【机器学习】K均值算法(II)
k聚类算法中如何选择初始化聚类中心所在的位置。
在选择聚类中心时候,如果选择初始化位置不合适,可能不能得出我们想要的局部最优解。
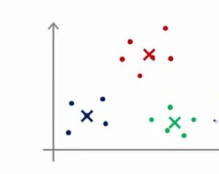
而是会出现一下情况:

为了解决这个问题,我们通常的做法是:
我们选取K<m个聚类中心。
然后随机选择K个训练样本的实例,之后令k个聚类中心分别与k个训练实例相等。
之后我们通常需要多次运行均值算法。每一次都重新初始化,然后在比较多次运行的k均值的结果,选择代价函数较小的结果。这种方法在k较小的时候可能会有效果,但是在K数量较多的时候不会有明显改善。
如何选取聚类数量
当我们研究聚类数量与畸变函数J的关系时候,发现“肘部法则”,也就是当k的数量逐渐增加时候,存在某一点成为J函数下降过程呢中的拐点。
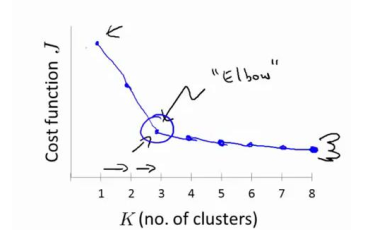
这个点之前,他的畸变的值迅速下降,在这个点之后,它的畸变值下变慢,那么看起来这个拐点通常会成为最合适的值。不过在实际情况中,我们会选择K值的数量取决于用聚类算法所需要解决的实际问题的目的出发。根据实际情况的需要选择K值的数量。
【机器学习】K均值算法(II)的更多相关文章
- 【机器学习】K均值算法(I)
K均值算法是一类非监督学习类,其可以通过观察样本的离散性来对样本进行分类. 例如,在对如下图所示的样本中进行聚类,则执行如下步骤 1:随机选取3个点作为聚类中心. 2:簇分配:遍历所有样本然后依据每个 ...
- 机器学习之K均值算法(K-means)聚类
K均值算法(K-means)聚类 [关键词]K个种子,均值 一.K-means算法原理 聚类的概念:一种无监督的学习,事先不知道类别,自动将相似的对象归到同一个簇中. K-Means算法是一种聚类分析 ...
- 机器学习算法之Kmeans算法(K均值算法)
Kmeans算法(K均值算法) KMeans算法是典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大.该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑 ...
- 秒懂机器学习---k临近算法(KNN)
秒懂机器学习---k临近算法(KNN) 一.总结 一句话总结: 弄懂原理,然后要运行实例,然后多解决问题,然后想出优化,分析优缺点,才算真的懂 1.KNN(K-Nearest Neighbor)算法的 ...
- 使用K均值算法进行图片压缩
K均值算法 上一期介绍了机器学习中的监督式学习,并用了离散回归与神经网络模型算法来解决手写数字的识别问题.今天我们介绍一种机器学习中的非监督式学习算法--K均值算法. 所谓非监督式学习,是一种 ...
- K 均值算法-如何让数据自动分组
公号:码农充电站pro 主页:https://codeshellme.github.io 之前介绍到的一些机器学习算法都是监督学习算法.所谓监督学习,就是既有特征数据,又有目标数据. 而本篇文章要介绍 ...
- 聚类算法:K-means 算法(k均值算法)
k-means算法: 第一步:选$K$个初始聚类中心,$z_1(1),z_2(1),\cdots,z_k(1)$,其中括号内的序号为寻找聚类中心的迭代运算的次序号. 聚类中心的向量值可任意设 ...
- 一句话总结K均值算法
一句话总结K均值算法 核心:把样本分配到离它最近的类中心所属的类,类中心由属于这个类的所有样本确定. k均值算法是一种无监督的聚类算法.算法将每个样本分配到离它最近的那个类中心所代表的类,而类中心的确 ...
- 聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
1.用python实现K均值算法 import numpy as np x = np.random.randint(1,100,20)#产生的20个一到一百的随机整数 y = np.zeros(20) ...
- Bisecting KMeans (二分K均值)算法讲解及实现
算法原理 由于传统的KMeans算法的聚类结果易受到初始聚类中心点选择的影响,因此在传统的KMeans算法的基础上进行算法改进,对初始中心点选取比较严格,各中心点的距离较远,这就避免了初始聚类中心会选 ...
随机推荐
- DAO(Repository),Service,Controller层之间的相互关系
DAO层:DAO层主要是做数据持久层的工作,负责与数据库进行联络的一些任务都封装在此,DAO层的设计首先是设计DAO的接口,然后在Spring的配置文件中定义此接口的实现类,然后就可在模块中调用此接口 ...
- TypeError: Fetch argument 0 has invalid type <type 'int'>, must be a string or Tensor. (Can not convert a int into a Tensor or Operation.)
6月5日的時候,修改dilated_seg.py(使用tensorflow)出現了報錯: TypeError: Fetch argument 0 has invalid type <type ' ...
- 远程git仓库的搭建
具体的操作见另一篇 第一部分: 安装 1. 下载地址: https://git-scm.com/download/win; 如果速度慢, 使用 迅雷下载; 2. 点击安装, 然后下一步, 直到下面这 ...
- SpringBoot学习笔记1
1.什么是SpringBoot 用一些固定的方式来构建生产级别的spring应用.spring boot推崇约定大于配置的方式便于你能够快速的启动并运行程序. 2.为什么要学spring boot j ...
- drf框架之跨域问题的解决与缓存问题
什么是跨域问题呢: 1. 跨域问题: CORS 跨域资源共享: 有简单请求 和非简单请求 简单请求: 只要符合如下两条,就是简单请求,否则则是非简单请求 (1) 请求方法是以下三种方法之一: HEAD ...
- python学习 生成随机函数 random模块的用法
random模块是用于生成随机数 常用函数 函数 含义 random() 生成一个[0,1.0)之间的随机浮点数 uniform(a,b) 生成一个a到b之间的随机浮点数 randint(a,b) 生 ...
- open函数新建文件报错
报错原因很多,我这里只写我遇到的: 给的路径或者文件名中包含了这些字符的:/\:*?"><| 都不行,我说的是Windows平台下的.
- 如何激活已经运行过的Activity, 而不是重新启动新的Activity
Intent i=new Intent(this,Activity1.class); i.addFlags(Intent.FLAG_ACTIVITY_REORDER_TO_FRONT); st ...
- RabbitMQ消费者抛异常日志持续打印的问题
场景 消费者接受消息,进行一系列处理,但是由于某些原因处理过程中该消费者的抛出了异常,并且不捕获(直接 throws IOException 抛出去): 由于抛出了IOException,那么这条消息 ...
- 工程启动没有报错,但是dubbo后台显示没有提供者,工程没有提供服务
先说一下我遇到的问题:服务工程启动没有异常,消费者工程启动会出现很多nested(嵌套的)错误,但其根本错误是No provider available(缺少服务提供者).可是服务工程起来的时候明明没 ...