JDK HttpClient 单次请求的生命周期
HttpClient 单次请求的生命周期
1. 简述
上篇我们通过流程图和时序图,简要了解了HttpClient的请求处理流程,并重点认识了其对用户请求的修饰和对一次用户请求可能引发的多重请求——响应交换的处理。本篇,我们以最基础的Http1.1为例,深入单次请求的处理过程,见证其完整的生命历程。
本篇是HttpClient源码分析的核心。我们将看到连接的管理和复用、channel的读写、响应式流的运用。
本文所述的HttpClient都指代JDK11开始内置的HttpClient及相关类,源码分析基于JAVA 17。阅读本文需要理解Reactive Streams规范及对应的JAVA Flow api的原理和使用。
2. uml图
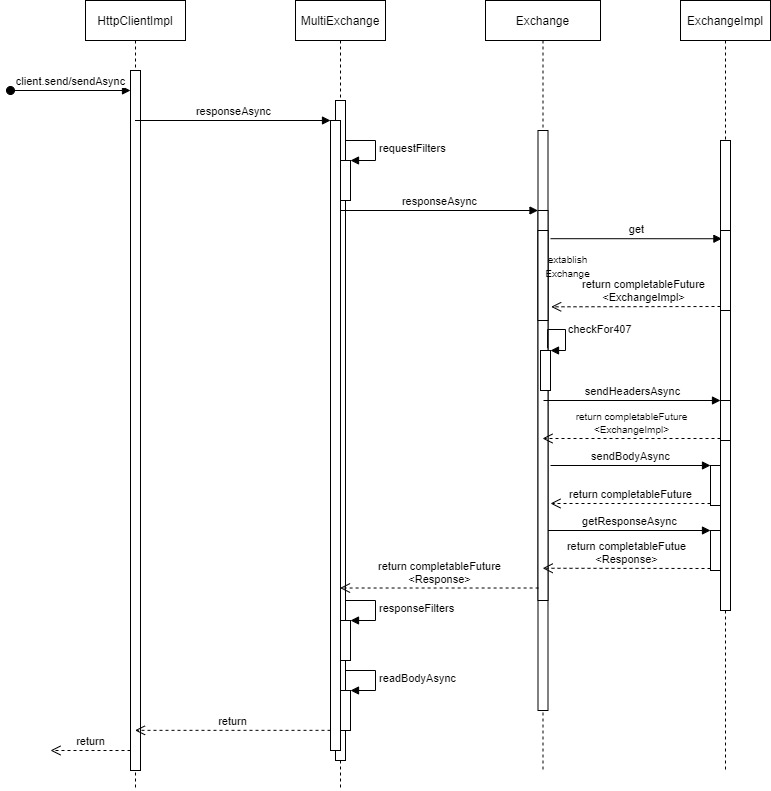
为了方便,我们再次回顾HttpClient发送请求的流程图和时序图:

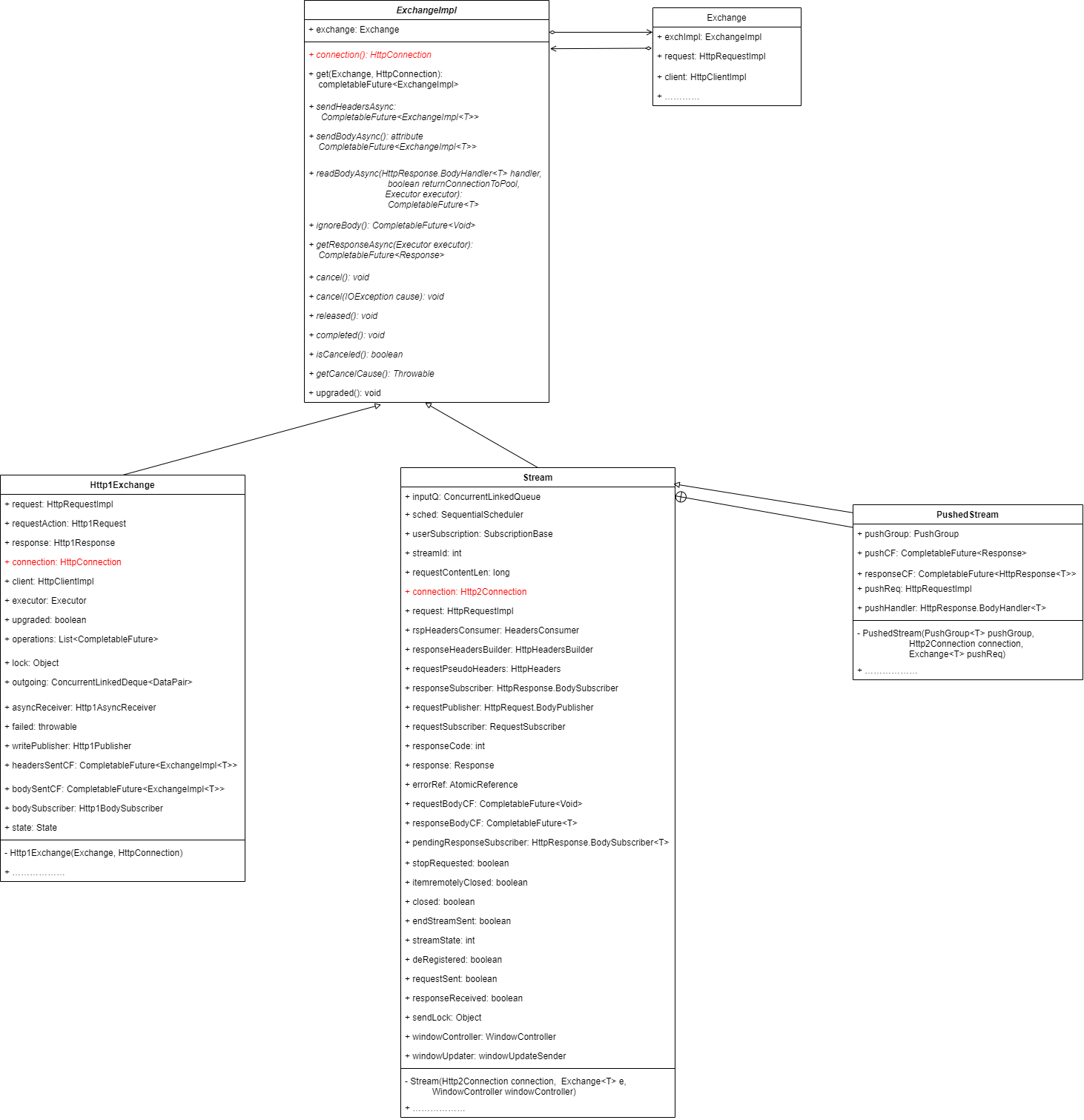
以下是本篇分析的重点类:Http1Exchange的uml类图:
3. Http连接的建立、复用和降级
在单次请求的过程中,首先进行的操作就是Http连接的建立。我们主要关注Http1连接。连接的过程可以简要概括如下:
- 根据请求类型实例化不同的ExchangeImpl,负责具体的请求——响应过程
- 根据交换类型决定要实例化的HTTP连接的版本;根据请求类型从连接池中尝试获取对应路由的已有连接
- 连接池中获取不到连接,实例化对应的Http连接(在最基本的Http1.1连接中,会开启NIOSocket通道并包裹到管道中)
- 如果初始化的连接实例是Http2,而协商发现不支持,则降级为建立Http1连接
我们将看到,HttpClient在Http1、Http2两个不同版本协议间切换自如。根据是否进行SSL加密,HttpClient会实例化HttpConnection的不同子类,而如果是Http2连接,那么一个组合了该子类实例的Http2Connection实例将会负责对Http2连接的管理。否则,则是HttpConnection的子类自身管理连接。
3.1 调用流程及连接的建立和复用
接下来是具体的分析。我们回顾上篇分析的MultiExchange的responseAsyncImpl方法,该方法负责把用户请求过滤后,委托给Exchange类处理,自己接受响应并处理多重请求。
//处理一次用户请求带来的一个或多个请求的过程,返回一个最终响应
private CompletableFuture<Response> responseAsyncImpl() {
CompletableFuture<Response> cf;
//省略………………
Exchange<T> exch = getExchange();
// 2. get response
// 由单个交换对象(Exhange)负责处理当前的单个请求,异步返回响应
//这是我们即将分析的方法
cf = exch.responseAsync()
.thenCompose((Response response) -> {
//省略……
}
return cf;
}
现在,我们将关注点转向Exchange类对一次请求——响应的处理。我们关注Exchange::responseAsync方法:
/**
* One request/response exchange (handles 100/101 intermediate response also).
* depth field used to track number of times a new request is being sent
* for a given API request. If limit exceeded exception is thrown.
*
* Security check is performed here:
* - uses AccessControlContext captured at API level
* - checks for appropriate URLPermission for request
* - if permission allowed, grants equivalent SocketPermission to call
* - in case of direct HTTP proxy, checks additionally for access to proxy
* (CONNECT proxying uses its own Exchange, so check done there)
*
*/
final class Exchange<T> {
//此处是Exchange类的成员变量的展示
final HttpRequestImpl request;
final HttpClientImpl client;
//ExchangeImpl抽象成员,具体类型根据连接类型确定
volatile ExchangeImpl<T> exchImpl;
volatile CompletableFuture<? extends ExchangeImpl<T>> exchangeCF;
volatile CompletableFuture<Void> bodyIgnored;
// used to record possible cancellation raised before the exchImpl
// has been established.
private volatile IOException failed;
@SuppressWarnings("removal")
final AccessControlContext acc;
final MultiExchange<T> multi;
final Executor parentExecutor;
volatile boolean upgrading; // to HTTP/2
volatile boolean upgraded; // to HTTP/2
final PushGroup<T> pushGroup;
final String dbgTag;
//…………省略大量代码
//上文中,MultiExchange调用的方法
// Completed HttpResponse will be null if response succeeded
// will be a non null responseAsync if expect continue returns an error
public CompletableFuture<Response> responseAsync() {
return responseAsyncImpl(null);
}
//上面方法调用的重载方法
CompletableFuture<Response> responseAsyncImpl(HttpConnection connection) {
SecurityException e = checkPermissions();
if (e != null) {
return MinimalFuture.failedFuture(e);
} else {
return responseAsyncImpl0(connection);
}
}
//实际处理的方法,我们需要重点关注。
CompletableFuture<Response> responseAsyncImpl0(HttpConnection connection) {
//此处声明一个通过407错误校验(代理服务器认证失败)后要执行的操作
Function<ExchangeImpl<T>, CompletableFuture<Response>> after407Check;
bodyIgnored = null;
if (request.expectContinue()) {
request.addSystemHeader("Expect", "100-Continue");
Log.logTrace("Sending Expect: 100-Continue");
// wait for 100-Continue before sending body
// 若我们构建请求设置了expectContinue(),那么通过407校验后,就会先发送一个等待100响应状态码的确认请求
after407Check = this::expectContinue;
} else {
// send request body and proceed. 绝大多数情况下,通过407校验后,直接发送请求体
after407Check = this::sendRequestBody;
}
// The ProxyAuthorizationRequired can be triggered either by
// establishExchange (case of HTTP/2 SSL tunneling through HTTP/1.1 proxy
// or by sendHeaderAsync (case of HTTP/1.1 SSL tunneling through HTTP/1.1 proxy
// Therefore we handle it with a call to this checkFor407(...) after these
// two places.
Function<ExchangeImpl<T>, CompletableFuture<Response>> afterExch407Check =
(ex) -> ex.sendHeadersAsync()
.handle((r,t) -> this.checkFor407(r, t, after407Check))
.thenCompose(Function.identity());
return establishExchange(connection) //首先建立连接
//校验是否发生407错误,否则执行上面的afterExch407Check,即发送请求头,然后再次校验407错误,之后执行after407check操作
.handle((r,t) -> this.checkFor407(r,t, afterExch407Check))
.thenCompose(Function.identity());
}
}
可以看到,实际处理请求的是Exchange::responseAsyncImpl0方法。此处发生的流程正如流程图里看到的那样:
- 尝试建立连接
- 校验是否发生407错误
- 发送请求头
- 再次校验是否发生了407错误
- 发送100确认请求/发送请求体
我们首先关注连接的建立过程:Exchange.estableExchange(connection)
// get/set the exchange impl, solving race condition issues with
// potential concurrent calls to cancel() or cancel(IOException)
private CompletableFuture<? extends ExchangeImpl<T>>
establishExchange(HttpConnection connection) {
if (debug.on()) {
debug.log("establishing exchange for %s,%n\t proxy=%s",
request, request.proxy());
}
//检查请求是否已取消
// check if we have been cancelled first.
Throwable t = getCancelCause();
checkCancelled();
if (t != null) {
if (debug.on()) {
debug.log("exchange was cancelled: returned failed cf (%s)", String.valueOf(t));
}
return exchangeCF = MinimalFuture.failedFuture(t);
}
CompletableFuture<? extends ExchangeImpl<T>> cf, res;
//注意,此处是关键,异步返回了exhangeImpl抽象类,它有三个子类,根据请求类型来判断
//我们将分析此方法,其中实现类连接的创建和复用
cf = ExchangeImpl.get(this, connection);
// We should probably use a VarHandle to get/set exchangeCF
// instead - as we need CAS semantics.
synchronized (this) { exchangeCF = cf; };
res = cf.whenComplete((r,x) -> {
synchronized(Exchange.this) {
if (exchangeCF == cf) exchangeCF = null;
}
});
checkCancelled();
return res.thenCompose((eimpl) -> {
// recheck for cancelled, in case of race conditions
exchImpl = eimpl;
IOException tt = getCancelCause();
checkCancelled();
if (tt != null) {
return MinimalFuture.failedFuture(tt);
} else {
// Now we're good to go. Because exchImpl is no longer
// null cancel() will be able to propagate directly to
// the impl after this point ( if needed ).
return MinimalFuture.completedFuture(eimpl);
} });
}
我们看到,ExchangeImpl的静态方法get(Exchange, Connection)方法异步返回了它的具体实现类(对象)。
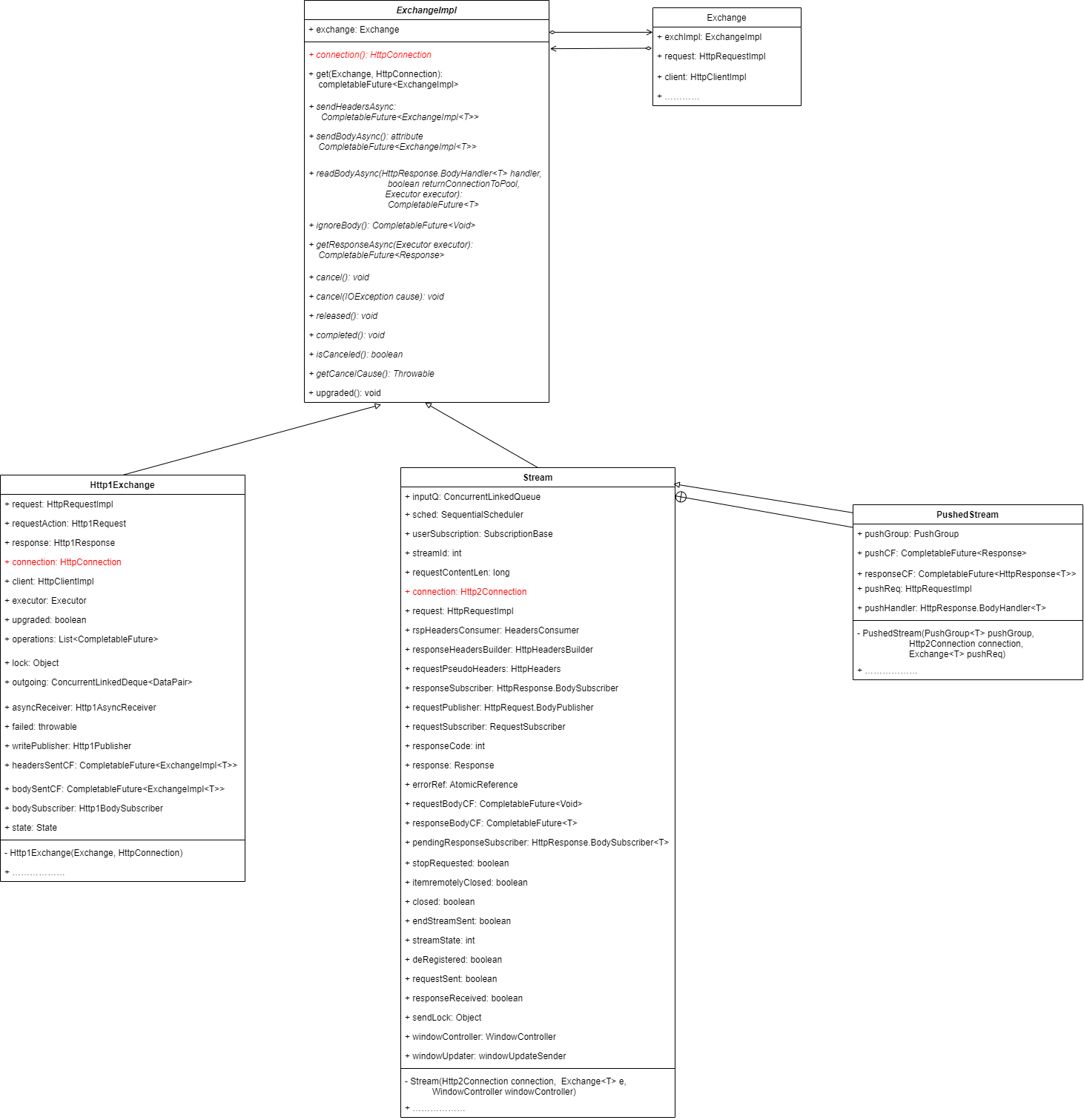
我们跟随进入get静态方法,可以看到根据当前交换版本(HTTP版本)的不同,实例化不同的Http子类。如果我们在调用时,指定了Http客户端或请求的版本号:
HttpClient client = HttpClient.newBuilder()
.version(HttpClient.Version.HTTP_1_1) //指定客户端为Http1.1版本
.build();
HttpRequest request = HttpRequest.newBuilder(URI.create(url))
.version(HttpClient.Version.HTTP_1_1) //或者指定请求的版本号为Http1.1
.GET().build();
那么,下面的get方法中,将会实例化Http1交换:Http1Exchange,否则,默认尝试建立的是Http2的交换:Stream。
/**
* Initiates a new exchange and assigns it to a connection if one exists
* already. connection usually null.
*/
static <U> CompletableFuture<? extends ExchangeImpl<U>>
get(Exchange<U> exchange, HttpConnection connection)
{
if (exchange.version() == HTTP_1_1) {
if (debug.on())
debug.log("get: HTTP/1.1: new Http1Exchange");
//创建Http1交换
return createHttp1Exchange(exchange, connection);
} else {
Http2ClientImpl c2 = exchange.client().client2(); // #### improve
HttpRequestImpl request = exchange.request();
//获取Http2连接
CompletableFuture<Http2Connection> c2f = c2.getConnectionFor(request, exchange);
if (debug.on())
debug.log("get: Trying to get HTTP/2 connection");
// local variable required here; see JDK-8223553
//创建Http2交换
CompletableFuture<CompletableFuture<? extends ExchangeImpl<U>>> fxi =
c2f.handle((h2c, t) -> createExchangeImpl(h2c, t, exchange, connection));
return fxi.thenCompose(x->x);
}
}
我们假定调用时指定了Http1.1版本号,继续关注Exchange的创建和连接建立过程。createHttp1Exchange方法调用了Http1Exchange的构造函数,我们跟随进入:
Http1Exchange(Exchange<T> exchange, HttpConnection connection)
throws IOException
{
super(exchange);
this.request = exchange.request();
this.client = exchange.client();
this.executor = exchange.executor();
this.operations = new LinkedList<>();
operations.add(headersSentCF);
operations.add(bodySentCF);
if (connection != null) {
this.connection = connection;
} else {
InetSocketAddress addr = request.getAddress();
//获取连接
this.connection = HttpConnection.getConnection(addr, client, request, HTTP_1_1);
}
this.requestAction = new Http1Request(request, this);
this.asyncReceiver = new Http1AsyncReceiver(executor, this);
}
我们看到,Http1Exchange中维持了抽象连接(connection)的引用,并在构造方法中获取了具体的连接。根据连接类型的不同,HttpConnection总共有6个实现类,它们的区别是否使用了SSL或代理。值得注意的是,Http2Connection并不在此体系内,它内部组合了一个HttpConnection的抽象成员。这说明了,Http2Connection实际上修饰了HttpConnection。
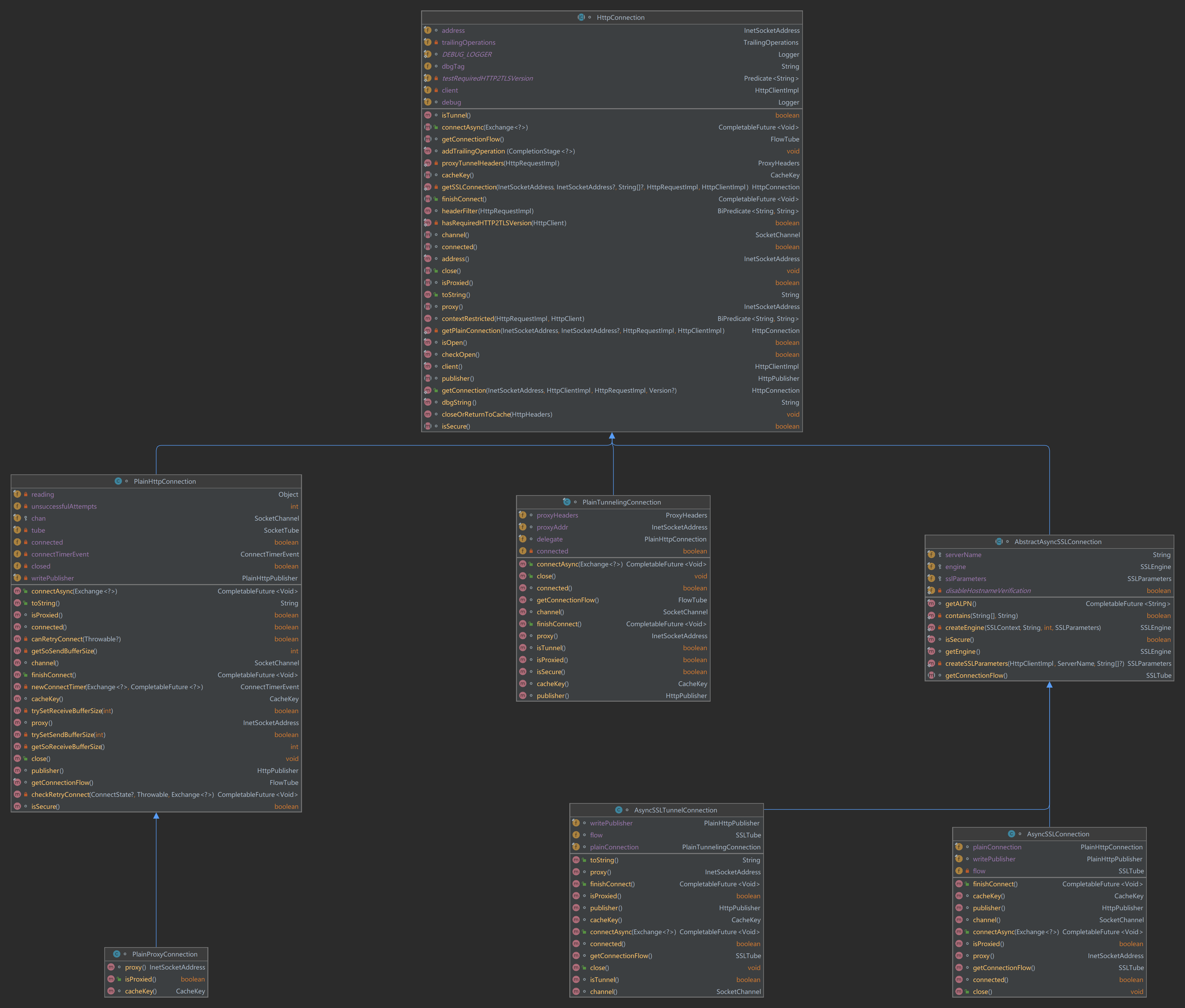
我们回到Http1。关注在Http1Exchange构造方法中出现的获取连接的方法HttpConnection::getConnection。
/**
* Factory for retrieving HttpConnections. A connection can be retrieved
* from the connection pool, or a new one created if none available.
*
* The given {@code addr} is the ultimate destination. Any proxies,
* etc, are determined from the request. Returns a concrete instance which
* is one of the following:
* {@link PlainHttpConnection}
* {@link PlainTunnelingConnection}
*
* The returned connection, if not from the connection pool, must have its,
* connect() or connectAsync() method invoked, which ( when it completes
* successfully ) renders the connection usable for requests.
*/
public static HttpConnection getConnection(InetSocketAddress addr,
HttpClientImpl client,
HttpRequestImpl request,
Version version) {
// The default proxy selector may select a proxy whose address is
// unresolved. We must resolve the address before connecting to it.
InetSocketAddress proxy = Utils.resolveAddress(request.proxy());
HttpConnection c = null;
//根据请求是否加密来决定连接类型
boolean secure = request.secure();
ConnectionPool pool = client.connectionPool();
if (!secure) {
//非加密连接
//尝试从连接池中获取
c = pool.getConnection(false, addr, proxy);
if (c != null && c.checkOpen() /* may have been eof/closed when in the pool */) {
final HttpConnection conn = c;
if (DEBUG_LOGGER.on())
DEBUG_LOGGER.log(conn.getConnectionFlow()
+ ": plain connection retrieved from HTTP/1.1 pool");
return c;
} else {
//连接池中取不到连接,创建新连接
return getPlainConnection(addr, proxy, request, client);
}
} else { // secure
if (version != HTTP_2) { // only HTTP/1.1 connections are in the pool
//有代理的Http1.1链接
c = pool.getConnection(true, addr, proxy);
}
if (c != null && c.isOpen()) {
final HttpConnection conn = c;
if (DEBUG_LOGGER.on())
DEBUG_LOGGER.log(conn.getConnectionFlow()
+ ": SSL connection retrieved from HTTP/1.1 pool");
return c;
} else {
String[] alpn = null;
if (version == HTTP_2 && hasRequiredHTTP2TLSVersion(client)) {
alpn = new String[] { "h2", "http/1.1" };
}
//创建SSL连接
return getSSLConnection(addr, proxy, alpn, request, client);
}
}
}
可以看到,连接到获取过程运用了池化技术,首先尝试从连接池中获取连接,获取不到再新建连接。使用连接池的好处,不在于减少对象创建的时间,而在于大大减少TCP连接“三次握手”的时间开销。
那么,HTTP1.1连接是怎样缓存和复用的呢?我们可以关注连接池类(ConnectionPool)。连接池在客户端初始化时被初始化,它内部使用了散列表来维护路由和之前建立的HTTP连接列表的关系。其中,加密连接存在名为sslPool的HashMap中,而普通连接存在plainPool中。取连接时,将请求地址和代理地址信息组合成缓存键,根据键去散列表中取出对应的第一个连接,返回给调用者。
/**
* Http 1.1 connection pool.
*/
final class ConnectionPool {
//20分钟的默认keepalive时间
static final long KEEP_ALIVE = Utils.getIntegerNetProperty(
"jdk.httpclient.keepalive.timeout", 1200); // seconds
//连接池大小不做限制
static final long MAX_POOL_SIZE = Utils.getIntegerNetProperty(
"jdk.httpclient.connectionPoolSize", 0); // unbounded
final Logger debug = Utils.getDebugLogger(this::dbgString, Utils.DEBUG);
// Pools of idle connections
//用散列表来维护路由和Http连接的映射关系
private final HashMap<CacheKey,LinkedList<HttpConnection>> plainPool;
private final HashMap<CacheKey,LinkedList<HttpConnection>> sslPool;
private final ExpiryList expiryList;
private final String dbgTag; // used for debug
boolean stopped;
/**
连接池中路由——连接映射表的缓存键。使用了目的地址和代理地址组合作为缓存键。
* Entries in connection pool are keyed by destination address and/or
* proxy address:
* case 1: plain TCP not via proxy (destination only)
* case 2: plain TCP via proxy (proxy only)
* case 3: SSL not via proxy (destination only)
* case 4: SSL over tunnel (destination and proxy)
*/
static class CacheKey {
final InetSocketAddress proxy;
final InetSocketAddress destination;
CacheKey(InetSocketAddress destination, InetSocketAddress proxy) {
this.proxy = proxy;
this.destination = destination;
}
@Override
public boolean equals(Object obj) {
if (obj == null) {
return false;
}
if (getClass() != obj.getClass()) {
return false;
}
final CacheKey other = (CacheKey) obj;
if (!Objects.equals(this.proxy, other.proxy)) {
return false;
}
if (!Objects.equals(this.destination, other.destination)) {
return false;
}
return true;
}
@Override
public int hashCode() {
return Objects.hash(proxy, destination);
}
}
ConnectionPool(long clientId) {
this("ConnectionPool("+clientId+")");
}
/**
* There should be one of these per HttpClient.
*/
private ConnectionPool(String tag) {
dbgTag = tag;
plainPool = new HashMap<>();
sslPool = new HashMap<>();
expiryList = new ExpiryList();
}
//省略部分代码
//从连接池获取连接的方法
synchronized HttpConnection getConnection(boolean secure,
InetSocketAddress addr,
InetSocketAddress proxy) {
if (stopped) return null;
// for plain (unsecure) proxy connection the destination address is irrelevant.
addr = secure || proxy == null ? addr : null;
CacheKey key = new CacheKey(addr, proxy);
HttpConnection c = secure ? findConnection(key, sslPool)
: findConnection(key, plainPool);
//System.out.println ("getConnection returning: " + c);
assert c == null || c.isSecure() == secure;
return c;
}
private HttpConnection findConnection(CacheKey key,
HashMap<CacheKey,LinkedList<HttpConnection>> pool) {
//从连接池中取出对应的连接列表
LinkedList<HttpConnection> l = pool.get(key);
if (l == null || l.isEmpty()) {
return null;
} else {
//对应请求地址的第一个连接,即是最老的一个连接
HttpConnection c = l.removeFirst();
//从过期时间列表中移除这个连接
expiryList.remove(c);
return c;
}
}
//暂时省略
}
上面就是Http1.1的池化连接获取过程。而Http2连接的获取有所不同,它是将scheme::host::port组成一个字符串,从自身维护的池里取的。这里就不展开了。
在这之后,我们的分析都以Http1.1,PlainHttpConnection为基准。
我们回到HttpConnection的getPlainConnection方法,此方法在当从连接池取不到连接,或取出的连接已关闭时被调用。该方法的目的是获取新的连接。可以看到,这里还是会根据请求类型和是否有代理来实例化不同的连接:
private static HttpConnection getPlainConnection(InetSocketAddress addr,
InetSocketAddress proxy,
HttpRequestImpl request,
HttpClientImpl client) {
if (request.isWebSocket() && proxy != null)
return new PlainTunnelingConnection(addr, proxy, client,
proxyTunnelHeaders(request));
if (proxy == null)
//创建最基本的Http连接
return new PlainHttpConnection(addr, client);
else
return new PlainProxyConnection(proxy, client);
}
我们进入PlainHttpConnection的构造函数:
/**
* Plain raw TCP connection direct to destination.
* The connection operates in asynchronous non-blocking mode.
* All reads and writes are done non-blocking.
*/
class PlainHttpConnection extends HttpConnection {
//部分成员变量,可见这里维护了NIO的Socket通道
private final Object reading = new Object();
protected final SocketChannel chan;
//双向socket管道
private final SocketTube tube; // need SocketTube to call signalClosed().
private final PlainHttpPublisher writePublisher = new PlainHttpPublisher(reading);
private volatile boolean connected;
private boolean closed;
private volatile ConnectTimerEvent connectTimerEvent; // may be null
private volatile int unsuccessfulAttempts;
// Indicates whether a connection attempt has succeeded or should be retried.
// If the attempt failed, and shouldn't be retried, there will be an exception
// instead.
private enum ConnectState { SUCCESS, RETRY }
//构造函数
PlainHttpConnection(InetSocketAddress addr, HttpClientImpl client) {
super(addr, client);
try {
//打开一个socket通道,实例化chan属性,并设置为非阻塞模式
this.chan = SocketChannel.open();
chan.configureBlocking(false);
//设置缓冲区的大小
if (debug.on()) {
int bufsize = getSoReceiveBufferSize();
debug.log("Initial receive buffer size is: %d", bufsize);
bufsize = getSoSendBufferSize();
debug.log("Initial send buffer size is: %d", bufsize);
}
if (trySetReceiveBufferSize(client.getReceiveBufferSize())) {
if (debug.on()) {
int bufsize = getSoReceiveBufferSize();
debug.log("Receive buffer size configured: %d", bufsize);
}
}
if (trySetSendBufferSize(client.getSendBufferSize())) {
if (debug.on()) {
int bufsize = getSoSendBufferSize();
debug.log("Send buffer size configured: %d", bufsize);
}
}
//设置禁用TCP粘包算法
chan.setOption(StandardSocketOptions.TCP_NODELAY, true);
// wrap the channel in a Tube for async reading and writing
//将nio socket通道包裹在实例化的socket管道成员变量中
//稍后将分析其内部结构和功能
tube = new SocketTube(client(), chan, Utils::getBuffer);
} catch (IOException e) {
throw new InternalError(e);
}
}
}
可见,对PlainHttpConnection的实例化过程中,开启了一个非阻塞模式的socket通道,并将其包裹在一个实例化的socketTube管道中,而socketTube管道,就是我们下一节要分析的重点。在此之前,我们先分析连接的降级过程。
3.2 连接的降级和升级
在上一小节中,我们提到,ExchangeImpl的静态get方法,通过判断版本号来决定实例化自身的那个子类。如果我们在调用时没有指定Http1.1版本,那么get方法将尝试实例化Stream(Http2的流)。可是,我们调用的是Http连接,为什么会实例化Http2呢?不是注定失败吗?
其实,Http2规范并未规定一定要建立在SSL(TLS)上。在Http2已经普及的今天,HttpClient自然首选尝试Http2。在连接建立时,客户端和服务器会通过alpn(Application Layer Protocol Negotiation, 应用层协议协商)进行沟通,确定要建立的连接类型。服务器告知只支持Http1.1连接时,HttpClient也必须进行连接的降级。
我们跟随代码,进行分析:
static <U> CompletableFuture<? extends ExchangeImpl<U>>
get(Exchange<U> exchange, HttpConnection connection)
{
if (exchange.version() == HTTP_1_1) {
if (debug.on())
debug.log("get: HTTP/1.1: new Http1Exchange");
return createHttp1Exchange(exchange, connection);
} else {
//获取HttpclientImpl的成员变量Httpclient2Impl
Http2ClientImpl c2 = exchange.client().client2(); // #### improve
HttpRequestImpl request = exchange.request();
//尝试异步获取Http2连接,如果失败,那么c2f中的结果将为空
CompletableFuture<Http2Connection> c2f = c2.getConnectionFor(request, exchange);
if (debug.on())
debug.log("get: Trying to get HTTP/2 connection");
// local variable required here; see JDK-8223553
//对可能获取到,也可能获取不到的Http2连接的处理,决定实例化Stream还是Http1Exchange
//我们稍后进入
CompletableFuture<CompletableFuture<? extends ExchangeImpl<U>>> fxi =
c2f.handle((h2c, t) -> createExchangeImpl(h2c, t, exchange, connection));
return fxi.thenCompose(x->x);
}
}
我们进入Http2ClientImpl.getConnectionFor方法。在我们要访问的url不支持http2时,有两种情况:http开头的地址,直接获取Http2连接失败;https开头的地址,会尝试建立Http2连接,但协商失败后,以异常告终。
CompletableFuture<Http2Connection> getConnectionFor(HttpRequestImpl req,
Exchange<?> exchange) {
URI uri = req.uri();
InetSocketAddress proxy = req.proxy();
String key = Http2Connection.keyFor(uri, proxy);
synchronized (this) {
//尝试从Http2连接池中获取连接,当然是获取不到的
Http2Connection connection = connections.get(key);
if (connection != null) {
try {
if (connection.closed || !connection.reserveStream(true)) {
if (debug.on())
debug.log("removing found closed or closing connection: %s", connection);
deleteConnection(connection);
} else {
// fast path if connection already exists
if (debug.on())
debug.log("found connection in the pool: %s", connection);
return MinimalFuture.completedFuture(connection);
}
} catch (IOException e) {
// thrown by connection.reserveStream()
return MinimalFuture.failedFuture(e);
}
}
//情况1:访问的是http连接。因为ALPN是对SSL/TLS协议的拓展,
//那么这里就不用考虑了,直接返回null,获取http2连接失败
if (!req.secure() || failures.contains(key)) {
// secure: negotiate failed before. Use http/1.1
// !secure: no connection available in cache. Attempt upgrade
if (debug.on()) debug.log("not found in connection pool");
return MinimalFuture.completedFuture(null);
}
}
return Http2Connection
//情况2:尝试继续获取Http2连接,后续将看到,这里也会以失败告终
.createAsync(req, this, exchange)
.whenComplete((conn, t) -> {
synchronized (Http2ClientImpl.this) {
if (conn != null) {
try {
conn.reserveStream(true);
} catch (IOException e) {
throw new UncheckedIOException(e); // shouldn't happen
}
offerConnection(conn);
} else {
Throwable cause = Utils.getCompletionCause(t);
if (cause instanceof Http2Connection.ALPNException)
failures.add(key);
}
}
});
}
我们跟踪Http2Connection.createAsync方法,会跟踪到Http2Connection::checkSSLConfig方法。下方可以看到,当尝试使用alpn协商用Http2连接无果时,会以失败终结建立Http2Connection对象的completableFuture。
//检查ssl握手情况,在https连接时会被调用
private static CompletableFuture<?> checkSSLConfig(AbstractAsyncSSLConnection aconn) {
assert aconn.isSecure();
Function<String, CompletableFuture<Void>> checkAlpnCF = (alpn) -> {
CompletableFuture<Void> cf = new MinimalFuture<>();
SSLEngine engine = aconn.getEngine();
String engineAlpn = engine.getApplicationProtocol();
assert Objects.equals(alpn, engineAlpn)
: "alpn: %s, engine: %s".formatted(alpn, engineAlpn);
DEBUG_LOGGER.log("checkSSLConfig: alpn: %s", alpn );
//尝试alpn协商,结果不是"h2",说明服务器不支持http2,只有尝试降级
if (alpn == null || !alpn.equals("h2")) {
String msg;
if (alpn == null) {
Log.logSSL("ALPN not supported");
msg = "ALPN not supported";
} else {
switch (alpn) {
case "":
Log.logSSL(msg = "No ALPN negotiated");
break;
case "http/1.1":
Log.logSSL( msg = "HTTP/1.1 ALPN returned");
break;
default:
Log.logSSL(msg = "Unexpected ALPN: " + alpn);
cf.completeExceptionally(new IOException(msg));
}
}
//以异常终结Http2连接的尝试
cf.completeExceptionally(new ALPNException(msg, aconn));
return cf;
}
cf.complete(null);
return cf;
};
return aconn.getALPN()
.whenComplete((r,t) -> {
if (t != null && t instanceof SSLException) {
// something went wrong during the initial handshake
// close the connection
aconn.close();
}
})
.thenCompose(checkAlpnCF);
}
在Http2协商连接失败的情况下,异步返回给ExchangeImpl的get方法的c2f,不会有结果。可以预想的是,之后便是Http1.1交换的建立过程。除此之外,还会发生什么呢?
我们将看到,HttpClient可谓是“锲而不舍”,对无法Alpn协商的http请求,也会对请求头进行修饰,尝试进行协议的升级。
由于ExchangeImpl::get方法调用了createExchangeImpl方法,我们跟随进入:
private static <U> CompletableFuture<? extends ExchangeImpl<U>>
createExchangeImpl(Http2Connection c,
Throwable t,
Exchange<U> exchange,
HttpConnection connection)
{
if (debug.on())
debug.log("handling HTTP/2 connection creation result");
boolean secure = exchange.request().secure();
if (t != null) {
if (debug.on())
debug.log("handling HTTP/2 connection creation failed: %s",
(Object)t);
t = Utils.getCompletionCause(t);
if (t instanceof Http2Connection.ALPNException) {
//如果我们访问的是Http1.1的https开头的连接,那么会进入该分支
Http2Connection.ALPNException ee = (Http2Connection.ALPNException)t;
AbstractAsyncSSLConnection as = ee.getConnection();
if (debug.on())
debug.log("downgrading to HTTP/1.1 with: %s", as);
//建立Http1Exchange,会复用原来的AsyncSSLConnection
CompletableFuture<? extends ExchangeImpl<U>> ex =
createHttp1Exchange(exchange, as);
return ex;
} else {
if (debug.on())
debug.log("HTTP/2 connection creation failed "
+ "with unexpected exception: %s", (Object)t);
return MinimalFuture.failedFuture(t);
}
}
if (secure && c== null) {
if (debug.on())
debug.log("downgrading to HTTP/1.1 ");
CompletableFuture<? extends ExchangeImpl<U>> ex =
createHttp1Exchange(exchange, null);
return ex;
}
if (c == null) {
//在我们要访问的地址是http开头时,会进入该分支,此时建立Http1.1连接,并尝试连接升级
// no existing connection. Send request with HTTP 1 and then
// upgrade if successful
if (debug.on())
debug.log("new Http1Exchange, try to upgrade");
return createHttp1Exchange(exchange, connection)
.thenApply((e) -> {
//尝试连接升级,其实就是在请求头加上Connection、Upgrade和Http2-Settings字段
exchange.h2Upgrade();
return e;
});
} else {
if (debug.on()) debug.log("creating HTTP/2 streams");
Stream<U> s = c.createStream(exchange);
CompletableFuture<? extends ExchangeImpl<U>> ex = MinimalFuture.completedFuture(s);
return ex;
}
}
我们看到,对Http开头的地址的访问会尝试进行Http2连接的升级,即先用Http1请求的方式向服务器请求升级成Http2,若服务器响应,则会进行升级。升级相关步骤在一次请求——响应过程之后。为了和本节主题贴切,我们也过一眼:
private CompletableFuture<Response>
checkForUpgradeAsync(Response resp,
ExchangeImpl<T> ex) {
int rcode = resp.statusCode();
//响应状态码是101时,代表服务器接收协议升级到Http2
if (upgrading && (rcode == 101)) {
Http1Exchange<T> e = (Http1Exchange<T>)ex;
// check for 101 switching protocols
// 101 responses are not supposed to contain a body.
// => should we fail if there is one?
if (debug.on()) debug.log("Upgrading async %s", e.connection());
return e.readBodyAsync(this::ignoreBody, false, parentExecutor)
.thenCompose((T v) -> {// v is null
debug.log("Ignored body");
// we pass e::getBuffer to allow the ByteBuffers to accumulate
// while we build the Http2Connection
ex.upgraded();
upgraded = true;
//建立Http2连接
return Http2Connection.createAsync(e.connection(),
client.client2(),
this, e::drainLeftOverBytes)
.thenCompose((Http2Connection c) -> {
boolean cached = c.offerConnection();
if (cached) connectionAborter.disable();
Stream<T> s = c.getStream(1);
//省略………………
);
}
return MinimalFuture.completedFuture(resp);
}
在此,Http连接降级和升级的过程就介绍完毕。我们将进入激动人心的环节:数据是怎样被发送的。
4. 响应式读写流的连接
看到上面Http连接的建立,我们似乎没有看到对应的TCP连接到建立?没错,是的。在初次请求建立连接时,JDK HttpClient把socket连接的建立推迟到了发送请求头的相关方法中。
我们承接上面对建立PlainHttpConnection连接的分析,看看最后实例化的SocketTube是什么。从下方的UML图中可以看到,socketTube是FlowTube接口的实现,它的另一个实现类是SSLTube。
4.1 socket管道的结构和功能

那么,FlowTube是什么呢?从FlowTube的结构和注释上看,其同时扮演了JAVA Flow Api(Reactive Streams)中的发布者和订阅者。作为一个”连接者“,它一端连接了Socket通道的读写,另一端连接了Http报文的读写。
/**
谷歌翻译原注释:
FlowTube 是一种 I/O 抽象,允许异步读取和写入目标。 这不是 Flow.Processor<List<ByteBuffer>, List<ByteBuffer>>,而是在双向流中对发布者源和订阅者接收器进行建模。
应该调用 connectFlows 方法来连接双向流。 FlowTube 支持随着时间的推移将相同的读取订阅移交给不同的顺序读取订阅者。 当 connectFlows(writePublisher, readSubscriber 被调用时,FlowTube 将在其以前的 readSubscriber 上调用 dropSubscription,在其新的 readSubscriber 上调用 onSubscribe。
*/
public interface FlowTube extends
Flow.Publisher<List<ByteBuffer>>,
Flow.Subscriber<List<ByteBuffer>> {
/**
* 用于从双向流中读取的订阅者。 TubeSubscriber 是可以通过调用 dropSubscription() 取消的 Flow.Subscriber。 一旦调用 dropSubscription(),TubeSubscriber 就应该停止调用其订阅的任何方法。
*/
static interface TubeSubscriber extends Flow.Subscriber<List<ByteBuffer>> {
default void dropSubscription() { }
default boolean supportsRecycling() { return false; }
}
/**
一个向双向流写入的发布者
* A publisher for writing to the bidirectional flow.
*/
static interface TubePublisher extends Flow.Publisher<List<ByteBuffer>> {
}
/**
* 将双向流连接到写入发布者和读取订阅者。 可以多次顺序调用此方法以将现有发布者和订阅者切换为新的写入订阅者和读取发布者对。
* @param writePublisher A new publisher for writing to the bidirectional flow.
* @param readSubscriber A new subscriber for reading from the bidirectional
* flow.
*/
default void connectFlows(TubePublisher writePublisher,
TubeSubscriber readSubscriber) {
this.subscribe(readSubscriber);
writePublisher.subscribe(this);
}
/**
* Returns true if this flow was completed, either exceptionally
* or normally (EOF reached).
* @return true if the flow is finished
*/
boolean isFinished();
}
这里再稍微提一下Reactive Streams反应式流的交互方式:
- 发布者(Publisher) 接受订阅者(Subscriber)的订阅:publisher.subscribe(Subscriber)
- 发布者将一个订阅关系(Subscription)交给订阅者:subscriber.onSubscribe(Subscription)
- 订阅者请求n个订阅:subscription.request(n)
- 订阅者接受至多n个订阅品:subscriber.onNext(T item)
- 订阅者可取消订阅:subscription.cancel()
- 订阅者接收 接收完成 和 发生错误 的通知:subscriber.onError(Throwable); subscriber.onComplete()
我们看下SocketTube的构造函数:
/**
* A SocketTube is a terminal tube plugged directly into the socket.
* The read subscriber should call {@code subscribe} on the SocketTube before
* the SocketTube is subscribed to the write publisher.
*/
final class SocketTube implements FlowTube {
final Logger debug = Utils.getDebugLogger(this::dbgString, Utils.DEBUG);
static final AtomicLong IDS = new AtomicLong();
private final HttpClientImpl client;
//nio 的 socket 通道
private final SocketChannel channel;
private final SliceBufferSource sliceBuffersSource;
private final Object lock = new Object();
private final AtomicReference<Throwable> errorRef = new AtomicReference<>();
private final InternalReadPublisher readPublisher;
private final InternalWriteSubscriber writeSubscriber;
private final long id = IDS.incrementAndGet();
public SocketTube(HttpClientImpl client, SocketChannel channel,
Supplier<ByteBuffer> buffersFactory) {
this.client = client;
this.channel = channel;
this.sliceBuffersSource = new SliceBufferSource(buffersFactory);
//这里实例化了两个对象作为属性:内部读发布者和内部写接受者
this.readPublisher = new InternalReadPublisher();
this.writeSubscriber = new InternalWriteSubscriber();
}
}
在构造方法中,SocketTube实例化了readPublisher和writeSubscriber。它们的类型分别是SocketTube的内部类InternalReadPublisher和InternalWriteSubscriber,从名称就可以看出它们的位置和作用:
- ReadPublisher从socket通道读取内容,并”发布“到管道中,等待消费者接收并将内容解析成Http请求头和请求体
- WriteSubscriber”订阅“Http报文,它等待Http内容的发布者将报文写入到SocketTube后,取出报文并写入socket通道
这些我们将在稍后到分析中继续深入。
4.2 socket 连接的建立
铺垫了这么多,socket连接究竟是如何建立的呢?答案就蕴含在FlowTube的默认方法connectFlows中(SocketTube重写了这一方法,但只是加了一行日志打印)。该方法要求调用方传入一个来源于一个”源“的发布者和一个订阅者,这样,调用方和SocketTube之间就建立了双向订阅关系。
@Override
public void connectFlows(TubePublisher writePublisher,
TubeSubscriber readSubscriber) {
//socketTube类的connectFlow方法
if (debug.on()) debug.log("connecting flows");
this.subscribe(readSubscriber);
writePublisher.subscribe(this);
}
为了见证这一历程,我们必须回过头来,回到Exchange的responseAsyncImpl0方法中。
CompletableFuture<Response> responseAsyncImpl0(HttpConnection connection) {
Function<ExchangeImpl<T>, CompletableFuture<Response>> after407Check;
bodyIgnored = null;
if (request.expectContinue()) {
request.addSystemHeader("Expect", "100-Continue");
Log.logTrace("Sending Expect: 100-Continue");
// wait for 100-Continue before sending body
after407Check = this::expectContinue;
} else {
after407Check = this::sendRequestBody;
}
// The ProxyAuthorizationRequired can be triggered either by
// establishExchange (case of HTTP/2 SSL tunneling through HTTP/1.1 proxy
// or by sendHeaderAsync (case of HTTP/1.1 SSL tunneling through HTTP/1.1 proxy
// Therefore we handle it with a call to this checkFor407(...) after these
// two places.
Function<ExchangeImpl<T>, CompletableFuture<Response>> afterExch407Check =
//现在,让我们关注这个名为异步发送请求头的方法,连接建立的过程就蕴含其中
(ex) -> ex.sendHeadersAsync()
.handle((r,t) -> this.checkFor407(r, t, after407Check))
.thenCompose(Function.identity());
return establishExchange(connection) //首先建立连接
.handle((r,t) -> this.checkFor407(r,t, afterExch407Check))
.thenCompose(Function.identity());
}
我们进入ExchangeImpl::sendHeadersAsync方法。这里展示的是Http1Exchange的重写方法:
@Override
CompletableFuture<ExchangeImpl<T>> sendHeadersAsync() {
// create the response before sending the request headers, so that
// the response can set the appropriate receivers.
if (debug.on()) debug.log("Sending headers only");
// If the first attempt to read something triggers EOF, or
// IOException("channel reset by peer"), we're going to retry.
// Instruct the asyncReceiver to throw ConnectionExpiredException
// to force a retry.
asyncReceiver.setRetryOnError(true);
if (response == null) {
//这里生成了响应对象。内部,asyncReceiver完成了对请求头的“订阅”
response = new Http1Response<>(connection, this, asyncReceiver);
}
if (debug.on()) debug.log("response created in advance");
CompletableFuture<Void> connectCF;
if (!connection.connected()) {
//注意,首次建立连接时,socket连接时没有建立的,会在这里建立连接
if (debug.on()) debug.log("initiating connect async");
//异步建立并完成socket连接,我们即将进入分析
connectCF = connection.connectAsync(exchange)
//异步将连接标记为已连接
.thenCompose(unused -> connection.finishConnect());
Throwable cancelled;
synchronized (lock) {
if ((cancelled = failed) == null) {
operations.add(connectCF);
}
}
if (cancelled != null) {
if (client.isSelectorThread()) {
executor.execute(() ->
connectCF.completeExceptionally(cancelled));
} else {
connectCF.completeExceptionally(cancelled);
}
}
} else {
connectCF = new MinimalFuture<>();
connectCF.complete(null);
}
return connectCF
.thenCompose(unused -> {
CompletableFuture<Void> cf = new MinimalFuture<>();
try {
asyncReceiver.whenFinished.whenComplete((r,t) -> {
if (t != null) {
if (debug.on())
debug.log("asyncReceiver finished (failed=%s)", (Object)t);
if (!headersSentCF.isDone())
headersSentCF.completeAsync(() -> this, executor);
}
});
//这里最终调用了FlowTube::connectFlows方法,建立了双向的连接
//我们即将分析
connectFlows(connection);
if (debug.on()) debug.log("requestAction.headers");
//从请求中取出请求头数据
List<ByteBuffer> data = requestAction.headers();
synchronized (lock) {
state = State.HEADERS;
}
if (debug.on()) debug.log("setting outgoing with headers");
assert outgoing.isEmpty() : "Unexpected outgoing:" + outgoing;
//放到输出的队列里面,我们下一节将分析
appendToOutgoing(data);
cf.complete(null);
return cf;
} catch (Throwable t) {
if (debug.on()) debug.log("Failed to send headers: %s", t);
headersSentCF.completeExceptionally(t);
bodySentCF.completeExceptionally(t);
connection.close();
cf.completeExceptionally(t);
return cf;
} })
.thenCompose(unused -> headersSentCF);
}
该方法名为”发送请求头“,实际上做了几件事:
- 异步建立socket连接
- 与管道(不是socket通道)建立双向订阅关系
- 取出请求头,放入到队列,并通知管道端的订阅者消费
我们将在本节分析前两个步骤。首先看下异步socket连接的建立:PlainHttpConnection::connectAsync方法
//PlainHttpConnection类实现的HttpConnection抽象类的connectAsync方法
@Override
public CompletableFuture<Void> connectAsync(Exchange<?> exchange) {
CompletableFuture<ConnectState> cf = new MinimalFuture<>();
try {
assert !connected : "Already connected";
assert !chan.isBlocking() : "Unexpected blocking channel";
boolean finished;
if (connectTimerEvent == null) {
//连接超时计时器的注册,这一步会唤醒阻塞的selector线程
connectTimerEvent = newConnectTimer(exchange, cf);
if (connectTimerEvent != null) {
if (debug.on())
debug.log("registering connect timer: " + connectTimerEvent);
client().registerTimer(connectTimerEvent);
}
}
//解析DNS地址,然后将该通道的套接字与对应的地址连接
//由于设置了非阻塞模式,这里会立即返回,
//返回时,可能已经连接成功(finished = true),或者之后还需要继续连接(finished = false)
PrivilegedExceptionAction<Boolean> pa =
() -> chan.connect(Utils.resolveAddress(address));
try {
finished = AccessController.doPrivileged(pa);
} catch (PrivilegedActionException e) {
throw e.getCause();
}
if (finished) {
//如果直接就已经连接成功,那么这个异步操作相当于同步了
if (debug.on()) debug.log("connect finished without blocking");
cf.complete(ConnectState.SUCCESS);
} else {
//否则的话,这里需要注册一个连接事件(稍后分析),等待事件就绪后,选择器管理线程分发该事件,
//并调用该事件的handle方法完成连接的建立。
if (debug.on()) debug.log("registering connect event");
client().registerEvent(new ConnectEvent(cf, exchange));
}
cf = exchange.checkCancelled(cf, this);
} catch (Throwable throwable) {
cf.completeExceptionally(Utils.toConnectException(throwable));
try {
close();
} catch (Exception x) {
if (debug.on())
debug.log("Failed to close channel after unsuccessful connect");
}
}
return cf.handle((r,t) -> checkRetryConnect(r, t,exchange))
.thenCompose(Function.identity());
}
阅读上面的方法,我们可以看到,socket连接的建立有两种可能:直接成功;或需等待相应通道就绪后(可连接事件)才成功。这时,便要注册一个连接事件,稍后由选择器线程来调用该事件的handle方法完成连接。流程图如下:

关于选择器管理线程(SelectorManager)的工作过程,在《HttpClient客户端的构建和启动》一篇中有详细介绍。
我们看下ConnectEvent的实现:它是位于PlainHttpConnection的一个内部类。
final class ConnectEvent extends AsyncEvent {
private final CompletableFuture<ConnectState> cf;
private final Exchange<?> exchange;
ConnectEvent(CompletableFuture<ConnectState> cf, Exchange<?> exchange) {
this.cf = cf;
this.exchange = exchange;
}
@Override
public SelectableChannel channel() {
return chan;
}
@Override
public int interestOps() {
//该事件感兴趣的操作是连接事件。
return SelectionKey.OP_CONNECT;
}
//事件处理方法,在连接事件就绪时,选择器管理线程(SelectorManager)会调用
@Override
public void handle() {
try {
assert !connected : "Already connected";
assert !chan.isBlocking() : "Unexpected blocking channel";
if (debug.on())
debug.log("ConnectEvent: finishing connect");
//调用java nio channel 通道的finishConnect方法,在连接就绪(现在)时完成连接
boolean finished = chan.finishConnect();
if (debug.on())
debug.log("ConnectEvent: connect finished: %s, cancelled: %s, Local addr: %s",
finished, exchange.multi.requestCancelled(), chan.getLocalAddress());
assert finished || exchange.multi.requestCancelled() : "Expected channel to be connected";
// complete async since the event runs on the SelectorManager thread
cf.completeAsync(() -> ConnectState.SUCCESS, client().theExecutor());
} catch (Throwable e) {
if (canRetryConnect(e)) {
unsuccessfulAttempts++;
cf.completeAsync(() -> ConnectState.RETRY, client().theExecutor());
return;
}
Throwable t = Utils.toConnectException(e);
client().theExecutor().execute( () -> cf.completeExceptionally(t));
close();
}
}
@Override
public void abort(IOException ioe) {
client().theExecutor().execute( () -> cf.completeExceptionally(ioe));
close();
}
}
这里的操作相对简单,就是调用了Channel::finishConnect方法完成连接。至此,异步socket连接的过程已分析完毕。
4.3 双向读写关系的建立
接着,我们再看下双向连接的建立过程:
//Http1Exchange的私有connectFlows方法
private void connectFlows(HttpConnection connection) {
FlowTube tube = connection.getConnectionFlow();
if (debug.on()) debug.log("%s connecting flows", tube);
// Connect the flow to our Http1TubeSubscriber:
// asyncReceiver.subscriber().
tube.connectFlows(writePublisher,
asyncReceiver.subscriber());
}
理解了4.1节,该方法的目的就显而易见:
SocketTube的InternalReadPublisher和Http1Exchange中的asyncReceiver的订阅器(Http1TubeSubscriber)连接
Http1Exchange中的writePublisher(Http1Publisher)和SocketTube的InternalWriteSubScriber连接
注意,这两步是存在先后顺序的。否则,就可能出现往socket通道写入了数据,而取出的响应数据没有订阅者的问题。
我们看下对应类的部分源码来看看订阅时做了什么:
Http1Publisher
final class Http1Publisher implements FlowTube.TubePublisher {
final Logger debug = Utils.getDebugLogger(this::dbgString);
volatile Flow.Subscriber<? super List<ByteBuffer>> subscriber;
volatile boolean cancelled;
//Http1内容的发布者持有Http1写入这一“订阅”
final Http1WriteSubscription subscription = new Http1WriteSubscription();
final Demand demand = new Demand();
//这里用了一个自定义的调度器来保证读写顺序,我们下一节将关注writeTask
final SequentialScheduler writeScheduler =
SequentialScheduler.lockingScheduler(new WriteTask());
@Override
public void subscribe(Flow.Subscriber<? super List<ByteBuffer>> s) {
assert state == State.INITIAL;
Objects.requireNonNull(s);
assert subscriber == null;
subscriber = s;
if (debug.on()) debug.log("got subscriber: %s", s);
//(在PlainHttpConnection里)使socketTube里面的internalWriteSubscriber接收订阅
s.onSubscribe(subscription);
}
//………………
}
SocketTube的InternalWriteSubscriber(内部类):
private final class InternalWriteSubscriber
implements Flow.Subscriber<List<ByteBuffer>> {
volatile WriteSubscription subscription;
volatile List<ByteBuffer> current;
volatile boolean completed;
//这里维持了触发对初片Http内容的请求所需要的事件
final AsyncTriggerEvent startSubscription =
new AsyncTriggerEvent(this::signalError, this::startSubscription);
final WriteEvent writeEvent = new WriteEvent(channel, this);
final Demand writeDemand = new Demand();
@Override
public void onSubscribe(Flow.Subscription subscription) {
WriteSubscription previous = this.subscription;
if (debug.on()) debug.log("subscribed for writing");
try {
//若是新订阅,则需要注册订阅事件,等待选择器线程分发处理,以触发写入操作
boolean needEvent = current == null;
if (needEvent) {
//若之前已订阅了别的发布者,则丢弃之前的订阅
if (previous != null && previous.upstreamSubscription != subscription) {
previous.dropSubscription();
}
}
//接收新的订阅。这里并没有直接把它作为成员变量,而是薄封装了一个新的订阅作为代理
this.subscription = new WriteSubscription(subscription);
if (needEvent) {
if (debug.on())
debug.log("write: registering startSubscription event");
client.registerEvent(startSubscription);
}
} catch (Throwable t) {
signalError(t);
}
}
}
SocketTube的InternalReadPublisher(内部类):
private final class InternalReadPublisher
implements Flow.Publisher<List<ByteBuffer>> {
//socket内容的发布者持有内部的读取socket信息的订阅
private final InternalReadSubscription subscriptionImpl
= new InternalReadSubscription();
AtomicReference<ReadSubscription> pendingSubscription = new AtomicReference<>();
private volatile ReadSubscription subscription;
@Override
public void subscribe(Flow.Subscriber<? super List<ByteBuffer>> s) {
Objects.requireNonNull(s);
TubeSubscriber sub = FlowTube.asTubeSubscriber(s);
ReadSubscription target = new ReadSubscription(subscriptionImpl, sub);
ReadSubscription previous = pendingSubscription.getAndSet(target);
//这里还是判断之前若已经被订阅了,就丢弃之前的订阅者
if (previous != null && previous != target) {
if (debug.on())
debug.log("read publisher: dropping pending subscriber: "
+ previous.subscriber);
previous.errorRef.compareAndSet(null, errorRef.get());
previous.signalOnSubscribe();
if (subscriptionImpl.completed) {
previous.signalCompletion();
} else {
previous.subscriber.dropSubscription();
}
}
if (debug.on()) debug.log("read publisher got subscriber");
//这一步内部是看sequentialScheduler的情况,选择注册一个订阅事件实现异步订阅,
//最终调用订阅者的onSubscribe方法;或者直接调用subscriber.onSubscribe
subscriptionImpl.signalSubscribe();
debugState("leaving read.subscribe: ");
}
}
Http1AsyncReceiver的Http1TubeSubscriber(内部成员):
final class Http1TubeSubscriber implements TubeSubscriber {
volatile Flow.Subscription subscription;
volatile boolean completed;
volatile boolean dropped;
public void onSubscribe(Flow.Subscription subscription) {
// supports being called multiple time.
// doesn't cancel the previous subscription, since that is
// most probably the same as the new subscription.
if (debug.on()) debug.log("Received onSubscribed from upstream");
if (Log.channel()) {
Log.logChannel("HTTP/1 read subscriber got subscription from {0}", describe());
}
assert this.subscription == null || dropped == false;
//接受订阅时,这里只是简单维持了对订阅的引用
this.subscription = subscription;
dropped = false;
canRequestMore.set(true);
if (delegate != null) {
scheduler.runOrSchedule(executor);
} else {
if (debug.on()) debug.log("onSubscribe: read delegate not present yet");
}
}
}
可以看到,调用connectFlows方法后,发布者和订阅者已经基本处于就绪状态了,但也可能还需要SelectorManager线程的协助才能真正完成订阅。
在上面的代码中,出现了一个scheduler成员,它事实上控制了整个读写的流程。我们必须清楚其作用,否则便会迷失在多变的“调度”过程中。
4.4 顺序调度器简析
上面代码里出现的secheduler变量,属于SequentialScheduler类型。SequentialScheduler类位于jdk.internal.net.http.common包下,是JDK为了简化同一个可重复执行的任务的顺序执行而设计的。它保证了相同的任务互斥执行。
下面是类上的注释说明和翻译。
A scheduler of ( repeatable ) tasks that MUST be run sequentially.
This class can be used as a synchronization aid that assists a number of parties in running a task in a mutually exclusive fashion.
To run the task, a party invokes runOrSchedule. To permanently prevent the task from subsequent runs, the party invokes stop.
The parties can, but do not have to, operate in different threads.
The task can be either synchronous ( completes when its run method returns ), or asynchronous ( completed when its DeferredCompleter is explicitly completed ).
The next run of the task will not begin until the previous run has finished.
The task may invoke runOrSchedule itself, which may be a normal situation.必须按顺序运行的(可重复的)任务的调度程序。 此类可用作同步辅助工具,帮助多方以互斥方式运行任务。
为了运行任务,一方调用 runOrSchedule。 为了永久阻止该任务在后续运行,该方调用 stop。
各方可以但不必在不同的线程中运作。 任务可以是同步的(在其 run 方法返回时完成),也可以是异步的(在其 DeferredCompleter 显式完成时完成)。
在上一次运行完成之前,不会开始下一次任务运行。
任务可能会调用runOrSchedule本身,这可能是正常情况。
我们看下SequentialScheduler的uml类图:
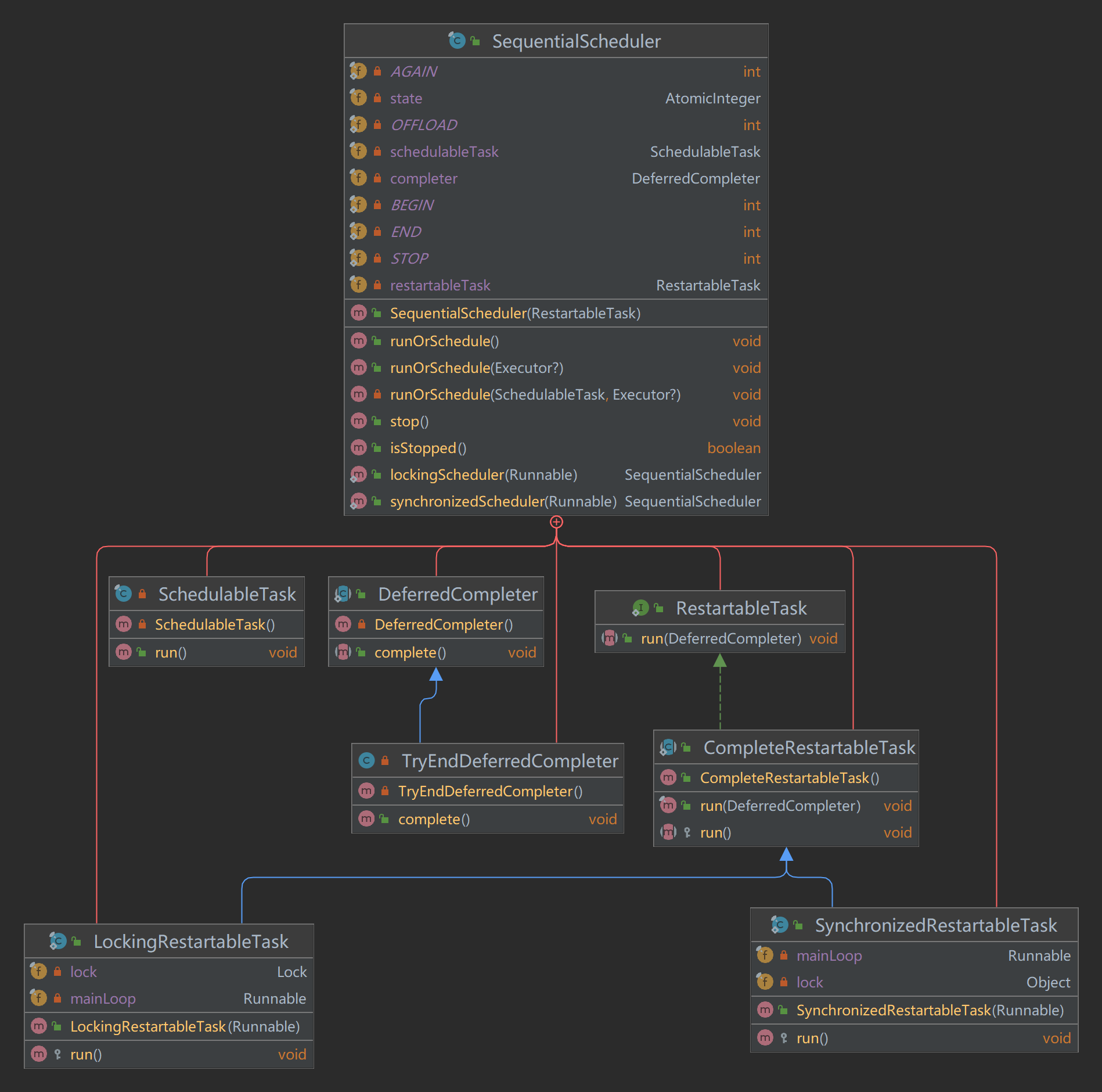
简而言之,该类通过state这个原子整形变量,控制新调用的runOrSchedule方法是否执行。值得注意的是,在多线程调用runOrSchedule方法时,只能有一个任务处于等待状态,其它任务则不会执行。
5. 请求头和请求体的发送
见识了精巧的连接建立过程,我们将要见证请求头和请求体的发送流程。 简而言之,对请求头的发送就是遵循了Reactive Streams规范的发布——订阅过程,其使用了一个线程安全的双向队列维护要输出的数据(请求头+体)。
在请求头的发送过程中,请求头数据的流转可用以下数据流图来描述:
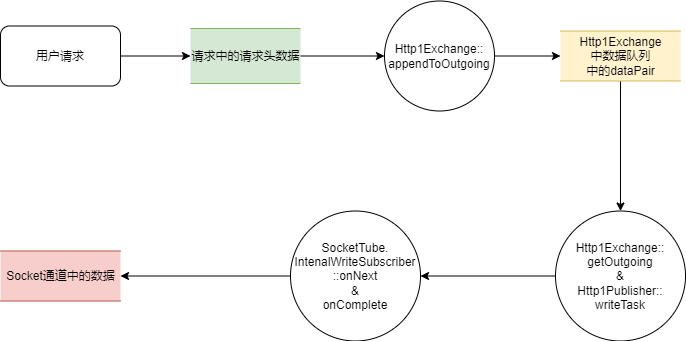
由于本节涉及到经典的响应式流交互,相对复杂,我们先对涉及的相关成员做简要介绍。
5.1 发布和订阅者介绍
在Plain Http1.1 请求——响应过程中,Http1Exchange扮演了请求的发布者和响应的订阅者的角色;而SocketTube则作为了请求的订阅者和响应的发布者。实际上,这些功能是由它们的内部类成员完成的。我们先放出Http1Exchange和SocketTube的UML类图,然后对涉及到的成员做简要介绍。
Http1Exchange的uml类图:
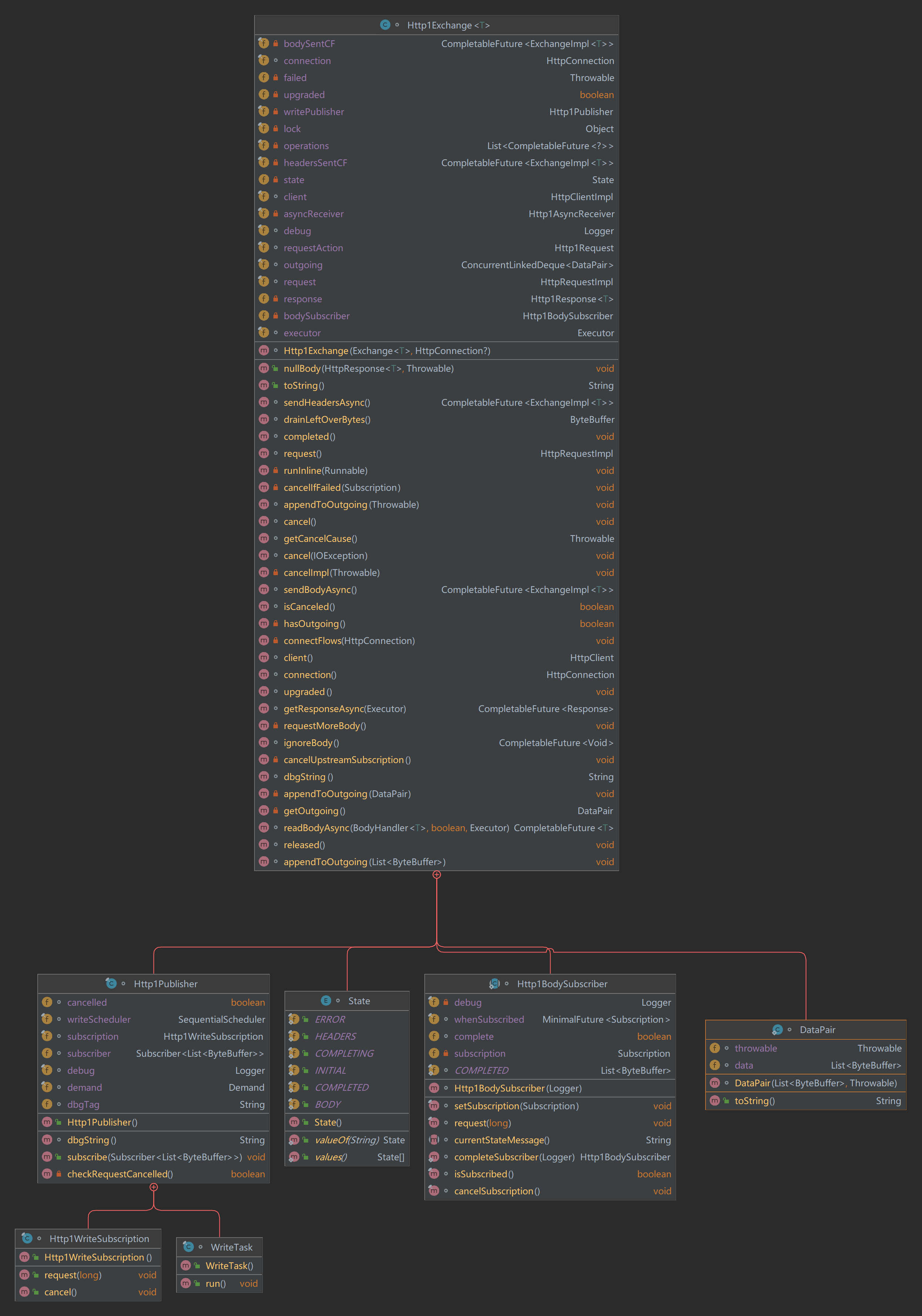
SocketTube的uml类图:

| 类名 | 父类(接口) | 外部类 | 角色 | 功能 |
|---|---|---|---|---|
| Http1Exchange | ExchangeImpl | - | 一次Http1.1请求——响应交换的管理者 | 实现父类方法,管理一次Http1.1请求——响应交换,将具体职责交由内部成员实现 |
| Http1Publisher | FlowTube.TubePublisher、Flow.Publisher | Http1Exchange | Http请求内容的发布者 | 接受管道订阅者的注册;从请求数据缓冲队列取出内容交给订阅者 |
| Http1WriteSubscription | Flow.Subscription | Http1Publisher | Http请求内容的订阅(关系) | 作为媒介,连接发布者和订阅者,接受管道订阅者对Http请求内容的需求并传递给发布者 |
| WriteTask | Runnable | Http1Publisher | 任务 | 作为Http1请求数据发布者(Http1Publisher)要执行的发布任务 |
| DataPair | - | Http1Exchange | 数据组合 | 组合要传输的Http请求分片数据和该分片上的错误,被存放在缓冲队列中等待发布者取出,实现错误通知 |
| SocketTube | Flow.Publisher,Flow.Subscriber | - | socket管道 | 管理和维护socket通道端的发布者和订阅者 |
| InternalWriteSubscriber | Flow.Subscriber | SocketTube | Http请求内容的订阅者 | 接收Http请求数据,将其写入socket通道 |
| WriteSubscription | Flow.Subscription | InternalWriteSubscriber | Http请求内容订阅的包装 | 代理并修饰Http1WriteSubscription的行为,参与开始要求Http请求数据的行为 |
| SocketFlowEvent | AsyncEvent | SocketTube | 通道流事件 | 通道读/写事件的父类,通过改变感兴趣的操作可暂停或启动对通道数据的读写 |
| WriteEvent | SocketFlowEvent | InternalWriteSubscriber | 通道写事件 | 对OP_Write操作感兴趣,用于注册到socket通道上启动写入操作 |
5.2 请求头发送的启动过程
我们回到Http1Exchange的sendHeadersAsync方法:
@Override
CompletableFuture<ExchangeImpl<T>> sendHeadersAsync() {
//留意这里的注释,在发送请求头的时候创建响应,这样响应对象就能设置正确的接收者
// create the response before sending the request headers, so that
// the response can set the appropriate receivers.
if (debug.on()) debug.log("Sending headers only");
// If the first attempt to read something triggers EOF, or
// IOException("channel reset by peer"), we're going to retry.
// Instruct the asyncReceiver to throw ConnectionExpiredException
// to force a retry.
asyncReceiver.setRetryOnError(true);
if (response == null) {
//创建响应
response = new Http1Response<>(connection, this, asyncReceiver);
}
if (debug.on()) debug.log("response created in advance");
CompletableFuture<Void> connectCF;
//这里是异步的建立socket连接过程,前面分析过了,就省略了
//…………
return connectCF
.thenCompose(unused -> {
CompletableFuture<Void> cf = new MinimalFuture<>();
try {
asyncReceiver.whenFinished.whenComplete((r,t) -> {
if (t != null) {
if (debug.on())
debug.log("asyncReceiver finished (failed=%s)", (Object)t);
if (!headersSentCF.isDone())
headersSentCF.completeAsync(() -> this, executor);
}
});
connectFlows(connection);
if (debug.on()) debug.log("requestAction.headers");
//从请求中构建并取出请求头,里面有headers字符串和ByteBuffer的构建过程,略过
List<ByteBuffer> data = requestAction.headers();
//设置这个交换(Exchange)的状态是在发送请求头
synchronized (lock) {
state = State.HEADERS;
}
if (debug.on()) debug.log("setting outgoing with headers");
assert outgoing.isEmpty() : "Unexpected outgoing:" + outgoing;
//这一步把请求头包装成一份dataPair,放入到一个缓冲队列中,并通知订阅者接受
//我们将进入分析
appendToOutgoing(data);
cf.complete(null);
return cf;
} catch (Throwable t) {
if (debug.on()) debug.log("Failed to send headers: %s", t);
headersSentCF.completeExceptionally(t);
bodySentCF.completeExceptionally(t);
connection.close();
cf.completeExceptionally(t);
return cf;
} })
.thenCompose(unused -> headersSentCF);
}
我们看到,请求头信息被取出后,调用了appendToOutgoing(List)方法,我们跟踪进入,同时需要关注outgoing队列:
class Http1Exchange<T> extends ExchangeImpl<T> {
//…………省略
/** Holds the outgoing data, either the headers or a request body part. Or
* an error from the request body publisher. At most there can be ~2 pieces
* of outgoing data ( onComplete|onError can be invoked without demand ).*/
//承载输出数据的队列,充当了响应式流中的“缓冲区”作用
final ConcurrentLinkedDeque<DataPair> outgoing = new ConcurrentLinkedDeque<>();
/** A carrier for either data or an error. Used to carry data, and communicate
* errors from the request ( both headers and body ) to the exchange. */
//Http1Exchange内的静态嵌套类,组合了一个“分片”的数据和错误
static class DataPair {
Throwable throwable;
List<ByteBuffer> data;
DataPair(List<ByteBuffer> data, Throwable throwable){
this.data = data;
this.throwable = throwable;
}
@Override
public String toString() {
return "DataPair [data=" + data + ", throwable=" + throwable + "]";
}
}
//这些方法都位于Http1Exchange内
void appendToOutgoing(List<ByteBuffer> item) {
//将输出的byteBuffer包装成一个DataPair数据对
appendToOutgoing(new DataPair(item, null));
}
private void appendToOutgoing(DataPair dp) {
if (debug.on()) debug.log("appending to outgoing " + dp);
//往名为outgoing的成员变量队列里面添加数据对
outgoing.add(dp);
//通知进行“发布”操作,我们继续跟踪,它位于下面的发布者内部类里
writePublisher.writeScheduler.runOrSchedule();
}
final class Http1Publisher implements FlowTube.TubePublisher {
final Logger debug = Utils.getDebugLogger(this::dbgString);
volatile Flow.Subscriber<? super List<ByteBuffer>> subscriber;
volatile boolean cancelled;
//请求的发布者持有的订阅(关系)信息。响应式流中,订阅(关系)都由发布者生成,并交给订阅者
//改类就位于该Http1Publisher内,为了不至于影响阅读,我们稍后分析
final Http1WriteSubscription subscription = new Http1WriteSubscription();
final Demand demand = new Demand();
//这里使用了上节简析过的顺序调度器包装了写任务。我们中的关注写任务
final SequentialScheduler writeScheduler =
SequentialScheduler.lockingScheduler(new WriteTask());
//我们要关注的重点写任务,写请求头和请求体都会调用它
final class WriteTask implements Runnable {
@Override
public void run() {
assert state != State.COMPLETED : "Unexpected state:" + state;
if (debug.on()) debug.log("WriteTask");
if (cancelled) {
if (debug.on()) debug.log("handling cancellation");
//如果因错误等原因取消了,那么调用调度器的停止方法,之后该任务便永远不会执行
//同时异步地将请求头发送和请求体发送过程标志为完成
writeScheduler.stop();
getOutgoing();
return;
}
if (checkRequestCancelled()) return;
if (subscriber == null) {
//如果还没有订阅者,那就先不理会
if (debug.on()) debug.log("no subscriber yet");
return;
}
if (debug.on()) debug.log(() -> "hasOutgoing = " + hasOutgoing());
//这是从缓冲队列读取请求数据的条件,即队列不为空,而且接到了订阅者的请求
while (hasOutgoing() && demand.tryDecrement()) {
//获取下一个需要输出的数据对。注意:请求头只是一份数据。
//getOutgoing()中会对当前交换状态进行切换,在读取完仅占有一份DataPair数据的请求头后,
//便会将当前交换对象的状态设置成"BODY",即发送请求体;还会设置“发送请求头”的占位符
//headersCentCF 为完成状态
DataPair dp = getOutgoing();
if (dp == null)
break;
if (dp.throwable != null) {
//出错了,便永远停止该写任务
if (debug.on()) debug.log("onError");
// Do not call the subscriber's onError, it is not required.
writeScheduler.stop();
} else {
List<ByteBuffer> data = dp.data;
if (data == Http1BodySubscriber.COMPLETED) {
//如果取出的要写入的数据是标志请求体结束的空byteBuffer,那么就标记已完成写请求任务
synchronized (lock) {
assert state == State.COMPLETING : "Unexpected state:" + state;
state = State.COMPLETED;
}
if (debug.on())
debug.log("completed, stopping %s", writeScheduler);
writeScheduler.stop();
// Do nothing more. Just do not publish anything further.
// The next Subscriber will eventually take over.
} else {
if (checkRequestCancelled()) return;
if (debug.on())
debug.log("onNext with " + Utils.remaining(data) + " bytes");
//在写入请求头、请求体过程中,不断调用订阅者(Plain Http1 中是 SocketTube)的onNext方法,
//使其向socket通道写入
subscriber.onNext(data);
}
}
}
}
}
}
}
我们看到,请求(头)发布者的操作还是相对明了的:
- 从请求中构建并取出请求头,包装成一份数据对,放入Http1Exchange中维持的一个双向缓冲队列
- 进行请求写入的“通知”,在符合条件时,从队列中取出数据,并通知订阅者消费
那么,“符合条件时”是怎样的条件呢?
while (hasOutgoing() && demand.tryDecrement())
我们看到,这一“条件”一方面是缓冲队列不为空,另一方面是“需求”(demand)不为空。那么,这个需求是什么鬼,又是怎样、何时被初始化和操作的呢?其实,这个需求只是封装了一个AtomicLong类型的变量,它充当了响应式流(反应式流)中订阅者向发布者的请求的(但还未被送达的)物品数量。我们看下Demand的结构,然后重点看下在请求头(体)发送的过程中,SocketTube里的InternalWriteSubscriber的行为。
/**
* Encapsulates operations with demand (Reactive Streams).
*
* <p> Demand is the aggregated number of elements requested by a Subscriber
* which is yet to be delivered (fulfilled) by the Publisher.
*/
public final class Demand {
private final AtomicLong val = new AtomicLong();
public boolean increase(long n) {
//增加n个需求
}
/**
* Increases this demand by 1 but only if it is fulfilled.
* @return true if the demand was increased, false otherwise.
*/
public boolean increaseIfFulfilled() {
//当前需求为空时,增加1个需求,用于启动
return val.compareAndSet(0, 1);
}
public long decreaseAndGet(long n) {
//尽量将需求减少n个,如果不足,则减为零
}
//将需求数量减少1个
public boolean tryDecrement() {
return decreaseAndGet(1) == 1;
}
public boolean isFulfilled() {
return val.get() == 0;
}
public void reset() {
val.set(0);
}
public long get() {
return val.get();
}
}
下面是SocketTube的InternalWriteScheduler,我们首先分析下onSubScribe方法。该方法订阅Http1Publisher后,接收一个订阅(关系),薄包装该订阅后,开始向订阅关系请求接受List数据,以便向socket通道写入。
//翻译下:此类假设发布者将按顺序调用 onNext,并且如果 request(1) 未增加需求,则不会调用 onNext。
//它有一个“长度为1的队列”,意味着它会在 onSubscribe 中调用 request(1),
//并且只有在它的 'current' 缓冲区列表被完全写入后, current 才会被设置为 null ;
// This class makes the assumption that the publisher will call onNext
// sequentially, and that onNext won't be called if the demand has not been
// incremented by request(1).
// It has a 'queue of 1' meaning that it will call request(1) in
// onSubscribe, and then only after its 'current' buffer list has been
// fully written and current set to null;
private final class InternalWriteSubscriber
implements Flow.Subscriber<List<ByteBuffer>> {
//对接受到的订阅的薄包装
volatile WriteSubscription subscription;
volatile List<ByteBuffer> current;
volatile boolean completed;
//初次发起消费数据请求的事件,由选择器管理线程分发处理。我们要关注的是this::startSubscription
final AsyncTriggerEvent startSubscription =
new AsyncTriggerEvent(this::signalError, this::startSubscription);
final WriteEvent writeEvent = new WriteEvent(channel, this);
final Demand writeDemand = new Demand();
@Override
public void onSubscribe(Flow.Subscription subscription) {
//我们再次关注接受订阅的方法,若之前有订阅,则抛弃它
WriteSubscription previous = this.subscription;
if (debug.on()) debug.log("subscribed for writing");
try {
boolean needEvent = current == null;
if (needEvent) {
if (previous != null && previous.upstreamSubscription != subscription) {
previous.dropSubscription();
}
}
//薄包装了接受到的订阅。这一步主要是为了控制
this.subscription = new WriteSubscription(subscription);
if (needEvent) {
if (debug.on())
debug.log("write: registering startSubscription event");
//向SelectorManager的待注册队列放置一个开始消费请求头(体)的事件,等待被
//选择器管理线程分发执行
client.registerEvent(startSubscription);
}
} catch (Throwable t) {
signalError(t);
}
}
@Override
public void onNext(List<ByteBuffer> bufs) {
//我们稍后再分析onNext方法,该方法负责写数据到socket通道
}
//……
//startSubscription成员变量构造函数第二个参数对应的方法句柄
void startSubscription() {
try {
if (debug.on()) debug.log("write: starting subscription");
if (Log.channel()) {
Log.logChannel("Start requesting bytes for writing to channel: {0}",
channelDescr());
}
assert client.isSelectorThread();
//确保之前读取socket响应功能的发布者已经注册(以便发送后能确保接收响应)
// make sure read registrations are handled before;
readPublisher.subscriptionImpl.handlePending();
if (debug.on()) debug.log("write: offloading requestMore");
// start writing; 请求发布者给它消息内容(订阅品)
client.theExecutor().execute(this::requestMore);
} catch(Throwable t) {
signalError(t);
}
}
void requestMore() {
WriteSubscription subscription = this.subscription;
//最后还是调用了订阅的请求更多方法
subscription.requestMore();
}
//薄包装接收到的Http1Publisher的订阅(关系)
final class WriteSubscription implements Flow.Subscription {
//上游订阅,即Http1Publisher的subscribe方法中调用s.onSubscribe(subscription)时的订阅
final Flow.Subscription upstreamSubscription;
volatile boolean cancelled;
WriteSubscription(Flow.Subscription subscription) {
this.upstreamSubscription = subscription;
}
@Override
public void request(long n) {
if (cancelled) return;
upstreamSubscription.request(n);
}
@Override
public void cancel() {
if (cancelled) return;
if (debug.on()) debug.log("write: cancel");
if (Log.channel()) {
Log.logChannel("Cancelling write subscription");
}
dropSubscription();
upstreamSubscription.cancel();
}
void dropSubscription() {
synchronized (InternalWriteSubscriber.this) {
cancelled = true;
if (debug.on()) debug.log("write: resetting demand to 0");
writeDemand.reset();
}
}
//终于到重点了
void requestMore() {
try {
if (completed || cancelled) return;
boolean requestMore;
long d;
// don't fiddle with demand after cancel.
// see dropSubscription.
synchronized (InternalWriteSubscriber.this) {
if (cancelled) return;
//下面这一步就是初始化请求,即请求初始为0,便请求更多
d = writeDemand.get();
requestMore = writeDemand.increaseIfFulfilled();
}
if (requestMore) {
//向上游订阅请求要获取一个订阅品
if (debug.on()) debug.log("write: requesting more...");
//这个方法向上游要求多一个物品(请求数据分片),对应上游的订阅要增加一个“需求”Demand
upstreamSubscription.request(1);
} else {
if (debug.on())
debug.log("write: no need to request more: %d", d);
}
} catch (Throwable t) {
if (debug.on())
debug.log("write: error while requesting more: " + t);
signalError(t);
} finally {
debugState("leaving requestMore: ");
}
}
}
}
上面的代码封装稍深,但在理解了响应式流的工作过程的情况下,仔细阅读还是不难理解其逻辑:就是收到订阅后做一层包装,然后注册一个“要求接收订阅品”的事件,等待选择器管理线程分发执行该事件,向上游订阅增加一个“需求”;上游的Http1Publisher便会开始将缓冲队列中的请求分片数据通过subscriber.onNext方法交给订阅者(当前这个InternalWriteSubscriber)。我们回看Http1Publisher的内部类里的内部类Http1WriteSubscription,即前面提到的“上游订阅'' 在接到request(1)时会如何操作:
final class Http1WriteSubscription implements Flow.Subscription {
@Override
public void request(long n) {
if (cancelled)
return; //no-op
//这里对Http1Publisher里面的成员变量demand增加1,即增加了需求
demand.increase(n);
if (debug.on())
debug.log("subscription request(%d), demand=%s", n, demand);
//启动上面提过的”从缓冲队列取出数据交给订阅者“的写任务
writeScheduler.runOrSchedule(client.theExecutor());
}
@Override
public void cancel() {
if (debug.on()) debug.log("subscription cancelled");
if (cancelled)
return; //no-op
cancelled = true;
writeScheduler.runOrSchedule(client.theExecutor());
}
}
至此,Http1请求头(也包括请求体)的发送启动流程已经被介绍完毕了。接下来,我们还是要关注订阅者(SocketTube内的InternalWriteSubscriber)的onNext方法,看看它是如何写入数据到socket通道的。
5.3 写入数据到NIO-Socket通道
我们接着关注InternalWriteSubscriber的onNext方法,里面涉及向发布者请求数据并向socket通道写入的操作:
final class SocketTube implements FlowTube {
//省略………………
//请求头和请求体的订阅者
private final class InternalWriteSubscriber
implements Flow.Subscriber<List<ByteBuffer>> {
volatile WriteSubscription subscription;
//当前持有的请求数据(请求头/请求体)
volatile List<ByteBuffer> current;
volatile boolean completed;
final AsyncTriggerEvent startSubscription =
new AsyncTriggerEvent(this::signalError, this::startSubscription);
final WriteEvent writeEvent = new WriteEvent(channel, this);
final Demand writeDemand = new Demand();
@Override
public void onSubscribe(Flow.Subscription subscription) {
//该方法上节分析过了
}
//这是我们要分析的方法
@Override
public void onNext(List<ByteBuffer> bufs) {
assert current == null : dbgString() // this is a queue of 1.
+ "w.onNext current: " + current;
assert subscription != null : dbgString()
+ "w.onNext: subscription is null";
current = bufs;
//将当前的请求数据冲刷到NIO socket通道
tryFlushCurrent(client.isSelectorThread()); // may be in selector thread
// For instance in HTTP/2, a received SETTINGS frame might trigger
// the sending of a SETTINGS frame in turn which might cause
// onNext to be called from within the same selector thread that the
// original SETTINGS frames arrived on. If rs is the read-subscriber
// and ws is the write-subscriber then the following can occur:
// ReadEvent -> rs.onNext(bytes) -> process server SETTINGS -> write
// client SETTINGS -> ws.onNext(bytes) -> tryFlushCurrent
debugState("leaving w.onNext");
}
//冲刷数据到socket通道的方法
// If this method is invoked in the selector manager thread (because of
// a writeEvent), then the executor will be used to invoke request(1),
// ensuring that onNext() won't be invoked from within the selector
// thread. If not in the selector manager thread, then request(1) is
// invoked directly.
void tryFlushCurrent(boolean inSelectorThread) {
List<ByteBuffer> bufs = current;
if (bufs == null) return;
try {
assert inSelectorThread == client.isSelectorThread() :
"should " + (inSelectorThread ? "" : "not ")
+ " be in the selector thread";
//获取待写入的数据长度
long remaining = Utils.remaining(bufs);
if (debug.on()) debug.log("trying to write: %d", remaining);
//尽可能一次往socket通道写入所有待写入数据,然而由于nio通道可能已慢,
//在非阻塞模式下会“尽最大努力”写入,之后直接返回已写的字节数
long written = writeAvailable(bufs);
if (debug.on()) debug.log("wrote: %d", written);
assert written >= 0 : "negative number of bytes written:" + written;
assert written <= remaining;
if (remaining - written == 0) {
//在本批请求数据已全部写入的情况下,向发布者请求更多数据
current = null;
if (writeDemand.tryDecrement()) {
Runnable requestMore = this::requestMore;
if (inSelectorThread) {
assert client.isSelectorThread();
client.theExecutor().execute(requestMore);
} else {
assert !client.isSelectorThread();
requestMore.run();
}
}
} else {
//由于没有全部写完,说明nio通道已满,那么这时要注册一个写事件,
//等待写就绪后由SelectorManager线程分发并处理事件,继续写入
resumeWriteEvent(inSelectorThread);
}
} catch (Throwable t) {
signalError(t);
}
}
//"最大努力"写入方法
private long writeAvailable(List<ByteBuffer> bytes) throws IOException {
ByteBuffer[] srcs = bytes.toArray(Utils.EMPTY_BB_ARRAY);
final long remaining = Utils.remaining(srcs);
long written = 0;
while (remaining > written) {
try {
//最终调用的是java.nio.channels.SocketChannel的write(ByteBuffer[]) 方法,
//写入请求数据到socket通道
long w = channel.write(srcs);
assert w >= 0 : "negative number of bytes written:" + w;
if (w == 0) {
break;
}
written += w;
} catch (IOException x) {
if (written == 0) {
// no bytes were written just throw
throw x;
} else {
// return how many bytes were written, will fail next time
break;
}
}
}
return written;
}
//调用外部类(SocketChannel)的“继续写事件”方法,注册事件
void resumeWriteEvent(boolean inSelectorThread) {
if (debug.on()) debug.log("scheduling write event");
resumeEvent(writeEvent, this::signalError);
}
}
//方法所做的是视情况注册或更新事件
private void resumeEvent(SocketFlowEvent event,
Consumer<Throwable> errorSignaler) {
boolean registrationRequired;
synchronized(lock) {
registrationRequired = !event.registered();
event.resume();
}
try {
if (registrationRequired) {
client.registerEvent(event);
} else {
client.eventUpdated(event);
}
} catch(Throwable t) {
errorSignaler.accept(t);
}
}
}
至此,我们已经看到了整个请求头信息写入的闭环。
5.4 请求体的发送
请求体的发送和请求头类似,写入socket通道的主要步骤都在上面呈现了。不过,请求体的从调用者发送到Http1Publisher,又是另一个“发布——订阅”的过程。我们将追踪整个请求体写入的过程。
我们先回顾下携带请求体时发送请求时的调用代码:
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("http://openjdk.java.net/")) //设置目的url
.timeout(Duration.ofMinutes(1)) //超时时间
.header("Content-Type", "application/json") //设置请求体为json格式
//.POST(BodyPublishers.ofFile(Paths.get("file.json"))) //设置从json文件里面读取内容
.POST(HttpRequest.BodyPublishers.ofString( //发送json字符串
JSONUtil.toJsonStr(Map.of("country", "China"))))
.build()
可以看到,我们可以指定POST方法时的请求体,指定方式是传入一个HttpRequest::BodyPublisher对象,具体操作是用字符串或者文件(还可以是输入流或者另外的发布者)通过辅助工具类BodyPublishers去实例化它的不同实现类。HttpRequest中的BodyPublisher接口定义如下。
public interface BodyPublisher extends Flow.Publisher<ByteBuffer> {
/**
* Returns the content length for this request body. May be zero
* if no request body being sent, greater than zero for a fixed
* length content, or less than zero for an unknown content length.
*
* <p> This method may be invoked before the publisher is subscribed to.
* This method may be invoked more than once by the HTTP client
* implementation, and MUST return the same constant value each time.
*
* @return the content length for this request body, if known
*/
long contentLength();
}
可以看到,BodyPublisher接口继承了Flow.Publisher接口,充当响应式流模型中的发布者的角色。它的实现类分布在RequestPublisher类中,如下图所示。后续将看到,该接口通过区分contentLength返回值是正数、负数还是0,来决定后续它的订阅者是固定长度的还是流式订阅者。
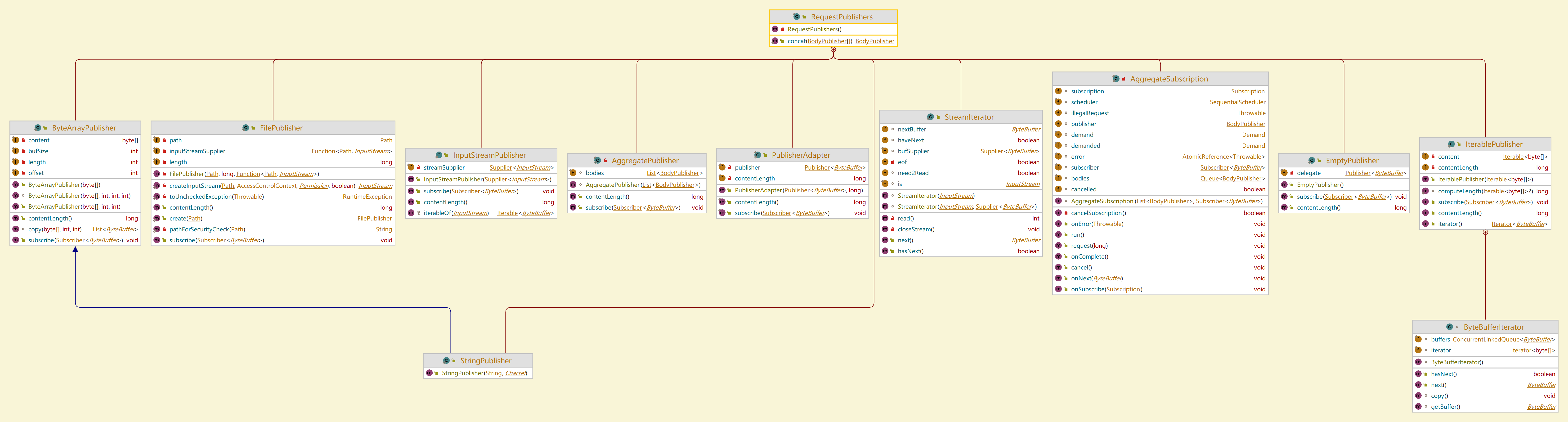
我们略微分析一下ByteArrayPublisher,它是作为调用者的我们最常用的BodyPublishers.ofString()返回的StringPublisher的父类。可以看到,字节发布者ByteArrayPublisher里面使用了byte数组存储了调用者的数据,在接受订阅时,生成一个真正的发布者PullPublisher,接受订阅者的发布。
//该类也是BodyPublishers.ofString()返回的StringPublisher的父类
public static class ByteArrayPublisher implements BodyPublisher {
private final int length;
//从调用者接受到的字节数组
private final byte[] content;
private final int offset;
private final int bufSize;
public ByteArrayPublisher(byte[] content) {
this(content, 0, content.length);
}
public ByteArrayPublisher(byte[] content, int offset, int length) {
this(content, offset, length, Utils.BUFSIZE);
}
/* bufSize exposed for testing purposes */
ByteArrayPublisher(byte[] content, int offset, int length, int bufSize) {
this.content = content;
this.offset = offset;
this.length = length;
this.bufSize = bufSize;
}
//被订阅时的操作,将字节数组转化为ByteBuffer
List<ByteBuffer> copy(byte[] content, int offset, int length) {
List<ByteBuffer> bufs = new ArrayList<>();
while (length > 0) {
ByteBuffer b = ByteBuffer.allocate(Math.min(bufSize, length));
int max = b.capacity();
int tocopy = Math.min(max, length);
b.put(content, offset, tocopy);
offset += tocopy;
length -= tocopy;
b.flip();
bufs.add(b);
}
return bufs;
}
//接受订阅方法,该方法会在请求体发布后被调用,完成订阅
@Override
public void subscribe(Flow.Subscriber<? super ByteBuffer> subscriber) {
List<ByteBuffer> copy = copy(content, offset, length);
//对于字节型的Http请求体来说,这个才是真正的发布者
var delegate = new PullPublisher<>(copy);
delegate.subscribe(subscriber);
}
@Override
//这里返回定长的请求体长度,意味着之后会创建固定长度的订阅者
public long contentLength() {
return length;
}
}
在PullPublisher的subscribe方法中,会调用订阅者的onSubscribe方法。
我们将目光转向订阅者。在请求头发送完成,并校验407错误通过后,Http1Exchange会立刻进行请求体的发送,而订阅的过程就发生在Exchange和ExchangeImpl的发送请求体相关方法中。调用的链路流程是:
Exchange::responseAsyncImpl0 -> Exchange::sendRequestBody -> Http1Exchange::sendBodyAsync
我们查看Http1Exchange和Http1Request中的相关方法:
/**
* Encapsulates one HTTP/1.1 request/response exchange.
*/
class Http1Exchange<T> extends ExchangeImpl<T> {
//省略…………
@Override
CompletableFuture<ExchangeImpl<T>> sendBodyAsync() {
assert headersSentCF.isDone();
if (debug.on()) debug.log("sendBodyAsync");
try {
//如果有请求体,则里面实例化了Http请求体的订阅者,完成了订阅操作
bodySubscriber = requestAction.continueRequest();
if (debug.on()) debug.log("bodySubscriber is %s",
bodySubscriber == null ? null : bodySubscriber.getClass());
if (bodySubscriber == null) {
bodySubscriber = Http1BodySubscriber.completeSubscriber(debug);
//没有请求体发送,直接发送“完成”的标志位到前面提到过的缓冲队列中,
//即是把“完成”这个标志给了Http1Publisher这个前面提到过的
//连接socketTube的下一个发布者
appendToOutgoing(Http1BodySubscriber.COMPLETED);
} else {
// start
bodySubscriber.whenSubscribed
.thenAccept((s) -> cancelIfFailed(s))
//异步订阅成功后,向发布者请求Http请求体
.thenAccept((s) -> requestMoreBody());
}
} catch (Throwable t) {
cancelImpl(t);
bodySentCF.completeExceptionally(t);
}
return Utils.wrapForDebug(debug, "sendBodyAsync", bodySentCF);
}
//省略…………
}
//表示Http1具体请求动作的外部类,和Http1Exchange相互引用
class Http1Request {
//省略…………
Http1BodySubscriber continueRequest() {
Http1BodySubscriber subscriber;
if (streaming) {
//如果是流式的请求体,就使用这个流式订阅者,否则采用定长的订阅者
subscriber = new StreamSubscriber();
requestPublisher.subscribe(subscriber);
} else {
if (contentLength == 0)
return null;
subscriber = new FixedContentSubscriber();
//完成上面对BodyPublisher的订阅
requestPublisher.subscribe(subscriber);
}
return subscriber;
}
//省略…………
}
再看下作为订阅者之一的FixedContentSubscriber,其位于Http1Request中,我们重点关注下其onNext(ByteBuffer item)方法:
//该方法订阅成功后就会立即被调用
@Override
public void onNext(ByteBuffer item) {
if (debug.on()) debug.log("onNext");
Objects.requireNonNull(item);
if (complete) {
Throwable t = new IllegalStateException("subscription already completed");
http1Exchange.appendToOutgoing(t);
} else {
long writing = item.remaining();
long written = (contentWritten += writing);
if (written > contentLength) {
cancelSubscription();
String msg = connection.getConnectionFlow()
+ " [" + Thread.currentThread().getName() +"] "
+ "Too many bytes in request body. Expected: "
+ contentLength + ", got: " + written;
http1Exchange.appendToOutgoing(new IOException(msg));
} else {
//将请求体放到上文提到过的缓冲队列中,交给了下一个响应式流,
//等待被下一个流冲刷到socket通道中
http1Exchange.appendToOutgoing(List.of(item));
}
}
}
到这里,发送请求体的响应式过程便也一目了然了。
5.5 发送小结
请求头和请求体的发送过程类似,但也略有差别。以无加密的Http1.1连接为例,它们的前置条件都是请求内容的发布者和SocketTube间建立了双向订阅关系。
请求头的发送过程如下:
- 从用户请求中过滤并构建请求头
- 将请求头放入缓冲队列
- 建立双向订阅关系后,SocketTube中写订阅者向Http1Publisher发布者请求请求头数据
- Http1Publisher发布者将请求头从缓冲队列中取出,交给SocketTube中的写订阅者
- 写订阅者向socket通道写入请求头数据
请求体的发送过程如下:
- 根据调用方传入的请求体实例化不同的请求体发布者
- 在请求头发布完成后,根据请求体情况实例化定长或流式请求体订阅者
- 请求头发布者接受请求体订阅者的订阅,请求体订阅者请求请求头信息
- 请求体订阅者将请求体数据放入缓冲队列,通知Http1Publisher启动发布——订阅任务
- Http1Publisher发布者将请求体从缓冲队列中取出,交给SocketTube中的写订阅者
- 写订阅者向socket通道写入请求体数据
两者的不同,主要还是在于请求体的写入过程涉及了两个“发布——订阅”过程,而请求头只涉及一个。
6. 响应的创建和响应头的解析
由于一个用户请求由于重定向等原因可能生成多个请求——响应交换,HttpClient总是在每个响应收到时,只解析请求头,只有确定这个请求是最终请求时,才会解析响应体。
毫无疑问的是,响应头(和响应体)的解析过程又是一轮响应式流的“发布——订阅”过程。发布者是SocketTube中的InternalReadPublisher,订阅者则是Http1AsyncReceiver中的Http1TubeSubscriber。不过,接收到响应内容的Http1TubeScriber,会将响应内容放入一个队列,等待后续的消费者去解析、处理,这时候便是Reader、Parser等一系列组件的舞台了。
相对请求来说,响应的接收和解析更加复杂凌乱。我们首先介绍下涉及响应解析的几个类的功能,再追踪响应头解析的过程。
6.1 发布和订阅者介绍
下图是Http1Response和Http1AsyncReceiver的类图,以及涉及响应头和响应体解析的几个组件的功能介绍:
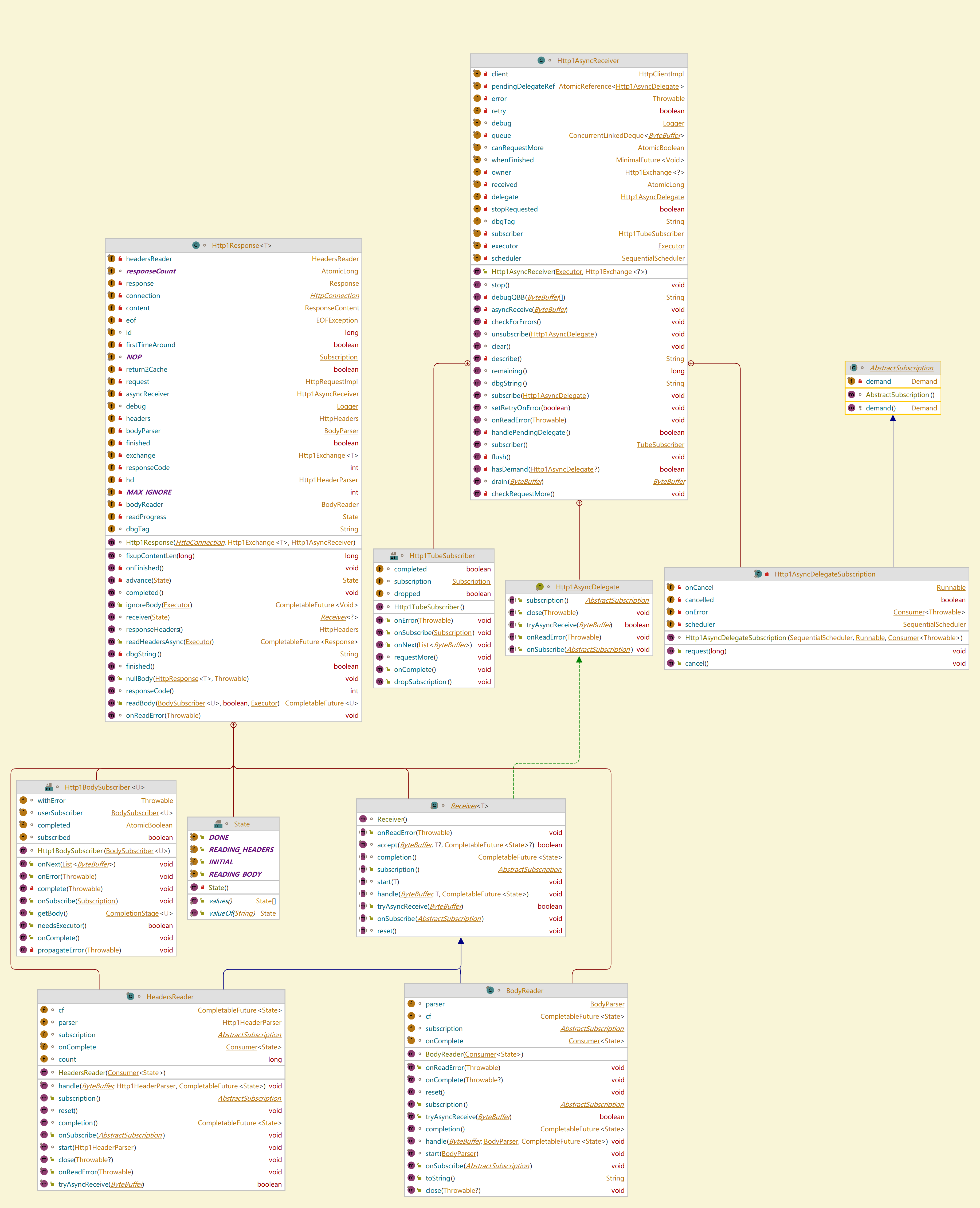
| 类名 | 父类(接口) | 外部类 | 角色 | 功能 |
|---|---|---|---|---|
| Http1TubeSunscriber | TubeSubscriber(Flow.Sunscriber) | Http1AsyncReceiver | 响应数据的直接接收者 | 接收SocketTube收到并发布的响应数据 |
| Http1AsyncDelegate | - | Http1AsyncReceiver | 抽象接收接口 | 接收或处理上游Http响应数据 |
| HttpAsyncDelegateSubscription | Abstraction(Flow.Subscription) | Http1AsyncReceiver | 代理订阅关系 | - |
| HttpAsyncReceiver | - | - | 响应数据接收辅助类 | 辅助接收响应数据,同时 |
| Http1Response | - | - | Http1响应对象 | 处理一个Http1.1响应对象 |
| HeadersReader | Http1AsyncDelegate | Http1Response | 响应头读取者 | 参与ByteBuffer格式的响应头的读取 |
| BodyReader | Http1AsyncDelegate | Http1Response | 响应体读取者 | 参与ByteBuffer格式的响应体的读取 |
| Http1HeaderParser | - | - | Http1响应头解析器 | 解析Http1响应头文本信息 |
| BodyParser | Consumer接口 | ResponseContent | 响应体解析接口 | 解析Http1响应体 |
| BodyHandler | - | HttpResponse | 响应体结果组装者 | 组装解析后的Http1响应体 |
6.2 响应头解析
我们首先关注响应头的解析过程。简而言之:响应头的解析链路如下:
在请求数据发送前,HeadersReader订阅HttpAsyncReceiver,做好接收数据的准备,并告知需求量
SocketTube中的InternalReadPublisher从socket通道中读取响应数据
SocketTube中的InternalReadPublisher将响应数据以发布——订阅(响应式流)的方式交给Http1TubeSubscriber
Http1TubeSubscriber接到数据后,将响应头数据交给HeadersReader处理
HeadersReader调用Http1HeaderParser完成响应头的解析
切换为读取响应体的状态,并组装响应对象Response返回
我们将逐一跟进。响应头的解析可以追溯到Http1Exchange中,Http1Response的实例化过程。
在这里先提一下,在HttpClient中,Response类和Http1Response类并不是继承的关系:
- Response类表示响应头和状态码
- Http1Response类表示一次Http1.1响应,包含响应头和响应体,其中组合了一个Response的成员变量
我们首先看下Http1Response响应的实例化过程,前面已经简要提到过,该过程位于Http1Exchange的sendHeadersAsync发送请求头方法中。
@Override
CompletableFuture<ExchangeImpl<T>> sendHeadersAsync() {
// create the response before sending the request headers, so that
// the response can set the appropriate receivers.
if (debug.on()) debug.log("Sending headers only");
// If the first attempt to read something triggers EOF, or
// IOException("channel reset by peer"), we're going to retry.
// Instruct the asyncReceiver to throw ConnectionExpiredException
// to force a retry.
asyncReceiver.setRetryOnError(true);
//这里提前创建了一个Http1Response
if (response == null) {
response = new Http1Response<>(connection, this, asyncReceiver);
}
if (debug.on()) debug.log("response created in advance");
//省略…………
}
我们于是分析Http1Response的构造过程。该过程至关重要:响应头读取者对Http1响应体异步接收者的订阅、对响应头的读取和解析过程的准备,就潜藏在Http1Response的构造函数中。
class Http1Response<T> {
private volatile ResponseContent content;
private final HttpRequestImpl request;
private Response response;
private final HttpConnection connection;
private HttpHeaders headers;
private int responseCode;
//这里维持了一个对Http1Exchange的引用,在HttpClient中,相互关联关系比较常见
private final Http1Exchange<T> exchange;
private boolean return2Cache; // return connection to cache when finished
//响应头读取者
private final HeadersReader headersReader; // used to read the headers
//响应体读取者
private final BodyReader bodyReader; // used to read the body
//Http响应内容的直接接收者(从socket管道)
private final Http1AsyncReceiver asyncReceiver;
private volatile EOFException eof;
//响应体解析者
private volatile BodyParser bodyParser;
// max number of bytes of (fixed length) body to ignore on redirect
private final static int MAX_IGNORE = 1024;
// Revisit: can we get rid of this?
static enum State {INITIAL, READING_HEADERS, READING_BODY, DONE}
private volatile State readProgress = State.INITIAL;
final Logger debug = Utils.getDebugLogger(this::dbgString, Utils.DEBUG);
final static AtomicLong responseCount = new AtomicLong();
final long id = responseCount.incrementAndGet();
//响应头解析者
private Http1HeaderParser hd;
Http1Response(HttpConnection conn,
Http1Exchange<T> exchange,
Http1AsyncReceiver asyncReceiver) {
this.readProgress = State.INITIAL;
this.request = exchange.request();
this.exchange = exchange;
this.connection = conn;
this.asyncReceiver = asyncReceiver;
//实例化了响应头和响应体的读取者
//advance回调方法用于读取完响应头或响应体时升级读取状态
headersReader = new HeadersReader(this::advance);
bodyReader = new BodyReader(this::advance);
hd = new Http1HeaderParser();
readProgress = State.READING_HEADERS;
//让响应头读取者维持解析者的引用
headersReader.start(hd);
//让响应头读取者订阅Http1响应内容异步接收者
asyncReceiver.subscribe(headersReader);
}
}
由于订阅的过程和之前的类似,此处便不再跟随进入。我们只需要知道headersReader此时已经准备好读取响应头数据了。
接下来便是SocketTube中的InternalReadPublisher从socket通道中读取响应数据的过程。注意,这里是一个编程上异步,I/O上同步非阻塞的过程:在发送请求体后,当socket通道对应的选择键可读时,选择器管理线程便会分发并执行读事件,最终调用了SocketTube中的InternalReadPublisher中的InternalReadSubscription中的read()方法。
那么,读事件是在什么时候注册的呢?其实,读时间的注册就发生在前文提到的connectFlows()方法中。当双向读写关系建立,Http1AsyncReceiver中的Http1TubeSubscriber订阅SocketTube中的InternalReadPublisher时,Http1TubeSubscriber的onSubscribe方法最终经过多重曲折, 调用了subscription.request(1)方法。对应的订阅InternalReadSubscription中,就注册了一个读事件到SelectorManager的待办事件列表,即注册到socket通道上。
我们简要关注下SocketTube的内部类InternalReadPublisher的内部类InternalReadSubscription的request方法及read方法:
final class InternalReadSubscription implements Flow.Subscription {
private final Demand demand = new Demand();
final SequentialScheduler readScheduler;
private volatile boolean completed;
private final ReadEvent readEvent;
private final AsyncEvent subscribeEvent;
@Override
public final void request(long n) {
if (n > 0L) {
boolean wasFulfilled = demand.increase(n);
if (wasFulfilled) {
if (debug.on()) debug.log("got some demand for reading");
//该方法注册了一个读事件到通道上
resumeReadEvent();
// if demand has been changed from fulfilled
// to unfulfilled register read event;
}
} else {
signalError(new IllegalArgumentException("non-positive request"));
}
debugState("leaving request("+n+"): ");
}
/** The body of the task that runs in SequentialScheduler. */
final void read() {
// It is important to only call pauseReadEvent() when stopping
// the scheduler. The event is automatically paused before
// firing, and trying to pause it again could cause a race
// condition between this loop, which calls tryDecrementDemand(),
// and the thread that calls request(n), which will try to resume
// reading.
try {
while(!readScheduler.isStopped()) {
if (completed) return;
// make sure we have a subscriber
if (handlePending()) {
if (debug.on())
debug.log("pending subscriber subscribed");
return;
}
// If an error was signaled, we might not be in the
// the selector thread, and that is OK, because we
// will just call onError and return.
ReadSubscription current = subscription;
Throwable error = errorRef.get();
if (current == null) {
assert error != null;
if (debug.on())
debug.log("error raised before subscriber subscribed: %s",
(Object)error);
return;
}
TubeSubscriber subscriber = current.subscriber;
if (error != null) {
completed = true;
// safe to pause here because we're finished anyway.
pauseReadEvent();
if (debug.on())
debug.log("Sending error " + error
+ " to subscriber " + subscriber);
if (Log.channel()) {
Log.logChannel("Raising error with subscriber for {0}: {1}",
channelDescr(), error);
}
current.errorRef.compareAndSet(null, error);
current.signalCompletion();
if (debug.on()) debug.log("Stopping read scheduler");
readScheduler.stop();
debugState("leaving read() loop with error: ");
return;
}
// If we reach here then we must be in the selector thread.
assert client.isSelectorThread();
if (demand.tryDecrement()) {
// we have demand.
try {
//这一步里面是从socket通道中读取可读的响应数据
List<ByteBuffer> bytes = readAvailable(current.bufferSource);
if (bytes == EOF) {
//收到eof,说明该通道读完成,在readAvailable方法中对应read()的结果为-1
if (!completed) {
if (debug.on()) debug.log("got read EOF");
if (Log.channel()) {
Log.logChannel("EOF read from channel: {0}",
channelDescr());
}
completed = true;
// safe to pause here because we're finished
// anyway.
//停止读事件,并标记读完成
pauseReadEvent();
current.signalCompletion();
if (debug.on()) debug.log("Stopping read scheduler");
readScheduler.stop();
}
debugState("leaving read() loop after EOF: ");
return;
} else if (Utils.remaining(bytes) > 0) {
// the subscriber is responsible for offloading
// to another thread if needed.
if (debug.on())
debug.log("read bytes: " + Utils.remaining(bytes));
assert !current.completed;
//将接收到的数据交给Http1TubeSubscriber
subscriber.onNext(bytes);
// we could continue looping until the demand
// reaches 0. However, that would risk starving
// other connections (bound to other socket
// channels) - as other selected keys activated
// by the selector manager thread might be
// waiting for this event to terminate.
// So resume the read event and return now...
//这里按照注释,并没有直接让循环读完,而是注册一个读事件等待再次分发,
//为的是其它通道的“公平”起见
resumeReadEvent();
if (errorRef.get() != null) continue;
debugState("leaving read() loop after onNext: ");
return;
} else {
// nothing available!
if (debug.on()) debug.log("no more bytes available");
// re-increment the demand and resume the read
// event. This ensures that this loop is
// executed again when the socket becomes
// readable again.
//没有读到怎么办?说明该通道不可读,注册新的读事件
demand.increase(1);
resumeReadEvent();
if (errorRef.get() != null) continue;
debugState("leaving read() loop with no bytes");
return;
}
} catch (Throwable x) {
signalError(x);
continue;
}
} else {
if (debug.on()) debug.log("no more demand for reading");
// the event is paused just after firing, so it should
// still be paused here, unless the demand was just
// incremented from 0 to n, in which case, the
// event will be resumed, causing this loop to be
// invoked again when the socket becomes readable:
// This is what we want.
// Trying to pause the event here would actually
// introduce a race condition between this loop and
// request(n).
if (errorRef.get() != null) continue;
debugState("leaving read() loop with no demand");
break;
}
}
} catch (Throwable t) {
if (debug.on()) debug.log("Unexpected exception in read loop", t);
signalError(t);
} finally {
if (readScheduler.isStopped()) {
if (debug.on()) debug.log("Read scheduler stopped");
if (Log.channel()) {
Log.logChannel("Stopped reading from channel {0}", channelDescr());
}
}
handlePending();
}
}
}
我们看到,在read()方法中,调用了subscriber.onNext(bytes)方法。我们关注作为订阅者的Http1TubeSubscriber是如何处理接到的响应数据的。
我们一路追踪,将会发现管道订阅者Http1TubeSubscriber在收到响应数据后,将其放到了外部对象维护的一个队列queue中,然后通知外部类Http1AsyncReceiver进行读操作,并将数据交付给headersReader:
//Http1AsyncReceiver的内部类
final class Http1TubeSubscriber implements TubeSubscriber {
volatile Flow.Subscription subscription;
volatile boolean completed;
volatile boolean dropped;
@Override
public void onNext(List<ByteBuffer> item) {
canRequestMore.set(item.isEmpty());
for (ByteBuffer buffer : item) {
//调用了外部类Http1AsyncReceiver的asyncReceive方法
//我们将分析
asyncReceive(buffer);
}
}
}
/**
* A helper class that will queue up incoming data until the receiving
* side is ready to handle it.
*/
class Http1AsyncReceiver {
//暂存收到的响应数据的队列
private final ConcurrentLinkedDeque<ByteBuffer> queue
= new ConcurrentLinkedDeque<>();
//一个运行取响应数据的调度器,我们重点关注flush方法
private final SequentialScheduler scheduler =
SequentialScheduler.lockingScheduler(this::flush);
final MinimalFuture<Void> whenFinished;
private final Executor executor;
//维持的对内部的管道订阅者的实例的引用
private final Http1TubeSubscriber subscriber = new Http1TubeSubscriber();
//……省略
//该方法即为内部成员subscriber调用的外部方法,我们进行分析
// Callback: Consumer of ByteBuffer
private void asyncReceive(ByteBuffer buf) {
if (debug.on())
debug.log("Putting %s bytes into the queue", buf.remaining());
received.addAndGet(buf.remaining());
//将响应数据放入到缓冲队列中
queue.offer(buf);
//调度进行flush方法,从队列中取数据并进行后续的消费
//我们将深入分析
//注释说这里由于是SelectorManager线程直接分发的读事件,
//为了防止阻塞选择器管理线程,将该任务交给其它线程
// This callback is called from within the selector thread.
// Use an executor here to avoid doing the heavy lifting in the
// selector.
scheduler.runOrSchedule(executor);
}
//重点要分析的方法,进行数据从队列的读取和消费
private void flush() {
ByteBuffer buf;
try {
// we should not be running in the selector here,
// except if the custom Executor supplied to the client is
// something like (r) -> r.run();
assert !client.isSelectorThread()
|| !(client.theExecutor().delegate() instanceof ExecutorService) :
"Http1AsyncReceiver::flush should not run in the selector: "
+ Thread.currentThread().getName();
//该handle pending方法调用了headersReader的onsubscribe方法
// First check whether we have a pending delegate that has
// just subscribed, and if so, create a Subscription for it
// and call onSubscribe.
handlePendingDelegate();
//从队列中取响应数据
// Then start emptying the queue, if possible.
while ((buf = queue.peek()) != null && !stopRequested) {
Http1AsyncDelegate delegate = this.delegate;
if (debug.on())
debug.log("Got %s bytes for delegate %s",
buf.remaining(), delegate);
if (!hasDemand(delegate)) {
// The scheduler will be invoked again later when the demand
// becomes positive.
return;
}
assert delegate != null;
if (debug.on())
debug.log("Forwarding %s bytes to delegate %s",
buf.remaining(), delegate);
// The delegate has demand: feed it the next buffer.
//注意,这一步即是将从队列中取出的数据交给headersReader,即请求头读取者
//由于之前在Http1Response的构造函数中,headers订阅了AsyncReceiver,
//delegate即指向headersReader。我们将进入分析该方法。
//该方法返回false,即表示接收解析完成当前数据,即解析完成响应头,该次flush运行便会停止
//如此,便可保证切换响应体接收的正确性
if (!delegate.tryAsyncReceive(buf)) {
final long remaining = buf.remaining();
if (debug.on()) debug.log(() -> {
// If the scheduler is stopped, the queue may already
// be empty and the reference may already be released.
String remstr = scheduler.isStopped() ? "" :
" remaining in ref: "
+ remaining;
remstr += remstr
+ " total remaining: " + remaining();
return "Delegate done: " + remaining;
});
canRequestMore.set(false);
// The last buffer parsed may have remaining unparsed bytes.
// Don't take it out of the queue.
return; // done.
}
// removed parsed buffer from queue, and continue with next
// if available
ByteBuffer parsed = queue.remove();
canRequestMore.set(queue.isEmpty() && !stopRequested);
assert parsed == buf;
}
//队列清空后,请求更多响应数据,这一步会触发读事件的注册
//由于flush方法在onSubscribe()中也会被调用,实际上触发了读过程
// queue is empty: let's see if we should request more
checkRequestMore();
} catch (Throwable t) {
Throwable x = error;
if (x == null) error = t; // will be handled in the finally block
if (debug.on()) debug.log("Unexpected error caught in flush()", t);
} finally {
// Handles any pending error.
// The most recently subscribed delegate will get the error.
checkForErrors();
}
}
我们看到,作为Http响应内容直接接收者的Http1TubeSubscriber,在onNext(bytes)方法中,促成了headersReader对Http1AsyncReceiver的订阅的完成,然后将响应数据(先是响应头,然后是响应体)交给了headersReader。
我们追踪headersReader的行为,最终调用的是headersReader的handle方法。该方法调用了parser的parse方法来解析响应头。
@Override
final void handle(ByteBuffer b,
Http1HeaderParser parser,
CompletableFuture<State> cf) {
assert cf != null : "parsing not started";
assert parser != null : "no parser";
try {
count += b.remaining();
if (debug.on())
debug.log("Sending " + b.remaining() + "/" + b.capacity()
+ " bytes to header parser");
//调用了响应头解析器的parse方法来解析响应头
//其内部多次循环,使用状态state记录解析状态,最终完成解析时返回true
if (parser.parse(b)) {
count -= b.remaining();
if (debug.on())
debug.log("Parsing headers completed. bytes=" + count);
//解析完成响应头后,进行状态的升级,即是让Http1Response进入到读取响应体的状态
onComplete.accept(State.READING_HEADERS);
//将占位符标志为完成请求头读取
cf.complete(State.READING_HEADERS);
}
} catch (Throwable t) {
if (debug.on())
debug.log("Header parser failed to handle buffer: " + t);
cf.completeExceptionally(t);
}
}
在上面的代码中,我们看到,只是调用了一次解析器的parse方法,就完成了响应头的解析。可是响应数据不是一次到齐的呀?其实,是Http1HeaderParser内部使用了一个状态位state来支持parse方法多次被调用,在最终解析完成时返回true,否则返回false:
/**
* Parses HTTP/1.X status-line and headers from the given bytes. Must be
* called successive times, with additional data, until returns true.
*
* All given ByteBuffers will be consumed, until ( possibly ) the last one
* ( when true is returned ), which may not be fully consumed.
*
* @param input the ( partial ) header data
* @return true iff the end of the headers block has been reached
*/
boolean parse(ByteBuffer input) throws ProtocolException {
requireNonNull(input, "null input");
while (canContinueParsing(input)) {
//这里通过state状态维护了一个初值为initial的状态机,一次调用parse,会根据读取的内容,在while循环中更新状态state,
//直到读完input中可读内容,state停在某个状态。多次调用,state会继续改变,直至读取完成,方法返回true
switch (state) {
case INITIAL -> state = State.STATUS_LINE;
case STATUS_LINE -> readResumeStatusLine(input);
case STATUS_LINE_FOUND_CR, STATUS_LINE_FOUND_LF -> readStatusLineFeed(input);
case STATUS_LINE_END -> maybeStartHeaders(input);
case STATUS_LINE_END_CR, STATUS_LINE_END_LF -> maybeEndHeaders(input);
case HEADER -> readResumeHeader(input);
case HEADER_FOUND_CR, HEADER_FOUND_LF -> resumeOrLF(input);
case HEADER_FOUND_CR_LF -> resumeOrSecondCR(input);
case HEADER_FOUND_CR_LF_CR -> resumeOrEndHeaders(input);
default -> throw new InternalError("Unexpected state: " + state);
}
}
//仅在完成时返回true
return state == State.FINISHED;
}
以上,我们就完成了对响应头读取和解析的大部分过程。最后的过程是组装一个Reponse对象。这一步就发生在Exchange类中,发送请求体之后。相关方法如下:
//Exchange类的sendReqeustBody方法,发送请求体然后调用具体实现类的接收并解析响应头方法
// After sending the request headers, if no ProxyAuthorizationRequired
// was raised and the expectContinue flag is off, we can immediately
// send the request body and proceed.
private CompletableFuture<Response> sendRequestBody(ExchangeImpl<T> ex) {
assert !request.expectContinue();
if (debug.on()) debug.log("sendRequestBody");
CompletableFuture<Response> cf = ex.sendBodyAsync()
//我们跟踪进入该方法
.thenCompose(exIm -> exIm.getResponseAsync(parentExecutor));
//协议升级和日志,协议升级对http1.1类型的exchange不适用
cf = wrapForUpgrade(cf);
cf = wrapForLog(cf);
return cf;
}
我们如果进入ExchangeImpl的实现类Http1Exchange的getResponseAsync方法,会发现其主要做的就是调用Http1Response的readHeadersAsync方法。于是,我们直接进入Http1Response的readHeadersAsync方法。
该方法定义解析Http响应头后要进行的操作:
//Http1Response的readHeadersAsync方法
public CompletableFuture<Response> readHeadersAsync(Executor executor) {
if (debug.on())
debug.log("Reading Headers: (remaining: "
+ asyncReceiver.remaining() +") " + readProgress);
//第一次解析
if (firstTimeAround) {
if (debug.on()) debug.log("First time around");
firstTimeAround = false;
} else {
// with expect continue we will resume reading headers + body.
asyncReceiver.unsubscribe(bodyReader);
bodyReader.reset();
hd = new Http1HeaderParser();
readProgress = State.READING_HEADERS;
headersReader.reset();
headersReader.start(hd);
asyncReceiver.subscribe(headersReader);
}
//这一步是什么呢?它返回了一个响应头读取的占位符。我们稍后分解
CompletableFuture<State> cf = headersReader.completion();
assert cf != null : "parsing not started";
if (debug.on()) {
debug.log("headersReader is %s",
cf == null ? "not yet started"
: cf.isDone() ? "already completed"
: "not yet completed");
}
//定义好解析响应头完成后的操作:返回一个Response对象
Function<State, Response> lambda = (State completed) -> {
assert completed == State.READING_HEADERS;
if (debug.on())
debug.log("Reading Headers: creating Response object;"
+ " state is now " + readProgress);
//解除响应头读取者对Http响应接收者的订阅
asyncReceiver.unsubscribe(headersReader);
responseCode = hd.responseCode();
headers = hd.headers();
response = new Response(request,
exchange.getExchange(),
headers,
connection,
responseCode,
HTTP_1_1);
if (Log.headers()) {
StringBuilder sb = new StringBuilder("RESPONSE HEADERS:\n");
Log.dumpHeaders(sb, " ", headers);
Log.logHeaders(sb.toString());
}
return response;
};
//在解析完响应头后执行该操作
if (executor != null) {
return cf.thenApplyAsync(lambda, executor);
} else {
return cf.thenApply(lambda);
}
}
由此,响应头的接收和解析过程就已经分析完成。采用了异步编程和非阻塞I/O的编程模式,也是该节的主要特点之一。
7. 响应体的解析
在上一节中看到,在解析响应头完成时, Http1Response的状态会升级为READING_BODY,然而,这并不意味着这一响应的响应体会被立刻解析返回。正如上一篇所呈现:一次用户请求可能会带来多次的请求——响应交换,只有当HttpClient应用响应头过滤器,发现没有新的请求生成,才会解析最终的响应。
我们将看到,对响应体的解析,又将引入新的响应式发布——订阅过程。
先回顾下我们发起请求时的调用方式:在send()或者sendAsync()中传入的第二个参数,是调用HttpResponse.BodyHandlers::ofString方法生成的一个对象。这个对象的作用,一句话说,是构造、生成出一个真正的响应体订阅者。
client.sendAsync(request, HttpResponse.BodyHandlers.ofString())
还是从uml类图开始:我们可以看到,BodyHandler是一个位于HttpResponse接口内部的函数式接口,它只有一个名为apply的方法,用于生成响应体的真正订阅者:BodySubscriber的具体实现。HttpResponse里的两个工具类HttpHandlers和HttpSubscribers,提供了便捷的静态方法,分别用于生成BodyHandler和BodySubscriber的具体实现。
我们跟踪一下调用BodyHandlers::ofString,发生了什么:
public static BodyHandler<String> ofString() {
return (responseInfo) -> BodySubscribers.ofString(charsetFrom(responseInfo.headers()));
}
可以看到,如果该BodyHandler被调用,那么将会响应头中获取字符集。我们再跟踪BodySubscribers::ofString方法。
public static BodySubscriber<String> ofString(Charset charset) {
Objects.requireNonNull(charset);
return new ResponseSubscribers.ByteArraySubscriber<>(
bytes -> new String(bytes, charset)
);
}
可以看到,如果该BodyHandler被调用,会生成一个BodyHandler的具体实现ByteArraySubscriber。它是一个标准的Flow-api中的订阅者,其中维持了一个接收响应体数据的缓冲队列,以及一个用于收集响应数据的函数:finisher。响应数据在onNext方法中被接收后,放入缓冲列表received,再接收完成时,onComplete方法会使用finisher收集响应数据成为最终给用户的结果。在上面的BodySubscribers::ofString方法中,finisher只是简单地把收到的byte数组生成了字符串。
//BodyHandler的具体实现
public static class ByteArraySubscriber<T> implements TrustedSubscriber<T> {
private final Function<byte[], T> finisher;
private final CompletableFuture<T> result = new MinimalFuture<>();
//响应体接收列表
private final List<ByteBuffer> received = new ArrayList<>();
private volatile Flow.Subscription subscription;
public ByteArraySubscriber(Function<byte[],T> finisher) {
this.finisher = finisher;
}
@Override
public void onSubscribe(Flow.Subscription subscription) {
if (this.subscription != null) {
subscription.cancel();
return;
}
this.subscription = subscription;
//接受订阅时,请求接收最大长度的响应体数据
// We can handle whatever you've got
subscription.request(Long.MAX_VALUE);
}
@Override
public void onNext(List<ByteBuffer> items) {
// incoming buffers are allocated by http client internally,
// and won't be used anywhere except this place.
// So it's free simply to store them for further processing.
assert Utils.hasRemaining(items);
//接收响应数据时,存到缓冲列表中
received.addAll(items);
}
@Override
public void onError(Throwable throwable) {
received.clear();
result.completeExceptionally(throwable);
}
static private byte[] join(List<ByteBuffer> bytes) {
int size = Utils.remaining(bytes, Integer.MAX_VALUE);
byte[] res = new byte[size];
int from = 0;
for (ByteBuffer b : bytes) {
int l = b.remaining();
b.get(res, from, l);
from += l;
}
return res;
}
@Override
public void onComplete() {
try {
//接收完成时,先将byteBuffer数据转成byte数组,再收集
result.complete(finisher.apply(join(received)));
received.clear();
} catch (IllegalArgumentException e) {
result.completeExceptionally(e);
}
}
@Override
public CompletionStage<T> getBody() {
return result;
}
}
响应体订阅者就分析完毕了。那么,发布者是什么呢?响应体处理的流程又是怎样的呢?
我们回到HttpClient处理多重响应的后的方法:MultiExchange.responseAsync0(CompletableFuture start)
private CompletableFuture<HttpResponse<T>>
responseAsync0(CompletableFuture<Void> start) {
//之前分析的全部内容,包括对多次交换的管理、对单次请求的发送和响应接收、响应头解析
//都发生在这个responseAsyncImpl方法中
return start.thenCompose( v -> responseAsyncImpl())
.thenCompose((Response r) -> {
//获取当前最终的交换
Exchange<T> exch = getExchange();
//检查204状态码,及无需(不可)有响应体的清清裤
if (bodyNotPermitted(r)) {
if (bodyIsPresent(r)) {
IOException ioe = new IOException(
"unexpected content length header with 204 response");
exch.cancel(ioe);
return MinimalFuture.failedFuture(ioe);
} else
//处理没有响应体的情况
return handleNoBody(r, exch);
}
//我们着重要分析的方法
return exch.readBodyAsync(responseHandler)
.thenApply((T body) -> {
//解析响应体完成后,返回一个最终要给调用者的响应对象
this.response =
new HttpResponseImpl<>(r.request(), r, this.response, body, exch);
return this.response;
});
}).exceptionallyCompose(this::whenCancelled);
}
我们看到,这过程调用了Exchange类的readBodyAsync(responseHandler)方法。
我们继续跟踪,发现直接调用了http1Exchange的responseAsync方法,我们跟随进入。
@Override
CompletableFuture<T> readBodyAsync(BodyHandler<T> handler,
boolean returnConnectionToPool,
Executor executor)
{
//应用传入的BodyHandler,生成具体的的bodySubscriber
BodySubscriber<T> bs = handler.apply(new ResponseInfoImpl(response.responseCode(),
response.responseHeaders(),
HTTP_1_1));
//读取响应,我们将稍后进入
CompletableFuture<T> bodyCF = response.readBody(bs,
returnConnectionToPool,
executor);
return bodyCF;
}
Http1Response.readBody方法时我们分析的重点,我们跟随进入:
//Http1Response.readBody方法
public <U> CompletableFuture<U> readBody(HttpResponse.BodySubscriber<U> p,
boolean return2Cache,
Executor executor) {
if (debug.on()) {
debug.log("readBody: return2Cache: " + return2Cache);
if (request.isWebSocket() && return2Cache && connection != null) {
debug.log("websocket connection will be returned to cache: "
+ connection.getClass() + "/" + connection );
}
}
assert !return2Cache || !request.isWebSocket();
this.return2Cache = return2Cache;
//这里将我们传入的BodyHandler生成的bodySubscriber包进了一个Http1BodySubscriber对象
//目的是防止发生错误时,onError方法被多次调用
//该subscriber做的基本只是代理转发的作用,会把主要功能交给我们的BodySubscriber
final Http1BodySubscriber<U> subscriber = new Http1BodySubscriber<>(p);
final CompletableFuture<U> cf = new MinimalFuture<>();
//确定content-length,可能为定长/-1(分块)或-2(未知)
long clen0 = headers.firstValueAsLong("Content-Length").orElse(-1L);
final long clen = fixupContentLen(clen0);
//解除响应体读取者对Http1响应异步接收者的订阅(其实之前解除过)
// expect-continue reads headers and body twice.
// if we reach here, we must reset the headersReader state.
asyncReceiver.unsubscribe(headersReader);
headersReader.reset();
ClientRefCountTracker refCountTracker = new ClientRefCountTracker();
// We need to keep hold on the client facade until the
// tracker has been incremented.
connection.client().reference();
executor.execute(() -> {
try {
//生成Http1响应体对象
content = new ResponseContent(
connection, clen, headers, subscriber,
this::onFinished
);
if (cf.isCompletedExceptionally()) {
// if an error occurs during subscription
connection.close();
return;
}
// increment the reference count on the HttpClientImpl
// to prevent the SelectorManager thread from exiting until
// the body is fully read.
refCountTracker.acquire();
//响应体解析者实例化,入参是完成时的回调,会设置bodyReader的future占位符为读取完成
//会根据前面的clen0来确定是实例化那种类型(定长,分块,不定长)的BodyParser
bodyParser = content.getBodyParser(
(t) -> {
try {
if (t != null) {
try {
subscriber.onError(t);
} finally {
cf.completeExceptionally(t);
}
}
} finally {
bodyReader.onComplete(t);
if (t != null) {
connection.close();
}
}
});
bodyReader.start(bodyParser);
CompletableFuture<State> bodyReaderCF = bodyReader.completion();
//设置响应体读取者订阅Http1响应异步接收者
//里面会调用flush方法,内部的handlePendingDelegate方法,
//会促使订阅的完成
asyncReceiver.subscribe(bodyReader);
assert bodyReaderCF != null : "parsing not started";
// Make sure to keep a reference to asyncReceiver from
// within this
CompletableFuture<?> trailingOp = bodyReaderCF.whenComplete((s,t) -> {
t = Utils.getCompletionCause(t);
try {
if (t == null) {
if (debug.on()) debug.log("Finished reading body: " + s);
assert s == State.READING_BODY;
}
if (t != null) {
subscriber.onError(t);
cf.completeExceptionally(t);
}
} catch (Throwable x) {
// not supposed to happen
asyncReceiver.onReadError(x);
} finally {
// we're done: release the ref count for
// the current operation.
refCountTracker.tryRelease();
}
});
connection.addTrailingOperation(trailingOp);
} catch (Throwable t) {
if (debug.on()) debug.log("Failed reading body: " + t);
try {
subscriber.onError(t);
cf.completeExceptionally(t);
} finally {
asyncReceiver.onReadError(t);
}
} finally {
connection.client().unreference();
}
});
//获取最终的响应体,对于ByteArraySubscriber而言,只是简单取个result
ResponseSubscribers.getBodyAsync(executor, p, cf, (t) -> {
cf.completeExceptionally(t);
asyncReceiver.setRetryOnError(false);
asyncReceiver.onReadError(t);
});
return cf.whenComplete((s,t) -> {
if (t != null) {
// If an exception occurred, release the
// ref count for the current operation, as
// it may never be triggered otherwise
// (BodySubscriber ofInputStream)
// If there was no exception then the
// ref count will be/have been released when
// the last byte of the response is/was received
refCountTracker.tryRelease();
}
});
}
我们可以看到:Http1Response的readBody方法设置了响应体读取者BodyReader对Http1AsyncReceiver的订阅。在这之后,Http1AsyncReceiver接收到的数据便会源源不断地交给bodyReader处理。这一过程,便发生在上一节提到的,flush方法中。在所有响应数据都被解析完成后,便会将最终的结果返回。
我们回顾下上节提到的Http1AsyncReceiver的flush方法,它的delegate.tryAsyncReceive方法要求我们关注BodyReader的执行过程。
//我们只截取一小段, 还是这个tryAsyncReceive方法
//由于设置了bodyReader订阅Http1AsyncReceiver,此处delegate即为bodyReader
//if条件成立的结果,是响应体被接收并解析完成
if (!delegate.tryAsyncReceive(buf)) {
final long remaining = buf.remaining();
if (debug.on()) debug.log(() -> {
// If the scheduler is stopped, the queue may already
// be empty and the reference may already be released.
String remstr = scheduler.isStopped() ? "" :
" remaining in ref: "
+ remaining;
remstr += remstr
+ " total remaining: " + remaining();
return "Delegate done: " + remaining;
});
canRequestMore.set(false);
// The last buffer parsed may have remaining unparsed bytes.
// Don't take it out of the queue.
return; // done.
}
我们一路跟踪,会发现最终调用的方法是BodyReader.handle重写方法:
@Override
final void handle(ByteBuffer b,
BodyParser parser,
CompletableFuture<State> cf) {
assert cf != null : "parsing not started";
assert parser != null : "no parser";
try {
if (debug.on())
debug.log("Sending " + b.remaining() + "/" + b.capacity()
+ " bytes to body parser");
//最后还是调用了BodyParser的parse方法,和前面解析响应头类似
//我们跟踪进入
parser.accept(b);
} catch (Throwable t) {
if (debug.on())
debug.log("Body parser failed to handle buffer: " + t);
if (!cf.isDone()) {
cf.completeExceptionally(t);
}
}
}
我们跟随parser.accept(b)这一行代码,看看响应体解析器是如何解析响应体的。前文提到:总共有三种类型的响应体解析器,分别是:
FixedLengthBodyParser,ChunkedBodyParser,UnknownLengthBodyParser
这次我们选取分块的响应体解析器ChunkedBodyParser来看看解析过程。其实也是通过一个类型为ChunkState状态来支持多次调用间的状态流转,每次都解析收到的数据,将解析后的结果交给bodySubscriber。
//下面的代码都位于ResponseContent内部类中
//这里定义了分块状态枚举
static enum ChunkState {READING_LENGTH, READING_DATA, DONE}
//分块的响应体解析器
class ChunkedBodyParser implements BodyParser {
final ByteBuffer READMORE = Utils.EMPTY_BYTEBUFFER;
final Consumer<Throwable> onComplete;
final Logger debug = Utils.getDebugLogger(this::dbgString, Utils.DEBUG);
final String dbgTag = ResponseContent.this.dbgTag + "/ChunkedBodyParser";
volatile Throwable closedExceptionally;
volatile int partialChunklen = 0; // partially read chunk len
volatile int chunklen = -1; // number of bytes in chunk
volatile int bytesremaining; // number of bytes in chunk left to be read incl CRLF
volatile boolean cr = false; // tryReadChunkLength has found CR
volatile int chunkext = 0; // number of bytes already read in the chunk extension
volatile int digits = 0; // number of chunkLength bytes already read
volatile int bytesToConsume; // number of bytes that still need to be consumed before proceeding
//初始化分块状态为读取分块长度。通过该变量来完成读取状态的切换
volatile ChunkState state = ChunkState.READING_LENGTH; // current state
volatile AbstractSubscription sub;
ChunkedBodyParser(Consumer<Throwable> onComplete) {
this.onComplete = onComplete;
}
@Override
public void accept(ByteBuffer b) {
if (closedExceptionally != null) {
if (debug.on())
debug.log("already closed: " + closedExceptionally);
return;
}
// debugBuffer(b);
boolean completed = false;
try {
List<ByteBuffer> out = new ArrayList<>();
do {
//该方法读取解析一个byteBuffer,根据换行符等来确定并切换分块读取状态
//当它返回true,仅当所有分块都被读取完成
if (tryPushOneHunk(b, out)) {
// We're done! (true if the final chunk was parsed).
if (!out.isEmpty()) {
// push what we have and complete
// only reduce demand if we actually push something.
// we would not have come here if there was no
// demand.
boolean hasDemand = sub.demand().tryDecrement();
assert hasDemand;
//最后一个分块内容的交付给订阅者,pusher即是上文提到了包装了
//传入的BodyHandler生成的BodySubscriber的Http1BodySubscriber
pusher.onNext(Collections.unmodifiableList(out));
if (debug.on()) debug.log("Chunks sent");
}
if (debug.on()) debug.log("done!");
assert closedExceptionally == null;
assert state == ChunkState.DONE;
//对asyncReceiver的清理
onFinished.run();
//所有分块传输完成,通知订阅者收集结果
pusher.onComplete();
if (debug.on()) debug.log("subscriber completed");
completed = true;
onComplete.accept(closedExceptionally); // should be null
break;
}
// the buffer may contain several hunks, and therefore
// we must loop while it's not exhausted.
} while (b.hasRemaining());
if (!completed && !out.isEmpty()) {
// push what we have.
// only reduce demand if we actually push something.
// we would not have come here if there was no
// demand.
boolean hasDemand = sub.demand().tryDecrement();
assert hasDemand;
//将下一个分块内容的交付给订阅者,pusher即是上文提到了包装了
//传入的BodyHandler生成的BodySubscriber的Http1BodySubscribe
pusher.onNext(Collections.unmodifiableList(out));
if (debug.on()) debug.log("Chunk sent");
}
assert state == ChunkState.DONE || !b.hasRemaining();
} catch(Throwable t) {
if (debug.on())
debug.log("Error while processing buffer: %s", (Object)t );
closedExceptionally = t;
if (!completed) onComplete.accept(t);
}
}
}
总结一下,响应体的解析可以分为如下过程:
- SocketTube不间断地从socket通道读取响应数据给Http1TubeSubscriber,后者将数据放到外部对象Http1AsyncReceiver维持的一个数据缓冲队列中
- 响应头读取解析结束后,Http1AsyncReceiver暂停从缓冲队列搬运响应数据交付给下游订阅者
- 根据用户提供的响应体处理办法实例化对应的订阅者BodySubscriber,根据响应头信息实例化对应的BodyParser
- Http1AsyncReceiver接受bodyReader的订阅,重启对响应数据的搬运,将响应体交付给bodyReader
- bodyParser接收多次调用,解析响应体,将解析结果交给下游的bodySubscriber
- 响应体解析完成后,bodySubscriber组装接收到的响应体数据成响应结果内容,返回
响应体数据的流转,可以用一下数据流图来描绘:
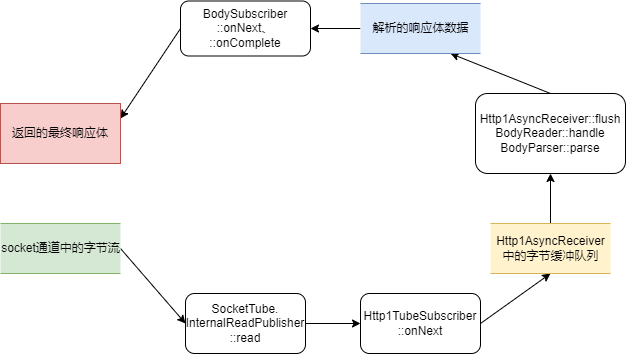
8. 小结
经过漫长的旅途,我们终于完整见识了单个无加密的Http1.1请求——响应过程的生命历程。理解响应式流模型,是理解这一流程的关键。
JDK HttpClient 单次请求的生命周期的更多相关文章
- 05.Django-form表单与请求的生命周期
Django中请求的生命周期 HTTP请求及服务端响应中传输的所有数据都是字符串 步骤 用户在浏览器中输入url时,浏览器会生成请求头和请求体发给服务器 url经过wsgi和中间件,到达路由映射表,在 ...
- Minor【 PHP框架】2.第一个应用与请求的生命周期
框架Github地址:github.com/Orlion/Minor (如果觉得还不错给个star哦(^-^)V) 框架作者: Orlion 知乎:https://www.zhihu.com/peop ...
- Mvc请求的生命周期
ASP.NET Core : Mvc请求的生命周期 translation from http://www.techbloginterview.com/asp-net-core-the-mvc-req ...
- [oldboy-django][2深入django]django一个请求的生命周期 + WSGI + 中间件
1 WSGI # WSGI(是一套协议,很多东西比如wsgiref, uwsgiref遵循这一套协议) - django系统本质 别人的socket(wsgiref或者uwsgiref) + djan ...
- Djngo 请求的生命周期
1.Django请求的生命周期 路由系统 -> 试图函数(获取模板+数据=>渲染) -> 字符串返回给用户 2.路由系统 /index/ -> 函数或类.as_view() / ...
- Envoy 代理中的请求的生命周期
Envoy 代理中的请求的生命周期 翻译自Envoy官方文档. 目录 Envoy 代理中的请求的生命周期 术语 网络拓扑 配置 高层架构 请求流 总览 1.Listener TCP连接的接收 2.监听 ...
- Spring Bean配置默认为单实例 pring Bean生命周期
Bean默认的是单例的. 如果不想单例需要如下配置:<bean id="user" class="..." scope="singleton&q ...
- Django中请求的生命周期
1. 概述 首先我们知道HTTP请求及服务端响应中传输的所有数据都是字符串. 在Django中,当我们访问一个的url时,会通过路由匹配进入相应的html网页中. Django的请求生命周期是指当用户 ...
- django请求的生命周期
1. 概述 首先我们知道HTTP请求及服务端响应中传输的所有数据都是字符串. 在Django中,当我们访问一个的url时,会通过路由匹配进入相应的html网页中. Django的请求生命周期是指当用户 ...
随机推荐
- Set && Map
ES6 提供了新的数据结构 Set, Map Set成员的值都是唯一的,没有重复的值,Set内的元素是强类型,会进行类型检查. let set = new Set([1, true, '1', 'tr ...
- Android 高级UI组件(三)
一.popupWindow 1.AlertDialog和PopupWindow最关键的区别是AlertDialog不能指定显示位置,只能默认显示在屏幕最中间(当然也可以通过设置WindowManage ...
- CentOS 6.5下安装Python+Django+Nginx+uWSGI
1.安装Python31.1先安装zlib库及其他三方库安装uWSGI时需要使用zlib,否则执行python uwsgiconfig.py --build时会报ImportError,就是因为在安装 ...
- js 长按鼠标左键实现溢出内容左右滚动滚动
var nextPress, prevPress; // 鼠标按下执行定时器,每0.1秒向左移一个li内容的宽度 function nextDown() { nextPress = setInterv ...
- Win10 Chrome 在DPI缩放下导致界面放大问题 解决方案
支持:54.0.2840.59 m (64-bit) 以下大多数版本,具体未测试.如有问题可以反馈一下. 方法1:为程序设置"高DPI设置时禁用显示缩放. 方法2:为程序添加启动参数: /h ...
- java输入/输出流的基本知识
通过流可以读写文件,流是一组有序列的数据序列,以先进先出方式发送信息的通道. 输入/输出流抽象类有两种:InputStream/OutputStream字节输入流和Reader/Writer字符输入流 ...
- 如何为Dash/Zeal生成c++ 文档: 以abseil文档为例
目录 1. 软件安装 2 Sample源文件下载: 3. 生成步骤 3.1 使用doxygen生成html文件 3.2 使用docsetutil 生成 dash/Zeal 格式 1. 软件安装: 1. ...
- Mysql从头部署多个版本
目录 一.环境准备 二.下载安装包 三.Mysql-5.6单独部署 四.Mysql-5.7单独部署 五.添加到多版本控制 六.muliti使用 一.环境准备 系统:centos7.3一台 软件版本:m ...
- vue插槽理解
1.插槽作用:父向子传递一段Html代码块 2.分类: (1)默认插槽:规则:父给子传,用父,不传,用子. (2)具名插槽:适用于一个页面有多个插槽时,需要做区分,使用name属性.给插槽取个名字 ( ...
- Istio在Rainbond Service Mesh体系下的落地实践
两年前Service Mesh(服务网格)一出来就受到追捧,很多人认为它是微服务架构的最终形态,因为它可以让业务代码和微服务架构解耦,也就是说业务代码不需要修改就能实现微服务架构,但解耦还不够彻底,使 ...