5.Flink实时项目之业务数据准备
1. 流程介绍
在上一篇文章中,我们已经把客户端的页面日志,启动日志,曝光日志分别发送到kafka对应的主题中。在本文中,我们将把业务数据也发送到对应的kafka主题中。
通过maxwell采集业务数据变化,相当于是ods数据,把采集的数据发送到kafka的topic(ods_base_db_m)中,然后flink从kafka消费数据,这个过程有维度数据,就放到hbase中,其他事实数据再发送给kafka作为dwd层。flink消费kafka数据可以做一些简单的ETL处理,比如过滤空值,长度限制。
2. 消费kafka数据及ETL操作
项目地址:https://github.com/zhangbaohpu/gmall-flink-parent/tree/master/gmall-realtime
在模块 gmall-realtime 的dwd包下创建类:BaseDbTask.java
具体步骤就看代码了
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.zhangbao.gmall.realtime.utils.MyKafkaUtil;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.LocalStreamEnvironment;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
/**
* 从kafka读取业务数据
* @author: zhangbao
* @date: 2021/8/15 21:10
* @desc:
**/
public class BaseDbTask {
public static void main(String[] args) {
//1.获取flink环境
LocalStreamEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
//设置并行度
env.setParallelism(4);
//设置检查点
env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(60000);
env.setStateBackend(new FsStateBackend("hdfs://hadoop101:9000/gmall/flink/checkpoint/baseDbApp"));
//指定哪个用户读取hdfs文件
System.setProperty("HADOOP_USER_NAME","zhangbao");
//2.从kafka获取topic数据
String topic = "ods_base_db_m";
String group = "base_db_app_group";
FlinkKafkaConsumer<String> kafkaSource = MyKafkaUtil.getKafkaSource(topic, group);
DataStreamSource<String> jsonStrDs = env.addSource(kafkaSource);
//3.对数据进行json转换
SingleOutputStreamOperator<JSONObject> jsonObjDs = jsonStrDs.map(jsonObj -> JSON.parseObject(jsonObj));
//4.ETL, table不为空,data不为空,data长度不能小于3
SingleOutputStreamOperator<JSONObject> filterDs = jsonObjDs.filter(jsonObject -> jsonObject.getString("table") != null
&& jsonObject.getJSONObject("data") != null
&& jsonObject.getString("data").length() > 3);
filterDs.print("json str --->>");
try {
env.execute("base db task");
} catch (Exception e) {
e.printStackTrace();
}
}
}3. 动态分流
由于MaxWell是把全部数据统一写入一个Topic中, 这样显然不利于日后的数据处理。所以需要把各个表拆开处理。但是由于每个表有不同的特点,有些表是维度表,有些表是事实表,有的表既是事实表在某种情况下也是维度表。
在实时计算中一般把维度数据写入存储容器,一般是方便通过主键查询的数据库比如HBase,Redis,MySQL 等。一般把事实数据写入流中,进行进一步处理,最终形成宽表。但是作为 Flink 实时计算任务,如何得知哪些表是维度表,哪些是事实表呢?而这些表又应该采集哪些字段呢?
我们可以将上面的内容放到某一个地方,集中配置。这样的配置不适合写在配置文件中,因为业务端随着需求变化每增加一张表,就要修改配置重启计算程序。所以这里需要一种动态配置方案,把这种配置长期保存起来,一旦配置有变化,实时计算可以自动感知。
这种可以有两个方案实现
一种是用 Zookeeper 存储,通过 Watch 感知数据变化。
另一种是用 mysql 数据库存储,周期性的同步或使用flink-cdc实时同步。
这里选择第二种方案,周期性同步,flink-cdc方式可自行尝试,主要是 mysql 对于配置数据初始化和维护管理,用 sql 都比较方便,虽然周期性操作时效性差一点,但是配置变化并不频繁。
所以就有了如下图:

业务数据保存到Kafka 的主题中,维度数据保存到Hbase 的表中。
4. mysql配置
① 在 gmall-realtime 模块添加依赖
<!--lomback 插件依赖-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.12</version>
<scope>provided</scope>
</dependency>
<!--commons-beanutils 是 Apache 开源组织提供的用于操作 JAVA BEAN 的工具包。
使用 commons-beanutils,我们可以很方便的对 bean 对象的属性进行操作-->
<dependency>
<groupId>commons-beanutils</groupId>
<artifactId>commons-beanutils</artifactId>
<version>1.9.3</version>
</dependency>
<!--Guava 工程包含了若干被 Google 的 Java 项目广泛依赖的核心库,方便开发-->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>29.0-jre</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>② 单独创建数据库gmall2021_realtime
create database gmall2021_realtime;
CREATE TABLE `table_process` (
`source_table` varchar(200) NOT NULL COMMENT '来源表',
`operate_type` varchar(200) NOT NULL COMMENT '操作类型 insert,update,delete',
`sink_type` varchar(200) DEFAULT NULL COMMENT '输出类型 hbase kafka',
`sink_table` varchar(200) DEFAULT NULL COMMENT '输出表(主题)',
`sink_columns` varchar(2000) DEFAULT NULL COMMENT '输出字段',
`sink_pk` varchar(200) DEFAULT NULL COMMENT '主键字段',
`sink_extend` varchar(200) DEFAULT NULL COMMENT '建表扩展',
PRIMARY KEY (`source_table`,`operate_type`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;③ 创建实体类
package com.zhangbao.gmall.realtime.bean;
import lombok.Data;
/**
* @author: zhangbao
* @date: 2021/8/22 13:06
* @desc:
**/
@Data
public class TableProcess {
//动态分流 Sink 常量 改为小写和脚本一致
public static final String SINK_TYPE_HBASE = "hbase";
public static final String SINK_TYPE_KAFKA = "kafka";
public static final String SINK_TYPE_CK = "clickhouse";
//来源表
private String sourceTable;
//操作类型 insert,update,delete
private String operateType;
//输出类型 hbase kafka
private String sinkType;
//输出表(主题)
private String sinkTable;
//输出字段
private String sinkColumns;
//主键字段
private String sinkPk;
//建表扩展
private String sinkExtend;
}④ mysql工具类
package com.zhangbao.gmall.realtime.utils;
import com.google.common.base.CaseFormat;
import com.zhangbao.gmall.realtime.bean.TableProcess;
import org.apache.commons.beanutils.BeanUtils;
import org.apache.commons.lang.reflect.FieldUtils;
import java.sql.*;
import java.util.ArrayList;
import java.util.List;
/**
* @author: zhangbao
* @date: 2021/8/22 13:09
* @desc:
**/
public class MysqlUtil {
private static final String DRIVER_NAME = "com.mysql.jdbc.Driver";
private static final String URL = "jdbc:mysql://192.168.88.71:3306/gmall2021_realtime?characterEncoding=utf-8&useSSL=false&serverTimezone=GMT%2B8";
private static final String USER_NAME = "root";
private static final String USER_PWD = "123456";
public static void main(String[] args) {
String sql = "select * from table_process";
List<TableProcess> list = getList(sql, TableProcess.class, true);
for (TableProcess tableProcess : list) {
System.out.println(tableProcess.toString());
}
}
public static <T> List<T> getList(String sql,Class<T> clz, boolean under){
Connection conn = null;
PreparedStatement ps = null;
ResultSet rs = null;
try {
Class.forName(DRIVER_NAME);
conn = DriverManager.getConnection(URL, USER_NAME, USER_PWD);
ps = conn.prepareStatement(sql);
rs = ps.executeQuery();
List<T> resultList = new ArrayList<>();
ResultSetMetaData metaData = rs.getMetaData();
int columnCount = metaData.getColumnCount();
while (rs.next()){
System.out.println(rs.getObject(1));
T obj = clz.newInstance();
for (int i = 1; i <= columnCount; i++) {
String columnName = metaData.getColumnName(i);
String propertyName = "";
if(under){
//指定数据库字段转换为驼峰命名法,guava工具类
propertyName = CaseFormat.LOWER_UNDERSCORE.to(CaseFormat.LOWER_CAMEL,columnName);
}
//通过guava工具类设置属性值
BeanUtils.setProperty(obj,propertyName,rs.getObject(i));
}
resultList.add(obj);
}
return resultList;
} catch (Exception throwables) {
throwables.printStackTrace();
new RuntimeException("msql 查询失败!");
} finally {
if(rs!=null){
try {
rs.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
if(ps!=null){
try {
ps.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
if(conn!=null){
try {
conn.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
}
return null;
}
}5. 程序分流
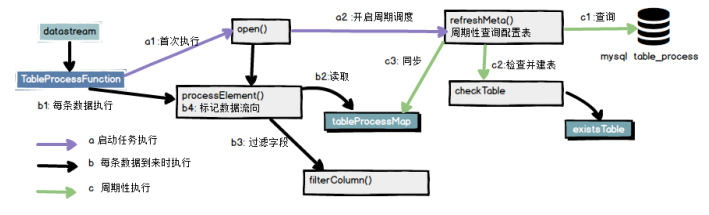
如图定义一个mapFunction函数
1.在open方法中初始化配置信息,并周期开启一个任务刷新配置
2.在任务中根据配置创建数据表
3.分流
主任务流程
package com.zhangbao.gmall.realtime.app.dwd;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.zhangbao.gmall.realtime.app.func.TableProcessFunction;
import com.zhangbao.gmall.realtime.bean.TableProcess;
import com.zhangbao.gmall.realtime.utils.MyKafkaUtil;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.LocalStreamEnvironment;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.OutputTag;
/**
* 从kafka读取业务数据
* @author: zhangbao
* @date: 2021/8/15 21:10
* @desc:
**/
public class BaseDbTask {
public static void main(String[] args) {
//1.获取flink环境
LocalStreamEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
//设置并行度
env.setParallelism(4);
//设置检查点
env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(60000);
env.setStateBackend(new FsStateBackend("hdfs://hadoop101:9000/gmall/flink/checkpoint/baseDbApp"));
//指定哪个用户读取hdfs文件
System.setProperty("HADOOP_USER_NAME","zhangbao");
//2.从kafka获取topic数据
String topic = "ods_base_db_m";
String group = "base_db_app_group";
FlinkKafkaConsumer<String> kafkaSource = MyKafkaUtil.getKafkaSource(topic, group);
DataStreamSource<String> jsonStrDs = env.addSource(kafkaSource);
//3.对数据进行json转换
SingleOutputStreamOperator<JSONObject> jsonObjDs = jsonStrDs.map(jsonObj -> JSON.parseObject(jsonObj));
//4.ETL, table不为空,data不为空,data长度不能小于3
SingleOutputStreamOperator<JSONObject> filterDs = jsonObjDs.filter(jsonObject -> jsonObject.getString("table") != null
&& jsonObject.getJSONObject("data") != null
&& jsonObject.getString("data").length() > 3);
//5.动态分流,事实表写会kafka,维度表写入hbase
OutputTag<JSONObject> hbaseTag = new OutputTag<JSONObject>(TableProcess.SINK_TYPE_HBASE){};
//创建自定义mapFunction函数
SingleOutputStreamOperator<JSONObject> kafkaTag = filterDs.process(new TableProcessFunction(hbaseTag));
DataStream<JSONObject> hbaseDs = kafkaTag.getSideOutput(hbaseTag);
filterDs.print("json str --->>");
try {
env.execute("base db task");
} catch (Exception e) {
e.printStackTrace();
}
}
}创建TableProcessFunction自定义任务
这里包括上面说的四个步骤
初始化并周期读取配置数据
执行每条数据
过滤字段
标记数据流向,根据配置写入对应去向,维度数据就写入hbase,事实数据就写入kafka
package com.zhangbao.gmall.realtime.app.func;
import com.alibaba.fastjson.JSONObject;
import com.zhangbao.gmall.realtime.bean.TableProcess;
import com.zhangbao.gmall.realtime.common.GmallConfig;
import com.zhangbao.gmall.realtime.utils.MysqlUtil;
import lombok.extern.log4j.Log4j2;
import org.apache.commons.lang3.StringUtils;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.*;
/**
* @author: zhangbao
* @date: 2021/8/26 23:24
* @desc:
**/
@Log4j2(topic = "gmall-logger")
public class TableProcessFunction extends ProcessFunction<JSONObject,JSONObject> {
//定义输出流标记
private OutputTag<JSONObject> outputTag;
//定义配置信息
private Map<String , TableProcess> tableProcessMap = new HashMap<>();
//在内存中存放已经创建的表
Set<String> existsTable = new HashSet<>();
//phoenix连接对象
Connection con = null;
public TableProcessFunction(OutputTag<JSONObject> outputTag) {
this.outputTag = outputTag;
}
//只执行一次
@Override
public void open(Configuration parameters) throws Exception {
//初始化配置信息
log.info("查询配置表信息");
//创建phoenix连接
Class.forName("org.apache.phoenix.jdbc.PhoenixDriver");
con = DriverManager.getConnection(GmallConfig.PHOENIX_SERVER);
refreshDate();
//启动一个定时器,每隔一段时间重新获取配置信息
//delay:延迟5000执行,每隔5000执行一次
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run() {
refreshDate();
}
},5000,5000);
}
//每进来一个元素,执行一次
@Override
public void processElement(JSONObject jsonObj, Context context, Collector<JSONObject> collector) throws Exception {
//获取表的修改记录
String table = jsonObj.getString("table");
String type = jsonObj.getString("type");
JSONObject data = jsonObj.getJSONObject("data");
if(type.equals("bootstrap-insert")){
//maxwell更新历史数据时,type类型是bootstrap-insert
type = "insert";
jsonObj.put("type",type);
}
if(tableProcessMap != null && tableProcessMap.size()>0){
String key = table + ":" + type;
TableProcess tableProcess = tableProcessMap.get(key);
if(tableProcess!=null){
//数据发送到何处,如果是维度表,就发送到hbase,如果是事实表,就发送到kafka
String sinkType = tableProcess.getSinkType();
jsonObj.put("sink_type",sinkType);
String sinkColumns = tableProcess.getSinkColumns();
//过滤掉不要的数据列,sinkColumns是需要的列
filterColumns(data,sinkColumns);
}else {
log.info("no key {} for mysql",key);
}
if(tableProcess!=null && tableProcess.getSinkType().equals(TableProcess.SINK_TYPE_HBASE)){
//根据sinkType判断,如果是维度表就分流,发送到hbase
context.output(outputTag,jsonObj);
}else if(tableProcess!=null && tableProcess.getSinkType().equals(TableProcess.SINK_TYPE_KAFKA)){
//根据sinkType判断,如果是事实表就发送主流,发送到kafka
collector.collect(jsonObj);
}
}
}
//过滤掉不要的数据列,sinkColumns是需要的列
private void filterColumns(JSONObject data, String sinkColumns) {
String[] cols = sinkColumns.split(",");
//转成list集合,用于判断是否包含需要的列
List<String> columnList = Arrays.asList(cols);
Set<Map.Entry<String, Object>> entries = data.entrySet();
Iterator<Map.Entry<String, Object>> iterator = entries.iterator();
while (iterator.hasNext()){
Map.Entry<String, Object> next = iterator.next();
String key = next.getKey();
//如果不包含就删除不需要的列
if(!columnList.contains(key)){
iterator.remove();
}
}
}
//读取配置信息,并创建表
private void refreshDate() {
List<TableProcess> processList = MysqlUtil.getList("select * from table_process", TableProcess.class, true);
for (TableProcess tableProcess : processList) {
String sourceTable = tableProcess.getSourceTable();
String operateType = tableProcess.getOperateType();
String sinkType = tableProcess.getSinkType();
String sinkTable = tableProcess.getSinkTable();
String sinkColumns = tableProcess.getSinkColumns();
String sinkPk = tableProcess.getSinkPk();
String sinkExtend = tableProcess.getSinkExtend();
String key = sourceTable+":"+operateType;
tableProcessMap.put(key,tableProcess);
//在phoenix创建表
if(TableProcess.SINK_TYPE_HBASE.equals(sinkType) && operateType.equals("insert")){
boolean noExist = existsTable.add(sinkTable);//true则表示没有创建表
if(noExist){
createTable(sinkTable,sinkColumns,sinkPk,sinkExtend);
}
}
}
}
//在phoenix中创建表
private void createTable(String table, String columns, String pk, String ext) {
if(StringUtils.isBlank(pk)){
pk = "id";
}
if(StringUtils.isBlank(ext)){
ext = "";
}
StringBuilder sql = new StringBuilder("create table if not exists " + GmallConfig.HBASE_SCHEMA + "." + table +"(");
String[] split = columns.split(",");
for (int i = 0; i < split.length; i++) {
String field = split[i];
if(pk.equals(field)){
sql.append(field + " varchar primary key ");
}else {
sql.append("info." + field +" varchar ");
}
if(i < split.length-1){
sql.append(",");
}
}
sql.append(")").append(ext);
//创建phoenix表
PreparedStatement ps = null;
try {
log.info("创建phoenix表sql - >{}",sql.toString());
ps = con.prepareStatement(sql.toString());
ps.execute();
} catch (SQLException throwables) {
throwables.printStackTrace();
}finally {
if(ps!=null){
try {
ps.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
throw new RuntimeException("创建phoenix表失败");
}
}
}
if(tableProcessMap == null || tableProcessMap.size()==0){
throw new RuntimeException("没有从配置表中读取配置信息");
}
}
}6. 重启策略
flink程序在运行时,有错误会抛出异常,程序就停止了,但当开始checkpoint检查点时,flink重启策略就是开启的,如果程序出现异常了,程序就会一直重启,并且重启次数是Integer.maxValue,这个过程也看不到错误信息,是很不友好的。
flink可以设置重启策略,所以在我们开启checkpoint检查点时,设置不需要重启就可以看到错误信息了:
env.setRestartStrategy(RestartStrategies.noRestart());
下面我们测试一下。
package com.zhangbao.gmall.realtime.app.dwd;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.zhangbao.gmall.realtime.app.func.TableProcessFunction;
import com.zhangbao.gmall.realtime.bean.TableProcess;
import com.zhangbao.gmall.realtime.utils.MyKafkaUtil;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.runtime.executiongraph.restart.RestartStrategy;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.LocalStreamEnvironment;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.OutputTag;
/**
* 从kafka读取业务数据
* @author: zhangbao
* @date: 2021/8/15 21:10
* @desc:
**/
public class Test {
public static void main(String[] args) {
//1.获取flink环境
LocalStreamEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
//设置并行度
env.setParallelism(4);
//设置检查点
env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(60000);
env.setStateBackend(new FsStateBackend("hdfs://hadoop101:9000/gmall/flink/checkpoint/baseDbApp"));
//指定哪个用户读取hdfs文件
System.setProperty("HADOOP_USER_NAME","zhangbao");
//flink重启策略,
// 如果开启上面的checkpoint,重启策略就是自动重启,程序有问题不会有报错,
// 如果没有开启checkpoint,就不会自动重启,所以这里设置不需要重启,就可以查看错误信息
env.setRestartStrategy(RestartStrategies.noRestart());
//2.从kafka获取topic数据
String topic = "ods_base_db_m";
String group = "test_group";
FlinkKafkaConsumer<String> kafkaSource = MyKafkaUtil.getKafkaSource(topic, group);
DataStreamSource<String> jsonStrDs = env.addSource(kafkaSource);
jsonStrDs.print("转换前-->");
//3.对数据进行json转换
SingleOutputStreamOperator<JSONObject> jsonObjDs = jsonStrDs.map(jsonObj ->{
System.out.println(4/0);
JSONObject jsonObject = JSON.parseObject(jsonObj);
return jsonObject;
});
jsonObjDs.print("转换后-->");
try {
env.execute("base db task");
} catch (Exception e) {
e.printStackTrace();
}
}
}在程序对数据进行转换过程中,我们加了 System.out.println(4/0); 这样一行代码,肯定会抛出异常的。
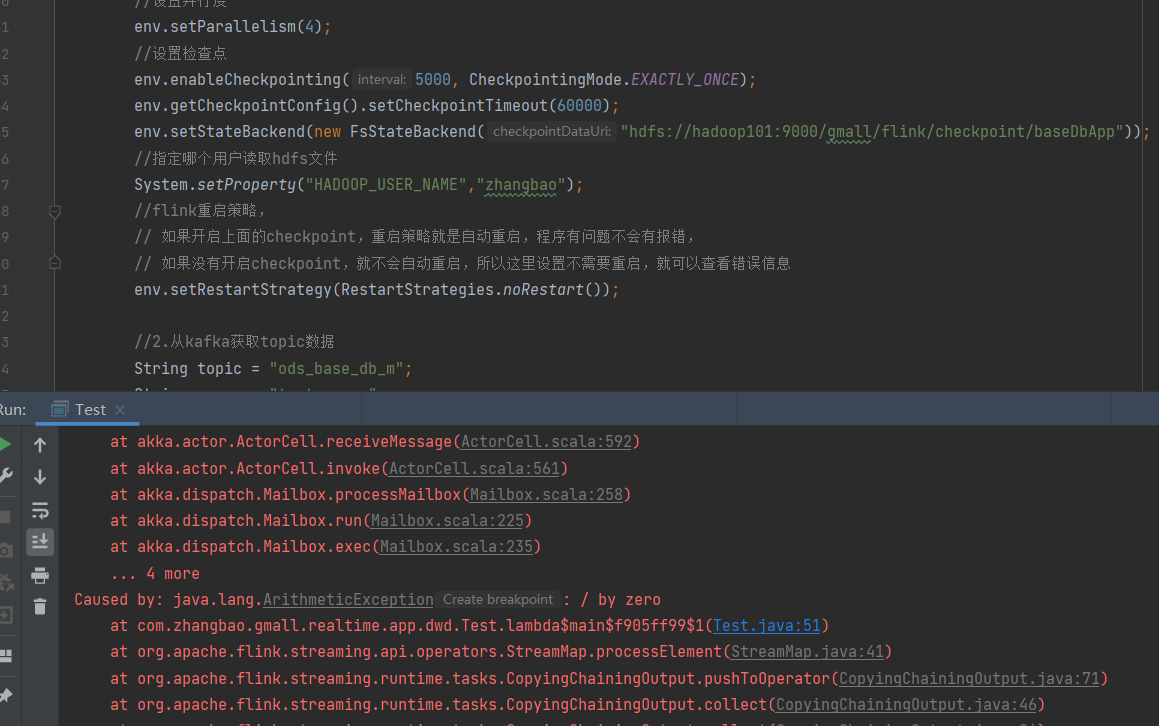
在设置不需要重启后,就可以看到错误信息了,当你把设置不需要重启一行代码注释掉,就会发现程序是一直在运行中的,并且没有任何错误信息。
在实际应用中,根据需要可以自行设置。
5.Flink实时项目之业务数据准备的更多相关文章
- 6.Flink实时项目之业务数据分流
在上一篇文章中,我们已经获取到了业务数据的输出流,分别是dim层维度数据的输出流,及dwd层事实数据的输出流,接下来我们要做的就是把这些输出流分别再流向对应的数据介质中,dim层流向hbase中,dw ...
- 10.Flink实时项目之订单维度表关联
1. 维度查询 在上一篇中,我们已经把订单和订单明细表join完,本文将关联订单的其他维度数据,维度关联实际上就是在流中查询存储在 hbase 中的数据表.但是即使通过主键的方式查询,hbase 速度 ...
- 3.Flink实时项目之流程分析及环境搭建
1. 流程分析 前面已经将日志数据(ods_base_log)及业务数据(ods_base_db_m)发送到kafka,作为ods层,接下来要做的就是通过flink消费kafka 的ods数据,进行简 ...
- 7.Flink实时项目之独立访客开发
1.架构说明 在上6节当中,我们已经完成了从ods层到dwd层的转换,包括日志数据和业务数据,下面我们开始做dwm层的任务. DWM 层主要服务 DWS,因为部分需求直接从 DWD 层到DWS 层中间 ...
- 4.Flink实时项目之数据拆分
1. 摘要 我们前面采集的日志数据已经保存到 Kafka 中,作为日志数据的 ODS 层,从 kafka 的ODS 层读取的日志数据分为 3 类, 页面日志.启动日志和曝光日志.这三类数据虽然都是用户 ...
- 1.Flink实时项目前期准备
1.日志生成项目 日志生成机器:hadoop101 jar包:mock-log-0.0.1-SNAPSHOT.jar gmall_mock |----mock_common |----mock ...
- 9.Flink实时项目之订单宽表
1.需求分析 订单是统计分析的重要的对象,围绕订单有很多的维度统计需求,比如用户.地区.商品.品类.品牌等等.为了之后统计计算更加方便,减少大表之间的关联,所以在实时计算过程中将围绕订单的相关数据整合 ...
- 11.Flink实时项目之支付宽表
支付宽表 支付宽表的目的,最主要的原因是支付表没有到订单明细,支付金额没有细分到商品上, 没有办法统计商品级的支付状况. 所以本次宽表的核心就是要把支付表的信息与订单明细关联上. 解决方案有两个 一个 ...
- 8.Flink实时项目之CEP计算访客跳出
1.访客跳出明细介绍 首先要识别哪些是跳出行为,要把这些跳出的访客最后一个访问的页面识别出来.那么就要抓住几个特征: 该页面是用户近期访问的第一个页面,这个可以通过该页面是否有上一个页面(last_p ...
随机推荐
- ssh到localhost或127.0.0.1拒绝连接
通过ssh连接到本机报错 ssh: connect to host localhost port 22: Connection refused, 你能用ssh登录其它主机并不代表着本地有ssh服务,要 ...
- VM搭建Hadoop环境静态IP未起作用
原文 https://www.toutiao.com/i6481452558941438478/ 问题描述 1.环境工具 VMware_workstation_full_12.5.2 CentOS-7 ...
- vue 图片拖拽和滚轮缩放
这里注意如果自己的页面有滚动条,一定阻止滚动事件的默认行为,否则缩放图片的时候,页面会跟着滚动@mousewheel.prevent 阻止默认行为 <div ref="imgWrap& ...
- 第3届云原生技术实践峰会(CNBPS 2020)重磅开启,“原”力蓄势待发!
CNBPS 2020将在11月19-21日全新启动!作为国内最有影响力的云原生盛会之一,云原生技术实践峰会(CNBPS)至今已举办三届. 在2019年的CNBPS上,灵雀云CTO陈恺喊出"云 ...
- 机器学习术语表——Beta
机器学习术语表 Beta 提示:你可以通过中文名称拼音首字母快速检索. C 超参数|Hyperparameter 在机器学习中,超参数是在开始学习过程之前设置值的参数,而不是通过训练得到的参数数据.通 ...
- 【Java】GUI实现贪吃蛇
[Java]GUI实现贪吃蛇 前言 我们在做这个小游戏之前,得确保自己的AWT和Swing有一定的基础,并且会写一些简单的逻辑操作.这些都会在后面写的时候体现出来. 狂神老师从这里开始讲贪吃蛇的 我们 ...
- jQuery ajax get与post后台交互中的奥秘
这两天在做关注功能模块(类似于Instagram).多处页面都需要通过一个"关注"按钮进行关注或者取消该好友的操作.一个页面对应的放一个按钮,进行操作.效率低维护性差.因此想通过j ...
- gin源码解读1-net/http的大概流程
gin框架预览 router.Run()的源码: func (engine *Engine) Run(addr ...string) (err error) { defer func() { debu ...
- k8s基本概念,资源对象
kubernetes里的master指的是集群控制节点 master负责是整个集群的管理和控制 kubernetes3大进程 API server 增删改查操作的关键入口 controller man ...
- Python 单元测试 生产HTML测试报告
使用HTMLTestRunnerNew模块,生成单元测试的html报告,报告标题根据对应测试时间. import unittest from datetime import datetime from ...