iGPT and ViT
概
两个将transformer用于图像分类任务的尝试.
主要内容
其实将transformer用于图像分类任务, 关键的问题是如果生成tokens.
iGPT
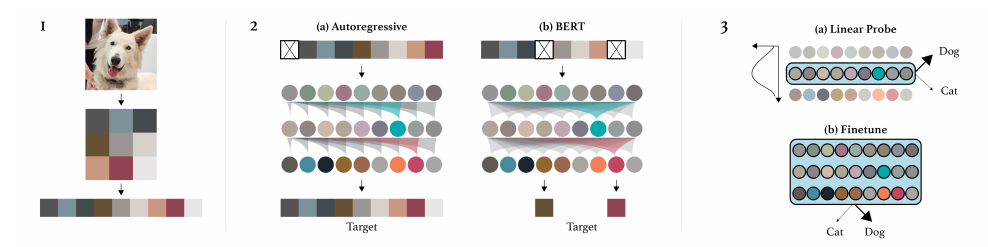
iGPT生成tokens方式很粗暴, 将图片拉成向量, 每一个element对应一个token, 然后根据‘字典’获得相应的embeddings. 但是普通的图片, 比如224x224x3, 由于transformer的memory需求是四次方的, 显然这个tokens数目无法计算, 所以本文会首先对图片进行压缩, 比如至32x32x3, 但是这样依然不够.
但是32往下的size对于人来说已经不易辨别了, 虽然本文采取的策略是将3通道压缩为1通道. 通过对图片进行k均值分类(k=512), 然后为每个像素点分配中心, 作者发现这么做效果不错.
注: 因此字典的大小也应该是长度也应该是512.
注: 在fine-tuning的时候, 因为最后的输出是(B, S, D), 也没法直接加全连接层分类, 故首先通过average pooling 变成(B, D), 再通过\(W^{K \times D}\)获得logits.
ViT
ViT则不这么粗暴, 其首先将图片分割成一个个patch, 然后通过一个线性投影\(W\)变成embeddings, 注意这里不再是NLP中的通过字典索取了.
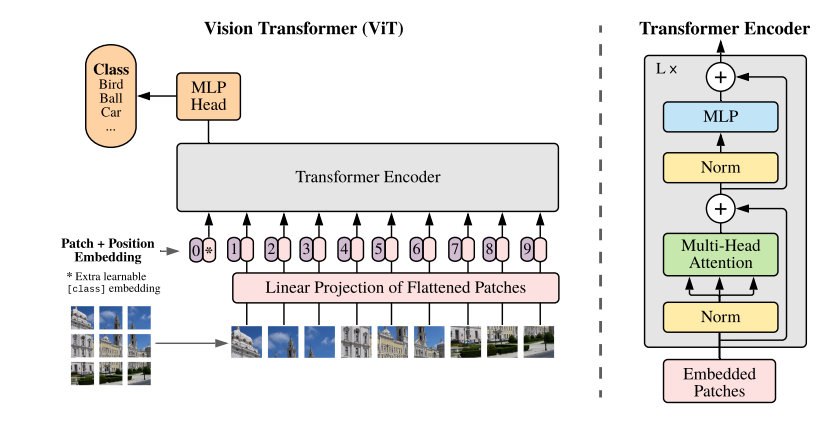
需要特别注意的是, 第一个embedding对应的是类别的embedding, 其对应的输出\(Z_0^L\)(最后的第0个token)用于最后的分类任务. 故不像iGPT, ViT其实是有监督的.
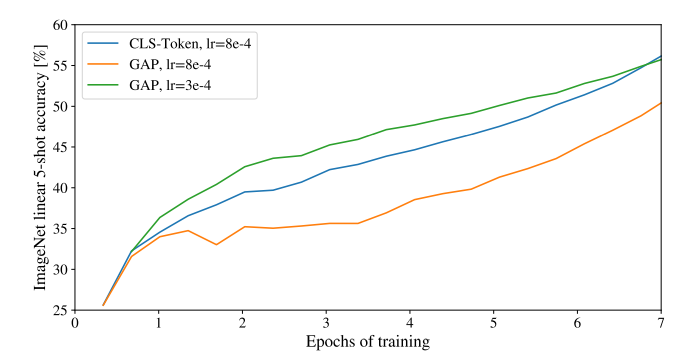
为什么不想iGPT一样通过average pooling来使用所有tokens来分类呢?
其实是可以的, 作者他们最先尝试的就是这个策略, 但是由于学习率没调好, 所以本文显示加了类别的token, 实际情况如下图:
能否从有监督变成自监督?
其实也是可以的, 可以最后预测每一个patch的平均值:
Finally, we predict the 3-bit, mean color (i.e. 512 colors in total) of every corrupted patch using their respective path representations.
positional embeddings有什么影响?
作者试了1-D, 2-D, 以及相对编码, 在第一层, 每一层(单独), 每一层(共享)策略下比较, 发现相差无几, 但是有位置编码会比无位置编码好很多.
代码
iGPT and ViT的更多相关文章
- VIT Vision Transformer | 先从PyTorch代码了解
文章原创自:微信公众号「机器学习炼丹术」 作者:炼丹兄 联系方式:微信cyx645016617 代码来自github [前言]:看代码的时候,也许会不理解VIT中各种组件的含义,但是这个文章的目的是了 ...
- 带你读Paper丨分析ViT尚存问题和相对应的解决方案
摘要:针对ViT现状,分析ViT尚存问题和相对应的解决方案,和相关论文idea汇总. 本文分享自华为云社区<[ViT]目前Vision Transformer遇到的问题和克服方法的相关论文汇总& ...
- ICCV2021 | Tokens-to-Token ViT:在ImageNet上从零训练Vision Transformer
前言 本文介绍一种新的tokens-to-token Vision Transformer(T2T-ViT),T2T-ViT将原始ViT的参数数量和MAC减少了一半,同时在ImageNet上从 ...
- EfficientFormer:轻量化ViT Backbone
论文:<EfficientFormer: Vision Transformers at MobileNet Speed > Vision Transformers (ViT) 在计算机视觉 ...
- [炼丹术]基于SwinTransformer的目标检测训练模型学习总结
基于SwinTransformer的目标检测训练模型学习总结 一.简要介绍 Swin Transformer是2021年提出的,是一种基于Transformer的一种深度学习网络结构,在目标检测.实例 ...
- java web学习总结(三十) -------------------JSTL表达式
一.JSTL标签库介绍 JSTL标签库的使用是为弥补html标签的不足,规范自定义标签的使用而诞生的.使用JSLT标签的目的就是不希望在jsp页面中出现java逻辑代码 二.JSTL标签库的分类 核心 ...
- java web学习总结(二十九) -------------------JavaBean的两种开发模式
SUN公司推出JSP技术后,同时也推荐了两种web应用程序的开发模式,一种是JSP+JavaBean模式,一种是Servlet+JSP+JavaBean模式. 一.JSP+JavaBean开发模式 1 ...
- [No0000A2]“原始印欧语”(PIE)听起来是什么样子?
"Faux Amis"节目中经常提到"原始印欧语"(PIE)——"Proto-Indo-European". 我们说过,英语,法语中的&qu ...
- git的基本介绍和使用
前言:从事iOS开发一年多以来,一直使用svn管理源代码.对svn的特点和弊端已经深有体会.前些天双十二前后,项目工期紧张到爆,起早贪黑的加班,可谓披星戴月,这还不止,回到家中还要疯狂的敲代码.那么问 ...
随机推荐
- 学习java的第十天
一.今日收获 1.java完全学习手册第二章2.9程序流程控制中的选择结构与顺序结构的例题 2.观看哔哩哔哩上的教学视频 二.今日问题 1.例题的问题不大,需要注意大小写,新的语句记忆不牢 2.哔哩哔 ...
- Spark基础:(二)Spark RDD编程
1.RDD基础 Spark中的RDD就是一个不可变的分布式对象集合.每个RDD都被分为多个分区,这些分区运行在分区的不同节点上. 用户可以通过两种方式创建RDD: (1)读取外部数据集====> ...
- Git提交规范
Commit message 的格式 每次提交,Commit message 都包括三个部分:Header,Body 和 Footer. <type>(<scope>): &l ...
- 转 Android应用开发必备的20条技能
https://blog.csdn.net/u012269126/article/details/52433237 有些andorid开发人员感觉很迷茫,接下来该去看系统源码还是继续做应用,但是感觉每 ...
- 「Python实用秘技02」给Python函数定“闹钟”
本文完整示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/PythonPracticalSkills 这是我的系列文章「Python实用秘技」的第2期 ...
- 车载以太网第二弹 | 测试之实锤-物理层PMA测试实践
前言 本期先从物理层"PMA测试"开始,下图1为"PMA测试"的测试结果汇总图.其中,为了验证以太网通信对线缆的敏感度,特选取两组不同特性线缆进行测试对比,果然 ...
- PDF.js Electron Viewer
PDF.js 是基于 HTML5 解析与渲染 PDF 的 JavaScript 库,由 Mozilla 主导开源. 本文旨在介绍 PDF.js 于 Electron 里如何开始使用,实际尝试了用其 A ...
- 搭建直接通过CPU执行汇编语言的环境
搭建直接通过CPU执行汇编语言环境 我们通过编译写好的汇编语言代码可以生成.bin的机器语言二进制代码.但是这个.bin程序我们该如何运行呢? 这里其实有两个办法: 1: 将其作为一个Windows/ ...
- QT QApplication干了啥?
------------恢复内容开始------------ QCoreApplicationPrivate 会取得current thread; 在windows平台创建TLS变量,记录线程信息,并 ...
- java中栈,堆,方法区
最近在看面试题复习javaee,所以在这里对栈,堆,方法区做一下整理 参考了https://www.cnblogs.com/hqji/p/6582365.html 1.栈 每个线程包含一个栈区,栈中只 ...