} \epsilon_{i}^{2}\) 也正是最小化均方误差!
我们并没有因为分布远离我们的初衷,到头来分布概率还在朝着同一个目标
Pierre Simone de Laplace 没错就是拉普拉斯大哥在1810年注意到了高斯分布,然后给高斯误差曲线再一次的证明:如果我们将误差视为许多(微小)的扰动影响集合,这个集合将按照 中心极限定理正态分布
中心极限定理
我觉得这里直接源自百度百科可能更快:
中心极限定理,是指概率论中讨论随机变量序列部分和分布渐近于正态分布的一类定理。这组定理是数理统计学和误差分析的理论基础,指出了大量随机变量近似服从正态分布的条件。
前文中我们提到了散落的点是独立同分布,在这个基础上我们加的是 随机性 ,也就是说有一串独立同分布的随机变量序列,如果此序列是有限的方差,那当 \(n\) 越大,此序列的平均值也就越大,而他也越接近正态分布;当 \(n \rightarrow \infin\) 平均值实际收敛到了正态分布
拉普拉斯意识到,如果将最小二乘问题中的误差视为小影响的总和(即均值),那么它们将呈正态分布。 这为最小二乘解提供了an elegant justification
举个python程序的例子吧(原文是R语言的哈)
首先我们假设由 \(m=500\) 个独立同分布(程序中分布为正态的) 生成的点,然后计算一个他们一起的误差 \(\epsilon_i\)。假设我们有 \(n=200\) 组数据观测,那么就有200个独立的误差值,然后你可以可以发现这个误差接近与高斯
import numpy as np
import matplotlib.pyplot as plt
n_error = 200
influence_one_error = 500
errors = list()
for i in range(n_error):
errors.append(np.mean(np.random.uniform(-10, 10,influence_one_error)))
num_bins = 30
fig, ax = plt.subplots()
# the histogram of the data
n, bins, patches = ax.hist(errors, num_bins, density=True) # 误差们直接的直方图
# add a 'best fit' line
mu = 0
sigma = np.sqrt(20**2 / 12 ) / np.sqrt(influence_one_error) #随意的 仅用来做表示
x = np.linspace(-1,1,num=1000) # x轴的取值范围
y = 1 / (sigma * pow(2 * np.pi, 0.5)) * np.exp(-((x - mu) ** 2) / (2 * sigma ** 2)) # 概率密度函数公式
ax.plot(x, y, 'r--')
ax.set_xlabel('Smarts')
ax.set_ylabel('Probability density')
ax.set_title('Central Limit Theorem')
# Tweak spacing to prevent clipping of ylabel
fig.tight_layout()
plt.show()
生成的图:
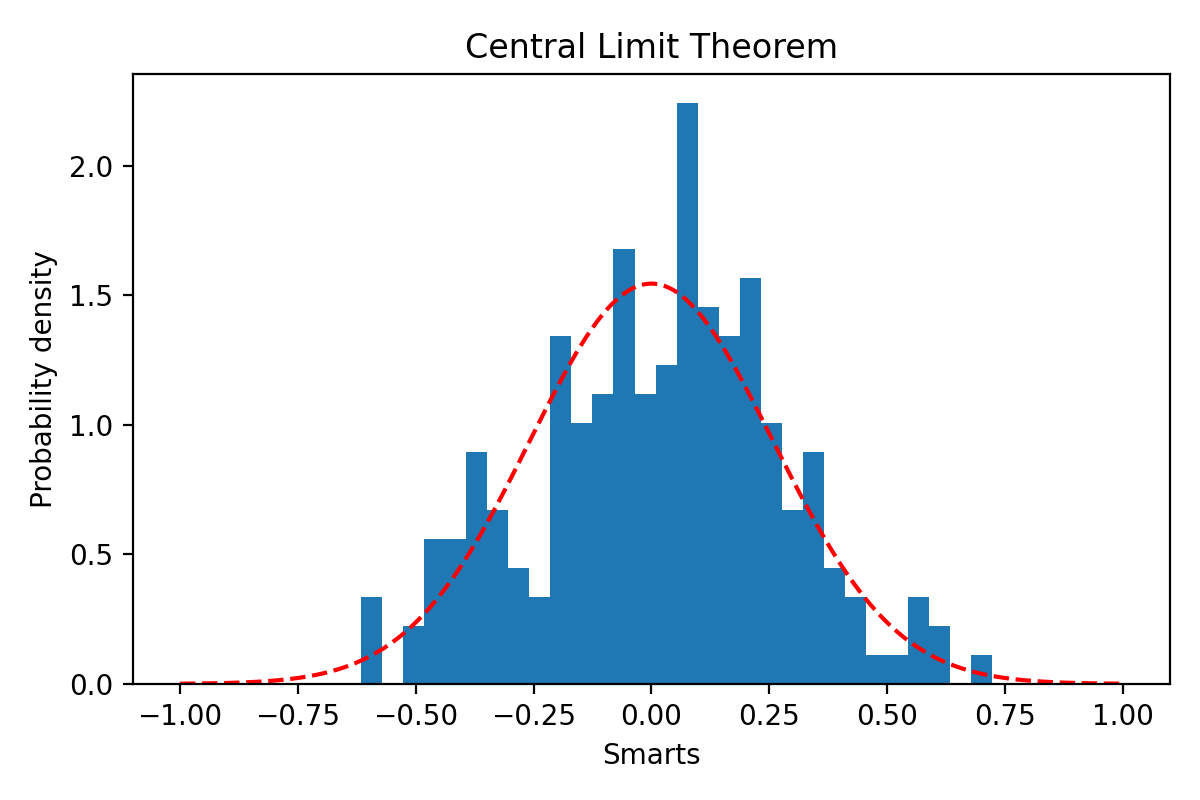
可能你还没意识到这个有多棒,让我帮你再来一次。首先我们是随意的生成了500个正态分布(按定义来讲 其他分布也OK 只要是他们一同属于某一分布) 的数据,然后算平均值,计算他们自己内部的误差是多少;而我们有200组这样的数据,那么我们就收集到了每组数据中自己的误差,然后我们发现误差间是属于正态分布的。
线性回归
最后我们再回到线性回归这个问题,也就是之前提到的拟合。
高斯分布的一个特点是任何正态分布随机变量的线性组合本身都是正态分布的。 我们可以将线性回归问题写成矩阵形式,这表明 y 是 x 的加权线性组合。 具体来说,如果我们有 n 个数据点,我们就有了一个由 n 个方程组成的系统,我们可以更简洁地用矩阵表示法来写
\left(\begin{array}{c}
y_{1} \\
y_{2} \\
\vdots \\
y_{n}
\end{array}\right) &=\left(\begin{array}{cc}
1 & x_{1} \\
1 & x_{2} \\
\vdots & \vdots \\
1 & x_{n}
\end{array}\right) \cdot\left(\begin{array}{c}
b_{0} \\
b_{1}
\end{array}\right)+\left(\begin{array}{c}
\epsilon_{1} \\
\epsilon_{2} \\
\vdots \\
\epsilon_{n}
\end{array}\right) \\
\mathbf{y} &=\mathbf{X b}+\epsilon
\end{aligned}
\]
因为这种线性的关系,使得对误差假设是正态分布,同时也为 \(\mathbf{y}\) 本身带来了这一假设条件,也就是服从正态分布:
\]
换句话说,每个点的 \(y_i\) 概率密度可以由这个公式给出:
\]
也就是下面这幅图:
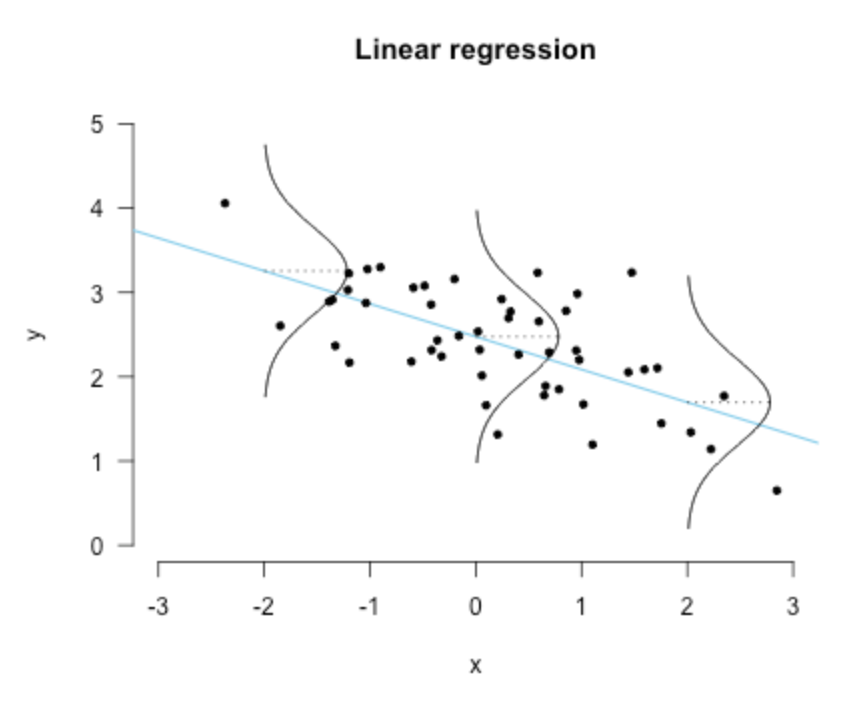
直观上来看的话就是:误差的方差越小,拟合的越好
后话 (相关性与回归系数)
相关性并不意味着因果关系。 有些人认为线性回归是一种因果模型,但是不是这样的。
为了证明这一点,我们可以将简单线性回归中的回归系数与相关性联系起来——它们仅在标准化上有所不同。
假设以均值为中心的数据,Pearson correlation的定义是:
\]
注意这里的相关性是对称的,他并不取决于我们是x与y相关或是y与x相关。但是呢,在回归中,我们使用x去预测y是这样的:
\]
但是我们如果是用y去预测x值,那系数就会变成这样:
\]
然而,通过对数据进行标准化,即通过将变量除以各自的标准差,回归系数就成为了样本相关性,即
\frac{\partial L}{\partial b_{x y}} &=\frac{\partial}{\partial b_{x y}} \sum_{i=1}^{n}\left(\frac{y_{i}}{\sqrt{\sum_{i=1}^{n} y_{i}^{2}}}-b_{x y} \frac{x_{i}}{\sqrt{\sum_{i=1}^{n} x_{i}^{2}}}\right)^{2} \\
&=\frac{\partial}{\partial b_{x y}}\left(\frac{\sum_{i=1}^{n} y_{i}^{2}}{\sqrt{\sum_{i=1}^{n} y_{i}^{2}}}-2 b_{x y} \frac{\sum_{i=1}^{n} y_{i} x_{i}}{\sqrt{\sum_{i=1}^{n} y_{i}^{2} \sum_{i=1}^{n} x_{i}^{2}}}+b_{x y}^{2} \frac{\sum_{i=1}^{n} x_{i}^{2}}{\sum_{i=1}^{n} x_{i}^{2}}\right) \\
&=0-2 \frac{\sum_{i=1}^{n} y_{i} x_{i}}{\sqrt{\sum_{i=1}^{n} y_{i}^{2} \sum_{i=1}^{n} x_{i}^{2}}}+2 b_{x y} \\
2 b_{x y} &=2 \frac{\sum_{i=1}^{n} y_{i} x_{i}}{\sqrt{\sum_{i=1}^{n} y_{i}^{2} \sum_{i=1}^{n} x_{i}^{2}}} \\
b_{x y} &=\frac{\sum_{i=1}^{n} y_{i} x_{i}}{\sqrt{\sum_{i=1}^{n} y_{i}^{2} \sum_{i=1}^{n} x_{i}^{2}}}
\end{aligned}
\]
可以看到最后他又等于了 \(r_{xy}\) ,同时 这个标准化的回归系数也可以通过乘以原始回归系数来实现,即
\]
同样的对 \(b_{yx}\) 也是一样的
\]
【翻译】拟合与高斯分布 [Curve fitting and the Gaussian distribution]的更多相关文章
- 数据拟合:多项式拟合polynomial curve fitting
http://blog.csdn.net/pipisorry/article/details/49804441 常见的曲线拟合方法 1.使偏差绝对值之和最小 2.使偏差绝对值最大的最小 3 ...
- 一起啃PRML - 1.1 Example: Polynomial Curve Fitting 多项式曲线拟合
一起啃PRML - 1.1 Example: Polynomial Curve Fitting @copyright 转载请注明出处 http://www.cnblogs.com/chxer/ 前言: ...
- [matlab工具箱] 曲线拟合Curve Fitting
——转载网络 我的matlab版本是 2016a 首先,工具箱如何打开呢? 在 apps 这个菜单项中,可以找到很多很多的应用,点击就可以打开具体的工具窗口 本文介绍的工具有以下这些: curve F ...
- 一起啃PRML - 1.2.4 The Gaussian distribution 高斯分布 正态分布
一起啃PRML - 1.2.4 The Gaussian distribution 高斯分布 正态分布 @copyright 转载请注明出处 http://www.cnblogs.com/chxer/ ...
- 正态分布(Normal distribution)又名高斯分布(Gaussian distribution)
正态分布(Normal distribution)又名高斯分布(Gaussian distribution),是一个在数学.物理及project等领域都很重要的概率分布,在统计学的很多方面有着重大的影 ...
- 高斯分布(Gaussian Distribution)的概率密度函数(probability density function)
高斯分布(Gaussian Distribution)的概率密度函数(probability density function) 对应于numpy中: numpy.random.normal(loc= ...
- 【PRML读书笔记-Chapter1-Introduction】1.1 Example:Polynomial Curve Fitting
书中给出了一个典型的曲线拟合的例子,给定一定量的x以及对应的t值,要你判断新的x对应的t值多少. 任务就是要我们去发现潜在的曲线方程:sin(2πx) 这时就需要概率论的帮忙,对于这种不确定给t赋何值 ...
- MATLAB学习(八)神经网络拟合工具箱 Neural Net Fitting使用示例
>> x=-3:0.2:5;y=x.^2-1;xn=-2:0.1:7; >> >> %多元函数(z=sin(x2+y2)/(x2+y2))拟合 >&g ...
- [PR & ML 2] [Introduction] Example: Polynomial Curve Fitting
啊啊啊,竟然不支持latex,竟然HTML代码不能包含javascript,代码编辑器也不支持Matlab!!!我要吐槽博客的编辑器...T_T只能贴图凑合看了,代码不是图,但这次为了省脑细胞,写的不 ...
随机推荐
- 源码简析Spring-Integration执行过程
一,前言 Spring-Integration基于Spring,在应用程序中启用了轻量级消息传递,并支持通过声明式适配器与外部系统集成.这一段官网的介绍,概况了整个Integration的用途.个人感 ...
- MySQL笔记04(黑马)
今日内容 多表查询 事务 DCL 多表查询 * 查询语法: select 列名列表 from 表名列表 where.... * 准备sql # 创建部门表 CREATE TABLE dept( id ...
- NX二次开发-克隆操作
模板文件: 克隆替换字符串: 1 #include "Text.h" 2 extern DllExport void ufsta(char *param, int *returnC ...
- 【NX二次开发】UF_CSYS_map_point()函数,绝对坐标,工作坐标,部件之间坐标转换。
UF_CSYS_map_point用来变换点的坐标,比较简单且实用.例如工作坐标系与绝对坐标系转换,一个部件的坐标与另一个部件坐标系之间的转换.下面的例子是在三个坐标下创建三个点相对坐标为{10,50 ...
- Vue——v-for动态绑定id的问题
问题:在Vue中,会遇到许多个多选框,倘若数量很庞大那么一个一个input框.label节点寻找,这样操作很繁琐. 直接上解决方案吧: html页面: <ul v-for="(item ...
- Pytest学习笔记3-fixture
前言 个人认为,fixture是pytest最精髓的地方,也是学习pytest必会的知识点. fixture用途 用于执行测试前后的初始化操作,比如打开浏览器.准备测试数据.清除之前的测试数据等等 用 ...
- 【科普】MySQL中DDL操作背后的并发原理
一. 简介 DQL:指数据库中的查询(select)操作. DML:指数据库中的插入(insert).更新(update).删除(delete)等行数据变更操作. DDL:指数据库中加列(add co ...
- typescript 中的 infer 关键字的理解
infer 这个关键字,整理记录一下,避免后面忘记了.有点难以理解呢. infer infer 是在 typescript 2.8中新增的关键字. infer 可以在 extends 条件类型的字句中 ...
- N沟通场效应管深度图解(1)工作原理及Multisim实例仿真
场效应晶体管(Field Effect Transistor, FET)简称场效应管,是一种由多数载流子参与导电的半导体器件,也称为单极型晶体管,它主要分型场效应管(Junction FET, JFE ...
- rabbitmqctl 命令整理
虽然还有http 接口.web admin组件可以进行管理,但是rabbitmqctl 基本包含了 rabbitmq 的全部管理功能,更为全面. 所以将其使用方法总结于此. 一,命令格式 rabbit ...