PubMed数据下载
目标站点分析
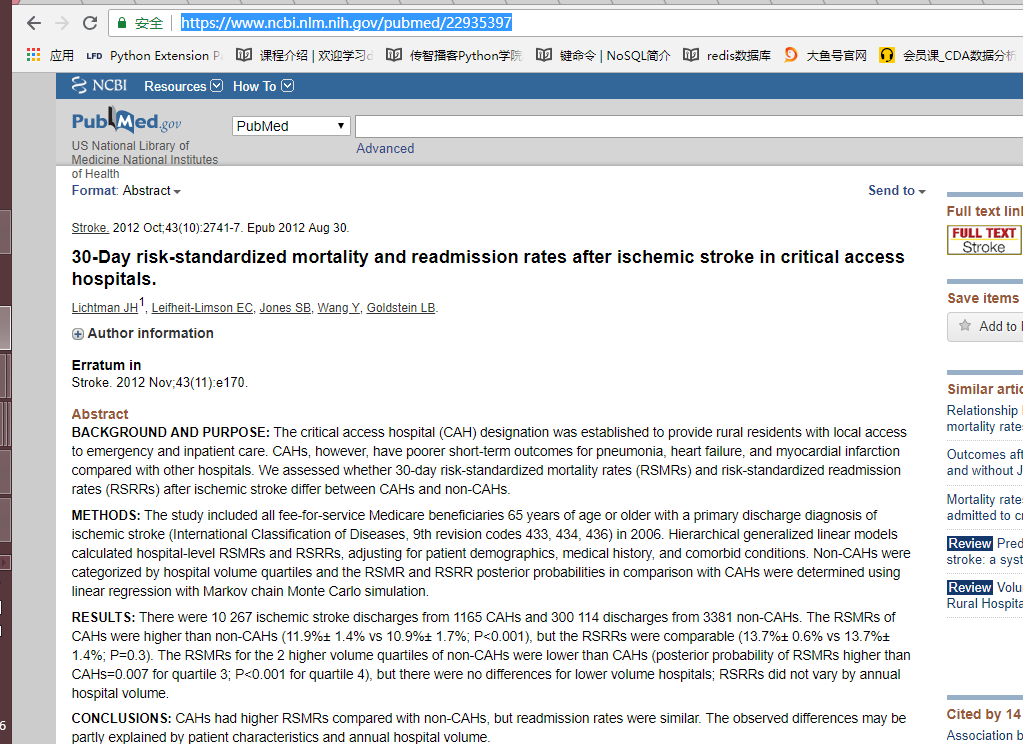
目标:抓取页面中的机构名称,日期,标题,作者, 作者信息, 摘要
程序实现
# -*- coding: utf-8 -*- """
@Datetime: 2019/3/6
@Author: Zhang Yafei
"""
import os
import re
import time
from concurrent.futures import ThreadPoolExecutor
import traceback import pandas as pd
import requests
from pyquery import PyQuery as pq headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'} BASE_DIR = 'html' if not os.path.exists(BASE_DIR):
os.mkdir(BASE_DIR) class PubMed(object):
def __init__(self, url):
self.url = url
# self.url = 'https://www.ncbi.nlm.nih.gov/pubmed/{}'.format(id)
self.retry = 0 def download(self):
try:
response = requests.get(self.url, headers=headers, timeout=20)
if response.status_code == 200:
self.parse(response.content)
except Exception as e:
traceback.print_exc()
print('error:' + self.url)
while True:
self.retry += 1
if self.retry < 5:
try:
response = requests.get(self.url, headers=headers, timeout=15)
if response.status_code == 200:
self.parse(response.content)
return
except Exception as e:
print(e)
time.sleep(10)
else:
print(self.url + '下载失败')
return def parse(self, response):
doc = pq(response, parser='html')
periodical_item = doc('.cit')
periodical = periodical_item.children().text()
try:
periodical_datetime = re.search('</a>(.*?);', periodical_item.__str__()).group(1)
except AttributeError:
periodical_datetime = re.search('</a>(.*?).', periodical_item.__str__()).group(1)
title = doc('.rprt_all h1').text()
authors_items = doc('.auths a').items()
authors = ','.join(list(map(lambda x: x.text(), authors_items)))
author_info = doc('.ui-ncbi-toggler-slave dd').text()
abstract = doc('.abstr').text()
data_dict = {'url': [self.url], 'periodical': [periodical], 'periodical_datetime': [periodical_datetime],
'title': [title], 'authors': [authors], 'author_info': [author_info], 'abstract': [abstract]}
self.write_csv(filename='pubmed_result.csv', data=data_dict)
print(self.url + '下载完成') @staticmethod
def write_csv(filename, data=None, columns=None, header=False):
""" 写入 """
if header:
df = pd.DataFrame(columns=columns)
df.to_csv(filename, index=False, mode='w')
else:
df = pd.DataFrame(data=data)
df.to_csv(filename, index=False, header=False, mode='a+') def filter_url_list(urls_list):
df = pd.read_csv('pubmed_result.csv')
has_urls = df.url.tolist()
url_list = set(urls_list) - set(has_urls)
print('共:{} 完成:{} 还剩:{}'.format(len(urls_list), len(has_urls), len(url_list)))
return list(url_list) def read_data():
df = pd.read_excel('data.xlsx', header=None)
return df[0].tolist() def main(url):
""" 主函数 """
pubmed = PubMed(url=url)
pubmed.download() if __name__ == '__main__':
url_list = read_data()
if not os.path.exists('pubmed_result.csv'):
columns = ['url', 'periodical', 'periodical_datetime', 'title', 'authors', 'author_info', 'abstract']
PubMed.write_csv(filename='pubmed_result.csv', columns=columns, header=True)
else:
url_list = filter_url_list(url_list) pool = ThreadPoolExecutor()
pool.map(main, url_list)
pool.shutdown() # 写入excel
df = pd.read_csv('pubmed_result.csv')
writer = pd.ExcelWriter('pubmed_result.xlsx')
df.to_excel(writer, 'table', index=False)
writer.save()
PubMed数据下载的更多相关文章
- tensorflow学习笔记三:实例数据下载与读取
一.mnist数据 深度学习的入门实例,一般就是mnist手写数字分类识别,因此我们应该先下载这个数据集. tensorflow提供一个input_data.py文件,专门用于下载mnist数据,我们 ...
- ios的网络数据下载和json解析
ios的网络数据下载和json解析 简介 在本文中,笔者将要给大家介绍如何使用nsurlconnection 从网上下载数据,以及解析json数据格式,以及如何显示数据和图片的异步下载显示. 涉及的知 ...
- 腾讯QQ群数据下载方法(7000万个qq群资料全泄漏)
仔细读完一定能找到自己需要的东西 据新华网报道,国内知名安全漏洞监测平台乌云20日公布报告称,腾讯QQ群关系数据被泄露,网上可以轻易就能找到数据下载链接,根据这些数据,通过QQ号可以查询到备注姓名.年 ...
- ios 网络数据下载和JSON解析
ios 网络数据下载和JSON解析 简介 在本文中笔者将要给大家介绍ios中如何利用NSURLConnection从网络上下载数据,如何解析下载下来的JSON数据格式,以及如何显示数据和图片的异步下载 ...
- iOS之网络数据下载和JSON解析
iOS之网络数据下载和JSON解析 简介 在本文中笔者将要给大家介绍IOS中如何利用NSURLconnection从网络上下载数据以及如何解析下载下来的JSON数据格式,以及如何显示数据和托图片的异步 ...
- Asp.Net MVC 实现将Easy-UI展示数据下载为Excel 文件
在一个项目中,需要做一个将Easy-UI界面展示数据下载为Excel文件的功能,经过一段时间努力,完成了一个小Demo.界面如下: 但按下导出Excel后,Excel文件将会下载到本地,在office ...
- OSM数据下载地址
1.OSM数据下载地址 官网下载: http://planet.openstreetmap.org/ GeoFabrik:http://www.geofabrik.de/ Metro Extracts ...
- 医学图像数据(三)——TCIA部分数据下载方式
前为止,本人还没有找到不需要账号的就可以部分下载的方式,因此这里讲的是需要注册账号下载部分数据的方法. 注意:下载部分数据需要注册账号 注册账号网址:https://public.cancerimag ...
- DEM数据及其他数据下载
GLCF大家都知道吧?http://glcf.umiacs.umd.edu/data/ +++++++++++++++去年12月份听遥感所一老师说TM08初将上网8万景,可是最近一直都没看到相关的网页 ...
随机推荐
- Spring MVC启动过程(1):ContextLoaderListener初始化
此文来自https://my.oschina.net/pkpk1234/blog/61971 (写的特别好)故引来借鉴 Spring MVC启动过程 以Tomcat为例,想在Web容器中使用Spirn ...
- Android 永久保存简单数据
转载: http://blog.csdn.net/xzlawin/article/details/45959033 方法1: 存数据: SharedPreferences userInfo = thi ...
- SpringBoot添加CORS跨域
配置CORSConfiguration 添加CORS的配置信息,我们创建一个CORSConfiguration配置类重写如下方法,如图所示: @Override public void addCors ...
- Matplotlib学习---用wordcloud画词云(Word Cloud)
画词云首先需要安装wordcloud(生成词云)和jieba(中文分词). 先来说说wordcloud的安装吧,真是一波三折.首先用pip install wordcloud出现错误,说需要安装Vis ...
- 【BZOJ1004】【HNOI2008】Cards 群论 置换 burnside引理 背包DP
题目描述 有\(n\)张卡牌,要求你给这些卡牌染上RGB三种颜色,\(r\)张红色,\(g\)张绿色,\(b\)张蓝色. 还有\(m\)种洗牌方法,每种洗牌方法是一种置换.保证任意多次洗牌都可用这\( ...
- 【BZOJ1426】收集邮票 期望DP
题目大意 有\(n\)种不同的邮票,皮皮想收集所有种类的邮票.唯一的收集方法是到同学凡凡那里购买,每次只能买一张,并且买到的邮票究竟是\(n\)种邮票中的哪一种是等概率的,概率均为\(\frac{1} ...
- 百度APP爬虫
1.抓包 访问一个频道,Charles抓包,找到真实连接,一般返回json数据和网页中数据对应为真实连接 请求方式为post,所以要添加请求头和表单数据,由于在charles环境下,所以要添加char ...
- HAOI2018 简要题解
这套题是 dy, wearry 出的.学长好强啊,可惜都 \(wc\) 退役了.. 话说 wearry 真的是一个计数神仙..就没看到他计不出来的题...每次考他模拟赛总有一两道毒瘤计数TAT 上午的 ...
- Leetcode 209.长度最小的子数组 By Python
给定一个含有 n 个正整数的数组和一个正整数 s ,找出该数组中满足其和 ≥ s 的长度最小的连续子数组.如果不存在符合条件的连续子数组,返回 0. 示例: 输入: s = 7, nums = [2, ...
- 【BZOJ2125】最短路(仙人掌,圆方树)
[BZOJ2125]最短路(仙人掌,圆方树) 题面 BZOJ 求仙人掌上两点间的最短路 题解 终于要构建圆方树啦 首先构建出圆方树,因为是仙人掌,和一般图可以稍微的不一样 直接\(tarjan\)缩点 ...