Pytorch_Part7_模型使用
VisualPytorch beta发布了!
功能概述:通过可视化拖拽网络层方式搭建模型,可选择不同数据集、损失函数、优化器生成可运行pytorch代码
扩展功能:1. 模型搭建支持模块的嵌套;2. 模型市场中能共享及克隆模型;3. 模型推理助你直观的感受神经网络在语义分割、目标探测上的威力;4.添加图像增强、快速入门、参数弹窗等辅助性功能
修复缺陷:1.大幅改进UI界面,提升用户体验;2.修改注销不跳转、图片丢失等已知缺陷;3.实现双服务器访问,缓解访问压力
访问地址:http://sunie.top:9000
发布声明详见:https://www.cnblogs.com/NAG2020/p/13030602.html
共同贡献PyTorch常见错误与坑汇总文档:《PyTorch常见报错/坑汇总》
一、模型保存与加载
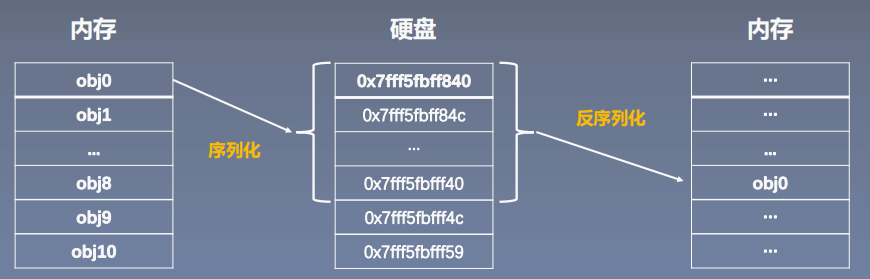
1. 序列化与反序列化
net = LeNet2(classes=2019)
# 法1: 保存整个Module,不仅保存参数,也保存结构
torch.save(net, path)
net_load = torch.load(path_model) # 网络名称、结构、模型参数、优化器参数均保留
# 法2: 保存模型参数(推荐,占用资源少)
state_dict = net.state_dict()
torch.save(state_dict , path)
net_new = LeNet2(classes=2019)
net_new.load_state_dict(state_dict_load)
2. 断点续训练
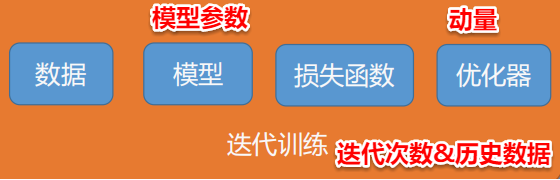
保存:
checkpoint = {
"model_state_dict": net.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),
"epoch": epoch
}
path_checkpoint = "./checkpoint_{}_epoch.pkl".format(epoch)
torch.save(checkpoint, path_checkpoint)
恢复:
# ============================ step 2/5 模型 ============================
net = LeNet(classes=2)
net.initialize_weights()
# ============================ step 3/5 损失函数 ============================
criterion = nn.CrossEntropyLoss() # 选择损失函数
# ============================ step 4/5 优化器 ============================
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9) # 选择优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=6, gamma=0.1) # 设置学习率下降策略
# ============================ step 5+/5 断点恢复 ============================
path_checkpoint = "./checkpoint_4_epoch.pkl"
checkpoint = torch.load(path_checkpoint)
net.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
scheduler.last_epoch = checkpoint['epoch']
二、模型微调(Finetune)
1. Transfer Learning
机器学习分支,研究源域(source domain)的知识如何应用到目标域(target domain)
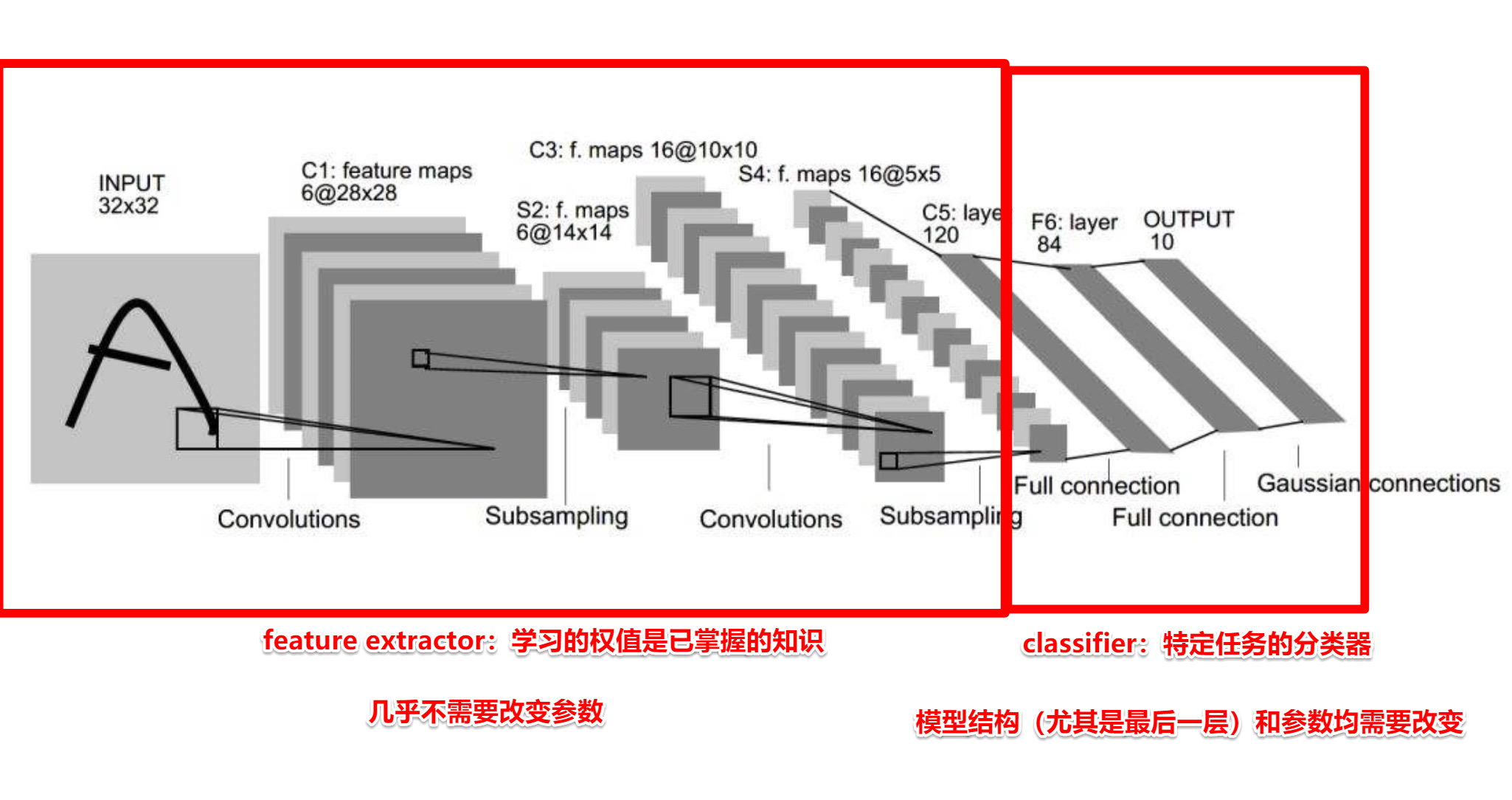
模型微调步骤:
- 获取预训练模型参数
- 加载模型(load_state_dict)
- 修改输出层
模型微调训练方法:
- 固定预训练的参数(requires_grad =False;lr=0)
- Features Extractor较小学习率(params_group)[推荐使用,更加灵活]
3. 将resnet18迁移
到蚂蚁-蜜蜂二分类任务,其中有114张训练,80张测试。可以看出来训练数据还是相当小的,必须有已经训练好的模型。
模型搭建如下:
# ============================ step 2/5 模型 ============================
# 1/3 构建模型
resnet18_ft = models.resnet18()
# 2/3 加载参数 !!!
path_pretrained_model = "resnet18-5c106cde.pth"
state_dict_load = torch.load(path_pretrained_model)
resnet18_ft.load_state_dict(state_dict_load)
# 法1 : 冻结卷积层,模型参数不再更新
for param in resnet18_ft.parameters():
param.requires_grad = False
# 3/3 替换fc层,将原本输出神经元个数改为 classes = 2 !!!
num_ftrs = resnet18_ft.fc.in_features
resnet18_ft.fc = nn.Linear(num_ftrs, classes)
如果不加载参数,训练了25个epoch仍只有70%正确率,最后Loss保持在0.5左右。而如果加载了参数,基本上第二个epoch就达到90%正确率。
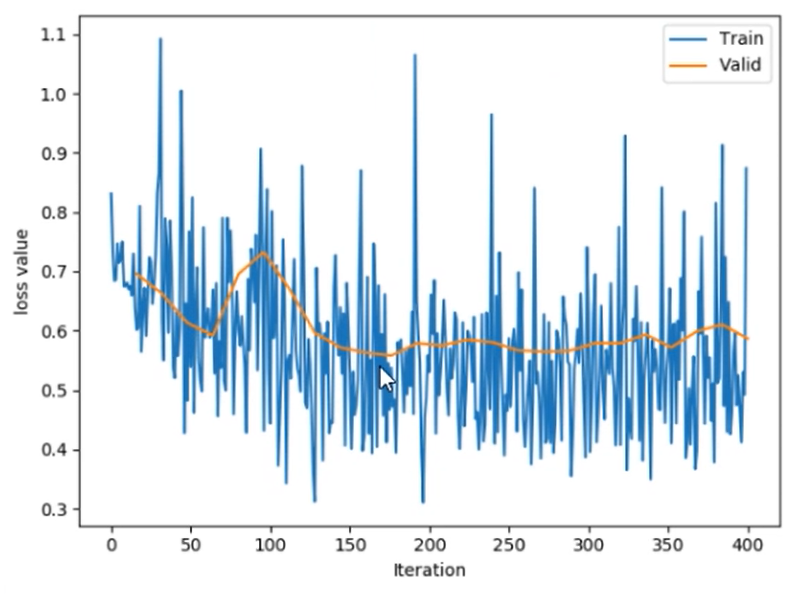
更推荐的用优化器控制学习率方法:分组灵活控制LR
# ============================ step 4/5 优化器 ============================
# 法2 : conv 小学习率
fc_params_id = list(map(id, resnet18_ft.fc.parameters())) # 返回的是parameters的 内存地址
base_params = filter(lambda p: id(p) not in fc_params_id, resnet18_ft.parameters())
optimizer = optim.SGD([
{'params': base_params, 'lr': LR*0.1}, # 0
{'params': resnet18_ft.fc.parameters(), 'lr': LR}], momentum=0.9)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=lr_decay_step, gamma=0.1) # 设置学习率下降策略
三、GPU的使用
CPU(Central Processing Unit, 中央处理器):主要包括控制器和运算器
GPU(Graphics Processing Unit, 图形处理器):处理统一的,无依赖的大规模数据运算
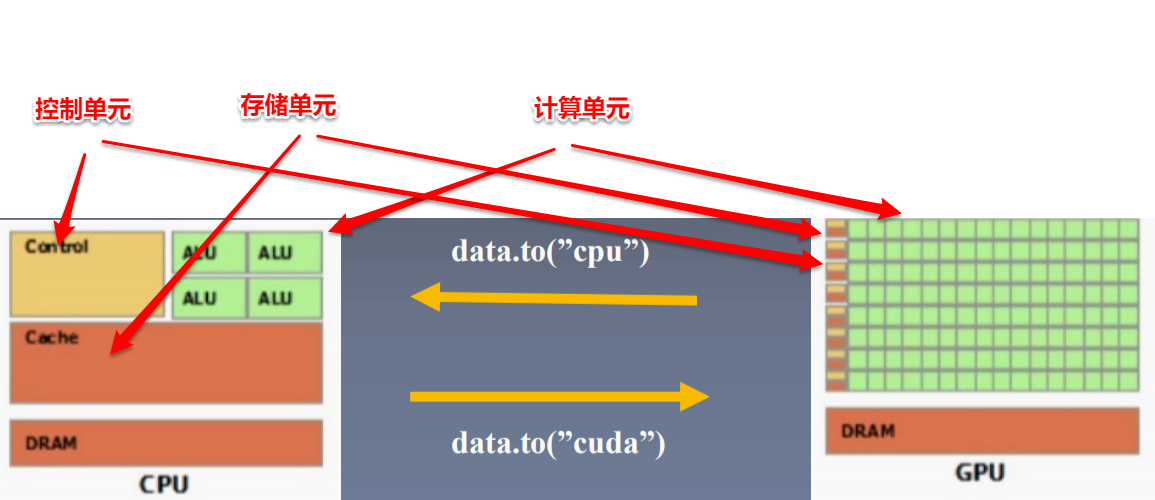
在模型训练/测试时必须使所有数据和模型参数都在同一类设备上,并且注意数据的to操作不是inplace操作。
经过实验,上面resnet18的迁移学习中,如果不采用GPU训练一个epoch耗时58.362s,而使用了GPU后仅需要6.626s!
1. to函数:转换数据类型/设备
- tensor.to(*args, **kwargs)
- module.to(*args, **kwargs)
区别:张量不执行inplace,模型执行inplace
x = torch.ones((3, 3))
x = x.to(torch.float64) # 数据类型
x = torch.ones((3, 3))
x = x.to("cuda") # 数据设备
linear = nn.Linear(2, 2)
linear.to(torch.double) # 模型数据类型,不改变存储位置
gpu1 = torch.device("cuda")
linear.to(gpu1) # 模型设备,不改变存储位置
2. torch.cuda常用方法
- torch.cuda.device_count():计算当前可见可用gpu数
- torch.cuda.get_device_name():获取gpu名称
- torch.cuda.manual_seed():为当前gpu设置随机种子
- torch.cuda.manual_seed_all():为所有可见可用gpu设置随机种子
- torch.cuda.set_device():设置主gpu为哪一个物理gpu(不推荐)
推荐: os.environ.setdefault("CUDA_VISIBLE_DEVICES", "2, 3")
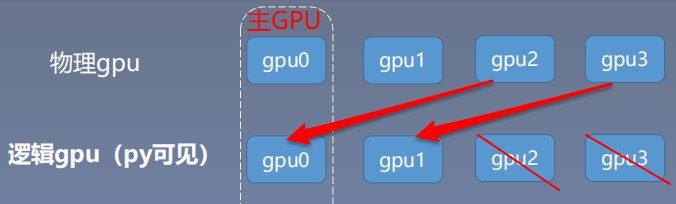
3. 多gpu运算的分发并行机制
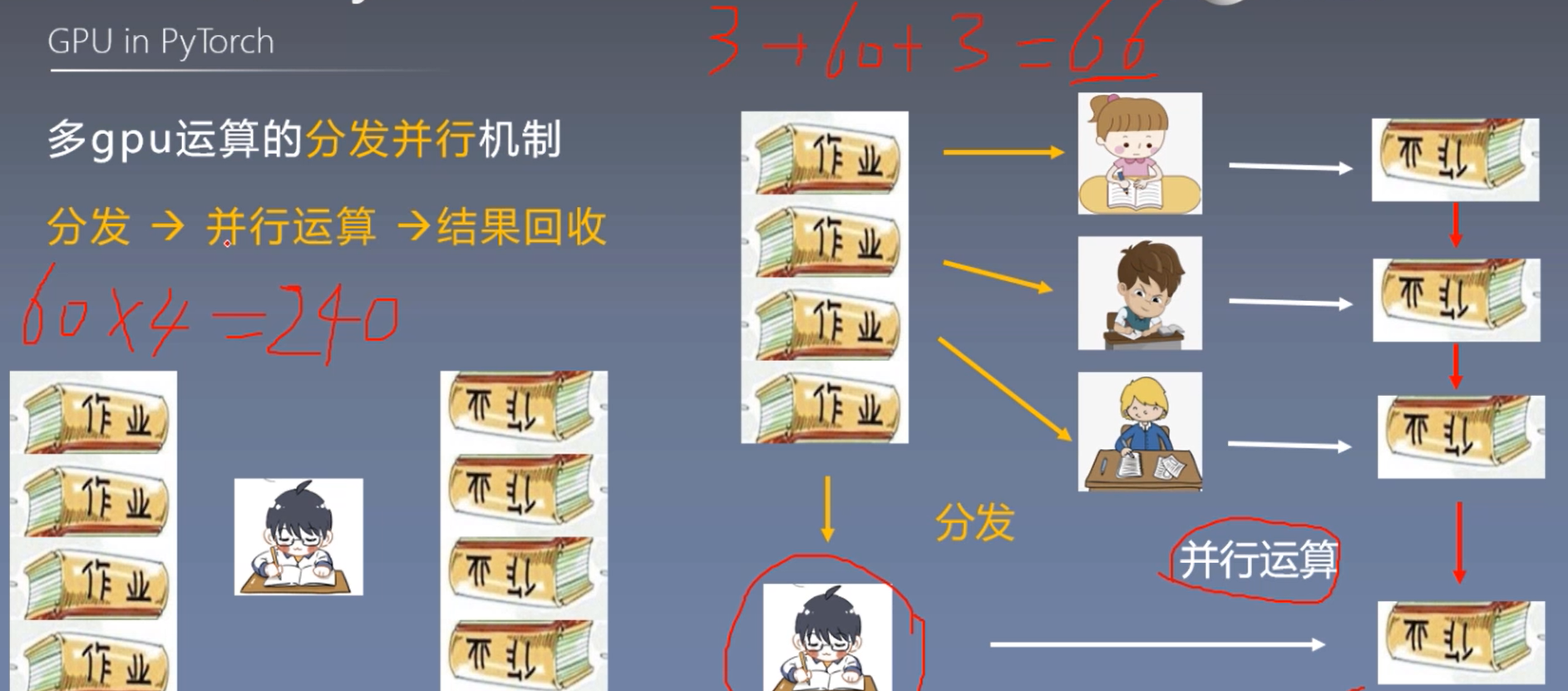
torch.nn.DataParallel(module, # 需要包装分发的模型
device_ids=None, # 可分发的gpu,默认分发到所有可见可用gpu
output_device=None, # 结果输出设备
dim=0
)
功能:包装模型,实现分发并行机制
查询当前gpu内存剩余:
def get_gpu_memory():
import os
os.system('nvidia-smi -q -d Memory | grep -A4 GPU | grep Free > tmp.txt')
memory_gpu = [int(x.split()[2]) for x in open('tmp.txt', 'r').readlines()]
os.system('rm tmp.txt')
return memory_gpu
gpu_memory = get_gpu_memory()
gpu_list = np.argsort(gpu_memory)[::-1]
gpu_list_str = ','.join(map(str, gpu_list))
os.environ.setdefault("CUDA_VISIBLE_DEVICES", gpu_list_str)
print("\ngpu free memory: {}".format(gpu_memory))
print("CUDA_VISIBLE_DEVICES :{}".format(os.environ["CUDA_VISIBLE_DEVICES"]))
>>> gpu free memory: [10362, 10058, 9990, 9990]
>>> CUDA_VISIBLE_DEVICES :0,1,3,2
gpu模型加载:
在没有GPU的机器上运行GPU代码:
RuntimeError: Attempting to deserialize object on a CUDA device but torch.cuda.is_available() is False...
解决:
torch.load(path_state_dict, map_location="cpu")在单GPU机器上加载多GPU训练模型参数(在参数key中会含有
module.)RuntimeError: Error(s) in loading state_dict for FooNet: Missing key(s) in state_dict: "linears.0.weight", "linears.1.weight", "linears.2.weight". Unexpected key(s) in state_dict: "module.linears.0.weight", "module.linears.1.weight", "module.linears.2.weight".
解决:
from collections import OrderedDict
new_state_dict = OrderedDict()
for k, v in state_dict_load.items ():
namekey = k[7:] if k.startswith('module.') else k
new_state_dict[namekey] =v
Pytorch_Part7_模型使用的更多相关文章
- ASP.NET MVC with Entity Framework and CSS一书翻译系列文章之第二章:利用模型类创建视图、控制器和数据库
在这一章中,我们将直接进入项目,并且为产品和分类添加一些基本的模型类.我们将在Entity Framework的代码优先模式下,利用这些模型类创建一个数据库.我们还将学习如何在代码中创建数据库上下文类 ...
- ASP.NET Core MVC/WebAPi 模型绑定探索
前言 相信一直关注我的园友都知道,我写的博文都没有特别枯燥理论性的东西,主要是当每开启一门新的技术之旅时,刚开始就直接去看底层实现原理,第一会感觉索然无味,第二也不明白到底为何要这样做,所以只有当你用 ...
- ASP.NET路由模型解析
大家好,我又来吹牛逼了 ~-_-~ 转载请注明出处:来自吹牛逼之<ASP.NET路由模型解析> 背景:很多人知道Asp.Net中路由怎么用的,却不知道路由模型内部的运行原理,今天我就给大家 ...
- 高性能IO模型浅析
高性能IO模型浅析 服务器端编程经常需要构造高性能的IO模型,常见的IO模型有四种: (1)同步阻塞IO(Blocking IO):即传统的IO模型. (2)同步非阻塞IO(Non-blocking ...
- 探索ASP.NET MVC5系列之~~~4.模型篇---包含模型常用特性和过度提交防御
其实任何资料里面的任何知识点都无所谓,都是不重要的,重要的是学习方法,自行摸索的过程(不妥之处欢迎指正) 汇总:http://www.cnblogs.com/dunitian/p/4822808.ht ...
- 隐马尔科夫模型python实现简单拼音输入法
在网上看到一篇关于隐马尔科夫模型的介绍,觉得简直不能再神奇,又在网上找到大神的一篇关于如何用隐马尔可夫模型实现中文拼音输入的博客,无奈大神没给可以运行的代码,只能纯手动网上找到了结巴分词的词库,根据此 ...
- webapi - 模型验证
本次要和大家分享的是webapi的模型验证,讲解的内容可能不单单是做验证,但都是围绕模型来说明的:首先来吐槽下,今天下午老板为自己买了套新办公家具,看起来挺好说明老板有钱,不好的是我们干技术的又成了搬 ...
- 谈谈一些有趣的CSS题目(二)-- 从条纹边框的实现谈盒子模型
开本系列,讨论一些有趣的 CSS 题目,抛开实用性而言,一些题目为了拓宽一下解决问题的思路,此外,涉及一些容易忽视的 CSS 细节. 解题不考虑兼容性,题目天马行空,想到什么说什么,如果解题中有你感觉 ...
- 【NLP】蓦然回首:谈谈学习模型的评估系列文章(一)
统计角度窥视模型概念 作者:白宁超 2016年7月18日17:18:43 摘要:写本文的初衷源于基于HMM模型序列标注的一个实验,实验完成之后,迫切想知道采用的序列标注模型的好坏,有哪些指标可以度量. ...
随机推荐
- POj1860(floyd+正权回路)
题目传送门 题意:有多种汇币,汇币之间可以交换,这需要手续费,当你用100A币交换B币时,A到B的汇率是29.75,手续费是0.39,那么你可以得到(100 - 0.39) * 29.75 = 296 ...
- 【安全研究】Domain fronting域名前置网络攻击技术
出品|MS08067实验室(www.ms08067.com) 千里百科 Domain Fronting基于HTTPS通用规避技术,也被称为域前端网络攻击技术.这是一种用来隐藏Metasploit,Co ...
- Android Studio 之 RadioButton
•任务 如何通过 RadioButton 实现如图所示的界面? •基本用法 RadioButton 单选按钮,就是只能够选中一个,所以我们需要把 RadioButton 放到 RadioGroup 按 ...
- 源码篇:Handler那些事
前言 Handler属于八股文中非常经典的一个考题了,导致这个知识点很多时候,考官都懒得问了:这玩意很久之前就看过,但是过了一段时间,就很容易忘记,但是处理内存泄漏,aidlHandler之类的考点答 ...
- Spring(一)简介和配置
知识补充: 那么什么是xmlns呢?xmlns其实是XML Namespace的缩写,可译为"XML命名空间",但个人觉得,翻译后的名字反而不好理解,所以我们就叫它为XML Nam ...
- joda-time的简单使用及mysql时间函数的使用(今天,本周,本月)
近期在做一些首页的统计数据复习了下mysql的时间函数,以及后续修改成 传入时间查询时使用的joda-time 软件简介 JodaTime 提供了一组Java类包用于处理包括ISO8601标准在内的d ...
- 网络编程Netty入门:责任链模式介绍
目录 责任链模式 责任链模式的简单实现 Netty中的ChannelPipeline责任链 服务端接收客户端连接 pipeline初始化 入站事件和出站事件 Pipeline中的Handler Pip ...
- 哈工大LTP基本使用-分词、词性标注、依存句法分析、命名实体识别、角色标注
代码 import os from pprint import pprint from pyltp import Segmentor, Postagger, Parser, NamedEntityRe ...
- 14.Quick QML-TextInput详解
1.TextInput属性用来编辑一行文本,对应QLineEdit,除了正常输入外,我们还可以设置echoMode属性改为密码显示状态,也可以通过validator属性和inputMask属性来设置验 ...
- Cobalt-Strike Office宏利用与免杀
1.打开Cobalt-Strike生产Office宏病毒. 首先需要设置监听器.因为钓鱼的目标比较单纯,在这里就不采用域前置技术. 然后使用攻击模块,生产Office宏病毒. 设置好监听器. 生成宏病 ...