如何快速排查发现redis的bigkey?4种方案一次性给到你!
本篇文章将以redis的bigkey为主题进行技术展开,通过从认识redis的高性能,bigkey的危害、存在原因、4种解决方案,到模拟实战演练的介绍方式,来跟大家一起认识、探讨和学习redis。
先认识一下redis和bigkey吧
redis——互联网的宠儿
redis作为一款优秀的工业级内存型数据库,自诞生后便逐渐成为互联网的宠儿,支撑起了互联网丰富多彩的功能和巨大的QPS(每秒查询率),并和nginx一样成为高性能的代名词,比如微博上的每一条热搜背后都有着redis默默守候。从某种意义上来说,redis的使用量也代表着一家互联网公司的流量。
在冯诺伊曼计算体系中,内存是一种重要的存在。计算和存储之间存在着一定的辩证关系,通过计算可以减少存储,通过存储可以减少一定量的消耗。因此,缓存的思想也成为系统性能减少计算量的一种重要优化手段。
我们看两张对比图。
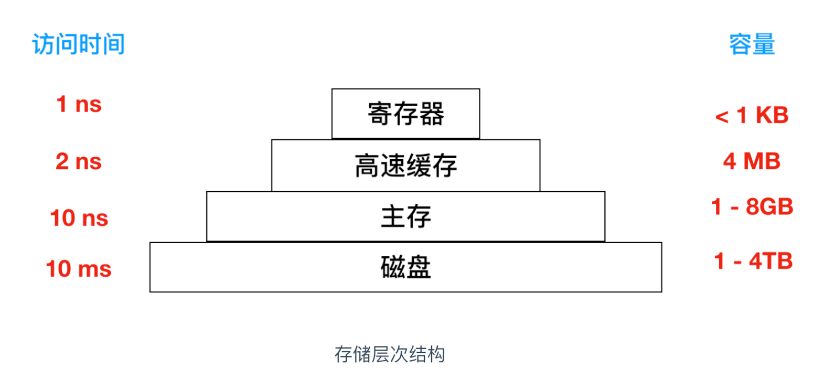
这张是cpu、内存、磁盘的性能对比。内存的读写性能是磁盘的近一千倍,redis作为内存型存储介质,对系统性能提升具有革命性的变化,经济基础决定上层建筑,所以经济效益永远是第一位的。
再看下各种存储的价格。
我们简单评估分析下:内存折算大约30元1G,磁盘大约0.5元1G,相比性能的差别,经济效益的投入产出比还是很高的。
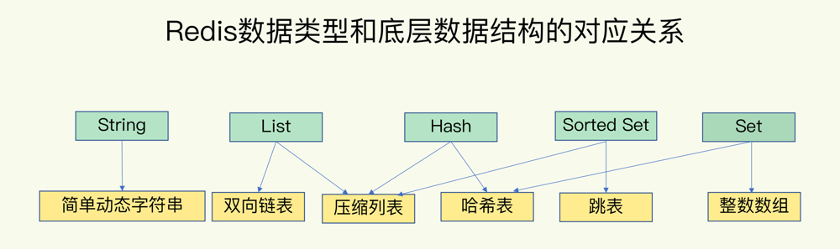
redis的存储数据结构:redis是一种key/value结构的存储型数据库,内部组织形式使用了hashMap的这种数据存取索引结构,数据的读取时间复杂度为O(1)。hashMap的key为string类型,valuek可以为string、list、hashMap、set和zset五种基本数据结构。这些数据都存储在内存中,具有高效的读写性能,常被用来做缓存处理,提高系统的性能。
底层存储结构如下:
支撑起redis高性能的另一个设计实现就是单线程的任务处理设计。
在面对一个巨大工作量时,为了尽快完成工作任务,通常都会选择加人,把任务拆解成多份并行处理。这就是一个简单的多线程并发处理的思想,多线程可以提高任务处理的吞吐量。
那么为什么redis却反其道而行之,使用单线程的方式?这里的单线程是指Redis 的网络 IO 和键值对读写是由一个线程来完成的,这也是 Redis 对外提供键值存储服务的主要流程。
先来看下,如果使用多线程,在处理网络IO时会存在哪些问题?线程是cpu调度的基本单位,cpu通过时钟中断,进行时间片的切换,对外表现出并行处理的效果,任务切换必然消耗资源。当开启很多的线程,到一定量后,这些切换就会达到性能的瓶颈。
还有一个就是多线程下的资源共享问题,这也是并发编程的核心问题。并发环境下存在资源竞争,就需要对共享资源的临界区进行加锁处理,把并发处理转化为串行化处理,redis的数据结构中,底层使用的hashMap索引数据结构,在多线程处理情况下,必然出现资源争夺的问题,这即又变成一个串行同步化的处理过程。因此,我们在此否定了多线程。
那么来看看单线程在这种场景下有什么好处
请求端和服务端通过tcp三次握手后会建立网络连接,请求数据从网卡被写入到操作系统的内核缓冲区中,用户程序执行read操作,会将数据从内核空间写入到用户程序执行的变量中,如果内核空间还未收到数据,这里就会发生阻塞等待。
这种处理方式我们显然是不能够接受的,为了解决这个技术问题,一种被叫做IO多路复用的技术被创造出来,在linux下一共有三种实现,select、poll、epoll,,简单来说,该机制允许内核中同时存在多个监听套接字和已连接套接字,再完成读写就绪,通知用户态来执行。具体这里不做展开,有兴趣的朋友可以网上搜下。
nodejs、nginx这些网关层的技术,都是单线程的设计,在处理网络IO上,单线程要比多线程优异。但是单线程也有其致命的弱点,一旦处理中的某个请求任务处理过长,就会阻塞后边的请求。这也是后文要展开的bigkey危害的主要原因。就像单行道上,某辆车出现了故障,就会出现堵车现象一个道理。
一、什么是bigkey?
从上图的redis底层数据存储结构中,可以看到value具有多种数据结构的实现,因此,value大小在字符串类型,表现为字符串的长度;value为复合类型,则表现为元素的个数。
bigkey就是redis key/value体系中的大value问题。根据数据类型的划分,bigkey体现在两点:
- 存储数据为string类型, value值长度过大;
- value为复合类型,包含元素个数过多。
在redis中,一个字符串最大512MB,一个二级数据结构(例如hash、list、set、zset)可以存储大约40亿个(2^32-1)个元素,这是一个理论值,实际使用时,我们可以通过运维给到的数据来综合衡量限制数,一般string类型控制在10KB以内,复合类型hash、 list,、set,和zset元素个数不超过5000个。
二、bigkey有什么危害?产生原因?
看到这里,我们对bigkey已经有一个初步的了解。接下来,我们针对bigkey的危害和产生原因一一进行介绍。
1、bigkey的四大危害
俗话说“一颗老鼠屎坏掉一锅汤”,对于redis而言,bigkey就像是老鼠屎的存在。其危险性主要表现为以下四个方面:
1.内存空间不均匀
在集群模式中,由于bigkey的存在,会造成主机节点的内存不均匀,这样会不利于集群对内存的统一管理,存在丢失数据的隐患。
2.超时阻塞
由于redis单线程的特性,操作bigkey通常比较耗时,也就意味着阻塞redis可能性越大,这样会造成客户端阻塞或者引起故障切换。慢查询通常就会有它们的身影。
3.网络拥塞
bigkey也就意味着每次获取要产生的网络流量较大。假设一个bigkey为1MB,客户端每秒访问量为1000,那么每秒产生1000MB的流量,对于普通的千兆网卡(按照字节算是128MB/s)的服务器来说简直是灭顶之灾。
4.阻塞删除
有个bigkey,对它设置了过期时间,当它过期后会被删除,如果使用Redis 4.0之前的版本,过期key是异步删除,就会存在阻塞redis的可能性,而且这个过期删除不会从慢查询发现(因为这个删除不是客户端产生的,是内部循环事件)。
2、bigkey怎么产生的?
bigkey的产生主要是由于程序的设计不当所造成的,如以下几种常见的业务场景
- 社交类:粉丝列表,如果某些明星或者大v不精心设计下,必是bigkey。
- 统计类:例如按天存储某项功能或者网站的用户集合,除非没几个人用,否则必是bigkey。
- 缓存类:将数据从数据库load出来序列化放到redis里,这个方式经常常用,但有两个地方需要注意:第一,是不是有必要把所有字段都缓存;第二,有没有相关关联的数据。
由此可见,在程序设计中,我们要对数据量的增长和边界有一个基本性的评估,做好技术选型和技术架构。
三、4种排查发现bigkey的解决方案
先看一个思考题:
今天年初,石家庄陆续爆发新冠疫情,对于一个有着1000万多人口的中大型城市,疫情防控面临着巨大的压力,怎么高效的发现病毒感染人群和接触人群,成为疫情防控取胜的关键。政府做了以下几方面工作,简单概括为4点:
- 禁止人员流通,居家隔离;
- 制定风险等级;
- 网格化管理;
- 核算检测。
根据流行病医学特点,出现症状必须主动上报。这种是主动上报,因为新冠疫情具有一定的潜伏期,很多无症状患者,因此就需要通过核算检测的机制,主动地发现,这其实就体现了一种计算机处理扫描的思想。
发现、处理bigkey的思想和疫情防控的做法有些相似,常规做法也有四种。
1、redis客户端工具
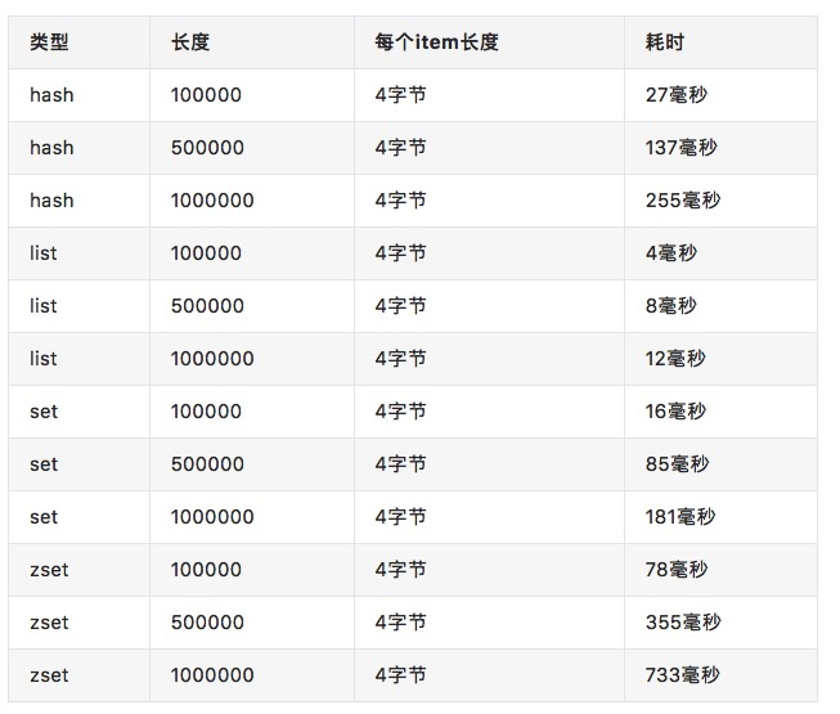
redis-cli提供了--bigkeys来查找bigkey,例如下面就是一次执行结果。
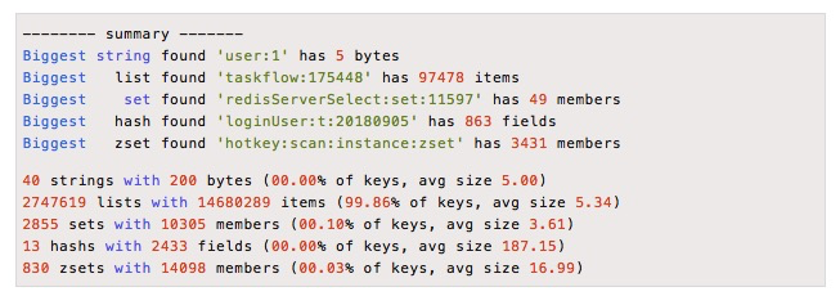
从上图可以看这种方式给出了每种数据结构的top 1 bigkey,同时给出了每种数据类型的键值个数以及平均大小。但如果我们需要更多的bigkey,这种方式就无法做到。它的内部是通过scan的方式进行的,有一定的性能开支,为了不影响业务,可把该任务放到从节点上进行执行。
2、debug object
redis提供了一个debug object key的命令。假设有一个“找出redis中大于10KB以上的key"需求,为了得到该结果数据,就需要先扫描出所有的key,然后通过循环调用debug object key得到所有key的字节大小。
由于debug object key的执行效率很慢,会存在阻塞redis线程的可能。因此该种方案,对业务也会存在一定的损伤,在使用时,可将该执行程序运行到从节点之上。
3、RDB文件扫描
我们知道,redis有一种持久化的方案叫做RDB持久化,它是redis内存存储数据的一个磁盘化快照,通过RDB工具对RDB文件进行扫描,可以查找出存在的bigkey。
在选择这种方案时,首先需要做RDB文件持久化。RDB持久化是一种内存快照的形式,按照一定的频次进行快照落盘,这种方案是一种理想化的选择,不会影响redis主机的运行,但在对数据可靠性要求很高的场景,不会选择RDB持久化方案,也因此它不具有普遍适用性。
4、DataFlux bigkey的扫描设计思想
前面几种方案,要么由客户端发现,要么需要进行全量数据扫描,扫描是很消耗计算资源的一种行为。类比疫情,就好比是某千万人口的城市出现病例后,不分等级地对全员进行核酸检测,这不但消耗巨大的物力、财力、人力,效率还十分低下,跟需要和时间赛跑的疫情防控背道而驰。
上文我们也分析了redis bigkey产生的原因,很多都是业务的设计不合理和评估不足所导致的。因此DataFlux产品在设计中,就让datakit的redis采集器使用了一种自主配置潜在bigkey进行扫描发现的方案,支持固定key值和key pattern。在key pattern中,通过scan pattern 得到一定范围的key,再通过length函数对每种类型的key("HLEN""LLEN""SCARD""ZCARD""PFCOUNT""STRLEN")取值,得到对应的key的length,上报DataFlux平台进行监控存储。
这种做法的好处就两点:
一、由于是针对目标key得到length,而redis中各种数据类型的length值获取都是O(1)时间复杂度。因此执行效率很高;
二、采集到的结果数据上报到DataFlux存储平台,在该平台下,可以对指标数据做各种图表展示,监控告警。
接下来,我们通过对该方案进行简单的业务场景模拟来展开说明。
四、实战演练,等的就是这刻!
在一个业务系统中,使用redis的string类型存储用户的认证token, 使用list数据类型做异步消息队列。
业务分析:存储token的key数据是一个定长数据,不会有数据量的变化,不会形成bigkey。再来看消息队列,如果消费端出现故障,消息生产端在这一时刻涌入了大量数据,这时使用消息队列的redis key就会成为一个潜在的bigkey,因此,我们需要对该key进行监控。
我们假设消息队列的键名为queue。
我们按官方教程,安装datakit工具。
官方教程:《如何安装DataKit》https://help.dataflux.cn/doc/ef29e8365e18d813a8ec5800bbcb1adf1f39ab37
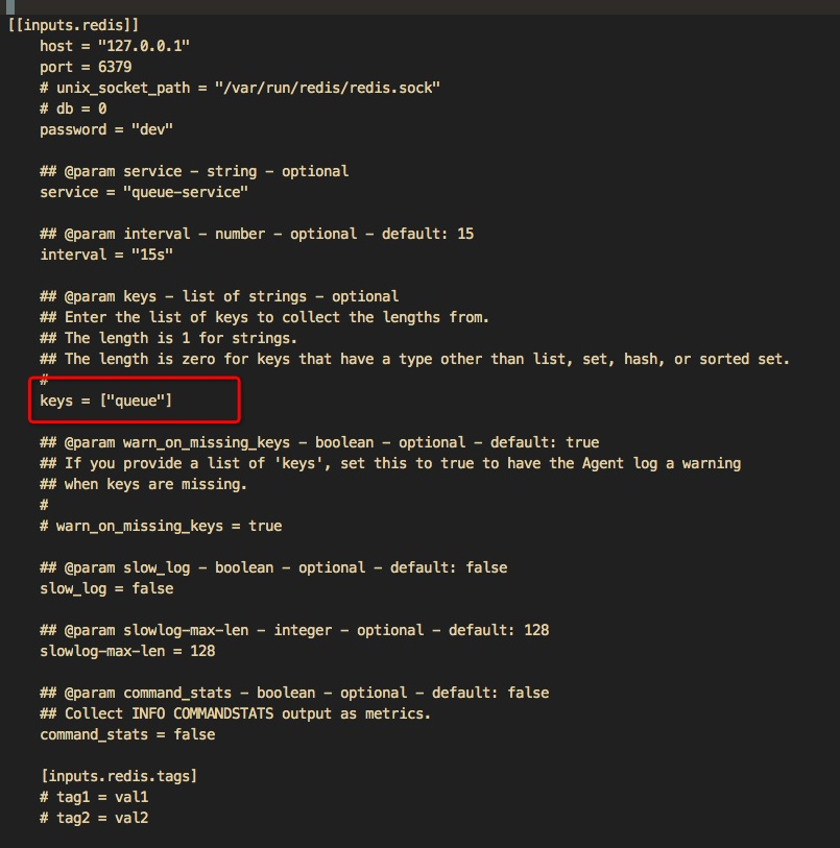
安装好后,进入 DataKit 安装目录下的 conf.d/db 目录,复制 redis.conf.sample 并命名为 redis.conf。做下图配置:
模拟初始队列push 10个value

数据上报到DataFlux平台
再push一定量的数据

最终可在DataFlux后台上看到如下采集结果。
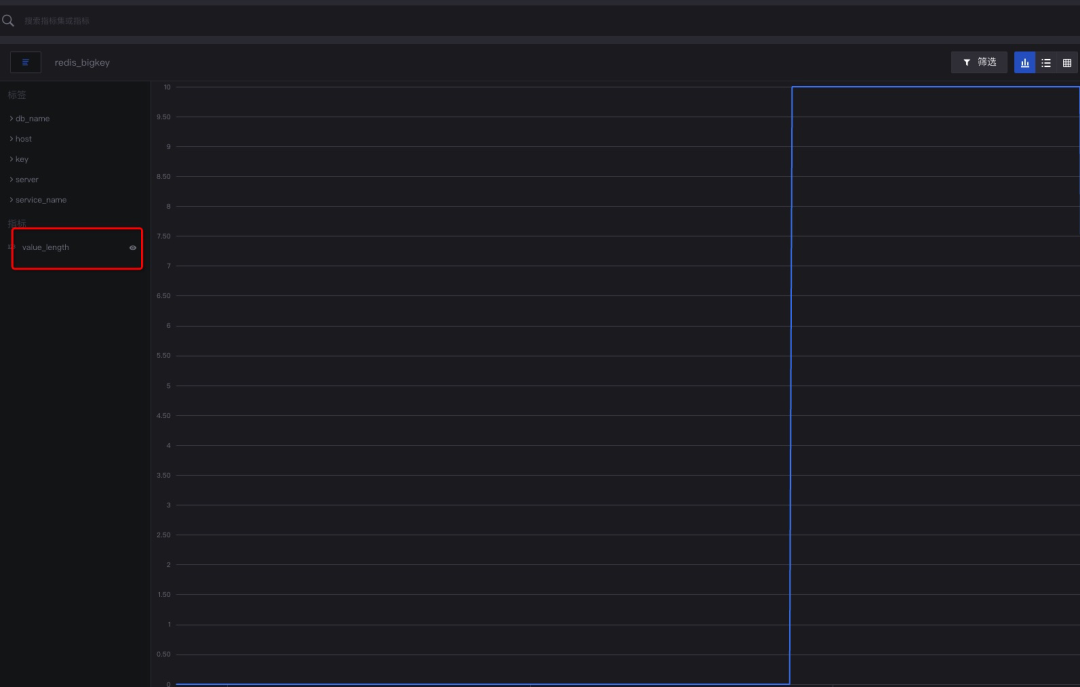
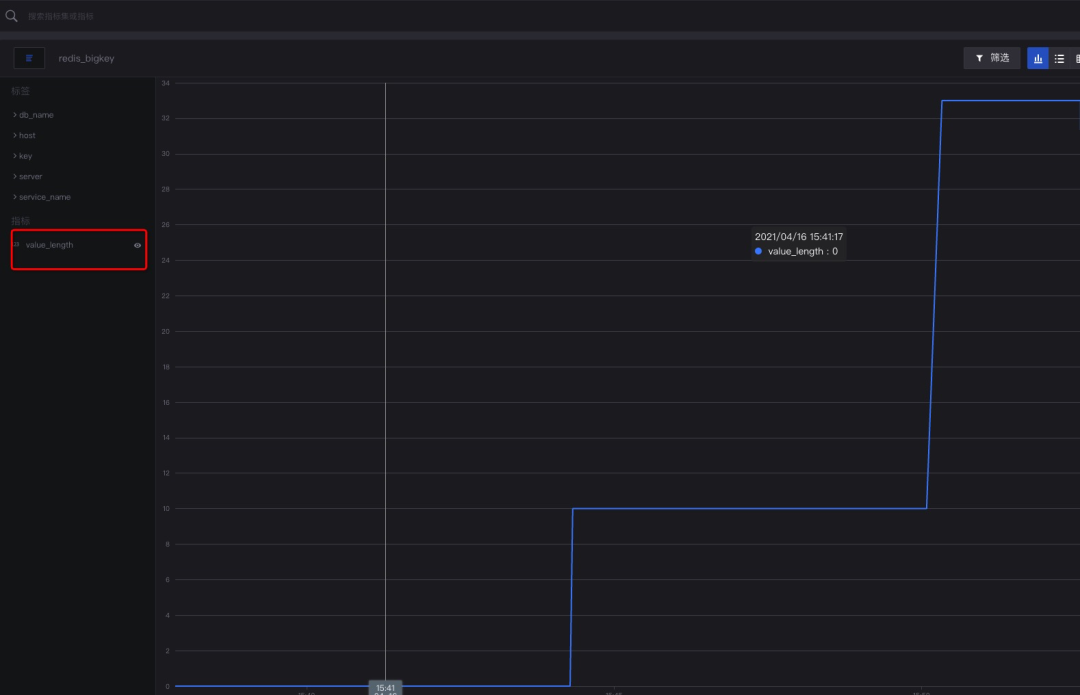
在DataFlux平台上,通过指标可对监控的key进行图表展示、监控报警以及可视化展示等等,最大幅度呈现数据价值。
如何快速排查发现redis的bigkey?4种方案一次性给到你!的更多相关文章
- Redis 持久化的两种方案
reids是一个key-value存储系统,为了保证效率,缓存在内存中,但是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,以保证数据的持久化. 所以:redis是一个支持持 ...
- zabbix告警邮件、短信发送错误快速排查方法
zabbix告警邮件.短信发送错误快速排查方法 背景 zabbix告警邮件.短信经常有同事反馈发送错误的情况,这个问题排查的角度很多,那么最快捷的角度是什么呢? 在我看来,最快的角度就是判断这个告警邮 ...
- 如何快速排查解决Android中的内存泄露问题
概述 内存泄露是Android开发中比较常见的问题,一旦发生会导致大量内存空间得不到释放,可用内存急剧减少,导致运行卡顿,部分功能不可用甚至引发应用crash.对于复杂度比较高.多人协同开发的项目来讲 ...
- 用于快速排查Java的CPU性能问题(top us值过高)
转载于GIT路径 https://github.com/oldratlee/useful-scripts/blob/master/docs/java.md#beer-show-busy-java-th ...
- 使用consul实现分布式服务注册和发现--redis篇
安装consul client consul 客户端检脚本 ====================================================================== ...
- 如何发现 Redis 热点 Key ,解决方案有哪些?
Java技术栈 www.javastack.cn 优秀的Java技术公众号 来源:http://t.cn/EAEu4to 一.热点问题产生原因 热点问题产生的原因大致有以下两种: 1.1 用户消费的数 ...
- ZABBIX自动发现Redis端口并监控
由于一台服务器开启许多Redis实例,如果一台一台的监控太耗费时间,也非常容器出错.这种费力不讨好的事情我们是坚决杜绝的,幸好ZABBIX有自动发现功能,今天我们就来用该功能来监控我们的Redis实例 ...
- Redis笔记5-redis高可用方案
一.哨兵机制 有了主从复制的实现以后,如果想对主服务器进行监控,那么在redis2.6以后提供了一个"哨兵"的机制.顾名思义,哨兵的含义就是监控redis系统的运行状态.可以启动多 ...
- Redis Cluster集群主从方案
本文介绍一种通过Jedis和Cluster实现Redis集群(主从)的高可用方案,该方案需要使用Jedis2.8.0(推荐),Redis3.0及以上版本(强制). 附:Redis Cluster集群主 ...
随机推荐
- varnish配置语言(2)
目录 1. Backend servers 2. 多个后端 3. Varnish 中的后端服务器和虚拟主机 4. 调度器 5. 健康检查 6. Hashing 7. 优雅模式 Grace mode 和 ...
- flex布局制作自适应网页
网页布局是css的一个重点应用.传统的布局都是依赖display.position.float属性来实现的,但是特殊布局就不易实现,如垂直居中. 01 flex布局是什么? Flex 是 Flexi ...
- 手把手0基础Centos下安装与部署paddleOcr 教程
!!!以下内容为作者原创,首发于个人博客园&掘金平台.未经原作者同意与许可,任何人.任何组织不得以任何形式转载.原创不易,如果对您的问题提供了些许帮助,希望得到您的点赞支持. 0.paddle ...
- elasticsearch常见错误及解决方案
1.OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, th ...
- jenkens安装教程
war包安装方式(linux和windows下) 具体参见:https://www.cnblogs.com/UncleYong/p/10742867.html
- Python基础之创建文件夹与删除文件夹。
参考链接:https://blog.csdn.net/weixin_43826242/article/details/87101436 创建目录结构 # 创建文件目录结构 def create_fol ...
- netcore一键nssm发布为windows服务
AntDeploy 是我开发一款开源一键部署工具包 发布功能支持: docker容器一键部署 docker镜像一键发布 支持iis一键部署 windows服务一键部署 linux服务一键部署 支持增量 ...
- mysql查询拥有某个字段的所有表
前言:最近遇到一个需求,需要给一个数据库所有的表添加一个字段,但是一些后创建的表已经有了这个字段,所以引发了下文. *注释 columnName 字段名 dbName 数据库名 #查询指定库拥有某 ...
- memcache(11211)未授权访问
1.安装Memcache服务端 sudo apt-get install memcached 2.启动服务 sudo memcached -d -m 128 -p 11211 -u root 3.ap ...
- RTB1靶机
一.信息收集 信息收集 http://192.168.111.132/Hackademic_RTB1/?cat=1 http://192.168.111.132/Hackademic_RTB1/?ca ...