Scrapy的流程
Scrapy框架的架构如下图
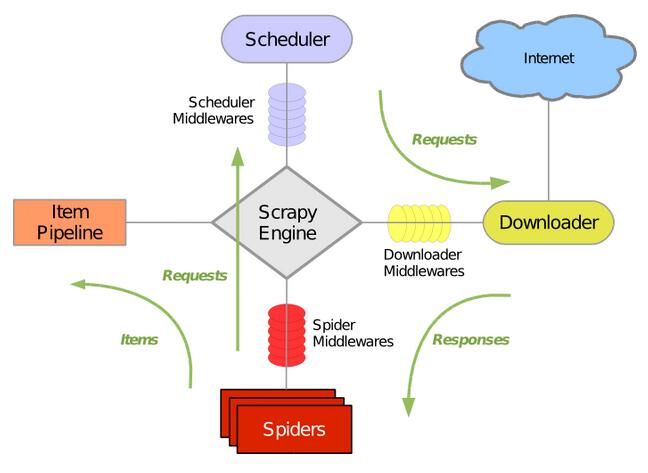
具体部分说明:
Engine:引擎,处理整个系统的数据流处理,出发事物,是整个框架的核心
Item:项目。定义了爬取结果的数据结构,爬取的数据会被赋值成该Item对象
Scheduler:调度器,接受引擎发过来的请求并将其加入队列中,在引擎再次请求的时候将请求提供给引擎
Downloader:下载器,下载网页的内容,并将网页的内容返回给蜘蛛
Spiders:蜘蛛,其内定义了爬去的逻辑和网页解析的规则,它主要负责解析响应并生成提取的结果和新的请求
Item Pipeline:项目管道,负责处理由蜘蛛从页面中抽取的项目,它主要的任务是清洗,验证和存储数据
Downloader Middlewares :下载器中间件,位于引擎和下载器之间的钩子框架,主要处理引擎与下载器之间的请求以及响应
Spider Middlewardes: 蜘蛛中间件,位于引擎和蜘蛛之间的钩子框架,主要处理蜘蛛的输入的响应和输出的结果及洗呢请求
数据流:
Scrapy的数据流由引擎控制,数据流的过程如下:
1.Engine首先打开一个网站,找到处理该网站的Spider,并向该网站的Spider请求的一个要爬取的URL
2.Engine从Spider中获取到第一个要爬取的URL,并通过Scheduler以Request的形式调度
3.Engine向Spider请求下一个要爬取的URL
4.Scheduler返回下个要爬取的URL给Engine,Engine将URL通过Downloader Middlewares转发个Downloader下载
5.一旦下载完毕,Downloader生成该页面的Response,并将其通过Downloader Middlewares发送给Engine
6.Engine从下载器中接收到Response,并将其通过Spider Middlewares发送给Spider处理
7.Spider处理Response,并返回取到的Item及新得Request返回给Engine
8.Engine将Spider返回的Item给Item Pipeline,将新得Request给Schedule
9.重复第2步到底8步,直到Schedule找那个没有更多的Request。Engine关闭网站,爬取结束
下面着重说一下Downloader Middlewares与Spider Middlewares
Downloader Middlewares
作用:
1.在Scheduler调出队列的Request发送给Downloader下载之前,也就是我们可以再Request执行下载之前对其进行修改
2.在下载后生成Response发送给Spider之前,也就是我们可以再生成Response被Spider解析之前对其进行修改
Downloader Middlewares的功能十分的强大,修改User-Agent,处理重定向、设置代理、失败重试、设置Cookies等功能都需要借助他来实现
核心方法:
1.process_request(request,spider) :Request被Scrapy引擎调度给Downloader之前,process_request()会被执行,方法返回的是None、Response对象、Request对象之一。参数:request是Request对象,即被处理的Request;spider,Spider对象,即此Request对应的Spider
2.process_response(request,response,spider) :Downloader执行Request下载之后,会得到对应的Response。Scrapy引擎便会将Response发送给Spider进行解析,返回值必须是Request对象、Response对象之一。参数:request,是Request对象,即此Response对应的Request;response:是response对象,即被处理的Response;spider:是Spider对象,即此被处理的Spider对象
3.process_exception(request,exception,spider):当Downloader或者process_requset()方法抛出异常时,此方法就会被调用。返回值必须是None,Response对象,Request对象之一。参数:request,是Request对象;exception,是Exception对象,即抛出的异常;spider,Spider对象,即此Request对应的Spider
Spider Middlewares
当Downloader生成Response之后,Response会被发送给Spider,在发送给Spider之前,Response会首先经过Spider Middlewares处理,当Spider生成处理后的Item和Request之后,Item和Request还会经过Spider MIddlewares处理
作用:
1.我们可以在Downloader生成Response发送给Spider之前,也就是Response发送给Spider之前对Response进行处理
2.我们可以在Spider生成Request发送给Scheduler之前,也就是在Request发送给Scheduler之前对Request进行处理
3.我们可以在Spider生成Item发送给Item Pipeline之前,也就是在Item发送给Scheduler之前对Item Pipeline进行处理
核心方法:
1.process_spider_input(reponse,spider):当Response被Spider Middlewares处理时,此方法会被调用;返回值是None或者是抛出一个异常
参数:response,是Response对象,即被处理的Response;spider,是Spider对象,即该Response对应的此Spider
2.process_spider_output(response,result,spider):当Spider处理Respon返回结果时,此方法会被调用;返回值必须是包含Request或Item的可迭代对象
参数:response,是Response对象,即被处理的Response;result,是包含Request或Item的可迭代对象;spider,是Spider对象,即该Response对应的此Spider
3.process_spider_exception(response,excsption,spider):当Spider或process_spider_input方法抛出异常时,此方法会执行;返回值为None或者包含Request或Item的可迭代对象; 参数:response,是Response对象,即被处理的Response;exception,是Exception对象,即抛出的异常;spider,Spider对象,即此Response对应的Spider
4.pricess_spider_requests(start_requests,spider):以Spider启动Request为参数时调用,执行过程类似于process_spider_output(),只不过没有相关联的Response,并且必须返回Request。 参数:start_requests,是包含Request的可迭代对象,即Start_Request;spider,Spider对象,即此Start_Request所属的Spider
未完待续。。。。。。。。
Scrapy的流程的更多相关文章
- scrapy 工作流程
Scrapy的整个数据处理流程由Scrapy引擎进行控制,其主要的运行方式为: 引擎打开一个域名,蜘蛛处理这个域名,然后获取第一个待爬取的URL. 引擎从蜘蛛那获取第一个需要爬取的URL,然后作为请求 ...
- 爬虫之scrapy工作流程
Scrapy是什么? scrapy 是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需要实现少量代码,就能够快速的抓取到数据内容.Scrapy 使用了 Twisted['twɪstɪd] ...
- scrapy工作流程
整个scrapy流程,我们可以用去超市取货的过程来比喻一下 两个采购员小王和小李开着采购车,来到一个大型商场采购公司月饼.到了商场之后,小李(spider)来到商场前台,找到服务台小花(引擎)并对她说 ...
- scrapy 开发流程
一.Spider 开发流程 实现一个 Spider 子的过程就像是完成一系列的填空题,Scrapy 框架提出以下问题让用户在Spider 子类中作答: 1.爬虫从哪个或者那些页面开始爬取? 2.对于一 ...
- Scrapy 框架流程详解
框架流程图 Scrapy 使用了 Twisted 异步非阻塞网络库来处理网络通讯,整体架构大致如下(绿线是数据流向): 简单叙述一下每层图的含义吧: Spiders(爬虫):它负责处理所有Respon ...
- Scrapy运行流程
接下来的图表展现了Scrapy的架构,包括组件及在系统中发生的数据流的概览(绿色箭头所示). 下面对每个组件都做了简单介绍,并给出了详细内容的链接.数据流如下所描述. 来源于https://scrap ...
- scrapy 安装流程和启动
#Windows平台 1. pip3 install wheel #安装后,便支持通过wheel文件安装软件,wheel文件官网:https://www.lfd.uci.edu/~gohlke/pyt ...
- scrapy使用流程
安装:通过pip install scrapy即可安装 在ubuntu上安装scrapy之前,需要先安装以下依赖:sudo apt-get install python3-dev build-esse ...
- 学习Spider 了解 Scrapy的流程
Scrapy 先创建项目 在windows下 scrapy startproject myproject #myproject是你的项目名称 cd 项目名称 scrapy g ...
- scrapy架构流程
1.爬虫spiders将请求通过引擎传递给调度器scheduler 2.scheduler有个请求队列,在请求队列中拿出请求给下载器,downloader 3.downloader从Internet的 ...
随机推荐
- SpringCloud之服务网关
1.zuul 1.1定义 zuul叫路由网关,它包含对请求的路由和过滤的功能. 路由负责将外部的请求转发到具体的微服务实例上,是实现外部访问统一入口的基础.而过滤是负责对请求的处理过程进行干预,是实现 ...
- LeetCode-重建二叉树(前序遍历+中序遍历)
重建二叉树 LeetCode-105 首次需要知道前序遍历和中序遍历的性质. 解题思路如下:首先使用前序比遍历找到根节点,然后使用中序遍历找到左右子树的范围,再分别对左右子树实施递归重建. 本题的难点 ...
- Spring Security 整合 微信小程序登录的思路探讨
1. 前言 原本打算把Spring Security中OAuth 2.0的机制讲完后,用小程序登录来实战一下,发现小程序登录流程和Spring Security中OAuth 2.0登录的流程有点不一样 ...
- PHP题库1
选择题11. php中,不等运算符是( B.C ) A ≠ B != C <> D >< 2. 函数的参数传递包括:( A.B ) A 按值传递 B ...
- 【Arduino学习笔记03】面包板基础知识
终端带 这里有一块面包板,它后面的黏贴纸被撕去了.你可以看到很多在底部的平行金属条. 金属条的结构:金属条的顶部有一个小夹子.这些夹子能将一条导线或某个部件的引脚固定在塑料洞上,使它们放置在适当的位置 ...
- Python爬虫系统化学习(5)
Python爬虫系统化学习(5) 多线程爬虫,在之前的网络编程中,我学习过多线程socket进行单服务器对多客户端的连接,通过使用多线程编程,可以大大提升爬虫的效率. Python多线程爬虫主要由三部 ...
- kubernetes生产实践之redis-cluster
方案一 自定义yaml文件安装redis cluster 背景 在Kubernetes中部署Redis集群面临挑战,因为每个Redis实例都依赖于一个配置文件,该文件可以跟踪其他集群实例及其角色.为此 ...
- YoloV3 记录
常用于目标检测,因为最近要从目标分类问题转到目标检测中去. tensoflow.Keras(大公司一般都用这个).pytorch(本次学习)------------------主要框架 程序设计模块规 ...
- Linux普通用户安装配置mysql(非root权限)
Linux普通用户安装配置mysql(非root权限) 说明:在实际工作中,公司内网的机器我们一般没有root权限,也没有连网,最近参考网上的资料使用一般的账户成功安装mysql,记录如下 Linux ...
- get和post的区别主要有以下几方面
1.url可见性: get,参数url可见: post,url参数不可见 2.数据传输上: get,通过拼接url进行传递参数: post,通过body体传输参数 3.缓存性: get请求是可以缓存的 ...