flask上下文(new)
flask源码解析之上下文
引入
对于flask而言,其请求过程与django有着截然不同的流程。在django中是将请求一步步封装最终传入视图函数的参数中,但是在flask中,视图函数中并没有请求参数,而是将请求通过上下文机制完成对请求的解析操作。
流程图镇楼:
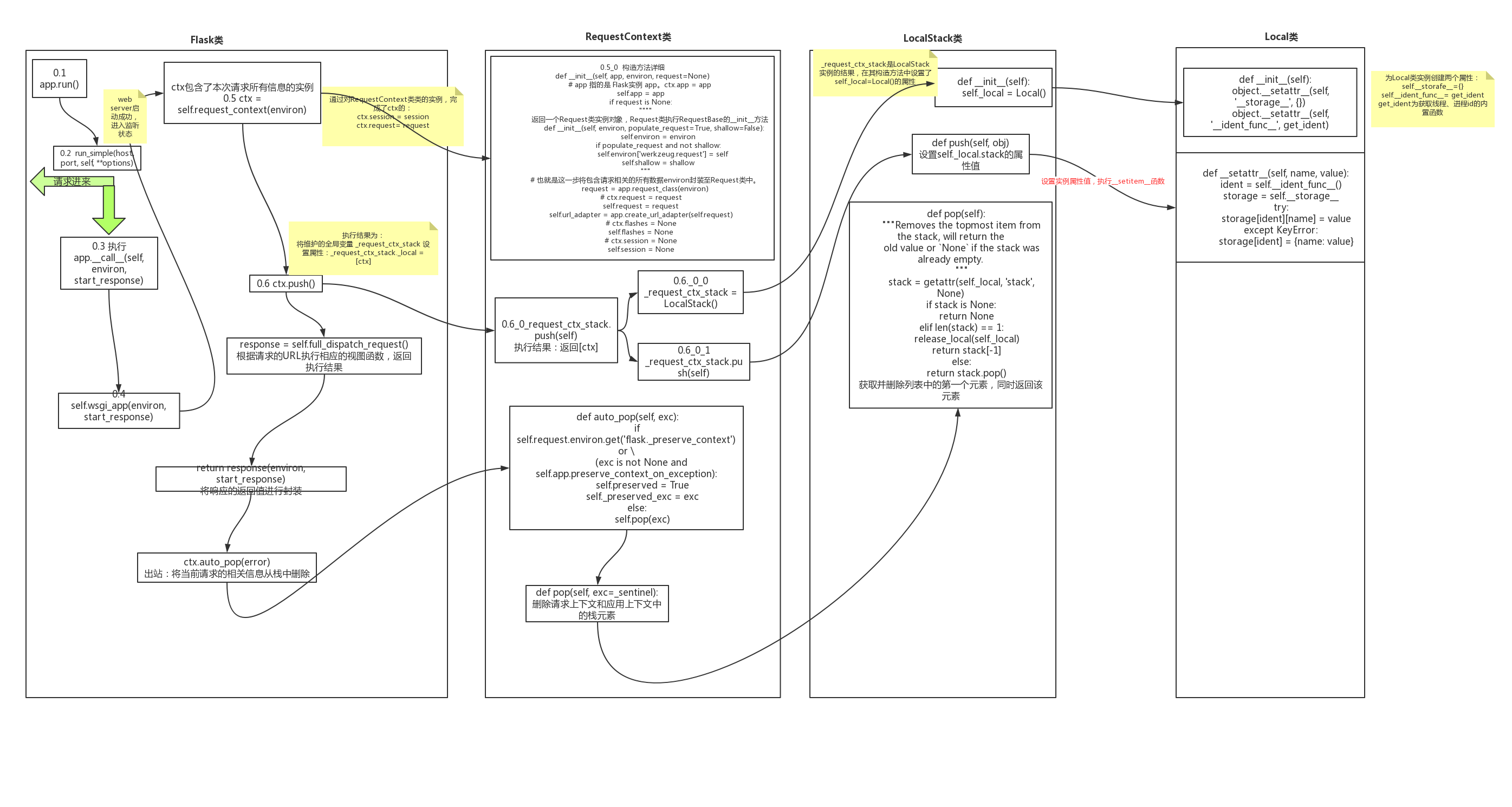
源码解析
0. 请求入口
- if __name__ == '__main__':
- app.run()
- def run(self, host=None, port=None, debug=None,
- load_dotenv=True, **options):
- # Change this into a no-op if the server is invoked from the
- # command line. Have a look at cli.py for more information.
- if os.environ.get('FLASK_RUN_FROM_CLI') == 'true':
- from .debughelpers import explain_ignored_app_run
- explain_ignored_app_run()
- return
- if get_load_dotenv(load_dotenv):
- cli.load_dotenv()
- # if set, let env vars override previous values
- if 'FLASK_ENV' in os.environ:
- self.env = get_env()
- self.debug = get_debug_flag()
- elif 'FLASK_DEBUG' in os.environ:
- self.debug = get_debug_flag()
- # debug passed to method overrides all other sources
- if debug is not None:
- self.debug = bool(debug)
- _host = '127.0.0.1'
- _port = 5000
- server_name = self.config.get('SERVER_NAME')
- sn_host, sn_port = None, None
- if server_name:
- sn_host, _, sn_port = server_name.partition(':')
- host = host or sn_host or _host
- port = int(port or sn_port or _port)
- options.setdefault('use_reloader', self.debug)
- options.setdefault('use_debugger', self.debug)
- options.setdefault('threaded', True)
- cli.show_server_banner(self.env, self.debug, self.name, False)
- from werkzeug.serving import run_simple
- try:
- run_simple(host, port, self, **options)
- finally:
- # reset the first request information if the development server
- # reset normally. This makes it possible to restart the server
- # without reloader and that stuff from an interactive shell.
- self._got_first_request = False
- def __call__(self, environ, start_response):
- """The WSGI server calls the Flask application object as the
- WSGI application. This calls :meth:`wsgi_app` which can be
- wrapped to applying middleware."""
- return self.wsgi_app(environ, start_response)
对于每次请求进来之后,都会执行Flask类实例的__call__方法,至于为什么执行的是__call__方法请看博主之前的《web框架本质》文章,这里不再过多叙述。但是我们可以知道的是,只要是请求进来之后,__call__方法执行的 wsgi_app方法是对请求处理及响应的全部过程,对于每次请求上下文的创建和销毁也是在其内部完成,而上下文正是flask框架的核心,因此研究其内部的执行流程有着至关重要的作用。
首先我们要明白,在上下文中,要完成的操作是:
1.对原生请求进行封装,生成视图函数可操作的request对象
2.获取请求中的cookie信息,生成Session对象
3.执行预处理函数和视图函数
4.返回响应结果
以下为上下文源码,后续对各部分代码进行分别阐述
- def wsgi_app(self, environ, start_response):
- # 生成 ctx.request , request.session,请求上下文,即请求先关的数据都封装到了 ctx这个对象中去
- ctx = self.request_context(environ)
- error = None
- try:
- try:
- # 将ctx入栈,但是内部也将应用上下文入栈
- ctx.push()
- # 对请求的url进行视图函数的匹配,执行视图函数,返回响应信息(cookie)
- response = self.full_dispatch_request()
- except Exception as e:
- # 若发生错误将错误信息最为相应信息进行返回
- error = e
- response = self.handle_exception(e)
- except:
- error = sys.exc_info()[1]
- raise
- # 封装响应信息
- return response(environ, start_response)
- finally:
- if self.should_ignore_error(error):
- error = None
- # 出栈,删除本次请求的相关信息
- ctx.auto_pop(error)
1.请求上下文对象的创建
- # 生成 ctx.request , request.session,请求上下文,即请求先关的数据都封装到了 ctx这个对象中去
- ctx = self.request_context(environ)
生成RequestContext类实例,该实例包含了本次请求的request和Session信息
- def request_context(self, environ):
- return RequestContext(self, environ)
对生成的类实例进行初始化,并且将传入的原生请求信息environ封装值Request类实例中。此时,request为封装之后的Request实例,Session为None
- class RequestContext(object):
- def __init__(self, app, environ, request=None):
- self.app = app
- if request is None:
- request = app.request_class(environ)
- self.request = request
- self.url_adapter = app.create_url_adapter(self.request)
- self.flashes = None
- self.session = None
- self._after_request_functions = []
- self.match_request()
- request_class = Request
2. 将请求上下文和应用上下文入栈
- # 将ctx入栈,但是内部也将应用上下文入栈
- ctx.push()
- def push(self):
- # 获取到的 top == ctx
- top = _request_ctx_stack.top
- if top is not None and top.preserved:
- top.pop(top._preserved_exc)
- # Before we push the request context we have to ensure that there
- # is an application context.
- """
- _request_ctx_stack 和 _app_ctx_stack 都是 Local 类的实例
- """
- # 获取 应用上下文的栈顶元素,得到 app_ctx
- app_ctx = _app_ctx_stack.top
- if app_ctx is None or app_ctx.app != self.app:
- # self.app == Fask()
- # 得到 一个 AppContext类的实例对象,得到一个 应用上下文对象 app_ctx,此时 app_ctx拥有以下属性: app_ctx.app = app, app_ctx.g = app.app_ctx_globals_class()
- app_ctx = self.app.app_context()
- # 将 app_ctx 入栈,应用上下文入栈
- app_ctx.push()
- self._implicit_app_ctx_stack.append(app_ctx)
- else:
- self._implicit_app_ctx_stack.append(None)
- if hasattr(sys, 'exc_clear'):
- sys.exc_clear()
- # self 指的是 ctx,即将ctx入栈,即 _request_ctx_stack._local.stack = [ctx]。请求上下文入栈
- _request_ctx_stack.push(self)
- # 由于每次请求都会初始化创建你ctx,因此session都为None
- if self.session is None:
- # SecureCookieSessionInterface()
- # session_interface = SecureCookieSessionInterface(),即session_interface就是一个SecureCookieSessionInterface类的实例对象
- session_interface = self.app.session_interface
- # 第一次访问:生成一个 字典(容器) 返回至 self.session
- self.session = session_interface.open_session(
- self.app, self.request
- )
- if self.session is None:
- self.session = session_interface.make_null_session(self.app)
首先,应用上下文入栈,这里不多做解释说明,其执行流程与请求上下文相同,请参考下文对与请求上下文的入栈流程分析。
其次,请求上下文入栈。执行 _request_ctx_stack.push(self) ,我们先看看 _request_ctx_stack 是什么。由 _request_ctx_stack = LocalStack() 可知 _request_ctx_stack 是 LocalStack 类实例对象,进入 LocalStack 的构造方法中
- def __init__(self):
- self._local = Local()
即在类实例化过程中,为 _request_ctx_stack 实例对象创建 _local 属性,该属性的值是 Local 类实例,进入其构造方法中,在该方法中为每一个 Local 类实例创建 __storage__ 和 __ident_func__ 属性:
- class Local(object):
- __slots__ = ('__storage__', '__ident_func__')
- def __init__(self):
- object.__setattr__(self, '__storage__', {})
- object.__setattr__(self, '__ident_func__', get_ident)
至此,完成了对 _request_ctx_stack 实例对象创建的流程分析,但是需要注意的是,该实例对象并不是在每次请求之后才创建完成的,而是在flask项目启动之后就会被立即创建,该对象对于每次的请求都会调用该对象的push方法进行请求上下文的入栈,也就是说 _request_ctx_stack 是一个单例对象,该单例对象可以在任何的地方被调用,其他的单例对象还有:
- """
- 注意:
- 在项目启动之后,global里的代码就已经执行完毕,而且也只会执行一次,因此这里面的变量是针对所有请求所使用的,但是根据不同线程id用来存放各自的值
- """
- # 生成 请求上下文栈对象,将请求上下文对象 ctx 保存到 _request_ctx_stack._local.stack = [ctx]中
- _request_ctx_stack = LocalStack()
- # 生成应用上下文栈对象,将应用上下文对象 app_ctx 保存到 _app_ctx_stack._local.stack = [app_ctx]中
- _app_ctx_stack = LocalStack()
- # current_app.__local = app
- current_app = LocalProxy(_find_app)
- # 获取ctx.request
- request = LocalProxy(partial(_lookup_req_object, 'request'))
- # 获取 ctx.session
- session = LocalProxy(partial(_lookup_req_object, 'session'))
- # 维护此次请求的一个全局变量,其实就是一个字典
- g = LocalProxy(partial(_lookup_app_object, 'g'))
对于以上的单例对象,在项目启动之后被创建,在项目停止后被销毁,与请求是否进来无任何关系。现在我们知道了 _request_ctx_stack 的创建流程,我们返回之前对请求上下文的入栈操作 _request_ctx_stack.push(self) (self指的是ctx),进入push方法:
- def push(self, obj):
- # obj == ctx
- """Pushes a new item to the stack"""
- rv = getattr(self._local, 'stack', None)
- if rv is None:
- self._local.stack = rv = []
- rv.append(obj)
- return rv
在上述流程中,首先使用反射获取 _request_ctx_stack._local.stack 的值,也就是获取请求栈的值。项目刚启动,在第一次请求进来之前,请求栈的为空,则代码继续向下执行将当前请求的ctx追加至请求栈中,并且返回请求栈的值。这里着重说一下入栈之前的流程和入栈之后的数据结构:执行 self._local.stack = rv = [] ,会调用 Local 类的 __setattr__ 方法
- def __setattr__(self, name, value):
- ident = self.__ident_func__()
- storage = self.__storage__
- try:
- storage[ident][name] = valueexcept KeyError:
- storage[ident] = {name: value}
self.__ident_func__() 为获取当前此次请求的协程id或者线程id, self.__storage__ 为一个字典对象,在项目启动后的第一个请求进来之后会发生 storage[ident][name] = value 的异常错误,抛出异常被下面捕获,因此执行 storage[ident] = {name: value} (以此次协程id或线程id为key,该key的value为一个字典,在字典中存储一个键值对"stack":[ctx]),即此数据结构为:
- _request_ctx_stack._local.stack={
- 线程id或协程id: {
- 'stack': [ctx]
- }
- }
同时, self._local.stack = [ctx]。至此,完成请求上下文的入栈操作,应用上下文与请求上下文的入栈流程相同,这里不在赘述。至此完成了请求入栈的操作,我们需要知道在上述过程中使用到的四个类: RequestContext (请求上下文类,实例对象ctx中包含了request,Session两个属性)、 Request (对请求的元信息environ进行封装)、 LocalStack (使用该类实例对象 _request_ctx_stack ,维护请求上下文对象ctx的入栈和出栈操作,相当于请求上下文对象的管理者)、 Local (堆栈类,真正存放请求上下文的类),如果你还是对着几个类关系还是不明白,请看我为你准备的图:
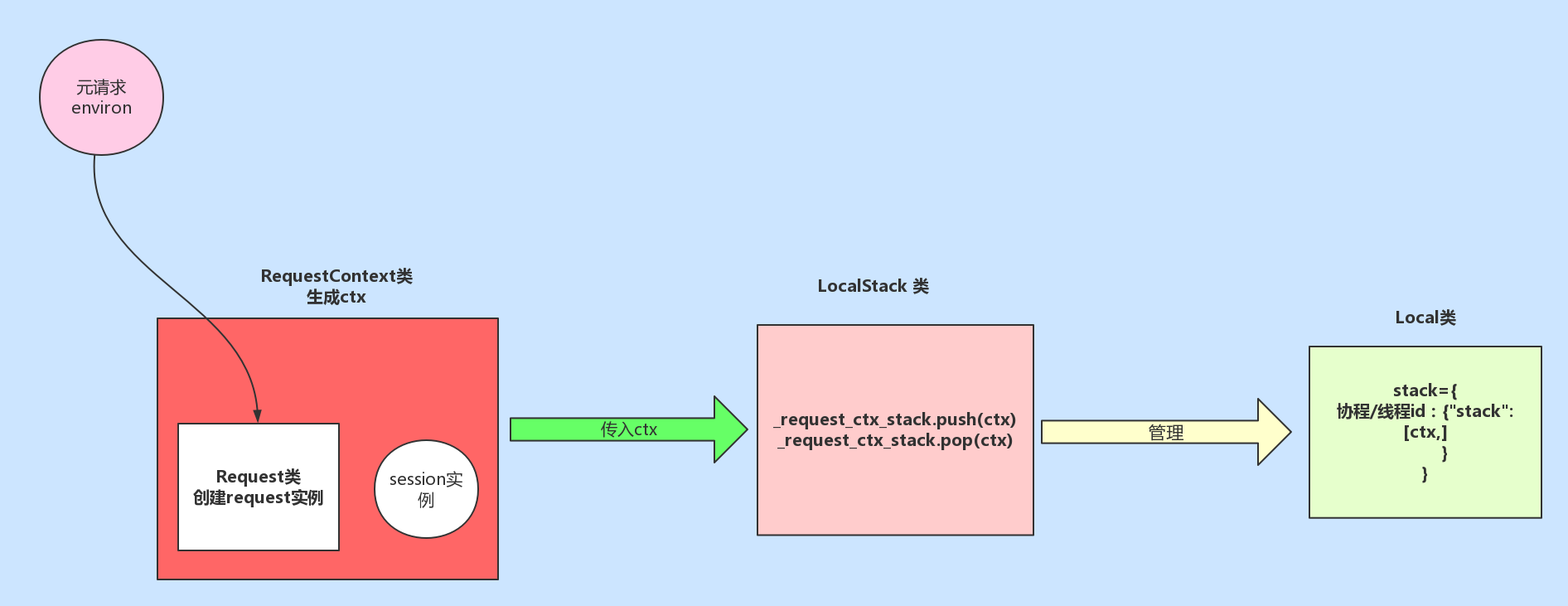
返回 wsgi_app 函数,继续向下执行 response = self.full_dispatch_request() 函数:
- def full_dispatch_request(self):
- # 将 _got_first_request = True,依次执行定义的 before_first_request 函数
- self.try_trigger_before_first_request_functions()
- try:
- # 触发 request_started 信号
- request_started.send(self)
- # 执行钩子函数:before_request,before_first_request
- rv = self.preprocess_request()
- # 如果执行的before_request,before_first_request函数没有返回值,则继续执行视图函数。若有返回值,则不执行视图函数
- if rv is None:
- # 执行此url对应的别名的视图函数并执行该函数,返回视图函数的返回值,得到相应信息
- rv = self.dispatch_request()
- except Exception as e:
- # 如果发生错误,则将异常信息作为返回值进行返回
- rv = self.handle_user_exception(e)
- # 封装返回信息并返回,包括 session
- return self.finalize_request(rv)
在函数的内部首先执行预处理函数再执行视图函数,返回预处理函数或视图函数的返回值至浏览器。
返回 wsgi_app 函数中,继续向下执行 ctx.auto_pop(error) 函数,完成对请求上下文和应用上下文的出栈操作:
- def auto_pop(self, exc):
- if self.request.environ.get('flask._preserve_context') or \
- (exc is not None and self.app.preserve_context_on_exception):
- self.preserved = True
- self._preserved_exc = exc
- else:
- self.pop(exc)
- def pop(self, exc=_sentinel):
- """Pops the request context and unbinds it by doing that. This will
- also trigger the execution of functions registered by the
- :meth:`~flask.Flask.teardown_request` decorator.
- .. versionchanged:: 0.9
- Added the `exc` argument.
- """
- app_ctx = self._implicit_app_ctx_stack.pop()
- try:
- clear_request = False
- if not self._implicit_app_ctx_stack:
- self.preserved = False
- self._preserved_exc = None
- if exc is _sentinel:
- exc = sys.exc_info()[1]
- self.app.do_teardown_request(exc)
- # If this interpreter supports clearing the exception information
- # we do that now. This will only go into effect on Python 2.x,
- # on 3.x it disappears automatically at the end of the exception
- # stack.
- if hasattr(sys, 'exc_clear'):
- sys.exc_clear()
- request_close = getattr(self.request, 'close', None)
- if request_close is not None:
- request_close()
- clear_request = True
- finally:
- # 请求上下文出栈
- rv = _request_ctx_stack.pop()
- # get rid of circular dependencies at the end of the request
- # so that we don't require the GC to be active.
- if clear_request:
- rv.request.environ['werkzeug.request'] = None
- # Get rid of the app as well if necessary.
- if app_ctx is not None:
- # 应用上下文出栈
- app_ctx.pop(exc)
- assert rv is self, 'Popped wrong request context. ' \
- '(%r instead of %r)' % (rv, self)
- def pop(self):
- """Removes the topmost item from the stack, will return the
- old value or `None` if the stack was already empty.
- """
- stack = getattr(self._local, 'stack', None)
- if stack is None:
- return None
- elif len(stack) == 1:
- release_local(self._local)
- return stack[-1]
- else:
- # 获取并删除列表中的第一个元素,同时返回该元素
- return stack.pop()
stack获取到的是请求栈或应用栈的列表,栈的长度为1,则进入 elif 控制语句中,首先执行 release_local(self._local) :
- def release_local(local):
- local.__release_local__()
local=self._local ,即执行 Local 类的 __release_local__ 方法,进入该方法:
- def __release_local__(self):
- # 将 self.__storage__ 所维护的字典中删除当前协程或线程id为key的元素
- self.__storage__.pop(self.__ident_func__(), None)
从上面的语句中可以很明显看出,要执行的操作就是将以当前协程或线程id为key的元素从字典 self.__storage__ 中删除,返回至pop函数中的elif控制语句,最终将列表中的最后一个元素返回。注意,最终 _request_ctx_stack._local 的请求栈和应用栈列表中至少会存在一个元素。
flask上下文(new)的更多相关文章
- Flask上下文管理、session原理和全局g对象
一.一些python的知识 1.偏函数 def add(x, y, z): print(x + y + z) # 原本的写法:x,y,z可以传任意数字 add(1,2,3) # 如果我要实现一个功能, ...
- flask上下文详解
一.前言 了解过flask的python开发者想必都知道flask中核心机制莫过于上下文管理,当然学习flask如果不了解其中的处理流程,可能在很多问题上不能得到解决,当然我在写本篇文章之前也看到了很 ...
- flask上下文全局变量,程序上下文、请求上下文、上下文钩子
Flask上下文 Flask中有两种上下文,程序上下文(application context)和请求上下文(request context) 当客户端发来请求时,请求上下文就登场了.请求上下文里包含 ...
- Flask上下文管理
一.一些python的知识 1.偏函数 def add(x, y, z): print(x + y + z) # 原本的写法:x,y,z可以传任意数字 add(1,2,3) # 如果我要实现一个功能, ...
- Flask 上下文(Context)原理解析
:first-child { margin-top: 0; } blockquote > :last-child { margin-bottom: 0; } img { border: 0; m ...
- Flask上下文管理机制
前引 在了解flask上下文管理机制之前,先来一波必知必会的知识点. 面向对象双下方法 首先,先来聊一聊面向对象中的一些特殊的双下划线方法,比如__call__.__getattr__系列.__get ...
- 4.1 python类的特殊成员,偏函数,线程安全,栈,flask上下文
目录 一. Python 类的特殊成员(部分) 二. Python偏函数 1. 描述 2. 实例一: 取余函数 3. 实例二: 求三个数的和 三. 线程安全 1. 实例一: 无线程,消耗时间过长 2. ...
- Flask 上下文机制和线程隔离
1. 计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决, 上下文机制就是这句话的体现. 2. 如果一次封装解决不了问题,那就再来一次 上下文:相当于一个容器,保存了Flask程序运行过程中 ...
- 详解Flask上下文
上下文是在Flask开发中的一个核心概念,本文将通过阅读源码分享下其原理和实现. Flask系列文章: Flask开发初探 WSGI到底是什么 Flask源码分析一:服务启动 Flask路由内部实现原 ...
- 10.Flask上下文
1.1.local线程隔离对象 不用local对象的情况 from threading import Thread request = ' class MyThread(Thread): def ru ...
随机推荐
- SpringCloud微服务负载均衡与网关
1.使用ribbon实现负载均衡ribbon是一个负载均衡客户端 类似nginx反向代理,可以很好的控制htt和tcp的一些行为.Feign默认集成了ribbon. 启动两个会员服务工程,端口号分别为 ...
- gk888t打印机安装
https://jingyan.baidu.com/article/948f5924090c7ad80ff5f9c5.html
- node 常用模块及方法fs,url,http,path
http://www.cnblogs.com/mangoxin/p/5664615.html https://www.liaoxuefeng.com/wiki/001434446689867b2715 ...
- python+selenium,打开浏览器时报selenium.common.exceptions.WebDriverException: Message: 'chromedriver' executable needs to be in PATH
有一年多没写web自动化了,今天搭建环境的时候报了一个常见错误,但是处理过程有点闹心,报错就是常见的找不到驱动<selenium.common.exceptions.WebDriverExcep ...
- ASP.NET Core 添加NLog日志支持(VS2015update3&VS2017)
1.创建一个新的ASP.NET Core项目 2.添加项目依赖 NLog.Web.AspNetCore 3.在项目目录下添加nlog.config文件: <?xml version=" ...
- Python并发解决方案
一.subprocess模块 call():执行命令,返回程序返回码(int) import subprocess print(subprocess.call("mspaint") ...
- jQuery基础方法:each(),map(),index(),is()
jQuery的each()方法和forEach()的区别: each()返回调用自身的jQuery对象,可用于链式调用 $('div').each(function(idx){ //找到所有div元素 ...
- GUI学习之四——QWidget控件学习总结
上一章将的QObject是PyQt里所有控件的基类,并不属于可视化的控件.这一章所讲的QWidget,是所有可视化控件的基类. QWidget包含下面几点特性 a.控件是用户界面的最小的元素 b.每个 ...
- JSON.parse()和eval()的区别
json格式非常受欢迎,而解析json的方式通常用JSON.parse()但是eval()方法也可以解析,这两者之间有什么区别呢? JSON.parse()之可以解析json格式的数据,并且会对要解析 ...
- union: php/laravel command
#########Laravel###############2018-01-09 16:46:26 # switch to maintenance mode php artisan down # s ...