057 Java中kafka的Producer程序实现
1.需要启动的服务
这里启动的端口是9092。
bin/kafka-console-consumer.sh --topic beifeng --zookeeper linux-hadoop01.ibeifeng.com:2181/kafka
2.producer的程序
package com.jun.it;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
import java.util.Properties;
import java.util.Random;
import java.util.concurrent.atomic.AtomicBoolean;
public class JavaKafkaProducer {
public static final char[] chars = "qazwsxedcrfvtgbyhnujmikolp0123456789".toCharArray();
public static final int charsLength = chars.length;
public static final Random random = new Random(System.currentTimeMillis());
private Producer<String, String> producer = null; private String topicName = null;
private String brokerList = null;
private boolean isSync = true; // 默认为同步 /**
* 构造函数
*
* @param topicName
* @param brokerList
*/
public JavaKafkaProducer(String topicName, String brokerList) {
this(topicName, brokerList, true);
} /**
* 构造函数,主要是产生producer
*
* @param topicName
* @param brokerList
* @param isSync
*/
public JavaKafkaProducer(String topicName, String brokerList, boolean isSync) {
// 赋值
this.topicName = topicName;
this.brokerList = brokerList;
this.isSync = isSync; // 1. 给定配置信息:参考http://kafka.apache.org/082/documentation.html#producerconfigs
Properties props = new Properties();
// kafka集群的连接信息
props.put("metadata.broker.list", this.brokerList);
// kafka发送数据方式
if (this.isSync) {
// 同步发送数据
props.put("producer.type", "sync");
} else {
// 异步发送数据
props.put("producer.type", "async");
/**
* 0: 不等待broker的返回
* 1: 表示至少等待1个broker返回结果
* -1:表示等待所有broker返回数据接收成功的结果
*/
props.put("request.required.acks", "0");
}
// key/value数据序列化的类
/**
* 默认是:DefaultEncoder, 指发送的数据类型是byte类型
* 如果发送数据是string类型,必须更改StringEncoder
*/
props.put("serializer.class", "kafka.serializer.StringEncoder"); // 2. 构建Kafka的Producer Configuration上下文
ProducerConfig config = new ProducerConfig(props); // 3. 构建Kafka的生产者:Producerr
this.producer = new Producer<String, String>(config);
} /**
* 关闭producer连接
*/
public void closeProducer() {
producer.close();
} /**
* 提供给外部应用调用的直接运行发送数据代码的方法
*
* @param threadNumbers
* @param isRunning
*/
public void run(int threadNumbers, final AtomicBoolean isRunning) {
for (int i = 0; i < threadNumbers; i++) {
new Thread(new Runnable() {
public void run() {
int count = 0;
while (isRunning.get()) {
// 只有在运行状态的情况下,才发送数据
KeyedMessage<String, String> message = generateMessage();
// 发送数据
producer.send(message);
count++;
// 打印一下
if (count % 100 == 0) {
System.out.println("Count = " + count + "; message:" + message);
} // 假设需要休息一下
try {
Thread.sleep(random.nextInt(100) + 10);
} catch (InterruptedException e) {
// nothings
}
}
System.out.println("Thread:" + Thread.currentThread().getName() + " send message count is:" + count);
}
}).start();
}
} /**
* 产生一个随机的Kafka的KeyedMessage对象
*
* @return
*/
public KeyedMessage<String, String> generateMessage() {
String key = generateString(3) + "_" + random.nextInt(10);
StringBuilder sb = new StringBuilder();
int numWords = random.nextInt(5) + 1; // [1,5]单词
for (int i = 0; i < numWords; i++) {
String word = generateString(random.nextInt(5) + 1); // 单词中字符最少1个最多5个
sb.append(word).append(" ");
}
String message = sb.toString().trim();
return new KeyedMessage(this.topicName, key, message);
} /**
* 随机生产一个给定长度的字符串
*
* @param numItems
* @return
*/
public static String generateString(int numItems) {
StringBuilder sb = new StringBuilder();
for (int i = 0; i < numItems; i++) {
sb.append(chars[random.nextInt(charsLength)]);
}
return sb.toString();
}
}
3.测试类
package com.jun.it;
import java.util.concurrent.atomic.AtomicBoolean;
public class JavaKafkaProducerTest {
public static void main(String[] args) {
String topicName = "beifeng";
String brokerList = "linux-hadoop01.ibeifeng.com:9092,linux-hadoop01.ibeifeng.com:9093";
int threadNums = 10;
AtomicBoolean isRunning = new AtomicBoolean(true);
JavaKafkaProducer producer = new JavaKafkaProducer(topicName, brokerList);
producer.run(threadNums, isRunning);
// 停留60秒后,进行关闭操作
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// nothings
}
isRunning.set(false);
// 关闭连接
producer.closeProducer();
}
}
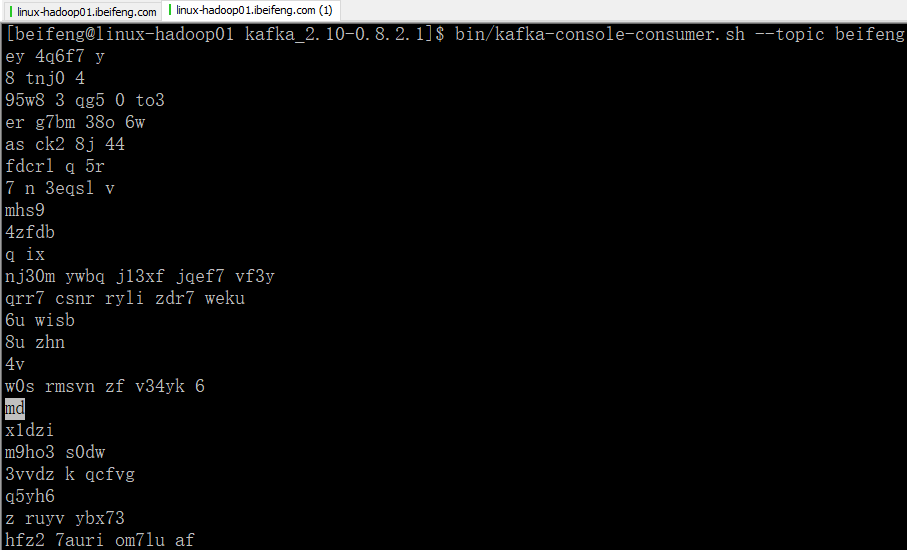
4.效果
二:使用自定义的分区器
1.分区器
package com.jun.it; import kafka.producer.Partitioner;
import kafka.utils.VerifiableProperties; public class JavaKafkaPartitioner implements Partitioner {
/**
* 默认无参构造函数
*/
public JavaKafkaPartitioner() {
this(new VerifiableProperties());
} /**
* 该构造函数必须给定
*
* @param properties 初始化producer的时候给定的配置信息
*/
public JavaKafkaPartitioner(VerifiableProperties properties) {
// nothings
} @Override
public int partition(Object key, int numPartitions) {
String tmp = (String) key;
int index = tmp.lastIndexOf('_');
int number = Integer.valueOf(tmp.substring(index + 1));
return number % numPartitions;
}
}
2.producer类重新修改
package com.jun.it;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
import java.util.Properties;
import java.util.Random;
import java.util.concurrent.atomic.AtomicBoolean;
public class JavaKafkaProducer {
public static final char[] chars = "qazwsxedcrfvtgbyhnujmikolp0123456789".toCharArray();
public static final int charsLength = chars.length;
public static final Random random = new Random(System.currentTimeMillis());
private Producer<String, String> producer = null; private String topicName = null;
private String brokerList = null;
private boolean isSync = true; // 默认为同步
private String partitionerClass = null; // 数据分区器class类 /**
* 构造函数
*
* @param topicName
* @param brokerList
*/
public JavaKafkaProducer(String topicName, String brokerList) {
this(topicName, brokerList, true, null);
} /**
* 构造函数
*
* @param topicName
* @param brokerList
* @param partitionerClass
*/
public JavaKafkaProducer(String topicName, String brokerList, String partitionerClass) {
this(topicName, brokerList, true, partitionerClass);
} /**
* 构造函数,主要是产生producer
*
* @param topicName
* @param brokerList
* @param isSync
*/
public JavaKafkaProducer(String topicName, String brokerList, boolean isSync, String partitionerClass) {
// 赋值
this.topicName = topicName;
this.brokerList = brokerList;
this.isSync = isSync;
this.partitionerClass = partitionerClass; // 1. 给定配置信息:参考http://kafka.apache.org/082/documentation.html#producerconfigs
Properties props = new Properties();
// kafka集群的连接信息
props.put("metadata.broker.list", this.brokerList);
// kafka发送数据方式
if (this.isSync) {
// 同步发送数据
props.put("producer.type", "sync");
} else {
// 异步发送数据
props.put("producer.type", "async");
/**
* 0: 不等待broker的返回
* 1: 表示至少等待1个broker返回结果
* -1:表示等待所有broker返回数据接收成功的结果
*/
props.put("request.required.acks", "0");
}
// key/value数据序列化的类
/**
* 默认是:DefaultEncoder, 指发送的数据类型是byte类型
* 如果发送数据是string类型,必须更改StringEncoder
*/
props.put("serializer.class", "kafka.serializer.StringEncoder"); // 给定分区器的class参数
if (this.partitionerClass != null && !this.partitionerClass.trim().isEmpty()) {
// 默认是:DefaultPartiioner,基于key的hashCode进行hash后进行分区
props.put("partitioner.class", this.partitionerClass.trim());
} // 2. 构建Kafka的Producer Configuration上下文
ProducerConfig config = new ProducerConfig(props); // 3. 构建Kafka的生产者:Producerr
this.producer = new Producer<String, String>(config);
} /**
* 关闭producer连接
*/
public void closeProducer() {
producer.close();
} /**
* 提供给外部应用调用的直接运行发送数据代码的方法
*
* @param threadNumbers
* @param isRunning
*/
public void run(int threadNumbers, final AtomicBoolean isRunning) {
for (int i = 0; i < threadNumbers; i++) {
new Thread(new Runnable() {
public void run() {
int count = 0;
while (isRunning.get()) {
// 只有在运行状态的情况下,才发送数据
KeyedMessage<String, String> message = generateMessage();
// 发送数据
producer.send(message);
count++;
// 打印一下
if (count % 100 == 0) {
System.out.println("Count = " + count + "; message:" + message);
} // 假设需要休息一下
try {
Thread.sleep(random.nextInt(100) + 10);
} catch (InterruptedException e) {
// nothings
}
}
System.out.println("Thread:" + Thread.currentThread().getName() + " send message count is:" + count);
}
}).start();
}
} /**
* 产生一个随机的Kafka的KeyedMessage对象
*
* @return
*/
public KeyedMessage<String, String> generateMessage() {
String key = generateString(3) + "_" + random.nextInt(10);
StringBuilder sb = new StringBuilder();
int numWords = random.nextInt(5) + 1; // [1,5]单词
for (int i = 0; i < numWords; i++) {
String word = generateString(random.nextInt(5) + 1); // 单词中字符最少1个最多5个
sb.append(word).append(" ");
}
String message = sb.toString().trim();
return new KeyedMessage(this.topicName, key, message);
} /**
* 随机生产一个给定长度的字符串
*
* @param numItems
* @return
*/
public static String generateString(int numItems) {
StringBuilder sb = new StringBuilder();
for (int i = 0; i < numItems; i++) {
sb.append(chars[random.nextInt(charsLength)]);
}
return sb.toString();
}
}
3.测试类
package com.jun.it;
import java.util.concurrent.atomic.AtomicBoolean;
public class JavaKafkaProducerTest {
public static void main(String[] args) {
String topicName = "beifeng";
String brokerList = "linux-hadoop01.ibeifeng.com:9092,linux-hadoop01.ibeifeng.com:9093";
String partitionerClass = "com.jun.it.JavaKafkaPartitioner";
int threadNums = 10;
AtomicBoolean isRunning = new AtomicBoolean(true);
JavaKafkaProducer producer = new JavaKafkaProducer(topicName, brokerList,partitionerClass);
producer.run(threadNums, isRunning);
// 停留60秒后,进行关闭操作
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// nothings
}
isRunning.set(false);
// 关闭连接
producer.closeProducer();
}
}
4.效果

057 Java中kafka的Producer程序实现的更多相关文章
- java中子类继承父类程序执行顺序
java中子类继承父类程序执行顺序 FatherTest.java public class FatherTest { private String name; public FatherTest() ...
- java中子类继承父类程序执行顺序问题
Java中,new一个类的对象,类里面的静态代码块.非静态代码.无参构造方法.有参构造方法.类的一般方法等部分,它们的执行顺序相对来说比较简单,用程序也很容易验证.比如新建一个测试父类. public ...
- 对上次“对字符串进行简单的字符数字统计 探索java中的List功能 ”程序,面向对象的改进
之前的随笔中的程序在思考后发现,运用了太多的static 函数,没有将面向对象的思想融入,于是做出了一下修改: import java.util.ArrayList; import java.util ...
- Java 中,编写多线程程序的时候你会遵循哪些最佳实践?
这是我在写 Java 并发程序的时候遵循的一些最佳实践: a)给线程命名,这样可以帮助调试. b)最小化同步的范围,而不是将整个方法同步,只对关键部分做同步. c)如果可以,更偏向于使用 volati ...
- JAVA中处理事务的程序--多条更新SQL语句的执行(包括回滚)
在与数据库操作时,如果执行多条更新的SQL语句(如:update或insert语句),在执行第一条后如果出现异常或电脑断电, 则后面的SQL语句执行不了,这时候设定我们自己提交SQL语句,不让JDBC ...
- Java中native关键字
Java中native关键字 标签: Java 2016-08-17 11:44 54551人阅读 评论(0) 顶(23453) 收藏(33546) 今日在hibernate源代码中遇到了nati ...
- Java中long类型直接赋值大数字 注意事项
在java中,我们都知道有八种基本数据类型:byte. char. short .int. long. float. double .boolean 下面列出以下四种数据类型及其取值范围: 本文主要讲 ...
- Java中native的用法
原文来自:http://blog.csdn.net/funneies/article/details/8949660 native关键字说明其修饰的方法是一个原生态方法,方法对应的实现不是在当前文件, ...
- 关于JAVA中的static方法、并发问题以及JAVA运行时内存模型
一.前言 最近在工作上用到了一个静态方法,跟同事交流的时候,被一个问题给问倒了,只怪基础不扎实... 问题大致是这样的,“在多线程环境下,静态方法中的局部变量会不会被其它线程给污染掉?”: 我当时的想 ...
随机推荐
- PHP针对数字的加密解密类,可直接使用
<?phpnamespace app;/** * 加密解密类 * 该算法仅支持加密数字.比较适用于数据库中id字段的加密解密,以及根据数字显示url的加密. * @author 深秋的竹子 * ...
- 排查linux系统是否被入侵
在日常繁琐的运维工作中,对linux服务器进行安全检查是一个非常重要的环节.今天,分享一下如何检查linux系统是否遭受了入侵? 一.是否入侵检查 1)检查系统日志 检查系统错误登陆日志,统计IP重试 ...
- 如何快速定位找出SEGV内存错误的程序Bug
通过查看php日志/usr/local/php/var/log/php-fpm.log,有如下警告信息: [16-Mar-2015 16:03:09] WARNING: [pool www] chil ...
- GZip使用
class Program { static void Main(string[] args) { //Trace.Listeners.Clear(); //Trace.Listeners.Add(n ...
- 在 Confluence 中启用 HTTP 响应压缩
Confluence 能够支持 HTTP 的 GZip 传输编码.这个意味着 Confluence 将可以把数据压缩后传输给用户,这种配置能够针对不稳定的互联网状态下的传输速度缓慢和不稳定并且能够降低 ...
- Vue.js结合vue-router和webpack编写单页路由项目
一.前提 1. 安装了node.js. 2. 安装了npm. 3. 检查是否安装成功: 打开cmd,输入node,没有报“node不是内部或外部命令”表示安装成功node.js. 打开cmd,输入np ...
- js模块化编程之CommonJS和AMD/CMD
js模块化编程commonjs.AMD/CMD与ES6模块规范 一.CommonJS commonjs的require是运行时同步加载,es6的import是静态分析,是在编译时而不是在代码运行时.C ...
- JMeter进行一次简单的压力测试
测试目的:10个用户并发打开百度首页(https://www.baidu.com/),百度能否正常响应. 操作步骤 一.打开JMeter 打开后的界面如下: 二.右击“测试计划”,添加线程组 三.设置 ...
- AD9361框图
1. Fir滤波器的阶数为64或128 而内插或抽取因子为:1.2或4. HB1和HB2的内插或抽取因子为1或2而HB3的因子为1.2或3 BB_LPF为:三阶巴特沃斯低通滤波器,3dB点频率可编程, ...
- Git 在webstrom上安装git
Git下载地址:https://git-scm.com/download/win 用webstorm迁入迁出代码时,首先要先下载git,网址一搜就可以搜到,然后开始配置webstorm,打开webst ...