R数据分析:生存分析与有竞争事件的生存分析的做法和解释
今天被粉丝发的文章给难住了,又偷偷去学习了一下竞争风险模型,想起之前写的关于竞争风险模型的做法,真的都是皮毛哟,大家见笑了。想着就顺便把所有的生存分析的知识和R语言的做法和论文报告方法都给大家梳理一遍。
什么时候用生存分析
当你关心结局和结局发生时间的时候,就要考虑生存分析了,这种既有结局又有时间的数据叫做生存数据,英文叫做Time-to-event data. 只不过因为这个方法医学上用来分析存活情况用的多,所以得名生存分析,反正你就记住一个例子,我要研究汽车发生故障,我也应该用生存分析,因为我既关心是不是有故障,我还关心用了多久(跑了多远)才出故障,就是既有time,又有event,Time-to-event data就用生存分析。
基本概念
首先是删失,对象失访了,脱落了,出现结局之前随访结束了,都叫做删失:
删失又分为左删失,区间删失和右删失,图示如下:
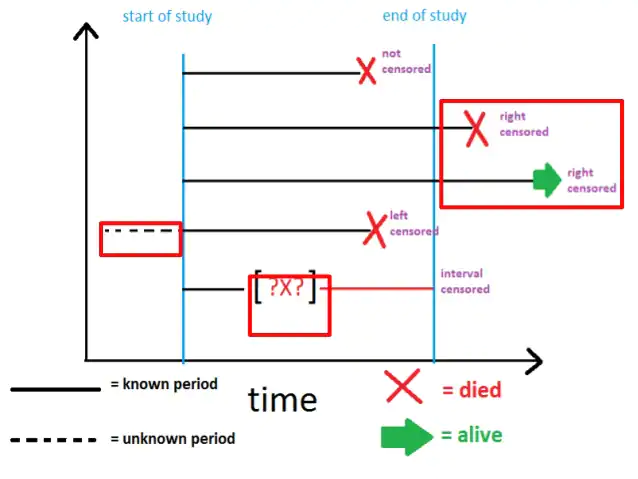
比如我想研究得了A病的人的生存情况,存在的所有可能情形为:
第一种,研究的开始的时候有人已经有A病,这个时候人家已经活了一段时间了,具体多久我不知道,叫做左删失;
第二种,入组随访的时候没病,中途得了A病死了,什么时候得的,没记录下来,叫区间删失;
第三种,得了A病,一直活到了研究结束还没死,叫做右删失。
你看,所有的删失情况造成的后果都是我们没法准确估计发生结局的时间,这也是其名字删失的由来,对于这类数据就需记录为删失数据。
生存分析的种类有哪些
具体的种类是为了回答具体的问题,我们做生存分析常常要回答的问题如下:

一个是描述生存情况,一个是比较,再一个就是探究影响因素。
比如我随访了很多病人,我就想知道随着时间变化这群人的生存概率是如何变化的(描述)?我就可以用简单粗暴的Kaplan-Meier method,又叫乘积极限法,基本思想就是此刻的生存概率等于上一时刻的生存概率乘以此刻的存活率。
比如我手上有如下数据:
time是随访时间,status是结局,我就可以写出如下代码拟合出总体人群的生存曲线:
fit1 <- survfit(Surv(time, status) ~ 1, data = mydata)
summary(fit1)并且得到每个时间点,病人生存概率的估计值和标准误:
如果我还恰好收集了病人的性别,我又想看看男病人和女病人生存情况是不是有不同(比较),我可以对生存曲线分组比较,代码如下:
fit2<- survfit(Surv(time, status) ~ sex, data = mydata)
summary(fit2)输出两组生存曲线比较的log-rank test的统计量:
survdiff(Surv(time, status) ~ sex, data = mydata)并且我们还可以进行复杂分组的组间比较,大家可以翻看我之前的文章。
但是大家明白,KM法始终是在做单因素分析,而且都是做的分类变量的单因素分析,我们经常还会有的需求是考虑各种混杂的情况下去探讨影响生存时间的因素,这个时候我们就要用到The Cox regression model了。
模型形式如下:
上面的式子把h0移项到左边,等号两边同时取对数就成了一个线性模型,和广义线性模型的理解一样一样的,b就是我们的影响因素的系数,解释为lnHR的改变量,其为正就是危险因素,为负就是保护因素:
The quantities exp(bi) are called hazard ratios (HR). A value of bi greater than zero, or equivalently a hazard ratio greater than one, indicates that as the value of the ith covariate increases, the event hazard increases and thus the length of survival decreases.
再观测一下上面的式子,我们拟合了预测因素对风险比例(t时刻风险比上基础风险)的模型,这个时候暗含的假设就是就是对于每个人在任何时刻风险只有一个常数,就是在所有预测因素的作用下,各个时间的风险是不变的,这个就叫做Proportional Hazards Assumption, 比例风险假设。
做COX比例风险模型的时候都有必要验证这个假设是不是满足,具体方法如下:
我们需要先做一个cox模型,拟合cox模型需要用到coxph函数,代码如下:
res.cox <- coxph(Surv(time, status) ~ age + sex + wt.loss, data = lung)
res.cox模型输出结果里面会有预测变量的β值(coef)和其标准误,有HR(exp(coef))值,还有预测变量的显著性检验结果:
我们将这个模型对象直接喂给cox.zph,就可以得到风险比例假设的检验结果了:
test.ph <- cox.zph(res.cox)
test.ph可以看到,我们的p值都大于0.05,即都满足ph假设。
我们还可以从图上看,看scaled Schoenfeld residuals是不是和时间独立,如果独立则满足ph假设:
ggcoxzph(test.ph)有竞争事件时
上面写了只有一个截距事件时生存分析的不同目的,描述,比较,和影响因素探讨,接着再来看存在竞争事件的时候该如何描述,比较,和探讨影响因素。
生存分析的另外情况就是竞争风险模型,就是time to event的event有多种,一种发生了另外一种就不可能发生了,这个就是竞争,比如好多文献中都会列举的经典例子:就是在造血干细胞移植人群中,我们关心其疾病复发风险,但是有些人因为移植死了(TRM),死了之后肯定也谈不上复发,如果你把因为移植死了的人都作为删失数据,肯定也是不对的,这个里面就会有两个竞争结局相关性造成的问题,此时我们应该用竞争风险模型来分析。
For example, disease relapse is an event of interest in studies of allogeneic hematopoietic stem cell transplantation (HSCT), as is mortality related to complications of transplantation (transplant-related mortality or TRM). Relapse and TRM are not independent in this setting because these two events are likely related to immunologic effector mechanisms following HSCT, whereby efforts to reduce TRM may adversely affect the risk of relapse; moreover, patients who die from TRM cannot be at further risk of relapse.
在比例风险中我们的结局事件只有一个,我们关心的是哪些因素对事件发生的风险有影响。在竞争风险模型中我们关注的地方又变了,因为我们有好几个结局事件,这个时候我们会关心在竞争事件存在的情况下各个结局事件的累计发病函数是如何随着时间变化的,以及如何来比较不同的累计发病函数,以及如何探讨影响因素(competing risks regression analysis)。
之前写的在非竞争风险模型中累计发病率的组间比较可以用KM法,将纵坐标换一换,用log-rank检验,在竞争风险模型中我们需要用Fine and Gray提到的方法来做(Gray’s test),如果比如说我发现两组(治疗组和对照组)的累计发病风险不一样,我肯定还想探讨哪些因素影响累计发病风险,之前是用COX比例风险模型做的,在竞争结局存在的情况下我们依然是得用Fine and Gray提出的模型(Fine and Gray Model),叫做竞争风险回归模型:
Fine and Gray (6) proposed a method for direct regression modeling of the effect of covariates on the cumulative incidence function for competing risks data. As in any other regression analysis, modeling cumulative incidence functions for competing risks can be used to identify potential prognostic factors for a particular failure in the presence of competing risks, or to assess a prognostic factor of interest after adjusting for other potential risk factors in the model.
首先看竞争风险时候累计发病曲线的比较方法。我手上有数据如下:
其中dis是疾病类型,2分类,ftime是时间,status是结局事件,结局事件有3个水平,多的1个水平是竞争事件。现在我关心不同疾病人群各个事件累积发病曲线有无不同,我可以用cuminc函数结合plot画出各个组的累计发病曲线:
fit=cuminc (ftime, status, dis, cencode = 0)
plot(fit)fit对象的结果中还有每条曲线的比较,从比较结果可以看出两组在事件2的累积发病曲线上是有显著差异的:
上面介绍的方法相当于没有竞争风险的时候的KM法,通过上面的方法我们知道有了不同风险结局累计发病曲线的差异,继续我们会继续看影响因素,要做的就是竞争风险回归模型了,需要用到的函数就是crr。
比如我手上有如下数据,除了时间,结局还包括每个病人的像sex,age等等协变量,我想探讨说这些因素是如何影响病人某个结局的,我就可以写出一个竞争风险回归模型:
mod1 <- crr(ftime,Status,x)
summary(mod1)上面的代码中x是自变量矩阵,运行代码输出竞争风险回归模型的结果如下:
到这儿基本就写完了所有的生存分析的情况,接着再结合一篇论文看看报告方法,论文就是下面这篇,是我随意查的:
S. Chen, H. Sun, M. Heng, X. Tong, P. Geldsetzer, Z. Wang, P. Wu, J. Yang, Y. Hu, C.
Wang, T. Bärnighausen, Factors Predicting Progression to Severe COVID-19: A Competing Risk Survival Analysis of 1753 Patients in Community Isolation in Wuhan, China, Engineering (2021), doi: https://doi.org/10.1016/j.eng.2021.07.021
这个作者用竞争风险模型探讨了重型新冠进程的影响因素,作者报告了每个影响因素的HR和置信区间,p值,这些都很容易做出来。还报告了固定时间点的累积发病的置信区间。在R语言中固定时间点的累计发病置信区间可以用CumIncidence这个函数计算出来:
The CumIncidence() function allows for the pointwise confidence intervals, by simply adding a further argument, level, where we specify the desired confidence level.
比如我想计算第10天各组的累计发病风险的置信区间,我就可以写出如下代码:
CumIncidence (ftime, status, dis, cencode = 0,t=10,level = 0.95) 输出结果如下:
图中就是各个组在时间为10的时候结局累计发病风险的置信区间。
小结
今天给大家写了生存分析的做法,具体包括存在竞争事件和不存在竞争事件的情况下,生存曲线的描述,比较,影响因素探讨,感谢大家耐心看完,自己的文章都写的很细,重要代码都在原文中,希望大家都可以自己做一做,请转发本文到朋友圈后私信回复“数据链接”获取所有数据和本人收集的学习资料。如果对您有用请先记得收藏,再点赞分享。
也欢迎大家的意见和建议,大家想了解什么统计方法都可以在文章下留言,说不定我看见了就会给你写教程哦,有疑问欢迎私信。
R数据分析:生存分析与有竞争事件的生存分析的做法和解释的更多相关文章
- R数据分析:潜类别轨迹模型LCTM的做法,实例解析
最近看了好多潜类别轨迹latent class trajectory models的文章,发现这个方法和我之前常用的横断面数据的潜类别和潜剖面分析完全不是一个东西,做纵向轨迹的正宗流派还是这个方法,当 ...
- R数据分析:二分类因变量的混合效应,多水平logistics模型介绍
今天给大家写广义混合效应模型Generalised Linear Random Intercept Model的第一部分 ,混合效应logistics回归模型,这个和线性混合效应模型一样也有好几个叫法 ...
- R数据分析:如何简洁高效地展示统计结果
之前给大家写过一篇数据清洗的文章,解决的问题是你拿到原始数据后如何快速地对数据进行处理,处理到你基本上可以拿来分析的地步,其中介绍了如何选变量如何筛选个案,变量重新编码,如何去重,如何替换缺失值,如何 ...
- 数据分析 - 美国金融科技公司Prosper的风险评分分析
数据分析 - 美国金融科技公司Prosper的风险评分分析 今年Reinhard Hsu觉得最有意思的事情,是参加了拍拍贷第二届魔镜杯互联网金融数据应用大赛.通过"富爸爸队",认识 ...
- (转载)Flash Loader加载完成不发送COMPLETE和ERROR事件的问题分析
(转载)http://blog.dou.li/flash-loader%E5%8A%A0%E8%BD%BD%E5%AE%8C%E6%88%90%E4%B8%8D%E5%8F%91%E9%80%81co ...
- UiAutomator喷射事件的源代码分析
上一篇文章<UiAutomator源代码分析之UiAutomatorBridge框架>中我们把UiAutomatorBridge以及它相关的类进行的描写叙述,往下我们会尝试依据两个实例将这 ...
- 老李推荐:第6章5节《MonkeyRunner源码剖析》Monkey原理分析-事件源-事件源概览-事件
老李推荐:第6章5节<MonkeyRunner源码剖析>Monkey原理分析-事件源-事件源概览-事件 从网络过来的命令字串需要解析翻译出来,有些命令会在翻译好后直接执行然后返回,但有 ...
- Android系统--输入系统(十三)Dispatcher线程情景分析_Reader线程传递事件
Android系统--输入系统(十三)Dispatcher线程情景分析_Reader线程传递事件 1. 输入按键 我们知道Android系统的按键分为三类:(1)Global Key;(2)Syste ...
- jquery get ($.get) 事件用法与分析
jquery get ($.get) 事件用法与分析 get() 方法通过远程 HTTP GET 请求载入信息.这是一个简单的 GET 请求功能以取代复杂 $.ajax .请求成功时可调用回调函数.如 ...
随机推荐
- 产生UUID随机字符串工具类
产生UUID随机字符串工具类 UUID是指在一台机器上生成的数字,它保证对在同一时空中的所有机器都是唯一的.通常平台会提供生成的API.按照开放软件基金会(OSF)制定的标准计算,用到了以太网卡地址. ...
- Windows 11正式版来了,下载、安装教程、一起奉上!
Windows 11正式版已经发布了,今天给大家更新一波Win11系统的安装方法,其实和Win10基本一样,有多种方法. 安装Win11前请先查看电脑是否支持Win11系统,先用微软自家的PC H ...
- IDEA Web渲染插件开发(二)— 自定义JsDialog
<IDEA Web渲染插件开发(一)>中,我们了解到了如何编写一款用于显示网页的插件,所需要的核心知识点就是IDEA插件开发和JCEF,在本文中,我们将继续插件的开发,为该插件的JS Di ...
- CI/CD-企业级DevOps
CI/CD-企业级DevOps 什么是DevOps? DevOps是一种思想或方法论,它涵盖开发.测试.运维的整个过程! DevOps强调软件开发人员与软件测试.软件运维.质量保障(QA) 部门之间有 ...
- 如何在前端通过JavaScript创建修改CAD图形
背景 在之前的博文CAD图DWG解析WebGIS可视化技术分析总结.CAD_DWG图Web可视化一站式解决方案-唯杰地图-vjmap中讲解了如何把CAD的DWG格式的图纸Web可视化的方案,那在Web ...
- Shadertoy 教程 Part 1 - 介绍
Note: This series blog was translated from Nathan Vaughn's Shaders Language Tutorial and has been au ...
- 学了ES6,还不会Promise的链式调用?🧐
前言 本文主要讲解promise的链式调用的方法及其最终方案 应用场景 假如开发有个需求是先要请求到第一个数据,然后根据第一个数据再去请求第二个数据,再根据第二个数据去请求第三个数据...一直到最后得 ...
- BUAA2020软工团队beta得分总表
BUAA2020软工团队beta得分总表 [TOC] 零.团队博客目录及beta阶段各部分博客地址 团队博客 计划与设计博客 测试报告博客 发布声明博客 事后分析博客 敏 杰 开 发♂ https:/ ...
- UltraSoft - Beta - Scrum Meeting 9
Date: May 25th, 2020. Scrum 情况汇报 进度情况 组员 负责 今日进度 q2l PM.后端 记录Scrum Meeting Liuzh 前端 用户忘记密码界面初稿完成 Kkk ...
- linux下命令拼接
前言:我个five,一道特别简单的拼接题没有做出来,我吐了,不过也是涨知识了 直接切入正题了 linux命令是可以拼接的,也就是说在一个system("???")下我们的???可以 ...