Google服务器架构图解简析
无疑是互联网时代最闪亮的明星。截止到今天为止,Google美国主站在Alexa排名已经连续3年第一,Alexa Top100中,各国的Google分站竟然霸占了超过20多个名额,不得不令人感叹Google的强大。不论何时,不论何地,也不论你搜索多么冷门的词汇,只要你的电脑连接互联网,只要你轻轻点击“google搜索”,那么这一切相关内容google都会在1秒钟之内全部搞定,这甚至比你查询“我的文档”都要快捷。这也就是为什么Google创业12年,市值超过2000亿美元的原因。
的 Myrinet或者Giganet 的 cLAN等先进昂贵的集群连接技术,Google各个数据中心和服务器间不同的耦合程度都随需而定自行连接。
那么google的存储呢?Google存储着海量的资讯,近千亿个网页、数百亿张图片。早在2004年,Google的存储容量就已经达到了5PB。可能很多读者一开始都认为Google采用了诸如EMC Symmetrix系列磁盘阵列来保存大量的资讯,但是Google的实际做法又一次让我们大跌眼镜——Google没有使用任何磁盘阵列,哪怕是低端的磁盘阵列也没用。Google的方法是将集群中的每一台PC级服务器,配备两个普通IDE硬盘来存储。不过Google倒也不是都是什么设备都落后,至少这些硬盘的转速都很高,而且每台服务器的内存也还算比较大。最大的电脑DIY消费者是谁?恐怕Google又登上了这个DIY宝座。Google的绝大部分服务器甚至也不是采购什么大品牌,而是购买各种廉价零件而后自行装配的。有趣的是,Google非常不满意现存的各种PC电源的功耗,甚至还自行设计了Google专用服务器电源。
File System)正是在这样的检索技术上构建的文件系统,GFS包括了GFS Master服务器和Chunk服务器。如下图所示,系统的流程从GFS客户端开始:GFS客户端以chunk偏移量制作目录索引并且发送请求——GFS Master收到请求通过chunk映射表映射反馈客户端——客户端有了chunk handle和chunk 位置,并将文件名和chunk的目录索引缓存,向chunk服务器发送请求——chunk服务器回复请求传输chunk数据。
平台
在2006年大约有450,000台廉价服务器,这个数量到2010年增加到了1,000,000台。
在2005年Google索引了80亿Web页面,现在没有人知道具体数目,近千亿并不断增长中。
目前在Google有超过500个GFS集群。一个集群可以有1000或者甚至5000台机器。成千上万的机器从运行着5000000000000000字节存储的GFS集群获取数据,集群总的读写吞吐量可以达到每秒40兆字节
目前在Google有6000个MapReduce程序,而且每个月都写成百个新程序
BigTable伸缩存储几十亿的URL,几百千千兆的卫星图片和几亿用户的参数选择
Google形象化它们的基础组织为三层架构:
1,产品:搜索,广告,email,地图,视频,聊天,博客
2,分布式系统基础组织:GFS,MapReduce和BigTable
3,计算平台:一群不同的数据中心里的机器
4,确保公司里的人们部署起来开销很小
5,花费更多的钱在避免丢失日志数据的硬件上,其他类型的数据则花费较少
1,可信赖的伸缩性存储是任何程序的核心需求。GFS就是Google的核心存储平台
2,Google File System – 大型分布式结构化日志文件系统,Google在里面扔了大量的数据
3,为什么构建GFS而不是利用已有的东西?因为可以自己控制一切并且这个平台与别的不一样,Google需要:
-跨数据中心的高可靠性
-成千上万的网络节点的伸缩性
-大读写带宽的需求
-支持大块的数据,可能为上千兆字节
-高效的跨节点操作分发来减少瓶颈
4,系统有Master和Chunk服务器
-Master服务器在不同的数据文件里保持元数据。数据以64MB为单位存储在文件系统中。客户端与Master服务器交流来在文件上做元数据操作并且找到包含用户需要数据的那些Chunk服务器
-Chunk服务器在硬盘上存储实际数据。每个Chunk服务器跨越3个不同的Chunk服务器备份以创建冗余来避免服务器崩溃。一旦被Master服务器指明,客户端程序就会直接从Chunk服务器读取文件
6,一个上线的新程序可以使用已有的GFS集群或者可以制作自己的GFS集群
7,关键点在于有足够的基础组织来让人们对自己的程序有所选择,GFS可以调整来适应个别程序的需求
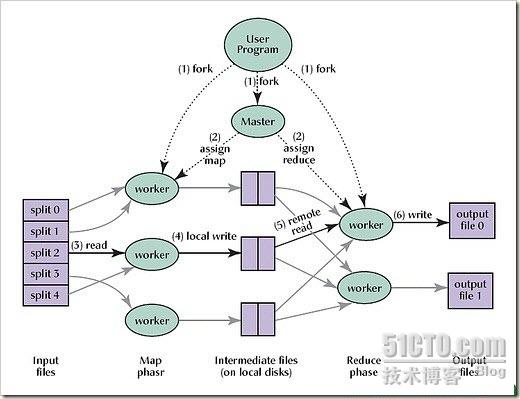
1,现在你已经有了一个很好的存储系统,你该怎样处理如此多的数据呢?比如你有许多TB的数据存储在1000台机器上。数据库不能伸缩或者伸缩到这种级别花费极大,这就是MapReduce出现的原因
2,MapReduce是一个处理和生成大量数据集的编程模型和相关实现。用户指定一个map方法来处理一个键/值对来生成一个中间的键/值对,还有一个reduce方法来合并所有关联到同样的中间键的中间值。许多真实世界的任务都可以使用这种模型来表现。以这种风格来写的程序会自动并行的在一个大量机器的集群里运行。运行时系统照顾输入数据划分、程序在机器集之间执行的调度、机器失败处理和必需的内部机器交流等细节。这允许程序员没有多少并行和分布式系统的经验就可以很容易使用一个大型分布式系统资源
3,为什么使用MapReduce?
-跨越大量机器分割任务的好方式
-处理机器失败
-可以与不同类型的程序工作,例如搜索和广告。几乎任何程序都有map和reduce类型的操作。你可以预先计算有用的数据、查询字数统计、对TB的数据排序等等
4,MapReduce系统有三种不同类型的服务器
-Master服务器分配用户任务到Map和Reduce服务器。它也跟踪任务的状态
-Map服务器接收用户输入并在其基础上处理map操作。结果写入中间文件
-Reduce服务器接收Map服务器产生的中间文件并在其基础上处理reduce操作
5,例如,你想在所有Web页面里的字数。你将存储在GFS里的所有页面抛入MapReduce。这将在成千上万台机器上同时进行并且所有的调整、工作调度、失败处理和数据传输将自动完成
-步骤类似于:GFS -> Map -> Shuffle -> Reduction -> Store Results back into GFS
-在MapReduce里一个map操作将一些数据映射到另一个中,产生一个键值对,在我们的例子里就是字和字数
-Shuffling操作聚集键类型
-Reduction操作计算所有键值对的综合并产生最终的结果
6,Google索引操作管道有大约20个不同的map和reduction。
7,程序可以非常小,如20到50行代码
8,一个问题是掉队者。掉队者是一个比其他程序慢的计算,它阻塞了其他程序。掉队者可能因为缓慢的IO或者临时的CPU不能使用而发生。解决方案是运行多个同样的计算并且当一个完成后杀死所有其他的
9,数据在Map和Reduce服务器之间传输时被压缩了。这可以节省带宽和I/O。
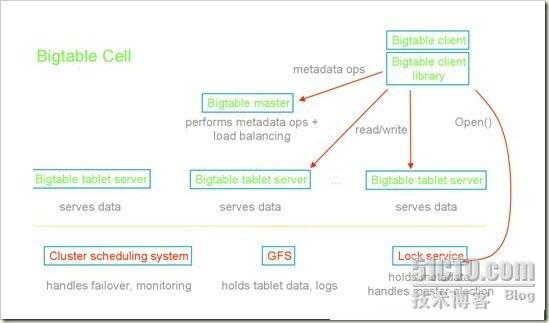
1,BigTable是一个大伸缩性、错误容忍、自管理的系统,它包含千千兆的内存和1000000000000000的存储。它可以每秒钟处理百万的读写
2,BigTable是一个构建于GFS之上的分布式哈希机制。它不是关系型数据库。它不支持join或者SQL类型查询
3,它提供查询机制来通过键访问结构化数据。GFS存储存储不透明的数据而许多程序需求有结构化数据
4,商业数据库不能达到这种级别的伸缩性并且不能在成千上万台机器上工作
5,通过控制它们自己的低级存储系统Google得到更多的控制权来改进它们的系统。例如,如果它们想让跨数据中心的操作更简单这个特性,它们可以内建它
6,系统运行时机器可以自由的增删而整个系统保持工作
7,每个数据条目存储在一个格子里,它可以通过一个行key和列key或者时间戳来访问
8,每一行存储在一个或多个tablet中。一个tablet是一个64KB块的数据序列并且格式为SSTable
9,BigTable有三种类型的服务器:
-Master服务器分配tablet服务器,它跟踪tablet在哪里并且如果需要则重新分配任务
-Tablet服务器为tablet处理读写请求。当tablet超过大小限制(通常是100MB-200MB)时它们拆开tablet。当一个Tablet服务器失败时,则100个Tablet服务器各自挑选一个新的tablet然后系统恢复。
-Lock服务器形成一个分布式锁服务。像打开一个tablet来写、Master调整和访问控制检查等都需要互斥
10,一个locality组可以用来在物理上将相关的数据存储在一起来得到更好的locality选择
11,tablet尽可能的缓存在RAM里
1,当你有很多机器时你怎样组织它们来使得使用和花费有效?
2,使用非常廉价的硬件
3,A 1,000-fold computer power increase can be had for a 33 times lower cost if you you use a failure-prone infrastructure rather than an infrastructure built on highly reliable components. You must build reliability on top of unreliability for this strategy
to work.
4,Linux,in-house rack design,PC主板,低端存储
5,Price per wattage on performance basis isn’t getting better. Have huge power and cooling issues
6,使用一些collocation和Google自己的数据中心
1,迅速更改而不是等待QA
2,库是构建程序的卓越方式
3,一些程序作为服务提供
4,一个基础组织处理程序的版本,这样它们可以发布而不用害怕会破坏什么东西
1,支持地理位置分布的集群
2,为所有数据创建一个单独的全局名字空间。当前的数据由集群分离
3,更多和更好的自动化数据迁移和计算
4,解决当使用网络划分来做广阔区域的备份时的一致性问题(例如保持服务即使一个集群离线维护或由于一些损耗问题)
1,基础组织是有竞争性的优势。特别是对Google而言。Google可以很快很廉价的推出新服务,并且伸缩性其他人很难达到。许多公司采取完全不同的方式。许多公司认为基础组织开销太大。Google认为自己是一个系统工程公司,这是一个新的看待软件构建的方式
2,跨越多个数据中心仍然是一个未解决的问题。大部分网站都是一个或者最多两个数据中心。我们不得不承认怎样在一些数据中心之间完整的分布网站是很需要技巧的
3,如果你自己没有时间从零开始重新构建所有这些基础组织你可以看看Hadoop。Hadoop是这里很多同样的主意的一个开源实现
4,平台的一个优点是初级开发人员可以在平台的基础上快速并且放心的创建健全的程序。如果每个项目都需要发明同样的分布式基础组织的轮子,那么你将陷入困境因为知道怎样完成这项工作的人相对较少
5,协同工作不一直是掷骰子。通过让系统中的所有部分一起工作则一个部分的改进将帮助所有的部分。改进文件系统则每个人从中受益而且是透明的。如果每个项目使用不同的文件系统则在整个堆栈中享受不到持续增加的改进
6,构建自管理系统让你没必要让系统关机。这允许你更容易在服务器之间平衡资源、动态添加更大的容量、让机器离线和优雅的处理升级
7,创建可进化的基础组织,并行的执行消耗时间的操作并采取较好的方案
8,不要忽略学院。学院有许多没有转变为产品的好主意。Most of what Google has done has prior art, just not prior large scale deployment.
9,考虑压缩。当你有许多CPU而IO有限时压缩是一个好的选择。
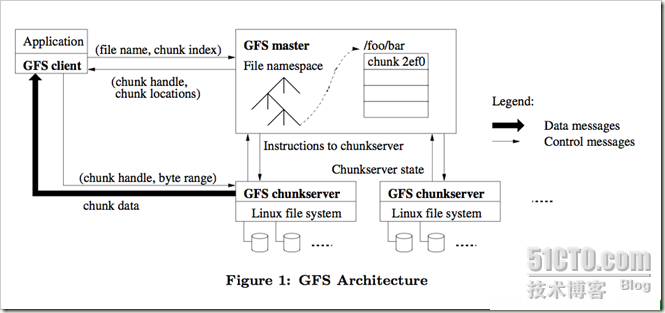
2、给master发送一个包含文件名和块索引的请求。
3、master回应对应的chunk handle和副本的位置(多个副本)。
4、client以文件名和块索引为键缓存这些信息。(handle和副本的位置)。
5、Client 向其中一个副本发送一个请求,很可能是最近的一个副本。请求指定了chunk handle(chunkserver以chunk handle标识chunk)和块内的一个字节区间。
6、除非缓存的信息不再有效(cache for a limited time)或文件被重新打开,否则以后对同一个块的读操作不再需要client和master间的交互。
(Yahoo,下称雅虎)等公司相比,具有更大的成本优势。Google程序员的效率比其他Web公司同行们高出50%~100%,原因是Google已经开发出了一整套专用于支持大规模并行系统编程的定制软件库。据他估算,其他竞争公司可能要花上四倍的时间才能获得同等的效果。
Workqueue)。
Apache更高,但是最终运行速度却更快。“如果我们能够压榨出10%~20%的性能,我们就可以节省出更多系统资源、电量和人力了。”迪博纳在总结中指出。
Google服务器架构图解简析的更多相关文章
- 从网络架构方面简析循环神经网络RNN
一.前言 1.1 诞生原因 在普通的前馈神经网络(如多层感知机MLP,卷积神经网络CNN)中,每次的输入都是独立的,即网络的输出依赖且仅依赖于当前输入,与过去一段时间内网络的输出无关.但是在现实生活中 ...
- hive架构原理简析-mapreduce部分
整个处理流程包括主要包括,语法解析(抽象语法树,AST,采用antlr),语义分析(sematic Analyzer生成查询块),逻辑计划生成(OP tree),逻辑计划优化,物理计划生成(Task ...
- [转帖]简析数据中心三大Overlay技术
简析数据中心三大Overlay技术 http://www.jifang360.com/news/20161010/n225987768.html 搭建大规模的云计算环境需要数据中心突破多种技术难题,其 ...
- Linux VFS机制简析(一)
Linux VFS机制简析(一) 本文主要基于Linux内核文档,简单分析Linux VFS机制,以期对编写新的内核文件系统(通常是给分布式文件系统编写内核客户端)的场景有所帮助. 个人渊源 切入正文 ...
- 简析 .NET Core 构成体系
简析 .NET Core 构成体系 Roslyn 编译器 RyuJIT 编译器 CoreCLR & CoreRT CoreFX(.NET Core Libraries) .NET Core 代 ...
- zxing二维码扫描的流程简析(Android版)
目前市面上二维码的扫描似乎用开源google的zxing比较多,接下去以2.2版本做一个简析吧,勿喷... 下载下来后定位两个文件夹,core和android,core是一些核心的库,android是 ...
- 简析TCP的三次握手与四次分手【转】
转自 简析TCP的三次握手与四次分手 | 果冻想http://www.jellythink.com/archives/705 TCP是什么? 具体的关于TCP是什么,我不打算详细的说了:当你看到这篇文 ...
- AFNetworking封装思路简析
http://blog.csdn.net/qq_34101611/article/details/51698473 一.AFNetworking的发展 1. AFN 1.0版本 AFN 的基础部分是 ...
- 无服务器架构(Faas/Serverless)
摘要无服务器架构(Faas/Serverless),是软件架构领域的热门话题. AWS,Google Cloud和Azure - 在无服务器上投入了大量资金,已经在看到了大量专门针对Faas/Serv ...
随机推荐
- 2021.8.12考试总结[NOIP模拟37]
T1 数列 考场上切掉的简单题. $a$,$b$与数列中数的正负值对答案无关.全当作正数计算即可. $exgcd$解未知数系数为$a$,$b$,加和为$gcd(a,b)$的不定方程组,再枚举每个数.如 ...
- Unity——射线系统
Unity射线系统 Demo展示 UI+Physical射线测试: FPS自定义射线测试: UGUI射线工具 实现功能,鼠标点击UI,返回鼠标点击的UI对象: 需要使用到鼠标点击事件-PointerE ...
- arduino 使用 analogRead 读取不到数据,digitalRead 却可以正常读取
项目场景: 最近在使用安信可的 ESP32S P14 引脚(ADC 16)读取一个电路状态的时候遇到一个问题,电路状态不是很稳定,在高电平的时候,会突然出现毫秒级的波动,出现短暂的低电平,造成设备状态 ...
- DC综合与Tcl语法结构概述
转载:https://www.cnblogs.com/IClearner/p/6617207.html 1.逻辑综合的概述 synthesis = translation + logic optimi ...
- 最接近的数 牛客网 程序员面试金典 C++ Python
最接近的数 牛客网 程序员面试金典 C++ Python 题目描述 有一个正整数,请找出其二进制表示中1的个数相同.且大小最接近的那两个数.(一个略大,一个略小) 给定正整数int x,请返回一个ve ...
- Javafx-【直方图】文本频次统计工具 中文/英文单词统计
上周倒腾了下 javafx,本来是做平时成绩系统.跟老师提了一下 javafx,他突然兴起,发了个统计中文和英文单词并以直方图显示的实验......只给两三天的期限,笑着说考验我们的潜力SOS,于是带 ...
- Spark中资源调度和任务调度
Spark比MR快的原因 1.Spark基于内存的计算 2.粗粒度资源调度 3.DAG有向无环图:可以根据宽窄依赖划分出可以并行计算的task 细粒度资源调度 MR是属于细粒度资源调度 优点:每个ta ...
- Mac 下安装 MySQL 步骤
安装 MySQL Mac 下安装MySQL推荐去官网下载dmg 版本的,我使用的版本是5.7.30. 如上图所示. 之后就是傻瓜式一键狂点不过需要注意的是,不要关闭下图所示的框框!不要关闭下图所示的框 ...
- puts()_C语言
puts()函数用来向标准输出设备, scanf函数是格式输入函数,即按用户指定的格式从键盘上把数据输入到指定的变量之中. puts就是输出字符串啊.int puts( const char* ...
- [cf1458D]Flip and Reverse
将$s$中的01分别变为$1,-1$,即得到一个序列$a_{i}$(设其长度为$n$,下标范围为$[1,n]$) 对$a_{i}$建立一张有向图,其点集合为$Z$,并对$\forall 0\le k& ...