007 linux环境下的伪分布式环境搭建
本文的配置环境是VMware10+centos2.5。
在学习大数据过程中,首先是要搭建环境,通过实验,在这里简短粘贴书写关于自己搭建大数据伪分布式环境的经验。
如果感觉有问题,欢迎咨询评论。
零:下载ruanjian
1.下载
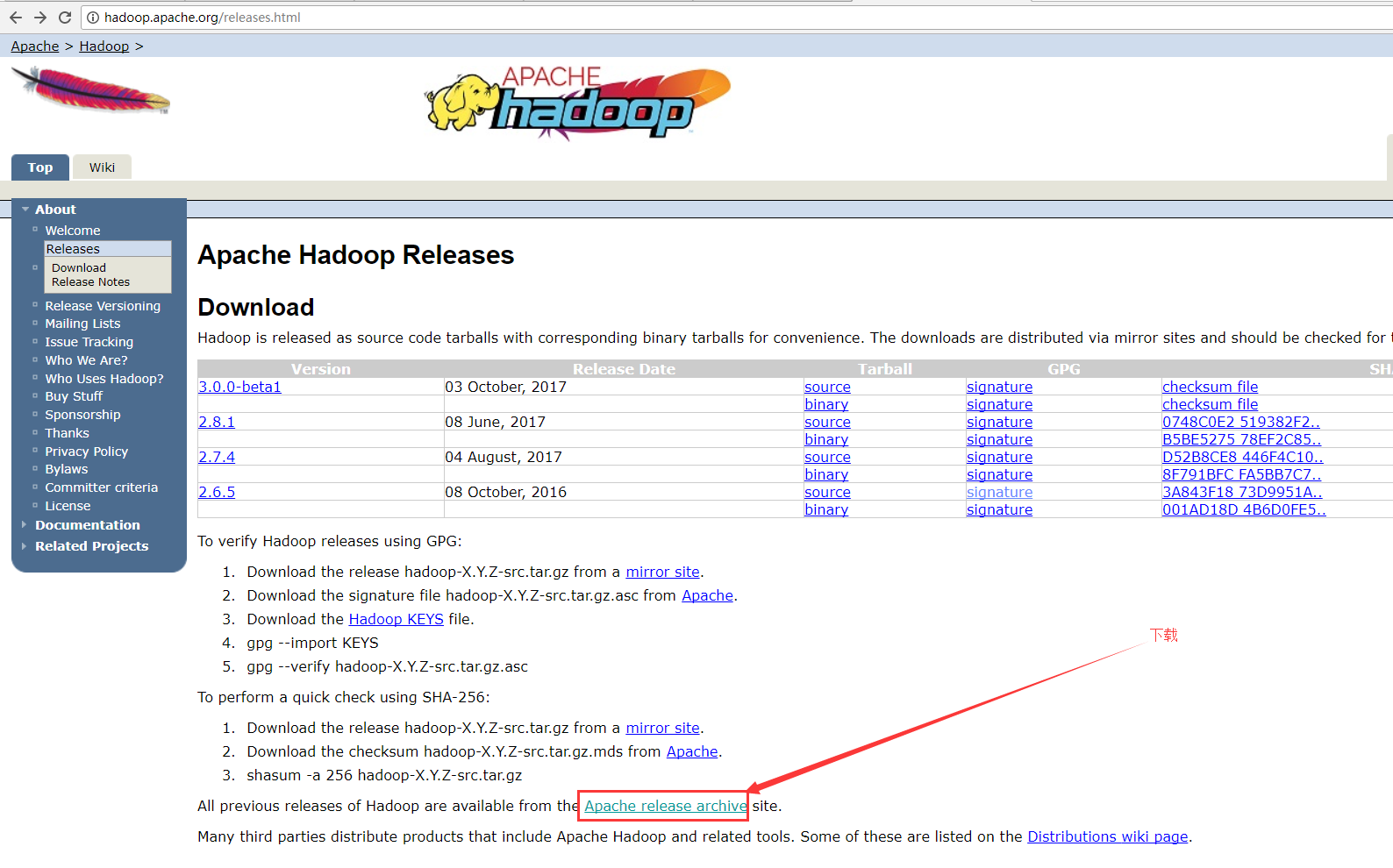
2.下载网址
https://archive.apache.org/dist/hadoop/common/
一:伪分布式准备工作
1.规划目录

2.修改目录所有者和所属组

3.删除原有的jdk

4.上传需要的jdk包

5.增加jdk 的执行权限

6.解压jdk

7.修改profile的JAVA_HOME,PATH

8.使文件生效
不需要使用root用户。

9.检验jdk是否成功

二:搭建为分布式(主要是namenode与datanode)
1.解压hadoop

2.进入hadoop主目录

3.获取JAVA_HOME的目录

4.*.env.sh
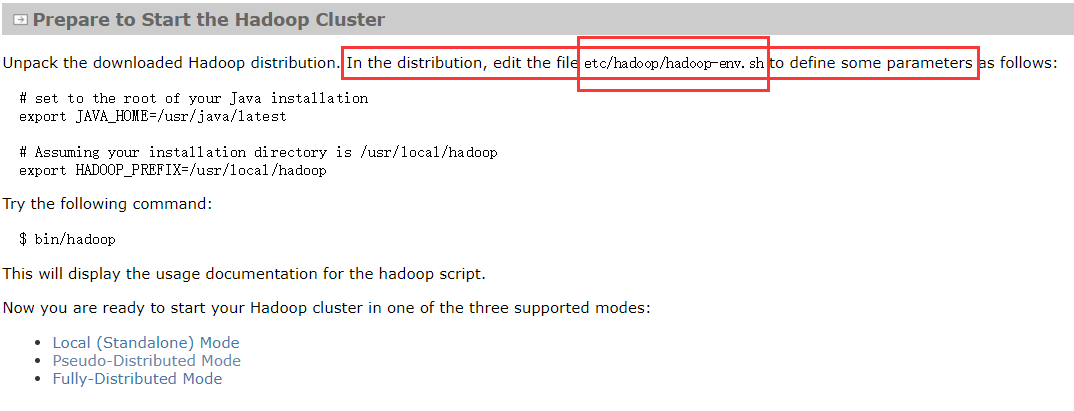
5.修改hadoop-env.sh的JAVA_HOME

6.修改mapred-env.h的JAVA_HOME
虽然官网没说,但是也需要修改。

7.修改yarn-env.sh的JAVA_HOME
虽然官网没说,但是也需要修改。

8.*-site.xml配置
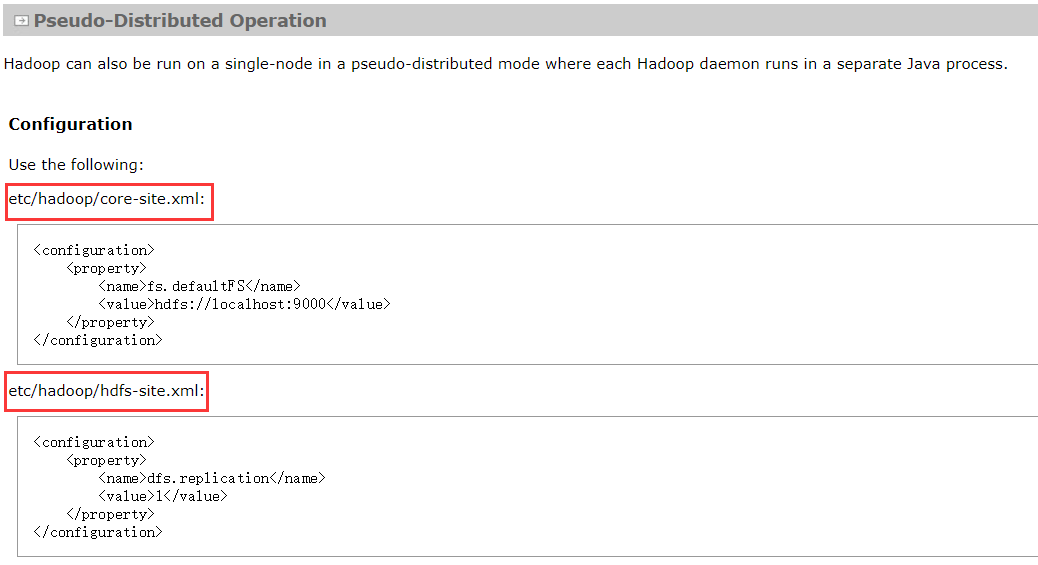
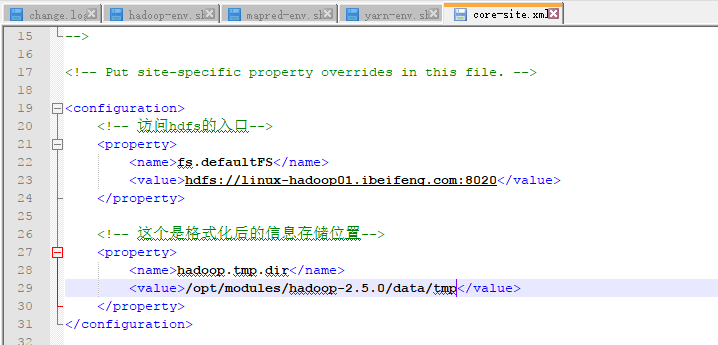
9.配置core-site.xml
8020是交互端口,namenode启动以后,可以通过浏览器进行访问hdfs文件系统。
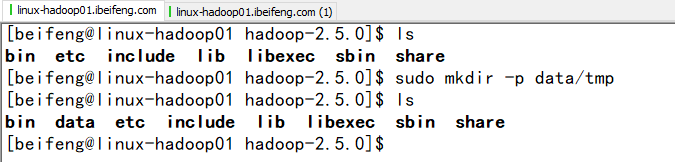
新建一个临时目录:
注意点:sudo chown -R beifeng:beifeng data
配置:
10.修改slave的配置

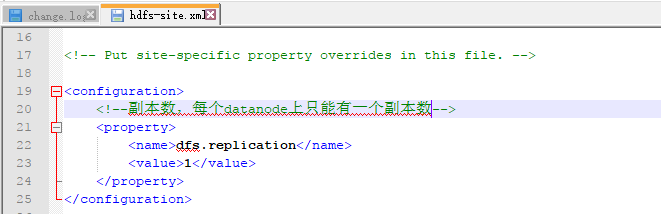
11.修改hdfs.site.xml
12.执行

13.检验hdfs

14.格式化hdfs
对文件操作系统进行格式化。


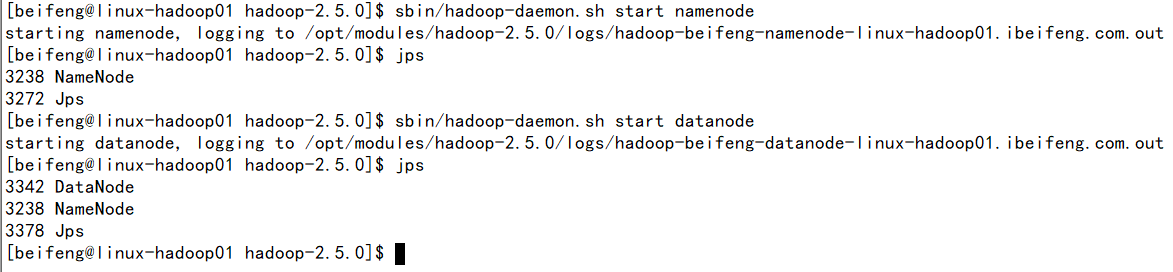
15.启动namenode 以及datanode进程
注意:
sudo chmod -R a+w hadoop-2.5.0/ 增加权限,因为要产生log文件夹。
16.查看浏览器,方便管理HDFS
http://linux-hadoop01.ibeifeng.com:50070/

17.在HDFS上新建文件夹


15.在HDFS上上传文件


16.在HDFS上读取wenjian

17.在HDFS上下载文件到本地

18.删除在HDFS上的文件
bin/hdfs dfs -rm -f core-site.xml
如果不知道可以使用bin/hdfs dfs ,在确认后就弹出使用方法
三:继续搭建伪分布式(YARN部分的搭建)
1.官网
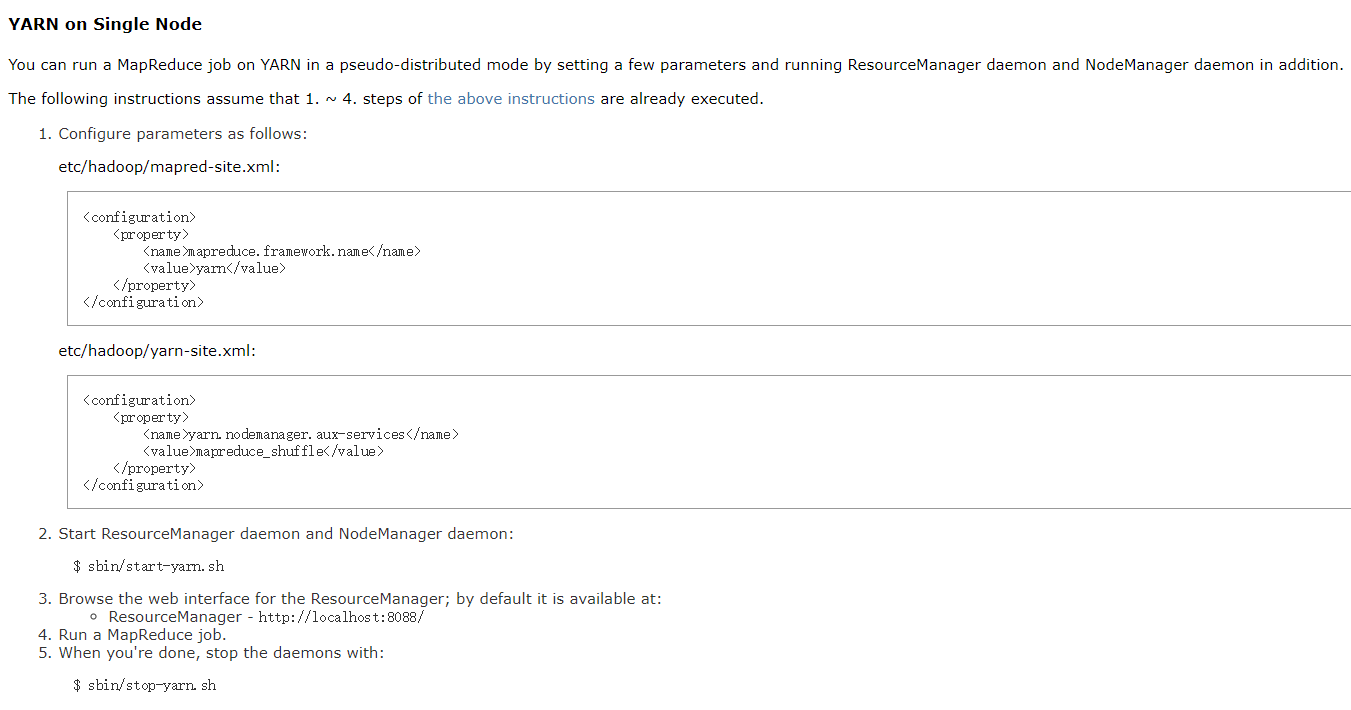
2.配置yarn-site.xml

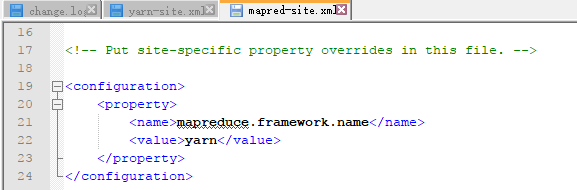
2..配置MapReduce的配置,MapReduce.site.xml
表示mapreduce将要运行在yarn上
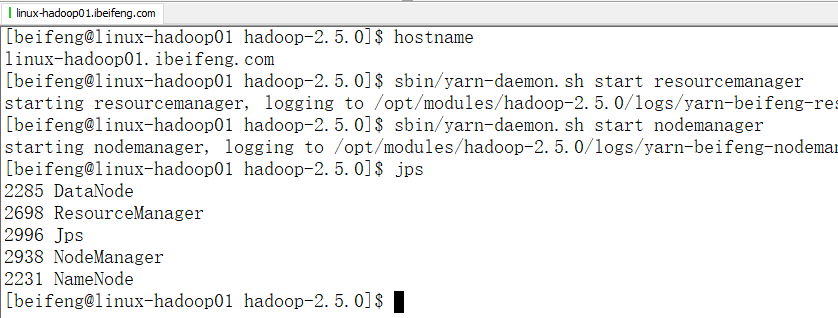
3.启动
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanager
4.浏览器上观察
端口为8088.
http://linux-hadoop01.ibeifeng.com:8088
5.新建将要测试的文件


6.在HDFS上新建文件目录


7.上传本地的wc.input文件进刚刚新建的目录


8.在yarn上运行计算
bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount mapreduce/wordcount/input mapreduce/wordcount/output1


9.查看结果
bin/hdfs dfs -text mapreduce/wordcount/output1/pa*

这个时候因为没有配置历史服务器,所以在途中的history没有用。

四:历史服务器的配置
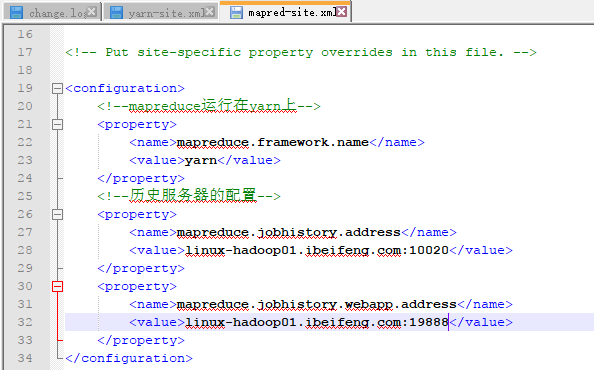
1.配置历史服务器,修改mapred-xite.xml
历史服务器可以查看已经完成的MR程序作业记录。
默认情况下历史服务器是不启动的。
所以配置在mapred-site.xml中。
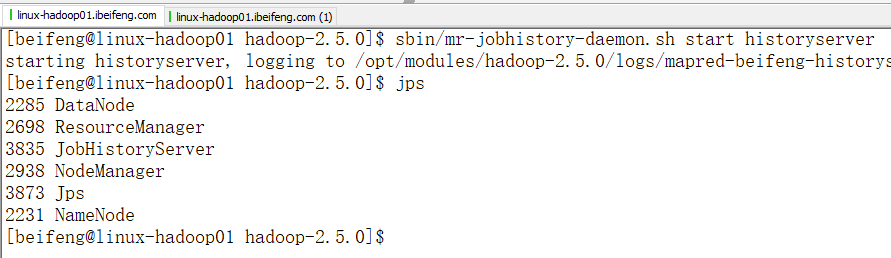
2.启动服务器

3.建议历史服务器在yarn启动之后紧接着启动
sbin/mr-jobhistory-daemon.sh start historyserver
4.浏览器观察
web端口是19888.
再点击一下刚才的history,这里不需要再次运行mapreduce程序。
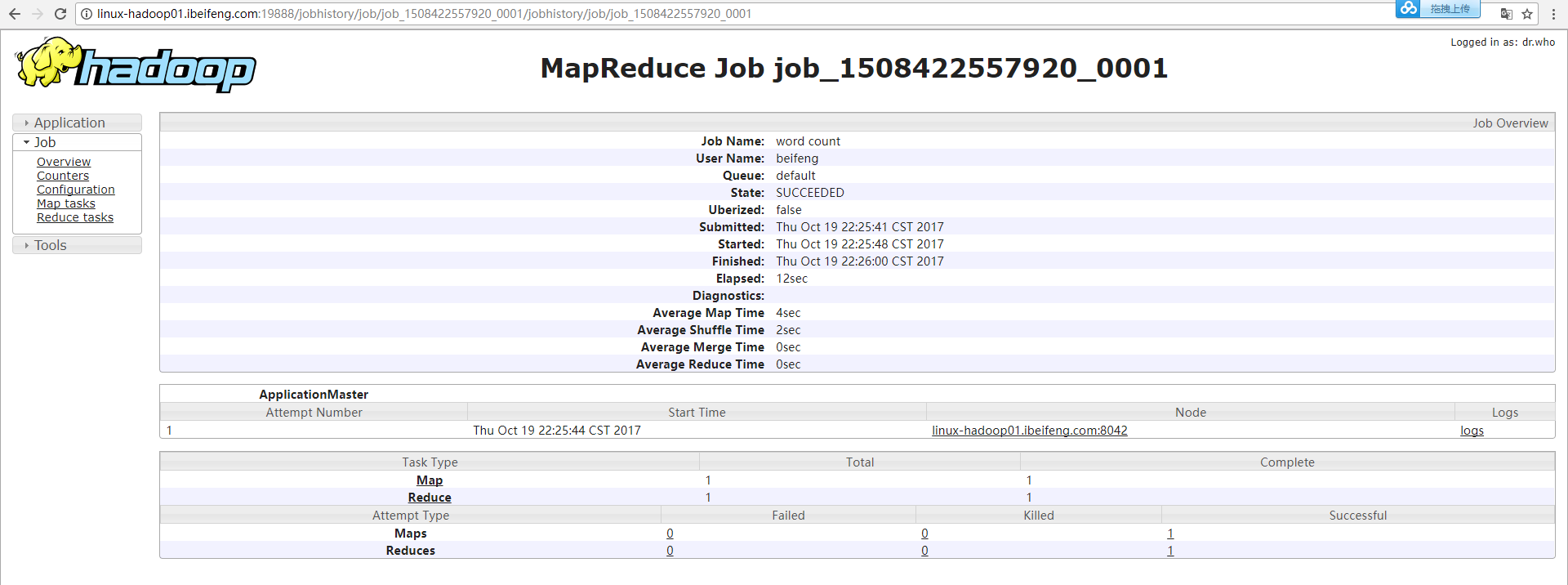
五:日志聚集功能
1.问题由来
这个log的聚集主要说的是yarn里面的日志功能。
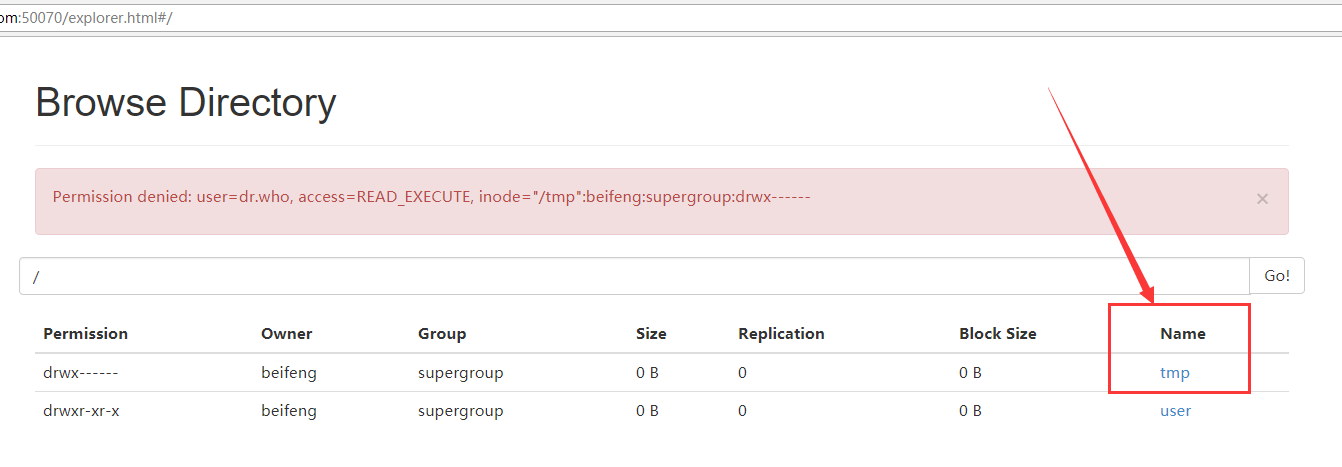
会将MR程序运行的日志上传到HDFS上的目录中,默认会在‘/’下产生一个tmp目录,这个tmp可以在HDFS的50070上看到,同时这个tmp对用户是无效的,没有权限。
很多mapreduce会对应需要的日志,如果将日志聚集到hdfs上,可以方便的查看。
19888上的logs:

50070上的tmp
2.日志聚集功能,修改yarn.site.xml

3.重新启动resourcemanager,nodemanager,jobhistory

6.再次在yarn上运行程序

7.这时就可以点击logs,在yarn的管理页面上观看日志文件

8.logs点击的结果

但是问题还是没有完全解决好,有下面的问题。
9.HDFS用户权限的修改,点击tmp时,出现的问题效果

10.修改hdfs.xite.xml,使hdfs不在检查用户权限
HDFS上会存在用户权限检查。

11.重新启动HDFS
这个时候,其实,yarn也需要关闭,只是在验证tmp时可以不启动yarn。

12.再次点击tmp,即可进入

六:静态用户名的修改
1.修改静态用户名,之前的状态

2.修改core.site.xml

3.重启HDFS和YARN

4.重启任务

5.这时静态用户将会变成设置的用户

007 linux环境下的伪分布式环境搭建的更多相关文章
- linux环境下的伪分布式环境搭建
本文的配置环境是VMware10+centos2.5. 在学习大数据过程中,首先是要搭建环境,通过实验,在这里简短粘贴书写关于自己搭建大数据伪分布式环境的经验. 如果感觉有问题,欢迎咨询评论. 一:伪 ...
- CentOS7下Hadoop伪分布式环境搭建
CentOS7下Hadoop伪分布式环境搭建 前期准备 1.配置hostname(可选,了解) 在CentOS中,有三种定义的主机名:静态的(static),瞬态的(transient),和灵活的(p ...
- Linux单机环境下HDFS伪分布式集群安装操作步骤v1.0
公司平台的分布式文件系统基于Hadoop HDFS技术构建,为开发人员学习及后续项目中Hadoop HDFS相关操作提供技术参考特编写此文档.本文档描述了Linux单机环境下Hadoop HDFS伪分 ...
- OS X Yosemite下安装Hadoop2.5.1伪分布式环境
最近开始学习Hadoop,一直使用的是公司配好的环境.用了一段时间后发现对Hadoop还是一知半解,故决定动手在本机上安装一个供学习研究使用.正好自己用的是mac,所以没啥说的,直接安装. 总体流程 ...
- Ubuntu15.10下Hadoop2.6.0伪分布式环境安装配置及Hadoop Streaming的体验
Ubuntu用的是Ubuntu15.10Beta2版本,正式的版本好像要到这个月的22号才发布.参考的资料主要是http://www.powerxing.com/install-hadoop-clus ...
- 在Win7虚拟机下搭建Hadoop2.6.0伪分布式环境
近几年大数据越来越火热.由于工作需要以及个人兴趣,最近开始学习大数据相关技术.学习过程中的一些经验教训希望能通过博文沉淀下来,与网友分享讨论,作为个人备忘. 第一篇,在win7虚拟机下搭建hadoop ...
- CentOS5.4 搭建Hadoop2.5.2伪分布式环境
简介: Hadoop是处理大数据的主要工具,其核心部分是HDFS.MapReduce.为了学习的方便,我在虚拟机上搭建了一个伪分布式环境,来进行开发学习. 一.安装前准备: 1)linux服务器:Vm ...
- Ubuntu 14.04 (32位)上搭建Hadoop 2.5.1单机和伪分布式环境
引言 一直用的Ubuntu 32位系统(准备下次用Fedora,Ubuntu越来越不适合学习了),今天准备学习一下Hadoop,结果下载Apache官网上发布的最新的封装好的2.5.1版,配置完了根本 ...
- 《OD大数据实战》Hadoop伪分布式环境搭建
一.安装并配置Linux 8. 使用当前root用户创建文件夹,并给/opt/下的所有文件夹及文件赋予775权限,修改用户组为当前用户 mkdir -p /opt/modules mkdir -p / ...
随机推荐
- Windows下Oracle 11g安装以及创建数据库
安装数据库 事实上Oracle安装 1.安装准备 Oracle的安装包下载以后是两个压缩包,同时选中两个压缩包右击进行解压 2.解压完成如下图所示 3.双击 setup.exe 文件进行安装,会弹出以 ...
- SoapUI、Jmeter、Postman三种接口测试工具的比较分析
前段时间忙于接口测试,也看了几款接口测试工具,简单从几个角度做了个比较,拿出来与诸位分享一下吧.各位如果要转载,请一定注明来源,最好在评论中告知博主一声,感谢.本报告从多个方面对接口测试的三款常用工具 ...
- ORA-00845 MEMORY_TARGET not supported on this system 的解决
本文来源:宁静致远 的<ORA-00845 MEMORY_TARGET not supported on this system 的解决> oracle11g数据库在执行dbca或者调整s ...
- Confluence 6 缓存状态
Confluence 为系统的内部缓存提供了缓存的状态以便于你对缓存的大小的命中率进行跟踪,在必要的情况下,你可以对缓存进行调整,让缓存能够更好的满足你的使用需求.请查看 Performance Tu ...
- Confluence 6 开始使用
欢迎来到 Confluence 的开始使用指南文档.在这个稳定中,你将会找到有关对 Confluence 进行评估的指南和其他的一些有用的内容.当你开始使用 Confluence 的时候,这些信息能够 ...
- Confluence 6 已经存在的安装配置数据库字符集编码
针对已经存在的 Confluence 安装,如果你安装的 Confluence 版本是 6.4 或者早期的版本,我们在安装的时候没有检查你数据库的字符设置. 如果你的数据库当前没有被配置使用 UTF- ...
- Confluence 6 管理站点模板
模板是一个预先定义的页面,这个预先定义的页面可以在创建新页面的时候预先载入.模板可以由用户创建也可以通过蓝图提供.请查看 Page Templates 和 Blueprints 页面中的内容. 管理员 ...
- HTML5-长按事件
<!DOCTYPE html> <html> <head> <meta charset="utf-8"/> <title> ...
- php回调函数的概念及实例
php提供了两个内置函数call_user_func()和call_user_func_array()提供对回调函数的支持.这两个函数的区别是call_user_func_array是以数组的形式接收 ...
- C++ Primer 笔记——异常处理
1.栈展开过程沿着嵌套函数的调用链不断查找,直到找到了与异常匹配的catch句子为止,或者也可能一直没找到匹配的catch,则程序将调用terminate,退出主函数后查找过程终止.假设找到了一个ca ...