Self Attention需要掌握的基本原理
字面意思理解,self attention就是计算句子中每个单词的重要程度。
1. Structure
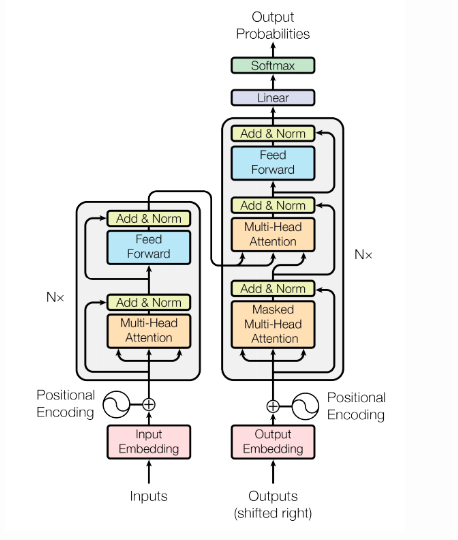
通过流程图,我们可以看出,首先要对输入数据做Embedding
1. 在编码层,输入的word-embedding就是key,value和query,然后做self-attention得到编码层的输出。这一步就模拟了图1中的编码层,输出就可以看成图1中的h。
2. 然后模拟图1中的解码层,解码层的关键是如何得到s,即用来和编码层做attention的query,我们发现,s与上个位置的真实label y,上个位置的s,和当前位置的attention输出c有关,换句话说,位置i的s利用了所有它之前的真实label y信息,和所有它之前位置的attention的输出c信息。label y信息我们全都是已知的,而之前位置的c信息虽然也可以利用,但是我们不能用,因为那样就又不能并行了(因为当前位置的c信息必须等它之前的c信息都计算出来)。于是我们只能用真实label y来模拟解码层的rnn。前面说过,当前位置s使用了它之前的所有真实label y信息。于是我们可以做一个masked attention,即对真实label y像编码层的x一样做self-attention,但每个位置的y只与它之前的y有关(mask),这样,self-attention之后每个位置的输出综合了当前位置和它之前位置的所有y信息,即可做为s(query)。
3. 得到编码层的key和value以及解码层的query后,下面就是模仿vanilla attention,利用key和value以及query再做最后一个attention。得到每个位置的输出。
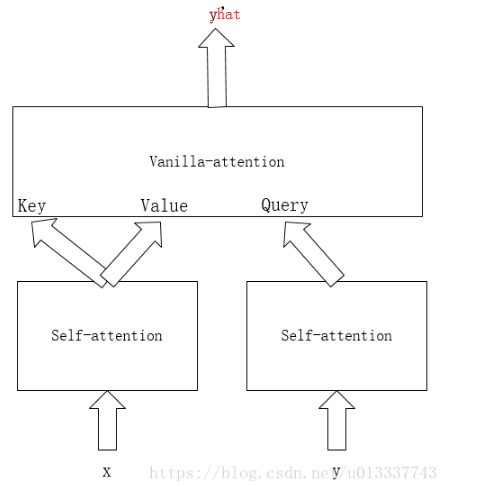
总结起来就是,x做self-attention得到key和value,y做masked self-attention得到query,然后key,value,query做vanilla-attention得到最终输出。
attention中计算Query和Key的相似度,相似度计算方法主要有4中:

2. position embedding
self-attention各个位置可以说是相互独立的,输出只是各个位置的信息加权输出,并没有考虑各个位置的位置信息。因此,Google提出一种pe算法:
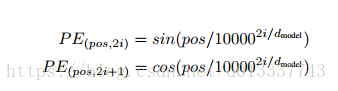
即在偶数位置,此word的pe是sin函数,在奇数位置,word的pe是cos函数。
论文说明了此pe和传统的训练得到的pe效果接近。并且因为 sin(α+β)=sinα cosβ+cosα sinβ 以及 cos(α+β)=cosα cosβ−sinα sinβ,位置 p+k 的向量可以用位置 p 的向量的线性变换表示,这也说明此pe不仅可以表示绝对位置,也能表示相对位置。
最后的embedding为word_embedding+position_embedding。
3. multi-head attention
首先embedding做h次linear projection,每个linear projection的参数不一样,然后做h次attention,最后把h次attention的结果拼接做为最后的输出。
多个attention便于模型学习不同子空间位置的特征表示,然后最终组合起来这些特征,而单头attention直接把这些特征平均,就减少了一些特征的表示可能。
4. Scaled Dot-Product
论文计算query和key相似度使用了dot-product attention,即query和key进行点乘(内积)来计算相似度。
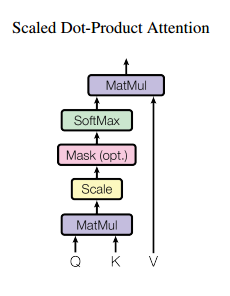
之所以用内积除以维度的开方,论文给出的解释是:假设Q和K都是独立的随机变量,满足均值为0,方差为1,则点乘后结果均值为0,方差为dk。也即方差会随维度dk的增大而增大,而大的方差导致极小的梯度(我认为大方差导致有的输出单元a(a是softmax的一个输出)很小,softmax反向传播梯度就很小(梯度和a有关))。为了避免这种大方差带来的训练问题,论文中用内积除以维度的开方,使之变为均值为0,方差为1。
5. Prediction
训练的时候我们知道全部真实label,但是预测时是不知道的。可以首先设置一个开始符s,然后把其他label的位置设为pad,然后对这个序列y做masked attention,因为其他位置设为了pad,所以attention只会用到第一个开始符s,然后用masked attention的第一个输出做为query和编码层的输出做普通attention,得到第一个预测的label y,然后把预测出的label加入到初始序列y中的相应位置,然后再做masked attention,这时第二个位置就不再是pad,那么attention层就会用到第二个位置的信息,依此循环,最后得到所有的预测label y。其实这样做也是为了模拟传统attention的解码层(当前位置只能用到前面位置的信息)。
Summary
self-attention层的好处是能够一步到位捕捉到全局的联系,解决了长距离依赖,因为它直接把序列两两比较(代价是计算量变为 O(n2),当然由于是纯矩阵运算,这个计算量相当也不是很严重),而且最重要的是可以进行并行计算。
相比之下,RNN 需要一步步递推才能捕捉到,并且对于长距离依赖很难捕捉。而 CNN 则需要通过层叠来扩大感受野,这是 Attention 层的明显优势。
self-attention其实和cnn,rnn一样,也是为了对输入进行编码,为了获得更多的信息。所以应把self-attention也看成网络中的一个层加进去。
Refrence
2. attention model–Neural machine translation by jointly learning to align and translate论文解读
3. self-attention----Attention is all you need 论文解读
Self Attention需要掌握的基本原理的更多相关文章
- attention、self-attention、transformer和bert模型基本原理简述笔记
attention 以google神经机器翻译(NMT)为例 无attention: encoder-decoder在无attention机制时,由encoder将输入序列转化为最后一层输出state ...
- attention 汇总(持续)
Seq2seq Attention Normal Attention 1. 在decoder端,encoder state要进行一个线性变换,得到r1,可以用全连接,可以用conv,取决于自己,这里 ...
- 深入理解Attention机制
要了解深度学习中的注意力模型,就不得不先谈Encoder-Decoder框架,因为目前大多数注意力模型附着在Encoder-Decoder框架下,当然,其实注意力模型可以看作一种通用的思想,本身并不依 ...
- Task9.Attention
注意力模型最近几年在深度学习各个领域被广泛使用,无论是图像处理.语音识别还是自然语言处理的各种不同类型的任务中,都很容易遇到注意力模型的身影.所以,了解注意力机制的工作原理对于关注深度学习技术发展的技 ...
- [论文阅读] Residual Attention(Multi-Label Recognition)
Residual Attention 文章: Residual Attention: A Simple but Effective Method for Multi-Label Recognition ...
- 论文解读(GSAT)《Interpretable and Generalizable Graph Learning via Stochastic Attention Mechanism》
论文信息 论文标题:Interpretable and Generalizable Graph Learning via Stochastic Attention Mechanism论文作者:Siqi ...
- Ognl表达式基本原理和使用方法
Ognl表达式基本原理和使用方法 1.Ognl表达式语言 1.1.概述 OGNL表达式 OGNL是Object Graphic Navigation Language(对象图导航语言)的缩写,他是一个 ...
- Android自定义控件之基本原理
前言: 在日常的Android开发中会经常和控件打交道,有时Android提供的控件未必能满足业务的需求,这个时候就需要我们实现自定义一些控件,今天先大致了解一下自定义控件的要求和实现的基本原理. 自 ...
- HMM基本原理及其实现(隐马尔科夫模型)
HMM(隐马尔科夫模型)基本原理及其实现 HMM基本原理 Markov链:如果一个过程的“将来”仅依赖“现在”而不依赖“过去”,则此过程具有马尔可夫性,或称此过程为马尔可夫过程.马尔可夫链是时间和状态 ...
随机推荐
- Nginx之 try_files 指令
location / { try_files $uri $uri/ /index.php; } 当用户请求 http://localhost/example 时,这里的 $uri 就是 /exampl ...
- Linux网络编程学习(九) ----- 消息队列(第四章)
1.System V IPC System V中引入的几种新的进程间通信方式,消息队列,信号量和共享内存,统称为System V IPC,其具体实例在内核中是以对象的形式出现的,称为IPC 对象,每个 ...
- logging-----日志模块
import logging #creat logger 第一步,创建一个记录器 logging_name = 'test' logger = logging.getLogger(logging_na ...
- Windows下pip 离线包安装
pip在线安装十分方便,有时候某些服务器并没有直接联网,需要下载好安装包上传到服务器上进行安装,不经常用,还是有点小麻烦的. 安装Python之后,将下载好的安装包包放在Python安装的根目录下使用 ...
- jsp Servlet 文件上传
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding= ...
- validate表单验证
validate使用步骤:1.导入jquery.js2.导入validate.js3.在页面加载成功之后 对表单进行校验 $("选择器").validate()4.在valida ...
- 微信小程序创建一个新项目
1. 新建一个文件夹. 2. 打开微信小程序开发工具,导入新建文件夹:然后输入创建的appId:会自动生成一个project.config.json,打开这个文件,会看到appid这个字段. 3.可以 ...
- python入门(十):模块、包
模块:py文件包:目录,目录里面包含__init__.py,内容可以是空里面可以包含多个模块文件,还可以包含子包 1.模块和包,可以很方便的提供给其他程序以复用 1) 利于组织复杂工程 我们写代码的时 ...
- 基于springboot的SSM框架实现返回easyui-tree所需要数据
1.easyui-tree easui-tree目所需要的数据结构类型如下: [ { "children": [ { "children": [], " ...
- Shell 运算相关
一.${str} 二.变量替换 三.3种计算字符串长度的效率比较 四.(())用法 五.expr 六.bc 4种连续整数求和效率 七.条件测试 八.字符串测试