STM32 HAL 库实现乒乓缓存加空闲中断的串口 DMA 收发机制,轻松跑上 2M 波特率
前言
直接储存器访问(Direct Memory Access,DMA),允许一些设备独立地访问数据,而不需要经过 CPU 介入处理。因此在访问大量数据时,使用 DMA 可以节约可观的 CPU 处理时间。在 STM32 中一般的 DMA 传输方向:内存->内存、外设->内存、内存->外设。这里的外设可以是 UART、SPI 等数据收发设备。
通用异步收发传输器(Universal Asynchronous Receiver/Transmitter,UART),在嵌入式开发中一般称为串口,通常用于中、低速通信场景,波特率低有 6400 bps,高能达到 4~5 Mbps。波特率低于 115200 bps 而且数据量不大场景中一般用不到 DMA 收发数据,因为 STM32 芯片的主频有几十到上百兆赫兹,低速串口这点中断响应就洒洒水而已。但当收发数据量很大,或波特率提高到 Mbps 数量级时就很有使用 DMA 的必要了,这时再使用阻塞方式或中断方式收发数据,都会占用过多的 CPU 时间,影响其他任务的执行。
对于 STM32 中使用 DMA 收发数据,网络上有很多例程和博客,作为学习 DMA 的使用都没问题。但它们中的大部分都是基础的使用,在高速、大数据量的场景中很容易出现数据异常。对于一个高速、可靠的串口收发程序而言,DMA 是必须的,而双缓冲区、空闲中断以及 FIFO 数据缓冲区也是非常重要的成分。这也是本文将要解决的问题。
STM32CubeMX 配置
本文使用的开发平台:
- STM32F407(RoboMaster C 型板)
- STM32CubeMX 6.3.0
- STM32Cube FW_F4 V1.26.2
- CLion
- GNU C/C++ Compiler
首先使能高速外部时钟
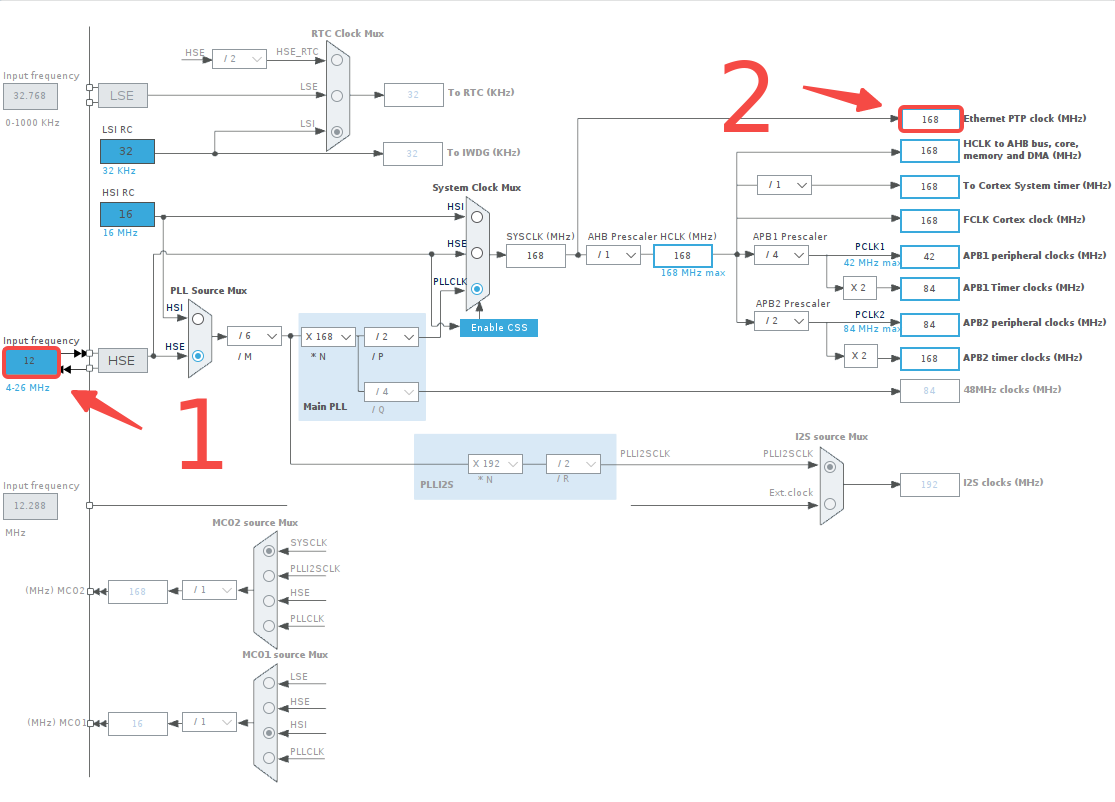
然后设置时钟树。1 处是外部晶振的频率,按自己所用晶振的实际频率填写;2 处一般填写自己所用芯片的最大频率,我这里用的 F407 就是 168 MHz。填入后回车,其他地方的数值都会自动计算出来,非常方便。
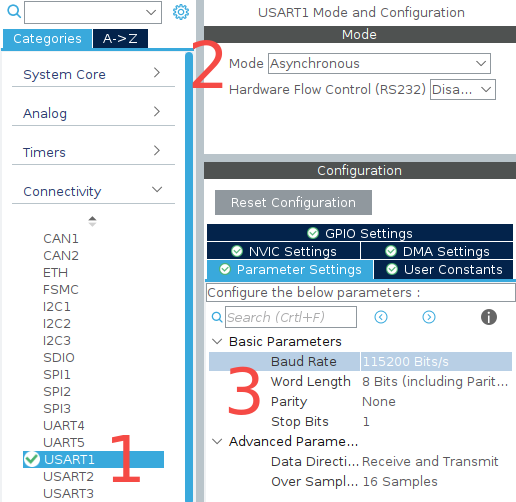
接下来配置串口:
选择一个串口;
设置模式为 Asynchronous(异步);
设置波特率、帧长度、奇偶校验以及停止位长度;
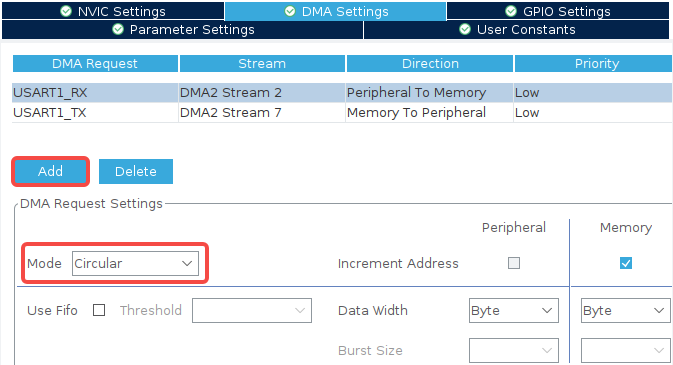
点击 Add 添加接收和发送的 DMA 配置,注意在 RX 中将 DMA 模式改为 Circular,这样 DMA 接收只用开启一次,缓冲区满后 DMA 会自动重置到缓冲区起始位置,不再需要每次接收完成后重新开启 DMA;
开启串口总中断;

选择正确的 GPIO 引脚。在 CubeMX 默认选择的引脚大多数都正确的情况下,这很容易被忽略,出 BUG 再查的时候很难想到是这里的问题,一定要核对好。
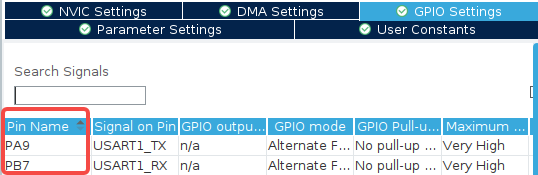
其他如调试接口、操作系统以及工程管理等设置不在赘述,一顿常规操作后可 GENERATE CODE。
串口 DMA 接收
串口收到数据之后,DMA 会逐字节搬运到 RX_Buf 中。搬运到一定的数量时,就会产生中断(空闲中断、半满中断、全满中断),程序会进入回调函数以处理数据。处理数据这一步在本文中是将数据写入 FIFO 中供应用读取,将在后文介绍。先来看数据接收的流程图。
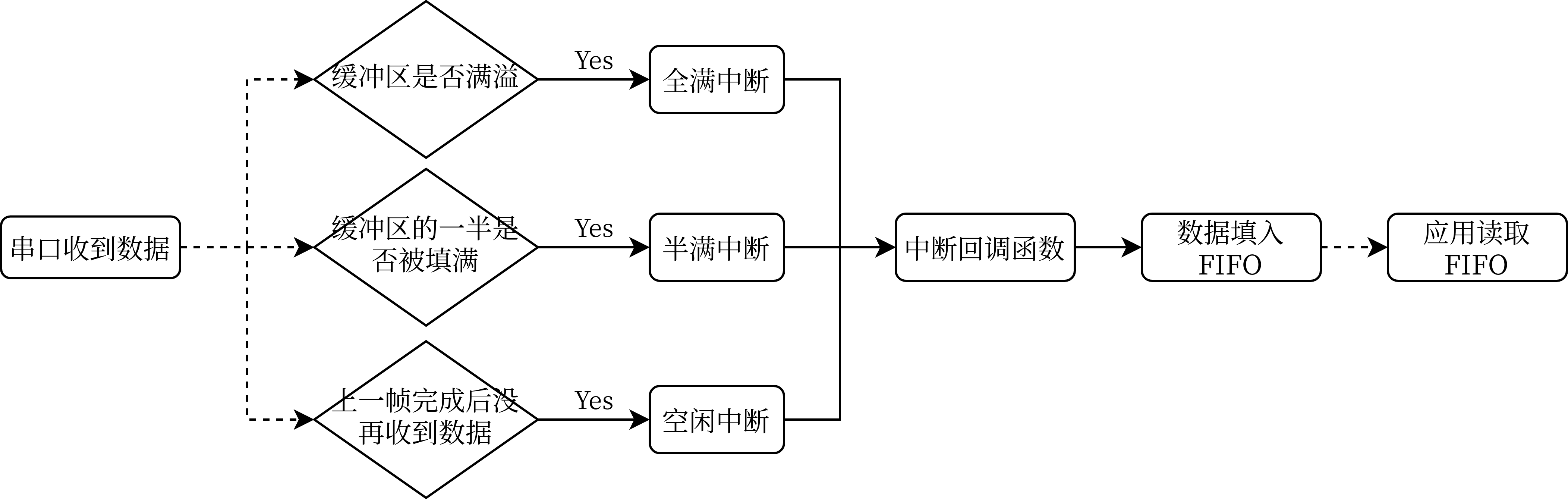
全满中断和半满中断都很好理解,就是串口 DMA 的缓冲区填充了一半和填满时产生的中断。而空闲中断是串口在上一帧数据接收完成之后在一个字节的时间内没有接收到数据时产生的中断,即总线进入了空闲状态。这对于接收不定长数据十分方便。
现在网络上大部分教程都使用了全满中断加空闲中断的方式来接收数据,不过这存在了一定的风险:DMA 可以独立于 CPU 传输数据,这意味着 CPU 和 DMA 有可能同时访问缓冲区,导致 CPU 处理其中的数据到中途时 DMA 继续传输数据把之前的缓冲区覆盖掉,造成了数据丢失。所以更合理的做法是借助半满中断实现乒乓缓存。
一个缓冲区实现的乒乓缓存
乒乓缓存是指一个缓存写入数据时,设备从另一个缓存读取数据进行处理;数据写入完成后,两边交换缓存,再分别写入和读取数据。这样给设备留足了处理数据的时间,避免缓冲区中旧数据还没读取完又被新数据覆盖掉的情况。但是出现了一个小问题,就是 STM32 大部分型号的串口 DMA 只有一个缓冲区,要怎么实现乒乓缓存呢?
没错,半满中断。现在,一个缓冲区能拆成两个来用了。

看这图我们再来理解一下上面提到的三个中断:接受缓冲区的前半段填满后触发半满中断,后半段填满后触发全满中断;而这两个中断都没有触发,但是数据包已经结束且后续没有数据时,触发空闲中断。举个例子:向这个缓冲区大小为 20 的程序传送一个大小为 25 的数据包,它会产生三次中断,如下图所示。
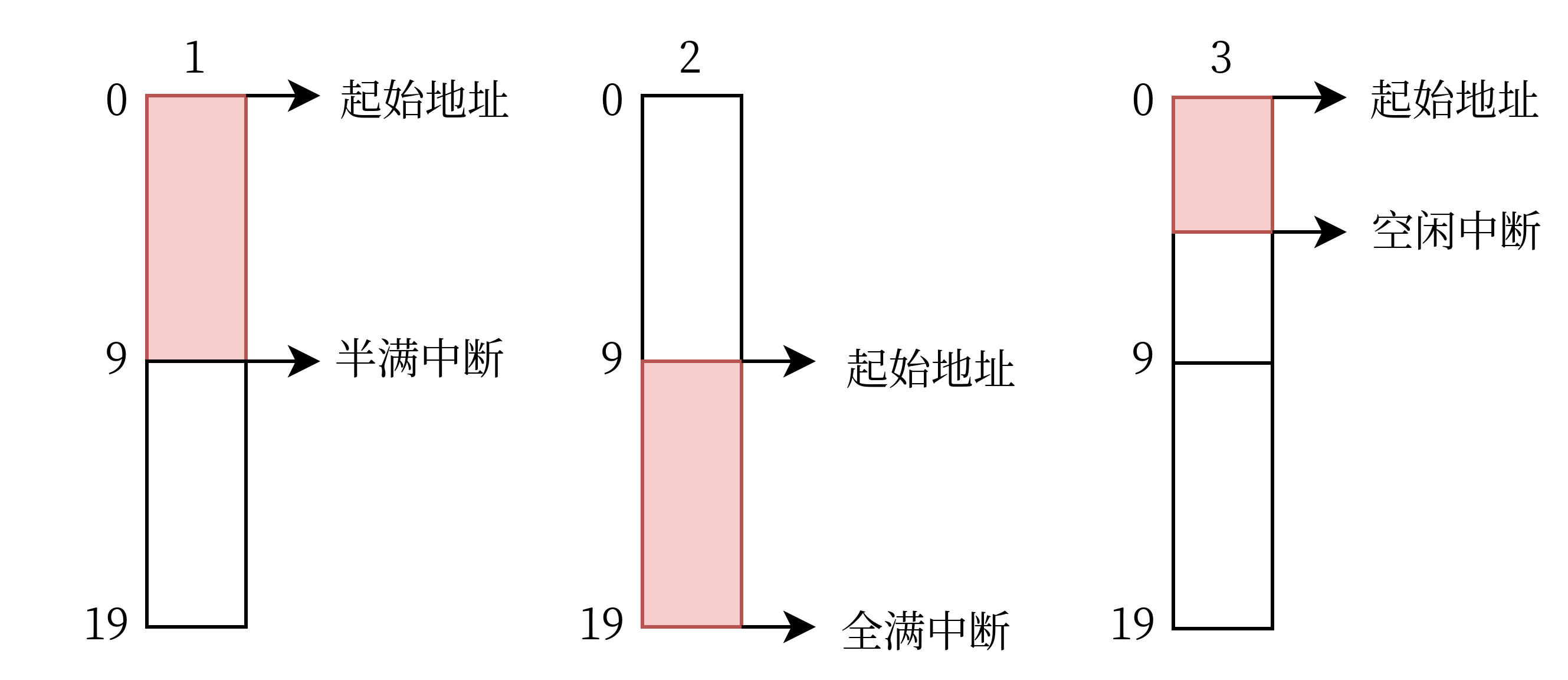
程序实现
原理介绍完成,感谢 ST 提供了 HAL 库,接下来再使用 C 语言实现它们就很简单了。
首先开启串口 DMA 接收。
#define RX_BUF_SIZE 20
uint8_t USART1_Rx_buf[RX_BUF_SIZE];
HAL_UARTEx_ReceiveToIdle_DMA(&huart1, USART1_Rx_buf, RX_BUF_SIZE);
然后编写回调函数,在回调函数里把 USART1_Rx_buf 中的数据搬运到 FIFO 中。
void HAL_UARTEx_RxEventCallback(UART_HandleTypeDef *huart, uint16_t Size)
{
static uint8_t Rx_buf_pos; //本次回调接收的数据在缓冲区的起点
static uint8_t Rx_length; //本次回调接收数据的长度
Rx_length = Size - Rx_buf_pos;
fifo_s_puts(&uart_rx_fifo, &USART1_Rx_buf[Rx_buf_pos], Rx_length); //数据填入 FIFO
Rx_buf_pos += Rx_length;
if (Rx_buf_pos >= RX_BUF_SIZE) Rx_buf_pos = 0; //缓冲区用完后,返回 0 处重新开始
}
这个回调函数本身是弱函数,需要自己把它重写一遍。它有两个传入的参数,第一个参数无须多言,第二个参数 Size 则是指整个缓冲区中已经被使用的大小。它有一个很神奇的地方,上文提到的三个中断都会进入这里,所以要写的代码只有这么几行了。
但是这带来一个问题,如何区分这三个中断呢?答案就是不用区分,只需要每次计算接收数据的起始地址和数据长度就能完成接收。所以我定义了两个静态变量:本次接收数据的长度 = 缓冲区被使用的总大小 - 本次回调接收的数据在缓冲区中的起始位置;而起始位置从 0 开始,每次回调加上本次接收数据的长度就好。
串口 DMA 发送
串口 DMA 的发送比接收简单了许多,只需要把数据从发送数据的 FIFO 复制到发送缓冲区中,然后调用 HAL 库发送函数就完成了:
const uint8_t TX_FIFO_SIZE = 100;
static uint8_t buf[TX_FIFO_SIZE]; //发送缓冲区
uint8_t len = fifo_s_used(&uart_tx_fifo); //待发送数据长度
fifo_s_gets(&uart_tx_fifo, (char *)buf, len); //从 FIFO 取数据
HAL_UART_Transmit_DMA(&huart1, buf, len); //发送
FIFO 队列
先进先出(First In, First Out,FIFO)可能看起来很陌生,但如果叫它队列应该就很熟悉了。在本文中 FIFO 被用来作为 DMA 收发缓冲区(RX_Buf、TX_Buf)与应用程序之间的缓冲区。说起来抽象,看看下图展示的接收状态数据流向。发送时的数据流向相反。
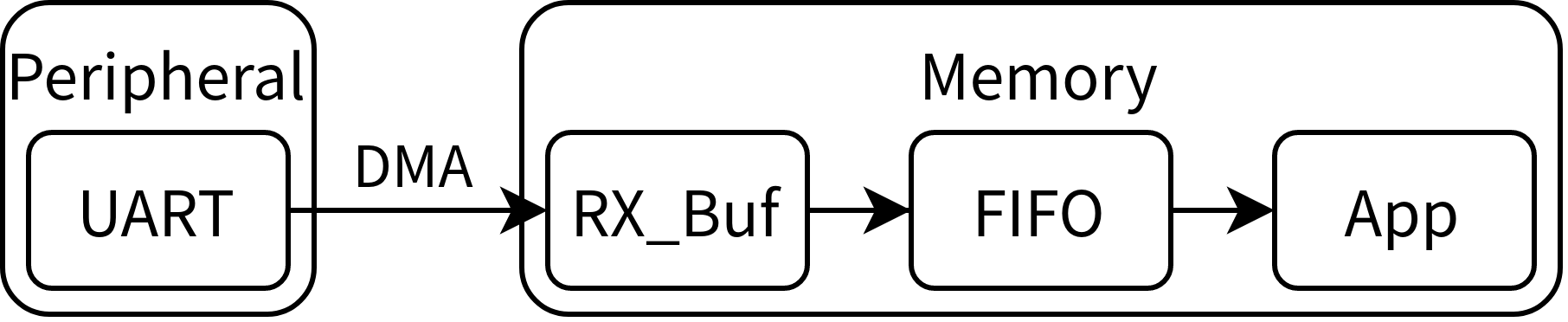
串口接收数据时,DMA 从串口寄存器搬运数据到内存中开辟的接收缓冲区 RX_Buf,并产生中断(半满中断、全满中断、空闲中断);在中断的回调函数里把 RX_Buf 中的数据送到 FIFO 中,应用程序中只需要检测 FIFO 是否为空,非空即可读取数据。
这看起来似乎有些画蛇添足,已经有了一个 DMA 接收缓冲区,直接从这个 RX_Buf 里读取数据岂不美哉?这里存在的问题就是,对 RX_Buf 的处理只能在 DMA 产生的中断的回调函数里进行;而中断的回调函数虽然阻塞住也不影响串口接收数据和 DMA 继续搬运数据到 RX_Buf中,但是 RX_Buf 的大小始终是有限的,后来的数据会把以前的数据覆盖掉。所以只要数据一来就需要立即处理完成,不及时就会丢数据。FIFO 虽然也会有满溢的问题,不过出现概率更小,处理起来相对简单一些。
使用 FIFO 的另一个理由是它把应用层与驱动层隔离开来。App 中不用管 RX_Buf 在什么情况下会获得几个数据,只管从 FIFO 中读数据;串口 DMA 的中断回调函数也有了固定的写法,只管把数据压入 FIFO。在数据不定长、数据量大的场景中,FIFO 无疑是非常必要的组分。
但是细心的朋友可能在上面 STM32CubeMX 配置串口 DMA 的图中发现也有一个 “fifo”,这与上文叙述的 FIFO 有什么区别呢?这也是我有过的困惑,稍作说明。
FIFO 与 DMA 的 FIFO 不是同一个 FIFO
DMA 中也有 FIFO,不过它的作用是在串口寄存器与内存缓冲区之间再加入一个 FIFO 缓冲区,数据流向如下。

由于串口寄存器只能储存一个字节,所以开启直接模式的 DMA 每个字节都要搬运一次数据到内存缓冲区中。而 DMA 的 FIFO 实际效果简单来说就是攒一批数据一起发送出去,可以减少软件开销和 AHB 总线上数据传输的次数,适合数据连续不断且系统中还有其他开销较大的任务这种场景使用。不过也是由于 DMA 的 FIFO 必须攒一批才能发送,攒不够就不发了,所以也有一些局限性。本文没有使用 DMA 的 FIFO,而是使用直接模式。
移植 FIFO
说了这么半天终于到写代码的时候了。我没有自己实现一个 FIFO 环形缓冲区,而是移植了 RoboMaster AI 机器人的固件中使用的 FIFO。
在上述 ropo 中复制
fifo.c与fifo.h文件到自己的工程中。在
fifo.h中删除#include "sys.h",并在上边链接里找到sys.h,将以下几行互斥锁的实现复制到fifo.h中,并额外包含头文件cmsis_gcc.h:#include <cmsis_gcc.h>
#define MUTEX_DECLARE(mutex) unsigned long mutex
#define MUTEX_INIT(mutex) do{mutex = 0;}while(0)
#define MUTEX_LOCK(mutex) do{__disable_irq();}while(0)
#define MUTEX_UNLOCK(mutex) do{__enable_irq();}while(0)
这个 FIFO 库中的动态创建队列的实现使用了
malloc,如果使用了操作系统,应该自己改成操作系统的内存管理 API。不过本文没有使用动态的方式创建队列。
使用 FIFO
在串口 DMA 接收和串口 DMA 发送两节已经介绍过了,这里再贴一下使用方法。
fifo_s_puts(&uart_rx_fifo, &USART1_Rx_buf[Rx_buf_pos], Rx_length); //数据填入 FIFO
uint8_t len = fifo_s_used(&uart_tx_fifo); //待发送数据长度
fifo_s_gets(&uart_tx_fifo, (char *)buf, len); //从 FIFO 取数据
压力测试
这样的一套收发流程当然没必要在低速环境(115200 bps)使用,但是它到底能用在波特率多高的场景下,稳定性如何,仍然是疑问。所以我们需要对它测试一下。
我选用了 PL2303、FT232 两种芯片的串口模块进行测试。
PL2303
PL2303 数据手册支持的串口波特率为 75 bps 到 6 Mbps。不过我测试之后最大的波特率约为 970000 bps,再大就没法收到数据了,远远达不到预期值。希望有好心人告诉我这是怎么一回事。
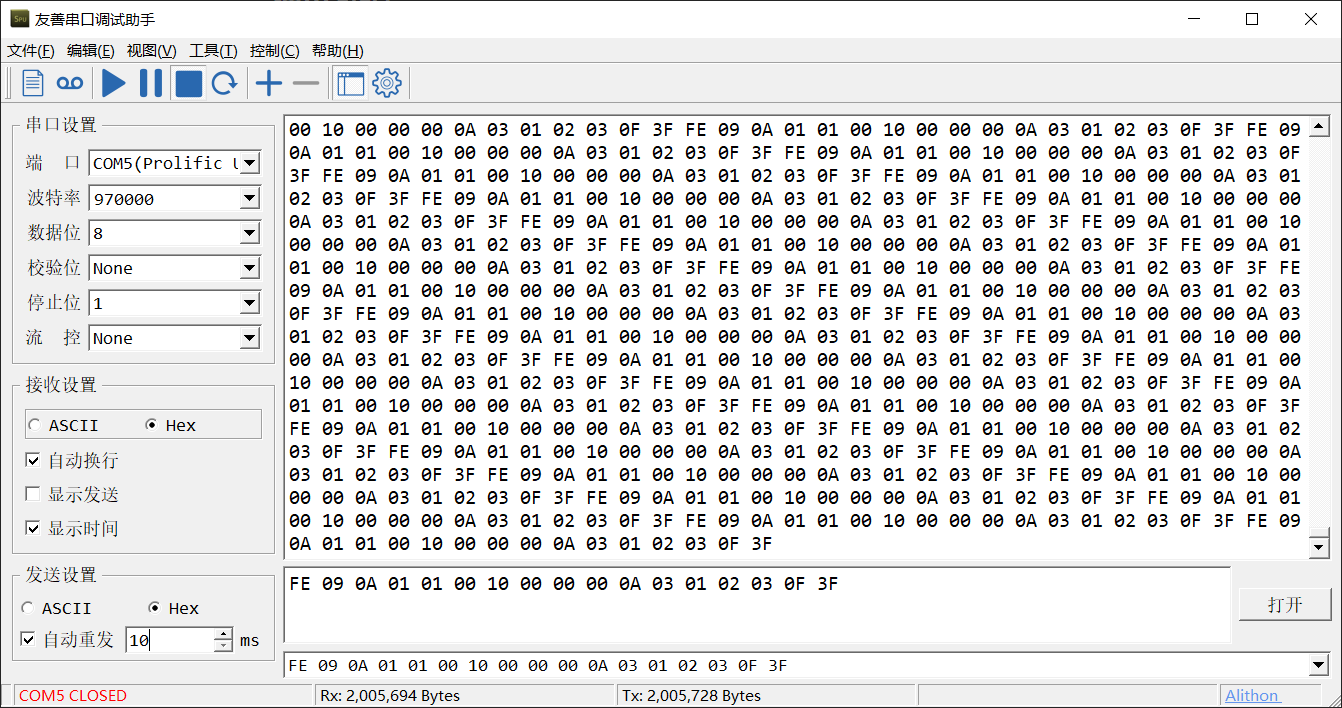
然后测试一下通信稳定性。我以最小自动重发间隔 10 ms 向单片机发送 17 Bytes 的数据包,单片机再回传所有数据。测试运行了 58 分钟,发送了 1958.69 KB 数据,接收到了 1958.69 KB,没有丢包,稳定性过关。而截图中 Tx 比 Rx 的值大是因为停止的时候发送了数据包没有接收,在运行的全过程中两个数据始终相等。
PL2303 还有个小问题是它在 Win10 上的驱动有问题,需要自己下载安装老版本的驱动才能使用。
FT232
FT232 数据手册有如下描述:
- 数据传输速率为300波特(baud)到3兆波特 (RS422/RS485和TTL电平)以及300波特到1兆波特(RS232)
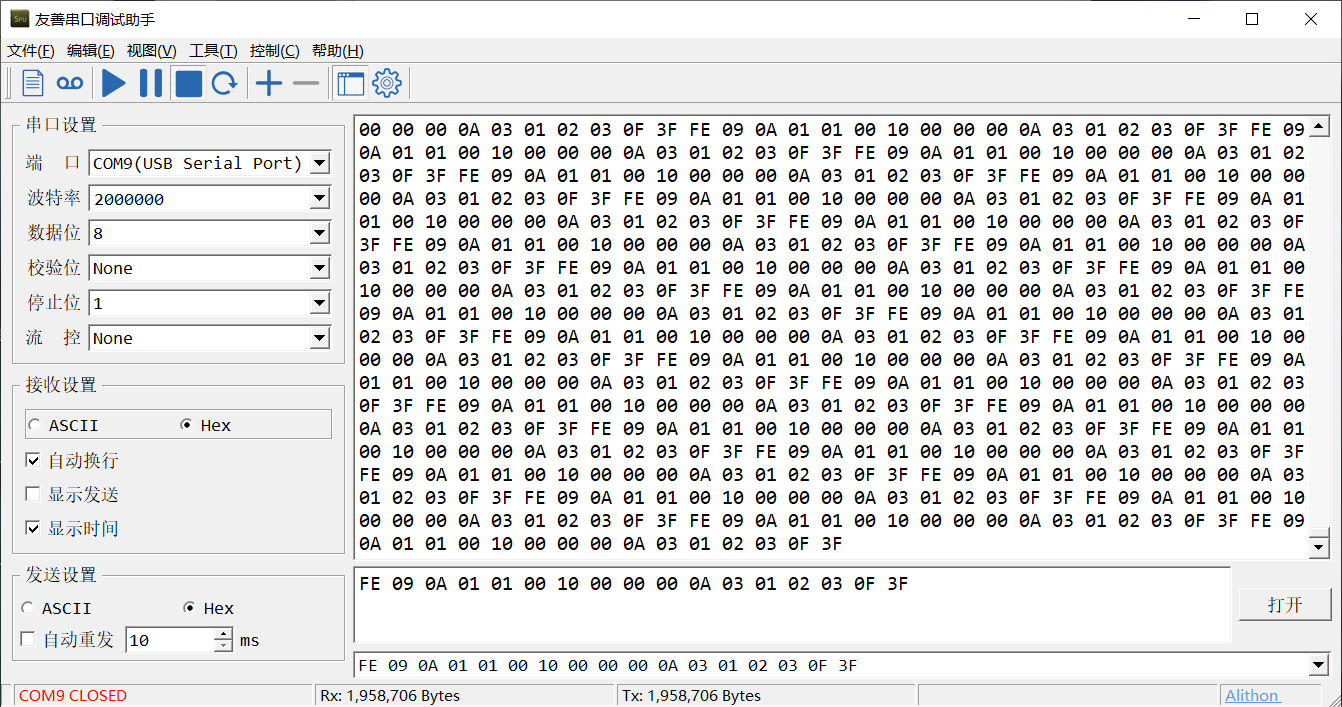
我手上这个使用了 FT232 芯片的串口模块实测最大波特率为 2 Mbps,终于达到了预期。
而 2 Mbps 下的稳定性测试效果也很好,运行了 66 分钟,没有丢包。
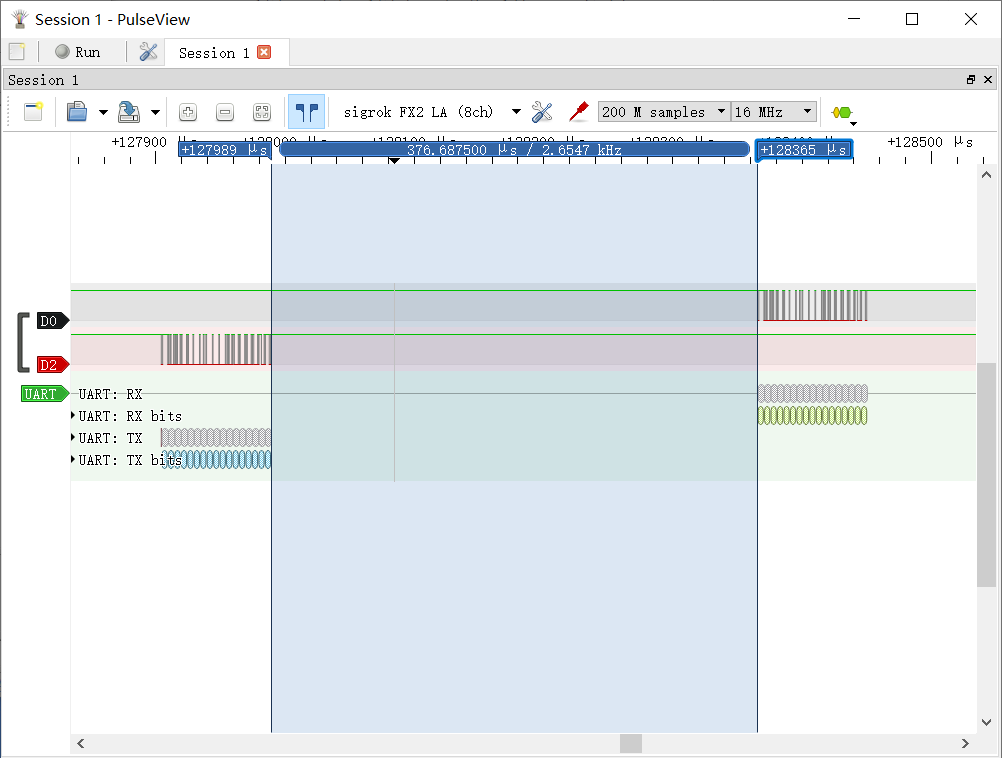
然后使用逻辑分析仪简单测试了 2 Mbps 下通信实际延迟,测试方法为发送一个 17 Bytes 的数据包,单片机接收到后再用串口返回所有数据:
转发延迟在 400 μs 左右。在我的程序里这段时间主要由检测 FIFO 是否为空的频率决定,目前理论值是 1000 Hz。
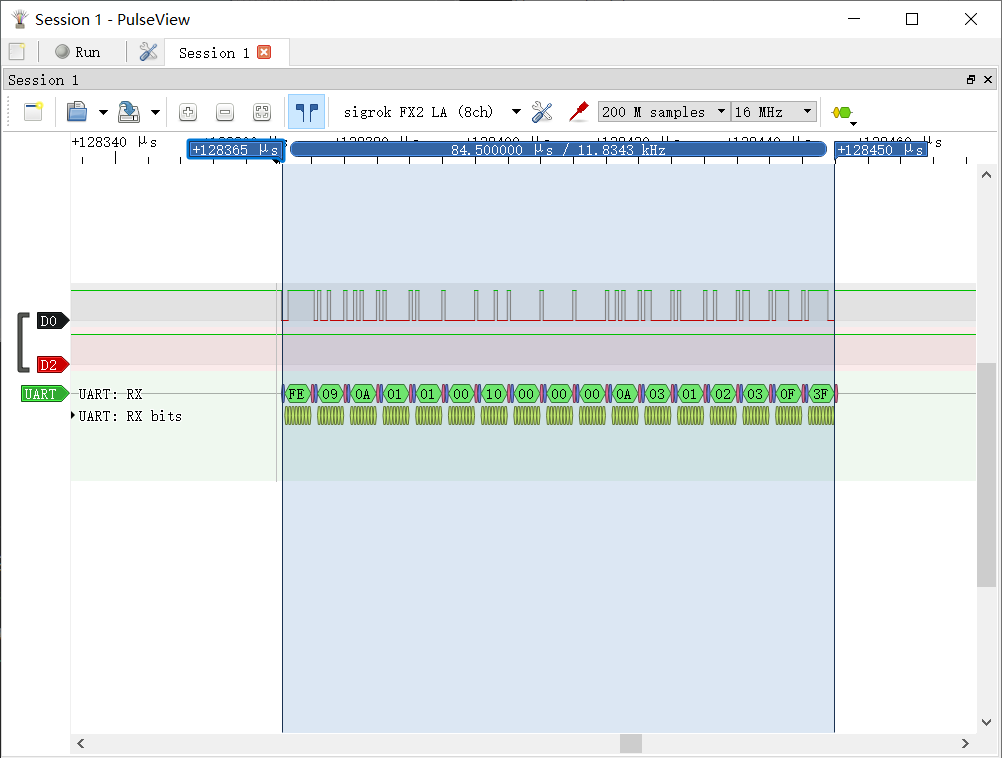
单个 17 Bytes 的数据包时长为 84 μs,收发过程全长约 0.5 ms。
再对比一下 115200 bps 下的通信,单个 17 Bytes 数据包长度约 1500 μs,数据包的整个收发过程约 3100 μs。

根据网上的博客,STM32F407 支持到 10.5 Mbps,但是这点我没在手册上查到。但是 2 Mbps 肯定不是它的极限。单片机与电脑相连的话,受限于串口模块,2 Mbps 基本是天花板了,但是单片机与单片机间的串口通信,仍有潜力可以挖掘。
参考
acuity. (2020, September 3). 一个严谨的STM32串口DMA发送&接收(1.5Mbps波特率)机制_只要思想不滑坡,想法总比问题多。-CSDN博客_dma接收. https://blog.csdn.net/qq_20553613/article/details/108367512
STMicroelectronics. (2021, June). Description of STM32F4 HAL and Low-Layer Drivers. https://www.st.com/content/ccc/resource/technical/document/user_manual/2f/71/ba/b8/75/54/47/cf/DM00105879.pdf/files/DM00105879.pdf/jcr:content/translations/en.DM00105879.pdf
STM32 HAL 库实现乒乓缓存加空闲中断的串口 DMA 收发机制,轻松跑上 2M 波特率的更多相关文章
- 【情人节选帽子】TCS34725颜色传感器和Python图形界面编程(STM32 HAL库)
截图 描述: l STM32 HAL库编程 l 使用模拟IIC通信,方便程序移植 l Python界面编写,蘑菇头的帽子是什么颜色 l STM32 HAL库串口通信 l Python界面使用 ...
- 【有趣的全彩LED | 编程】用STM32 HAL库让WS2812B为你所动
一.效果展示 观看演示效果:https://www.bilibili.com/video/BV1dv411Y7x3 使用STM32 HAL库编程 PWM+DMA控制输出,CubeMX生成初始工程 实现 ...
- STM32 HAL库与标准库的区别_浅谈句柄、MSP函数、Callback函数
最近笔者开始学习STM32的HAL库,由于以前一直用标准库进行开发,于是发现了HAL库几点好玩的地方,在此分享. 1.句柄在STM32的标准库中,假设我们要初始化一个外设(这里以USART为例)我们首 ...
- stm32 HAL库笔记(零)
最近在设计四旋翼飞行器,用stm32f407,有三种开发方式可以选择:一.寄存器开发.二:库函数开发.三:HAL库开发,考虑了一下,选择了HAL库,原因如下: 1. 寄存器开发相对较慢,寄存器很多,配 ...
- STM32 HAL库详解 及 手动移植
源: STM32 HAL库详解 及 手动移植
- 【书籍连载】《STM32 HAL 库开发实战指南—基于F7》-第一章
从今天起,每天开始连载一章<STM32 HAL 库开发实战指南—基于F7>.欢迎各位阅读.点评.学习. 第1章 如何使用本书 1.1 本书的参考资料 本书参考资料为:<STM32 ...
- STM32 HAL库之串口详细篇
一.基础认识 (一) 并行通信 原理:数据的各个位同时传输 优点:速度快 缺点:占用引脚资源多,通常工作时有多条数据线进行数据传输 8bit数据传输典型连接图: 传输的数据是二进制:11101010, ...
- 【春节歌曲回味 | STM32小音乐盒 】PWM+定时器驱动无源蜂鸣器(STM32 HAL库)
l STM32通过PWM与定时器方式控制无源蜂鸣器鸣响 l STM32小音乐盒,歌曲进度条图形显示与百分比显示,歌曲切换 l 编程使用STM32 HAL库 l IIC OLED界面编程,动画实 ...
- STM32 HAL库利用DMA实现串口不定长度接收方法
参考:https://blog.csdn.net/u014470361/article/details/79206352 我这里使用的芯片是 F1 系列的,主要是利用 DMA 数据传输方式实现的,在配 ...
随机推荐
- 学习Layui笔记-父窗口获取子窗口的radio
最近学习layui,使用radio做单项选择的时候,发现layui无论怎么取值,都是默认取到第一个radio的值. 百度下找解决方法. html页面部分 <div class="lay ...
- 利用Spring AOP切面对用户访问进行监控
开发系统时往往需要考虑记录用户访问系统查询了那些数据.进行了什么操作,尤其是访问重要的数据和执行重要的操作的时候将数记录下来尤显的有意义.有了这些用户行为数据,事后可以以用户为条件对用户在系统的访问和 ...
- 539. Minimum Time Difference
Given a list of 24-hour clock time points in "Hour:Minutes" format, find the minimum minut ...
- 关于网页中鼠标动作 onfocus onblur focus()
其中: onFocus事件就是当光标落在文本框中时发生的事件. onBlur事件是光标失去焦点时发生的事件. 例如: <textarea onfocus="if(hello') {va ...
- 学习AJAX必知必会(1)~Ajax
一.ajax(Asynchronous JavaScript And XML,即异步的 JS 和 XML) 1.通过 AJAX 可以在浏览器中向服务器发送异步请求实现无刷新获取数据. 2.优势:无刷新 ...
- javaObject类—hashCode方法
1 package face_object; 2 /* 3 * Object:所有类的根类. 4 * Object是不断抽取而来的,具备所有对象都具备的共性内容. 5 * 常用的共性功能: 6 * 7 ...
- Clang-Format 个人常用配置
Clang-Format 个人常用配置 本文记录 Clang-Format 个人常用配置. 欲了解更多配置选项,可查阅 官方文档. BasedOnStyle: Google AccessModifie ...
- 无法自动装配。未找到 ‘xxxx’ 类型的 Bean。
无法自动装配.未找到 'xxxx' 类型的 Bean. 1.解决办法 打开设置,找到编辑器->检查.把"自动装配Bean类",取消勾选,点击应用.确定.
- linux 权限命令行 xshell 切换用户
一. 权限命令行 两种方式. 1.1 chown -R 指定的用户名, 权限的文件/文件夹 赋予这个用户的权限读写. /*1.0 权限命令行 1. chown -R 指定的用户名 权限的文件/文件夹 ...
- CF388C Fox and Card Game
基于观察可以发现,双方都一定能保证取到每一列靠近自己的 \(\lfloor \frac{k}{2} \rfloor\) 个元素. 那么一旦一个人想要取另一个人能必然能取的部分,另一个人必然可以不让其取 ...