基于python的pixiv爬虫
基于python的pixiv爬虫
1、目标
在和朋友吹逼过程中,聊到qq群机器人,突发奇想动手做一个p站每日推荐色图的色图机,遂学习爬虫。
目标:
- 批量下载首页推荐色图。
- 由于对qq机器人不熟,先利用flask搭键一个网页色图机。
2、流程
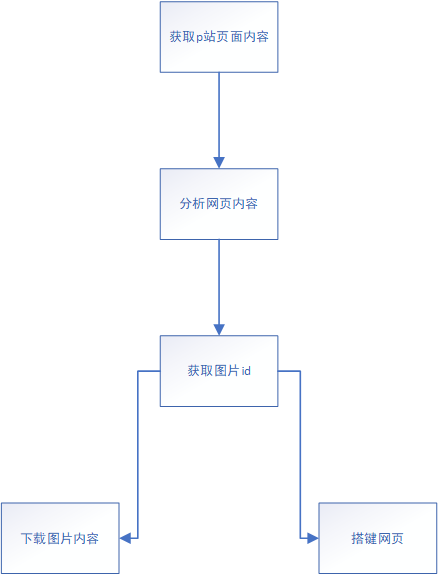
3、批量下载
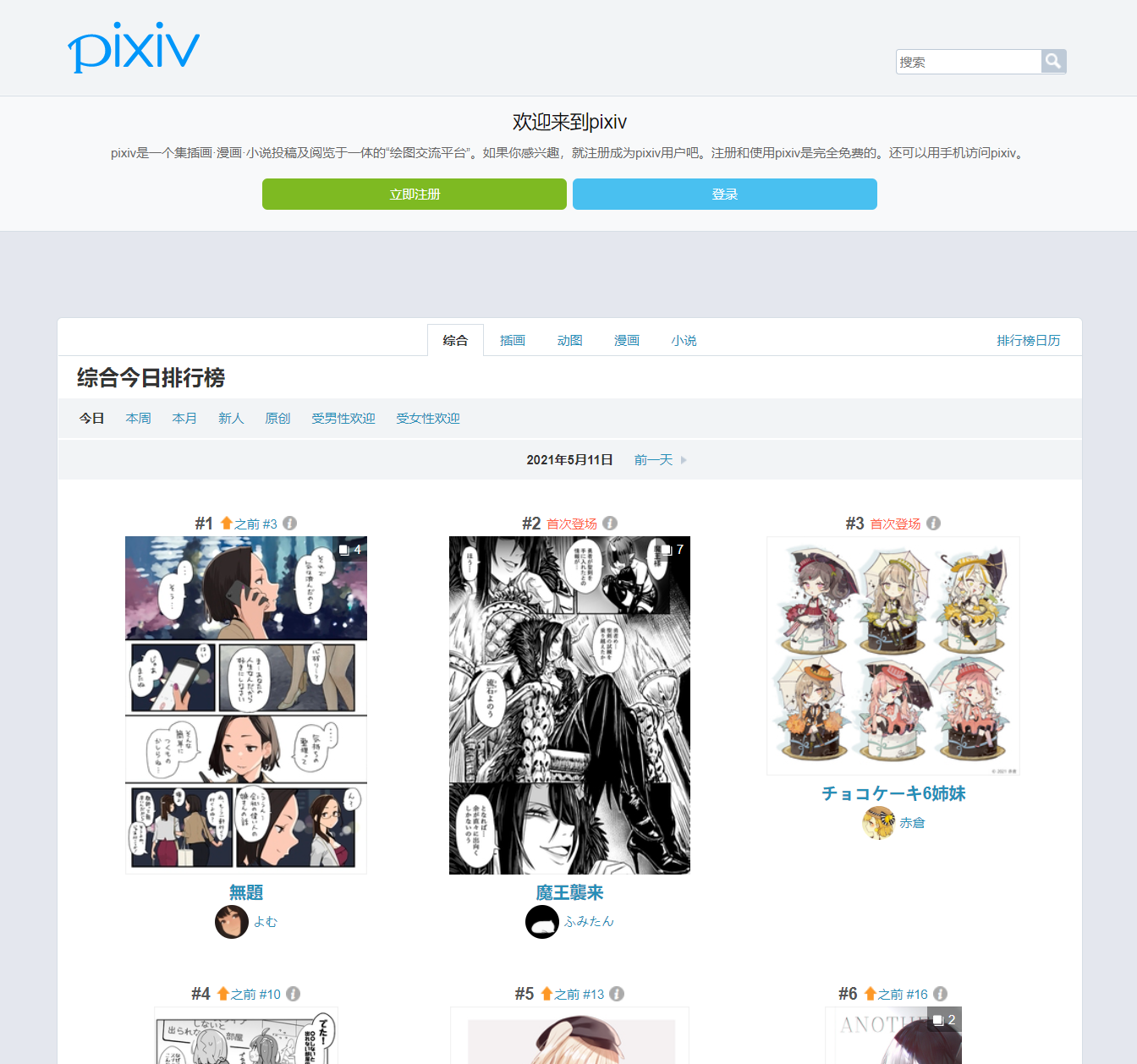
1、分析网页
虽然直接进入pixiv的主页是需要登录的,但是进入排行榜却不需要这个过程。
通过网页源代码定位到图片id
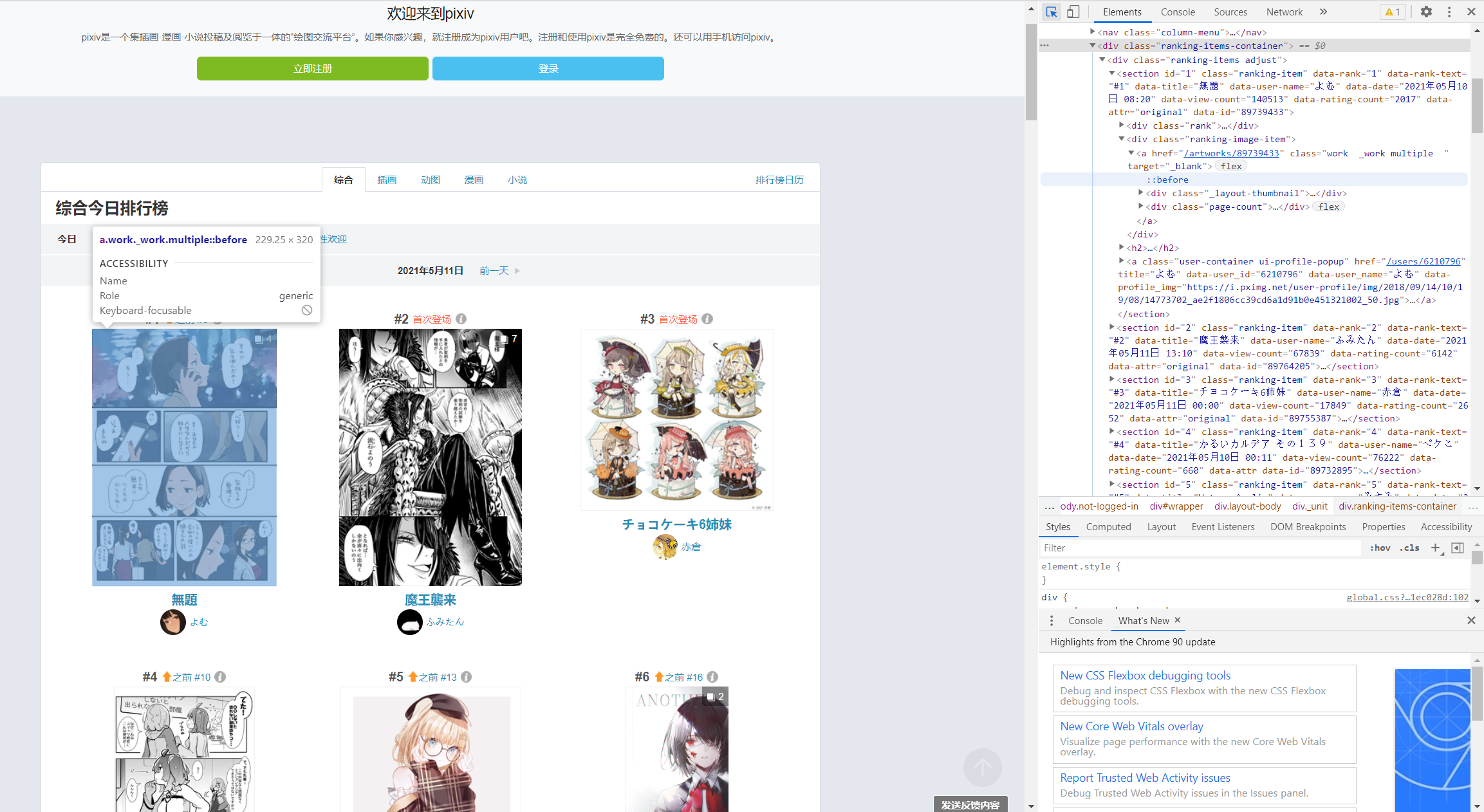
<section id="1" class="ranking-item" data-rank="1" data-rank-text="#1" data-title="無題" data-user-name="よむ" data-date="2021年05月10日 08:20" data-view-count="140513" data-rating-count="2017" data-attr="original" data-id="89739433"><div class="rank"><h1><a href="#1" class="label ui-scroll" data-hash-link="true">#1</a><i class="up sprites-up"></i></h1><p><a href="ranking.php?mode=daily&date=20210510&p=1&ref=rn-b-1-yesterday-3#3" target="_blank">之前 #3</a></p><i class="_icon sprites-info open-info ui-modal-trigger"></i></div><div class="ranking-image-item"><a href="/artworks/89739433" class="work _work multiple " target="_blank"><div class="_layout-thumbnail"><img src="https://i.pximg.net/c/240x480/img-master/img/2021/05/10/08/20/13/89739433_p0_master1200.jpg" alt="" class="_thumbnail ui-scroll-view" data-filter="thumbnail-filter lazy-image" data-src="https://i.pximg.net/c/240x480/img-master/img/2021/05/10/08/20/13/89739433_p0_master1200.jpg" data-type="illust" data-id="89739433" data-tags="がんばれ同期ちゃん 予定調和 マニキュア オリジナル7500users入り 知ってる" data-user-id="6210796" style="opacity: 1;"></div><div class="page-count"><div class="icon"></div><span>4</span></div></a></div><h2><a href="/artworks/89739433" class="title" target="_blank" rel="noopener">無題</a></h2><a class="user-container ui-profile-popup" href="/users/6210796" title="よむ" data-user_id="6210796" data-user_name="よむ" data-profile_img="https://i.pximg.net/user-profile/img/2018/09/14/10/19/08/14773702_ae2f1806cc39cd6a1d91b0e451321002_50.jpg"><div class="_user-icon size-32 cover-texture ui-scroll-view" data-filter="lazy-image" data-src="https://i.pximg.net/user-profile/img/2018/09/14/10/19/08/14773702_ae2f1806cc39cd6a1d91b0e451321002_50.jpg" style="background-image: url("https://i.pximg.net/user-profile/img/2018/09/14/10/19/08/14773702_ae2f1806cc39cd6a1d91b0e451321002_50.jpg");"></div><span class="user-name">よむ</span></a></section>
可以看到这张图片的详细信息
data-rank="1" #排名为第一
data-user-name="よむ" #作者名为よむ
data-id="89739433" #图片id为89739433
还有一个重要信息,是我在后期进行下载和引用时才发现的
class="page-count"><div class="icon"></div><span>4</span></div>
因为排行榜上的并非都是单张插画,也有此类多张的漫画,给爬虫工作增加了许多困难。
2、分析动态页面
在分析了这个页面所有的内容后,发现在主页面,只显示了至多50张图片的信息,但其实每日排行的图片远远不止这个数量,但是pixiv并非像豆瓣或者bangumi拥有静态的目录,而且采取动态加载的方法,一直往下滑,则页面一直加载。
滑了半天,得知每日图片推荐一共有500张图片
对于动态页面,采取抓包查看每次动态加载的具体内容。
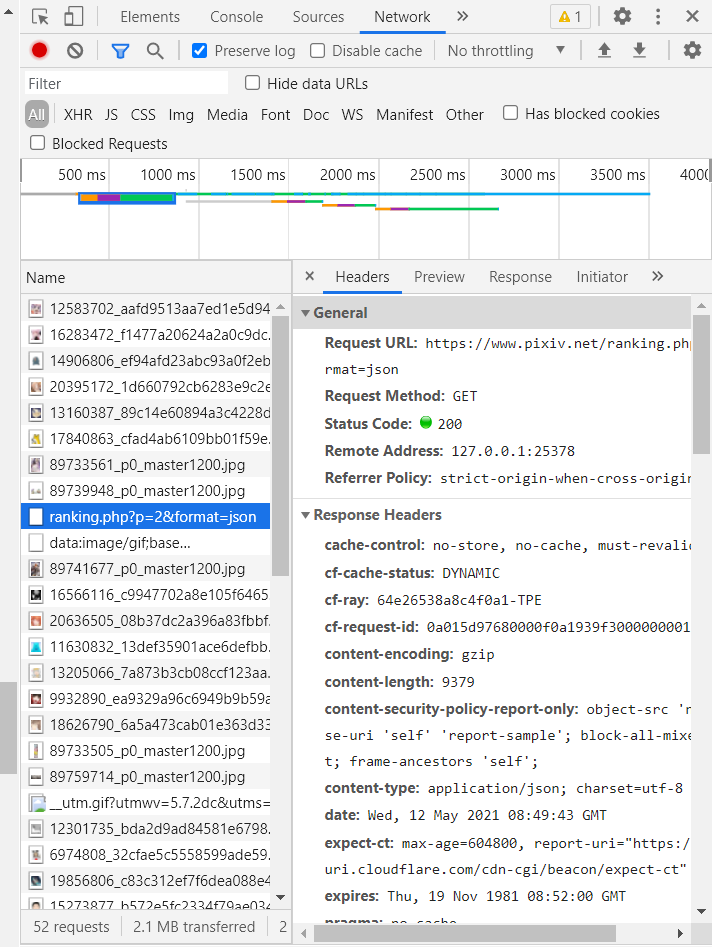
除了不停加载的图片信息,抓到一条请求
https://www.pixiv.net/ranking.php?p=2&format=json
查看这个页面

显然,这是排行榜第二页的内容,将p=2改为p=1,同样显示了第一页的内容,也就是说,每次发送请求,则返回50张图片的信息,发送十次请求,则可以获得500张照片的信息,那么接下来的工作就简单了。
3、热门图片信息获取
抓取的网页并非html标准格式的,不能也没必要用bs4进行内容分析,直接用正则表达式即可。
先用request请求获取十个页面,并且打印出来看下是否正确。
import requests
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36',
'referer': 'https://www.pixiv.net/ranking.php?mode=daily&content=illust',
}
for i in range(1, 11):
url = 'https://www.pixiv.net/ranking.php?p=%d&format=json' % i
res = requests.get(url, headers=headers)
print(res.text)
打印结果太多了,和上图浏览器中结果相同,就不做展示,正确的打印了十次请求获取的数据。
下面通过正则表达式获取每次请求中我们需要的内容,并打印查看
import re
id = re.findall('"illust_id":(\d+)', res.text)
for i in id:
print(i)
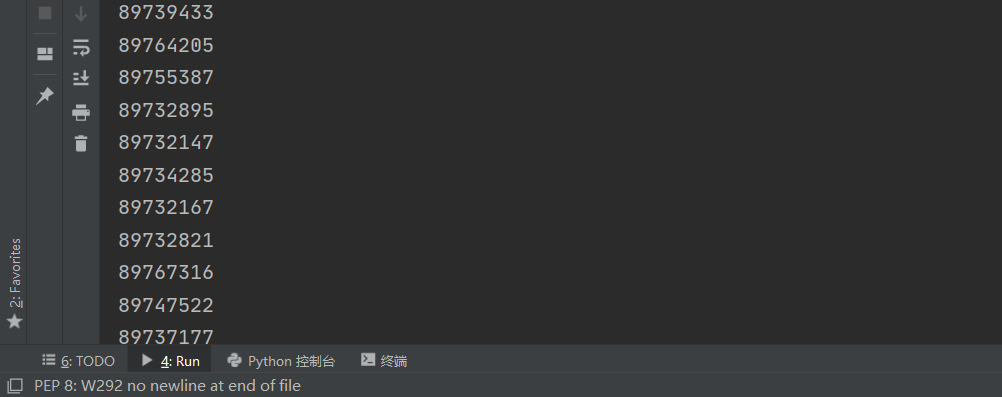
图片id就哗啦啦地出来了,检查打印下len(id)每组都为50个,一切无误。
同时,也将每一组图片的张数进行获取,方便之后的显示、下载。
count = re.findall('"illust_page_count":"(\d+)"', res.text)
4、图片下载
拿到了排行榜图片的id、张数,下一步是对其进行下载。
能否进行下载一直是我很担心的一个难点,因为有的图片尺度过大,在未登录时是无法直接进行访问的。

先进入一张普通图片的页面,寻找图片下载的地址
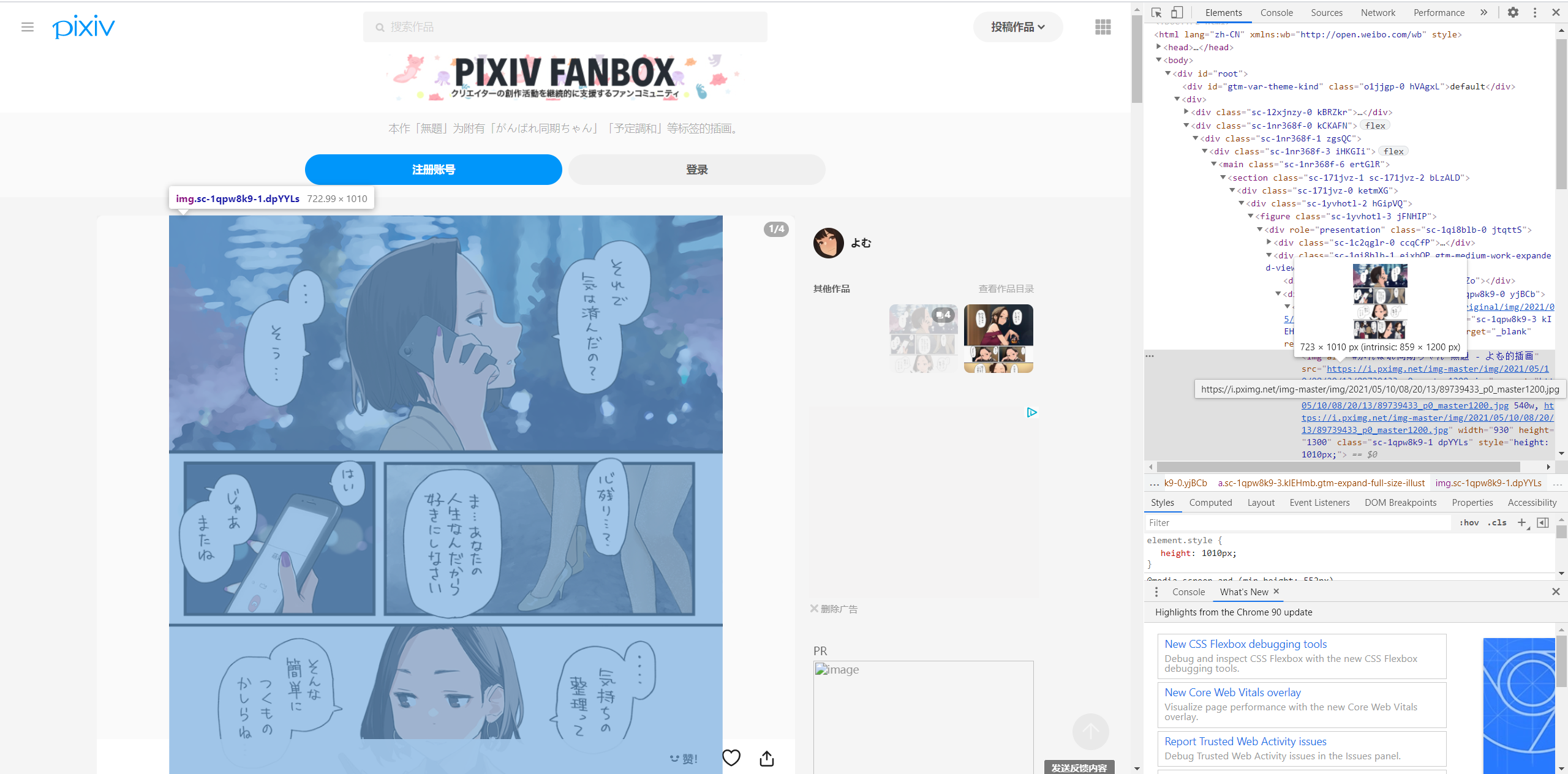
<div role="presentation" class="sc-1qpw8k9-0 yjBCb"><a href="https://i.pximg.net/img-original/img/2021/05/10/08/20/13/89739433_p0.png" class="sc-1qpw8k9-3 kIEHmb gtm-expand-full-size-illust" target="_blank" rel="noopener"><img alt="#がんばれ同期ちゃん 無題 - よむ的插画" src="https://i.pximg.net/img-master/img/2021/05/10/08/20/13/89739433_p0_master1200.jpg"
拿到图片下载的地址。
注意到,这个标签的role的值为presentation,之后如果使用bs4进行查找,则可以轻松获得下载地址。
url = 'https://www.pixiv.net/artworks/89739433'
res = requests.get(url, headers=headers)
with open('test.txt','wb') as f :
f.write(res.text.encode('utf8'))
通过requests访问一下试试
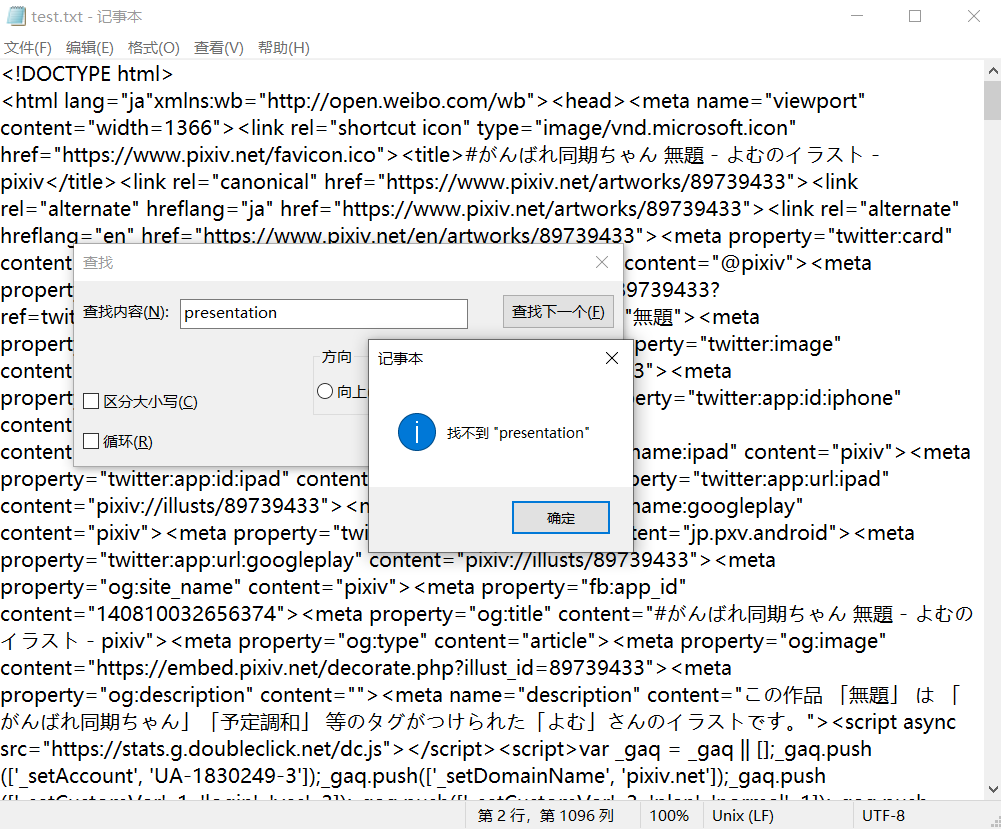
然而,离谱的事情就出现了,那就是通过浏览器直接访问的内容和爬虫访问的内容是不一样的。不过还好,就算不一样,仍然可以拿到链接。
在txt文件中搜索https://i.pximg.net/img-original,找到了
"original":"https://i.pximg.net/img-original/img/2021/05/10/08/20/13/89739433_p0.png"}
通过正则,便可获取到这个下载地址
result = re.findall(r'"original":"(.+?)"',res.text)
在下载图片时,需要给图片命名,分为文件名和后缀名,全部通过正则提取。
pic_name = re.findall(r'"illustTitle":"(.+?)"', res.text)[0]
extension = re.findall(r'....$', pic_url)[0]
下载图片时,我用最简单的方法,将原始的url的末尾删除,for循环改变p的值,拼接上文件后缀名,从而达到下载一组多张图片的功能
pic_url = re.sub('.....$','',pic_url)
# 下载图片
for i in range(0,int(count)):
url = pic_url+str(i)+extension
print(url)
pic = requests.get(url, headers=headers)
with open('%s%d%s' % (pic_name, i, extension), 'wb') as f:
f.write(pic.content)
最后,将之前所有的代码整合,构造一个函数,输入图片id和图片张数,自动下载。
def download(id, count):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36',
'referer': 'https://www.pixiv.net/ranking.php?mode=daily&content=illust',
}
url = 'https://www.pixiv.net/artworks/%d' % id
res = requests.get(url, headers=headers)
pic_url = re.findall(r'"original":"(.+?)"', res.text)[0]
pic_name = re.findall(r'"illustTitle":"(.+?)"', res.text)[0]
# 获取后缀
extension = re.findall(r'....$', pic_url)[0]
pic_url = re.sub('.....$','',pic_url)
# 下载图片
for i in range(0,int(count)):
url = pic_url+str(i)+extension
print(url)
pic = requests.get(url, headers=headers)
with open('%s%d%s'% (pic_name, i, extension), 'wb') as f:
f.write(pic.content)
5、debug
获取到了图片的id和张数,并且构造了输入id和张数就能自动执行脚本的函数,将两者稍作整合,结果在运行时报错:
OSError: [Errno 22] Invalid argument: './ex/電車で寄りかかられたOLと寄りかかってきた居眠り(?)JK1.jpg'
显然,文件命名不能包含'?',于是添加正则去除这些符号
if re.search('[\\\ \/ \* \? \" \: \< \> \|]', pic_name) != None:
pic_name = re.sub('[\\\ \/ \* \? \" \: \< \> \|]', '', pic_name)
之后运行正常
6、总代码
#-*— codeing = utf-8 -*-
import requests
import re
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36',
'referer': 'https://www.pixiv.net/ranking.php?mode=daily&content=illust',
}
def download(id, count):
url = 'https://www.pixiv.net/artworks/%d' % id
res = requests.get(url, headers=headers)
pic_url = re.findall(r'"original":"(.+?)"', res.text)[0]
pic_name = re.findall(r'"illustTitle":"(.+?)"', res.text)[0]
# 获取后缀
extension = re.findall(r'....$', pic_url)[0]
pic_url = re.sub('.....$','',pic_url)
if re.search('[\\\ \/ \* \? \" \: \< \> \|]', pic_name) != None:
pic_name = re.sub('[\\\ \/ \* \? \" \: \< \> \|]', '', pic_name)
# 下载图片
for i in range(0,int(count)):
url = pic_url+str(i)+extension
print('正在下载id为:%d的第%d张图片'%(id,i+1),end=' ')
pic = requests.get(url, headers=headers)
with open('./ex/%s%d%s' % (pic_name, i+1, extension), 'wb') as f:
f.write(pic.content)
print('下载成功', end='\n')
def bot():
id = []
count = []
for i in range(1, 2):
url = 'https://www.pixiv.net/ranking.php?p=%d&format=json' % i
res = requests.get(url, headers=headers)
id = id + re.findall('"illust_id":(\d+)', res.text)
count = count + re.findall('"illust_page_count":"(\d+)"', res.text)
if len(id) == len(count):
for i in range(0,len(id)):
download(int(id[i]),int(count[i]))
bot()
4、网页搭键
1、思路
如果要将所有图片下载至服务器,且不说我使用的阿里云无法访问p站,占用空间、下载花费时间,都是问题。而p站的图片的下载地址链接并没有办法直接显示图片,固选择第三方代理来实现在网页中显示p站图片的功能。
使用的代理网站是
pixiv.cat
虽然在国内直接访问速度也并不理想,但是可以直接通过链接在网页中显示图片。
重新写一个爬虫,功能是把所有每日推荐图片的id存到一个txt文件中,方便我们在服务器上直接调用。值得注意的是,如果这组图片不止一张,就在图片id后加一个'-1',这样代理网站才能正常工作(代理网站规则请自行前往查看)
2、爬虫代码
for i in range(1, 11):
url = 'https://www.pixiv.net/ranking.php?p=%d&format=json' % i
res = requests.get(url, headers=headers)
illust_id = re.findall('"illust_id":(\d+?),', res.text)
illust_page_count = re.findall('"illust_page_count":"(\d+?)"', res.text)
len_ = len(illust_id)
i = 0
if len_ != 0:
while i < len_:
with open('id.txt','a') as f:
if illust_page_count[i] == '1':
f.write(illust_id[i])
f.write('\n')
else :
f.write(illust_id[i])
f.write('-1')
f.write('\n')
i = i+1
else:
pass
3、flask代码
from flask import Flask,render_template
import random
app = Flask(__name__)
list_ = []
with open('id.txt')as id_list:
for line in id_list:
line = line.strip('\n')
list_.append(line)
len = len(list_)
ran = list_[random.randint(1,len)]
@app.route('/')
def index():
ran = list_[random.randint(1, len)]
return render_template("index.html",pic=ran)
if __name__ == '__main__':
app.run(app.run(host='0.0.0.0', port=8001, debug=True))
大致思路是读取txt文件,随机取得一张图片的id,并传递给前端
4、前端代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>色图机</title>
<html lang="en">
<head>
<meta charset="UTF-8">
</head>
<script>
function handle() {
document.getElementById('myImage').src='https://pixiv.cat/'+'{{ pic }}'+'.jpg';
}
</script>
<body >
<h1 style="text-align: center;">色图机</h1>
<div style="text-align: center;">
<img height="500" id= "myImage" src='https://pixiv.cat/{{ pic }}.jpg'/>
</div>
<h2 style="text-align: center;">p站id为:{{pic}}</h2>
<h2 style="text-align: center;">刷新页面以刷新色图</h2>
<footer style="text-align: center;">
图片来源为pixiv每日推荐,本网站仅做学习,图片内容与本人无关
<br>power by huigugu
<br>To dear じじ
</footer>
</body>
</html>
</head>
</html>
5、总结
- 对于基础的爬虫,难点在分析网页内容。
- 通过浏览器访问到的和通过爬虫访问到的不尽相同。
- 看色图久了会感觉枯燥无味。
6、参考资料
- b站爬虫教学视频 http://www.bilibili.com/video/BV12E411A7ZQ
- CSDN相似爬虫项目(在其基础上解决了一组多张图片的问题) https://blog.csdn.net/weixin_45826022/article/details/109406389
基于python的pixiv爬虫的更多相关文章
- 2019基于python的网络爬虫系列,爬取糗事百科
**因为糗事百科的URL改变,正则表达式也发生了改变,导致了网上许多的代码不能使用,所以写下了这一篇博客,希望对大家有所帮助,谢谢!** 废话不多说,直接上代码. 为了方便提取数据,我用的是beaut ...
- 基于Python,scrapy,redis的分布式爬虫实现框架
原文 http://www.xgezhang.com/python_scrapy_redis_crawler.html 爬虫技术,无论是在学术领域,还是在工程领域,都扮演者非常重要的角色.相比于其他 ...
- 基于python的知乎开源爬虫 zhihu_oauth使用介绍
今天在无意之中发现了一个知乎的开源爬虫,是基于Python的,名字叫zhihu_oauth,看了一下在github上面star数还挺多的,貌似文档也挺详细的,于是就稍微研究了一下.发现果然很好用啊.就 ...
- python 全栈开发,Day140(RabbitMQ,基于scrapy-redis实现分布式爬虫)
一.RabbitMQ 队列 在生产者消费模型中,比如去餐馆吃饭的例子.生产者相当于厨师,队列相当于服务员,消费者就是你. 我们必须通过服务员,才能吃饭! 如果队列满了,队列会一直hold住.必须让消费 ...
- 基于Python使用scrapy-redis框架实现分布式爬虫
1.首先介绍一下:scrapy-redis框架 scrapy-redis:一个三方的基于redis的分布式爬虫框架,配合scrapy使用,让爬虫具有了分布式爬取的功能.github地址: https: ...
- 基于python的爬虫项目
一.项目简介 1.1 项目博客地址 https://www.cnblogs.com/xsfa/p/12083913.html 1.2 项目完成的功能与特色 爬虫和拥有三个可视化数据分析 1.3 项目采 ...
- 基于python的知乎开源爬虫 zhihu
今天在无意之中发现了一个知乎的开源爬虫,是基于Python的,名字叫zhihu_oauth,看了一下在github上面star数还挺多的,貌似文档也挺详细的,于是就稍微研究了一下.发现果然很好用啊.就 ...
- 基于python爬虫的github-exploitdb漏洞库监控与下载
基于python爬虫的github-exploitdb漏洞库监控与下载 offensive.py(爬取项目历史更新内容) #!/usr/bin/env python # -*- coding:utf- ...
- 一个基于Scrapy框架的pixiv爬虫
源码 https://github.com/vicety/Pixiv-Crawler,功能什么的都在这里介绍了 说几个重要的部分吧 登录部分 困扰我最久的部分,网上找的其他pixiv爬虫的登录方式大多 ...
随机推荐
- ffmpeg 常用知识点收集
ffmpeg 常用知识点收集 一.基础简介 FFmpeg是一个自由软件,可以运行音频和视频多种格式的录影.转换.流功能,包含了libavcodec ─这是一个用于多个项目中音频和视频的解码器库,以及l ...
- Python中的reduce()函数
reduce()函数也是Python内置的一个高阶函数.reduce()函数接收的参数和 map()类似,一个函数 f,一个list,但行为和 map()不同,reduce()传入的函数 f 必须接收 ...
- python操作图片
时间:2018-11-30 记录:byzqy 标题:python实现图片操作 地址:https://blog.csdn.net/baidu_34045013/article/details/79187 ...
- centos7 ftp 拒绝连接
2021-09-03 1. 问题描述 刚才在重新搭建 ftp 服务器时,发现 ftp 拒绝连接,想起来我还没启动 vsftpd 服务,尝试启动却无法启动 vsftpd 服务 2. 解决方法 使用命令 ...
- leaflet加载离线OSM(OpenStreetMap)
本文为博主原创,如需转载需要署名出处. leaflet作为广为应用的开源地图操作的API,是非常受欢迎,轻量级的代码让使用者更容易操作. 废话不多说,下面直接给出范例. 首先在这个网站下载leafle ...
- Linux(一)——简介
aaa https://www.cnblogs.com/three-fighter/p/14644152.html#navigator
- centos7安装privoxy
本文分为三部分,第一部分是在阿里云的ECS上安装Privoxy,第二部分是在AWS的EC2上安装Privoxy,第三部分是Privoxy的配置. 第一部分:阿里云ECS安装Privoxy 配置yum源 ...
- Vs code自动生成Doxygen格式注释
前言 程序中注释的规范和统一性的重要性不言而喻,本文就推荐一种在用vscode编写代码时自动化生成标准化注释格式的方法,关于Doxygen规范及其使用可查看博文 代码注释规范之Doxygen. ...
- 图像处理之Canny边缘检测(一)
一:历史 Canny边缘检测算法是1986年有John F. Canny开发出来一种基于图像梯度计算的边缘 检测算法,同时Canny本人对计算图像边缘提取学科的发展也是做出了很多的贡献.尽 管至今已经 ...
- VSCode一些设置
//每次保存后自动格式化 "editor.formatOnSave": true, // #每次保存的时候将代码按eslint格式进行修复 "editor.codeAct ...