scrapy_电影天堂多页数据和图片下载
嵌套的 爬取
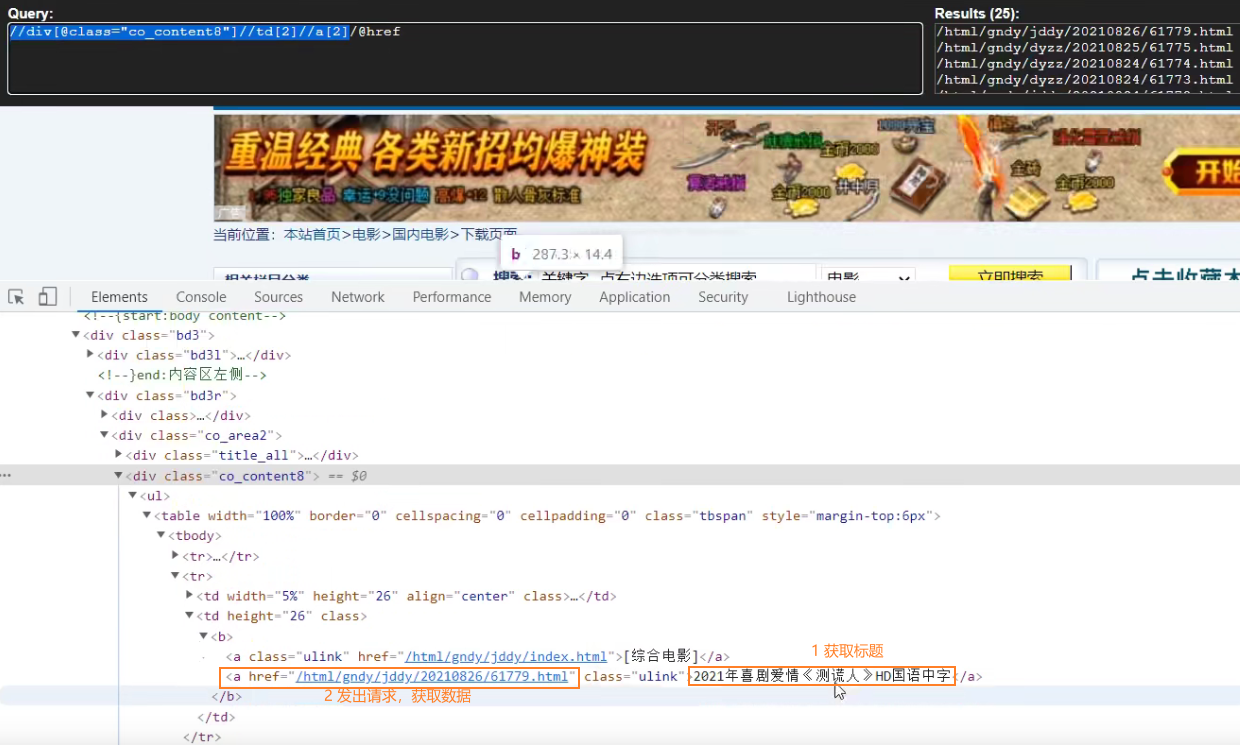
先获取第一页的标题
点击标题到第二页的图片url

1、创建项目
> scrapy startproject scrapy_movie_099
2、创建爬虫文件
spiders>scrapy genspider mv https: //www.dytt8.net/html/gndy/china/index.html
3、测试
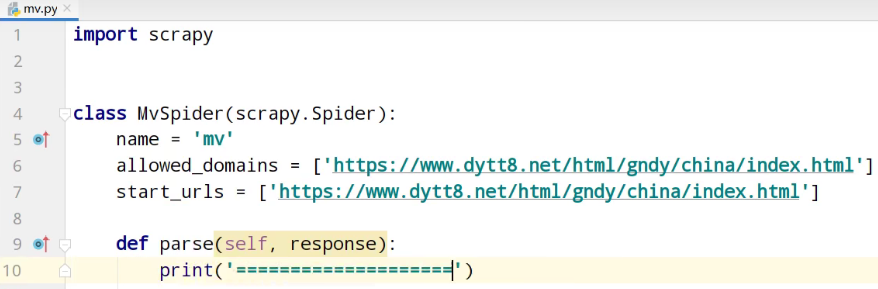
5、运行
spiders> scrapy crawl mv

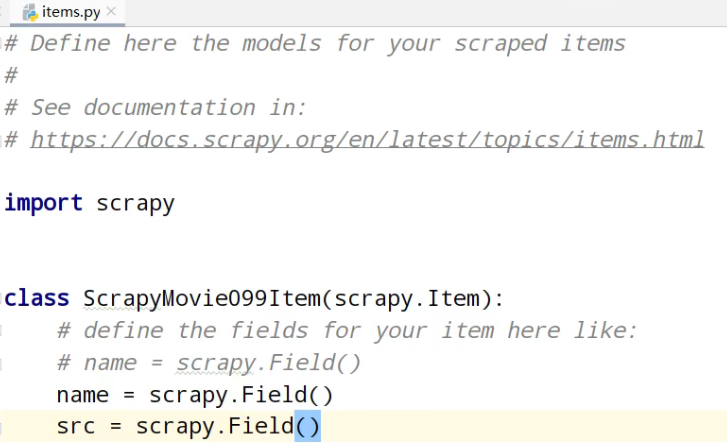
①、定义数据结构
②、分析xpath
运行
spiders> scrapy crawl mv

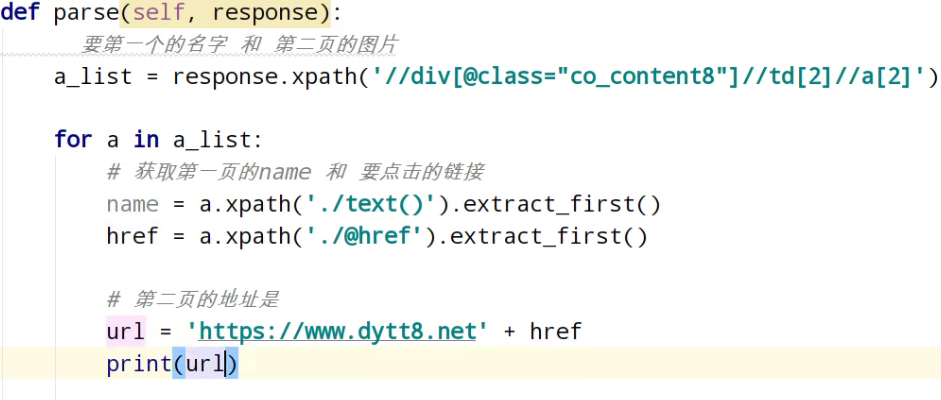
分析第二页的地址

运行
spiders> scrapy crawl mv

测试

分析第二页的地址
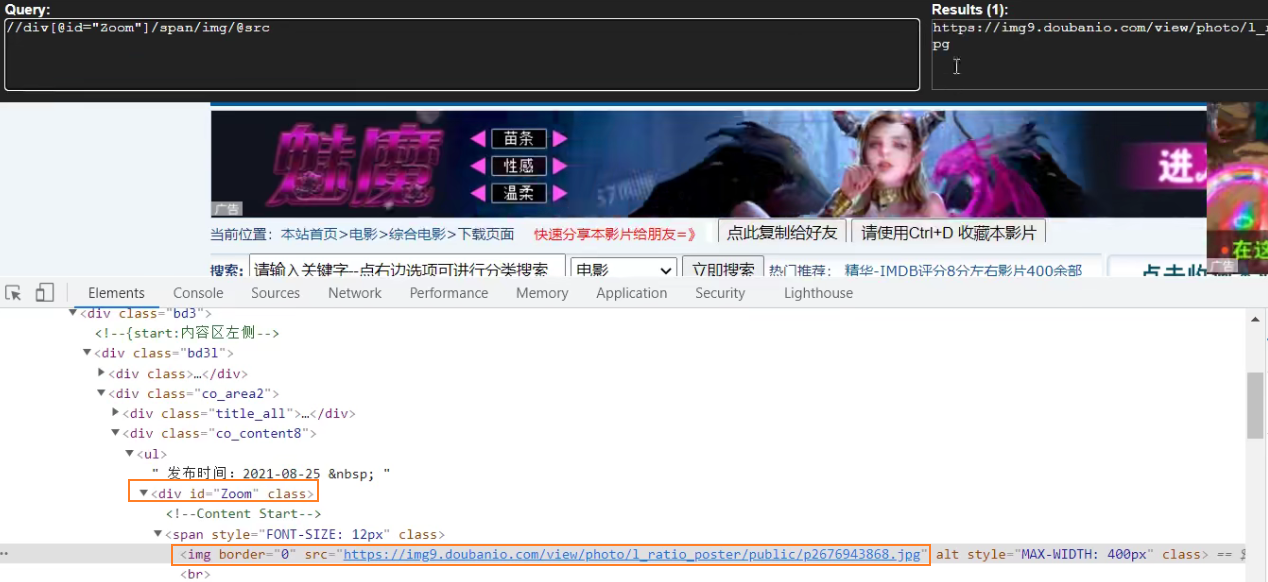
测试xpath,有些span标签识别不了。调试修改成 //div[@id="Zoom"]//img/@src
测试

查看转到定义request

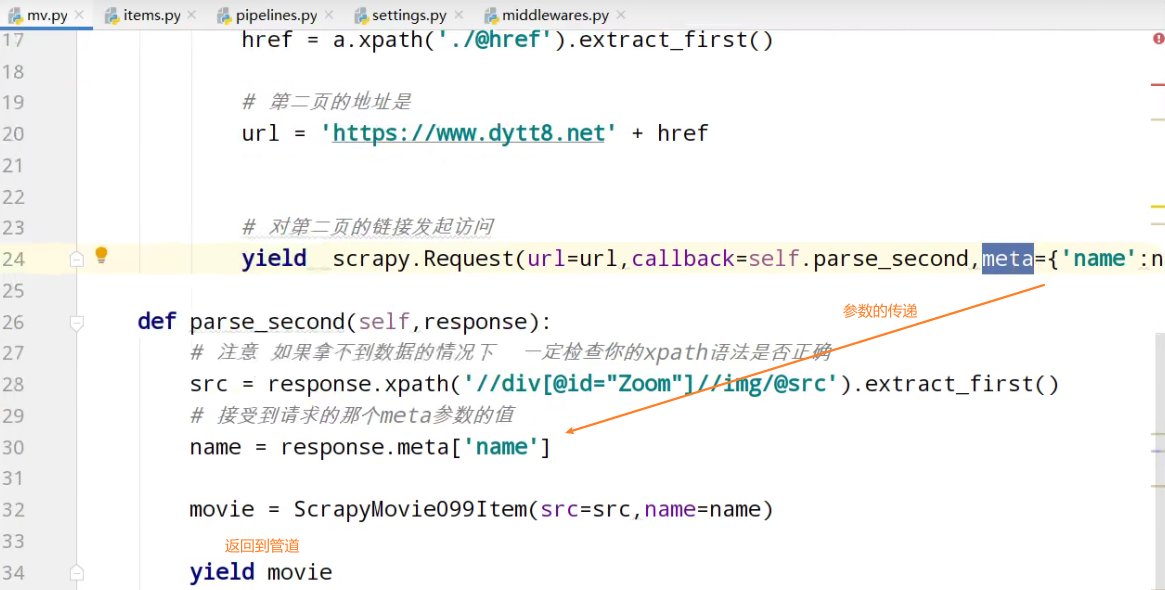
meta是个字典

导入数据结构类

movie返回个管道
settings中开启管道
pipeline管道的封装
运行
spiders> scrapy crawl mv

项目文件
爬虫核心文件mv.py
import scrapy from scrapy_movie_099.items import ScrapyMovie099Item class MvSpider(scrapy.Spider):
name = 'mv'
allowed_domains = ['www.dytt8.net']
start_urls = ['https://www.dytt8.net/html/gndy/china/index.html'] def parse(self, response):
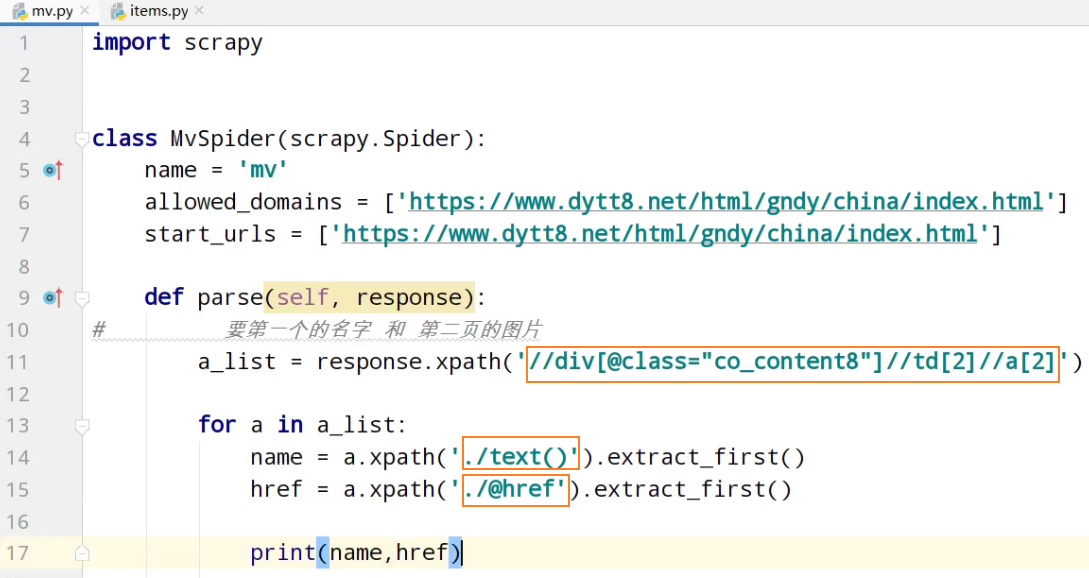
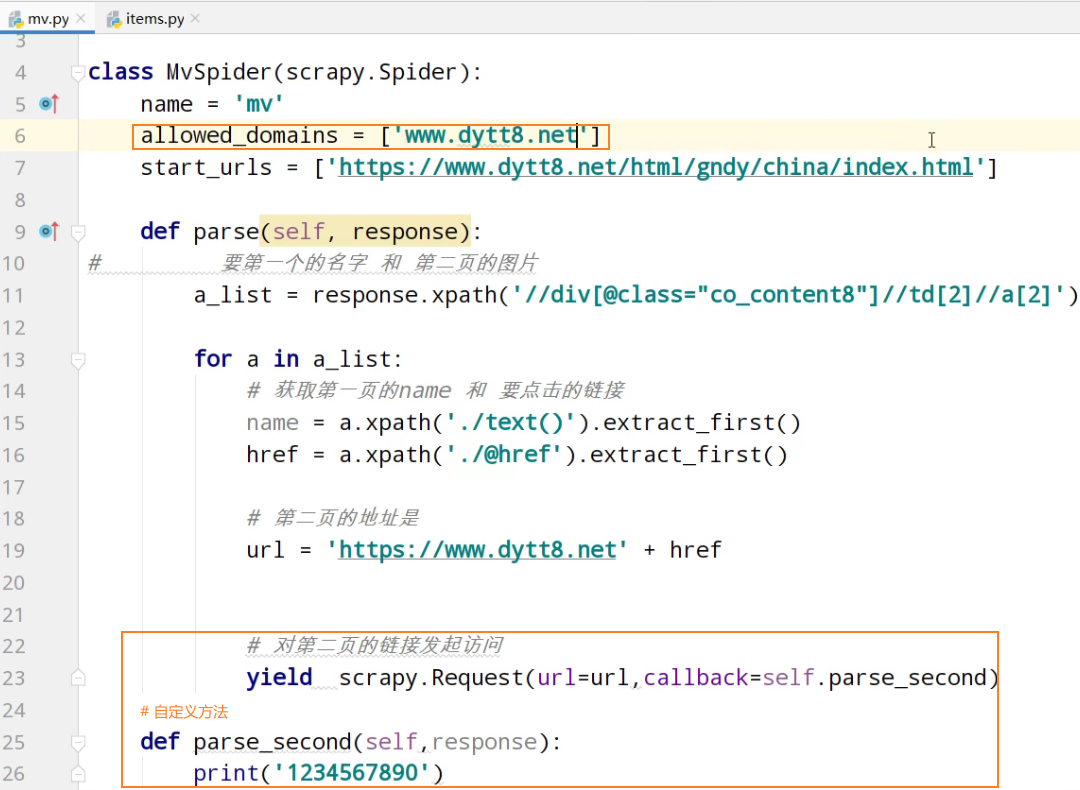
# 要第一个的名字 和 第二页的图片
a_list = response.xpath('//div[@class="co_content8"]//td[2]//a[2]') for a in a_list:
# 获取第一页的name 和 要点击的链接
name = a.xpath('./text()').extract_first()
href = a.xpath('./@href').extract_first() # 第二页的地址是
url = 'https://www.dytt8.net' + href # 对第二页的链接发起访问
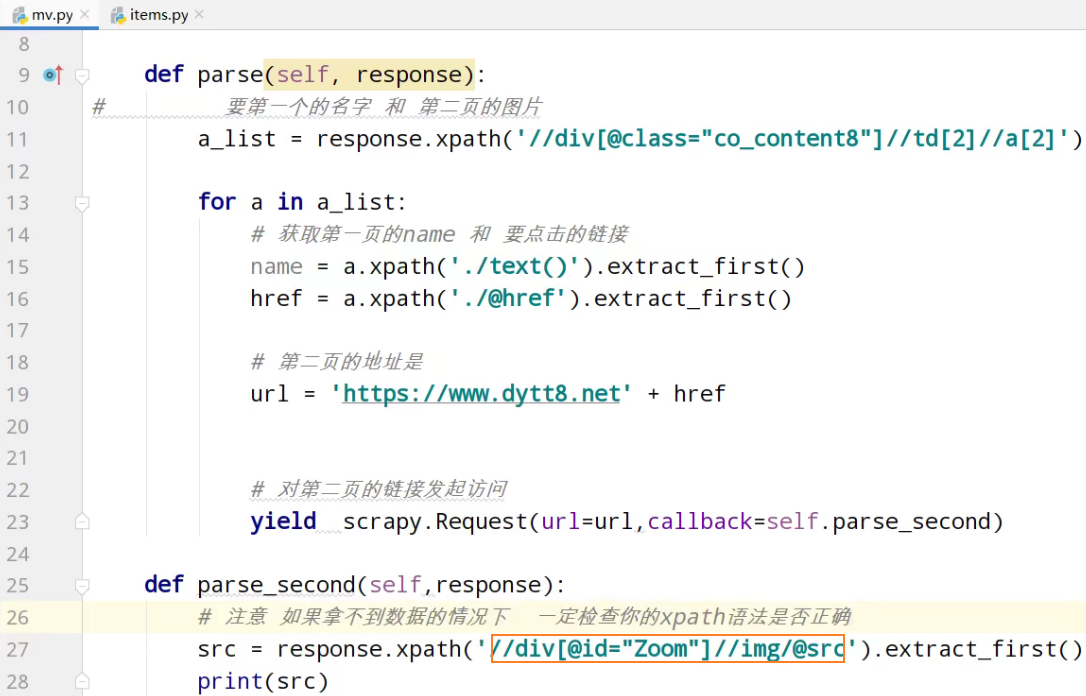
yield scrapy.Request(url=url,callback=self.parse_second,meta={'name':name}) def parse_second(self,response):
# 注意 如果拿不到数据的情况下 一定检查你的xpath语法是否正确
src = response.xpath('//div[@id="Zoom"]//img/@src').extract_first()
# 接受到请求的那个meta参数的值
name = response.meta['name'] movie = ScrapyMovie099Item(src=src,name=name) yield movie
items.py自定义结构类
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html import scrapy class ScrapyMovie099Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
src = scrapy.Field()
settings.py基本配置。robots协议配置,管道配置
# Scrapy settings for scrapy_movie_099 project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html BOT_NAME = 'scrapy_movie_099' SPIDER_MODULES = ['scrapy_movie_099.spiders']
NEWSPIDER_MODULE = 'scrapy_movie_099.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'scrapy_movie_099 (+http://www.yourdomain.com)' # Obey robots.txt rules
ROBOTSTXT_OBEY = True # Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default)
#COOKIES_ENABLED = False # Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False # Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#} # Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'scrapy_movie_099.middlewares.ScrapyMovie099SpiderMiddleware': 543,
#} # Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'scrapy_movie_099.middlewares.ScrapyMovie099DownloaderMiddleware': 543,
#} # Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#} # Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'scrapy_movie_099.pipelines.ScrapyMovie099Pipeline': 300,
} # Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
pipelines.py管道功能
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html # useful for handling different item types with a single interface
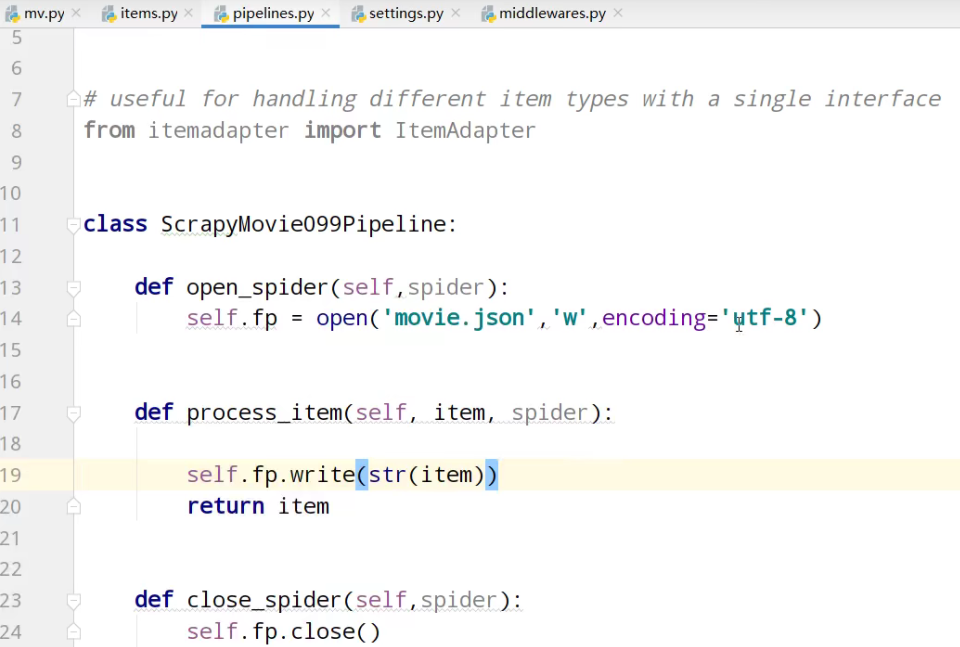
from itemadapter import ItemAdapter class ScrapyMovie099Pipeline: def open_spider(self,spider):
self.fp = open('movie.json','w',encoding='utf-8') def process_item(self, item, spider): self.fp.write(str(item))
return item def close_spider(self,spider):
self.fp.close()
scrapy_电影天堂多页数据和图片下载的更多相关文章
- 猫眼电影和电影天堂数据csv和mysql存储
字符串常用方法 # 去掉左右空格 'hello world'.strip() # 'hello world' # 按指定字符切割 'hello world'.split(' ') # ['hello' ...
- [py][mx]django添加后台课程机构页数据-图片上传设置
分析下课程页前台部分 机构类别-目前机构库中没有这个字段,需要追加下 所在地区 xadmin可以手动添加 课程机构 涉及到机构封面图, 即图片上传media设置, 也需要在xadmin里手动添加几条 ...
- ajax的get方法获取豆瓣电影前10页的数据
# _*_ coding : utf-8 _*_ # @Time : 2021/11/2 11:45 # @Author : 秋泊酱 # 1页数据 电影条数20 # https://movie.dou ...
- python爬取豆瓣电影第一页数据and使用with open() as读写文件
# _*_ coding : utf-8 _*_ # @Time : 2021/11/2 9:58 # @Author : 秋泊酱 # @File : 获取豆瓣电影第一页 # @Project : 爬 ...
- python利用requests和threading模块,实现多线程爬取电影天堂最新电影信息。
利用爬到的数据,基于Django搭建的一个最新电影信息网站: n1celll.xyz (用的花生壳动态域名解析,服务器在自己的电脑上,纯属自娱自乐哈.) 今天想利用所学知识来爬取电影天堂所有最新电影 ...
- Node.js 抓取电影天堂新上电影节目单及ftp链接
代码地址如下:http://www.demodashi.com/demo/12368.html 1 概述 本实例主要使用Node.js去抓取电影的节目单,方便大家使用下载. 2 node packag ...
- 使用Requests+正则表达式爬取猫眼TOP100电影并保存到文件或MongoDB,并下载图片
需要着重学习的地方:(1)爬取分页数据时,url链接的构建(2)保存json格式数据到文件,中文显示问题(3)线程池的使用(4)正则表达式的写法(5)根据图片url链接下载图片并保存(6)MongoD ...
- scrapy电影天堂实战(二)创建爬虫项目
公众号原文 创建数据库 我在上一篇笔记中已经创建了数据库,具体查看<scrapy电影天堂实战(一)创建数据库>,这篇笔记创建scrapy实例,先熟悉下要用到到xpath知识 用到的xpat ...
- 14.python案例:爬取电影天堂中所有电视剧信息
1.python案例:爬取电影天堂中所有电视剧信息 #!/usr/bin/env python3 # -*- coding: UTF-8 -*- '''======================== ...
随机推荐
- MySQL MVCC原理深入探索
一.MVCC的由来 二.MVCC的实际应用 RR级别场景 RC级别场景 三.MVCC的实现 3.1 多版本的数据从哪里来--Undo Log 3.1.1 插入操作对应的undo log 3.1.2 删 ...
- Java实现爬取京东手机数据
Java实现爬取京东手机数据 最近看了某马的Java爬虫视频,看完后自己上手操作了下,基本达到了爬数据的要求,HTML页面源码也刚好复习了下,之前发布两篇关于简单爬虫的文章,也刚好用得上.项目没什么太 ...
- 学习Tomcat(七)之Spring内嵌Tomcat
前面的文章中,我们介绍了Tomcat容器的关键组件和类加载器,但是现在的J2EE开发中更多的是使用SpringBoot内嵌的Tomcat容器,而不是单独安装Tomcat应用.那么Spring是怎么和T ...
- Java初步学习——2021.09.23每日报告,第三周周四
(1)今天做了什么: (2)明天准备做什么? (3)遇到的问题,如何解决? 学习数组,编写了一个随机选牌的代码.自己最开始一直想只设置一个字符串数组,利用随机数来输出,但那样对字符串赋值会比较麻烦.可 ...
- bzoj4821 && luogu3707 SDOI2017相关分析(线段树,数学)
题目大意 给定n个元素的数列,每一个元素有x和y两种元素,现在有三种操作: \(1\ L\ R\) 设\(xx\)为\([l,r]\)的元素的\(x_i\)的平均值,\(yy\)同理 求 \(\fra ...
- 【UE4】GAMES101 图形学作业1:mvp 模型、视图、投影变换
总览 到目前为止,我们已经学习了如何使用矩阵变换来排列二维或三维空间中的对象.所以现在是时候通过实现一些简单的变换矩阵来获得一些实际经验了.在接下来的三次作业中,我们将要求你去模拟一个基于CPU 的光 ...
- Sequence Model-week3编程题1-Neural Machine Translation with Attention
1. Neural Machine Translation 下面将构建一个神经机器翻译(NMT)模型,将人类可读日期 ("25th of June, 2009") 转换为机器可读日 ...
- Noip模拟79 2021.10.17(题目名字一样)
T1 F 缩点缩成个$DAG$,然后根据每个点的度数计算期望值 1 #include<cstdio> 2 #include<cstring> 3 #include<vec ...
- Noip模拟35 2021.8.10
考试题目变成四道了,貌似确实根本改不完... 不过给了两个小时颓废时间确实很爽(芜湖--) 但是前几天三道题改着不是很费劲的时候为什么不给放松时间, 非要在改不完题的时候颓?? 算了算了不碎碎念了.. ...
- $dy$讲课总结
字符串: 1.广义后缀自动机(大小为\(m\))上跑一个长度为\(n\)的串,所有匹配位置及在\(parent\)树上其祖先的数量的和为\(min(n^2,m)\),单次最劣是\(O(m)\). 但是 ...