论文阅读笔记二十五:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition(SPPNet CVPR2014)

论文源址:https://arxiv.org/abs/1406.4729
tensorflow相关代码:https://github.com/peace195/sppnet
摘要
深度卷积网络需要输入固定尺寸大小的图片(224x224),这引入了大量的手工因素,同时,一定程度上,对于任意尺寸的图片或者子图会降低识别的准确率。SPP-net对于任意大小的图片,可以生成固定长度的特征表述。SPP-net对于变形的图片仍有一定的鲁棒性。基于上述优点,SPP-net会提高基于CNN的图像分类的效果。
SPP-net对于目标检测任务也有一定的贡献,只从整张图片中计算一次获得feature map,然后,通过从任意尺寸区域得到的池化特征中生成固定尺寸的特征表述用于检测器的训练。此模型避免重复的卷积特征提取过程,大大减轻了计算负担。经测试,SPP-net要快于R-CNN 24-102倍。
介绍
对于输入卷积网络图片的尺寸要求为固定尺寸,大多数做法是通过裁剪,或拉伸至目标尺寸中,裁剪过的图片可能并未包含目标物体,而拉伸操作可能会使图片的几何失真。进而可能会对识别的准确率造成一定的影响。当目标物体的大小发生变化时,预训练时的尺寸大小可能会发生矛盾,固定大小的输入忽略了多尺度的问题。如下图吗,
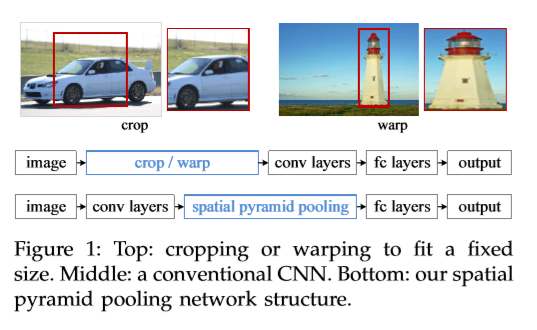
卷积网络要求输入尺寸固定的原因:卷积网络主要包含两部分:卷积层和全连接层。卷积层通过一个滑动窗口并输出代表空间分布的响应。实际上,卷积层并不需要固定的图片尺寸,而且可以输出任意大小的feature map。而全连接层根据定义要求输入必须为固定的大小。
该文提出了空间金字塔池化层用于消除尺寸固定这个限制。具体实现是在最后一层卷积层后添加SPP层。SPP将特征池化处理,并产生一个固定长度的输出,送入全连接层。一句话,SPP-net在网络的较深层中(卷积层与全连接层之间)执行一些聚合不同层次信息的操作来减弱输入时采用裁剪拉伸等操作产生的不良影响。SPP-net实现不同尺寸的输入,这增加了模型尺寸的不变性及防止过拟合。
基于空间金字塔池化的深度网络
卷积网络与feature map:参考七层网络结构,前5层为卷积层,每层参杂池化层,后接几层池化层,最后两层为全连接层,同时输出N路soft-max,N代表类别数。此网络结构需要输入固定尺寸的图片,而固定的性质是由全连接层决定的。卷积层执行滑动卷积操作,输出与输入之间的比是相似的。得到的feature map包含了响应值同时也包含了空间位置信息。

空间金字塔池化层:卷积层接受任意尺寸的输入同时生成不同尺寸的输出。SVM,全连接层分类器要求输入固定尺寸的特征向量。通过词袋方法将特征进行池化。相比词袋,空间金字塔池化层可一个保留池化操作后的空间信息到局部空间bin中。spatial bin与输入成比例的尺寸。而spatial bin的数量不受图片大小的影响。而先前的池化操作滑动窗口的数量受输入大小的影响。该文将最后一层池化层更改为SPP,通过使用不同的核对feature map进行池化操作。SPP层输出kxM维的向量,k为最后一层卷积层核的个数。M为bin的个数,固定维度的向量送入全连接层中。在SPP中有一个全局池化操作,全局平均池化操作可以降低模型的复杂度,同时可以防止过拟合。在测试时,在卷积层后使用平均池化层利于提高准确率,而最大池化操作用于弱监督的目标识别。
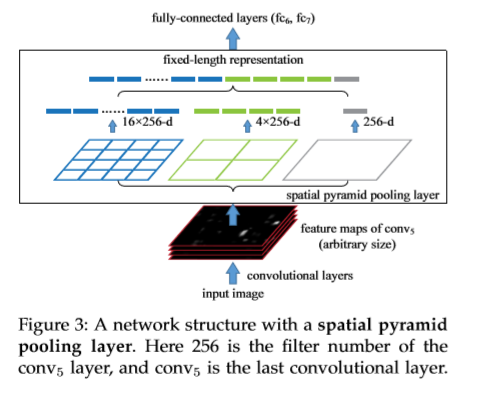
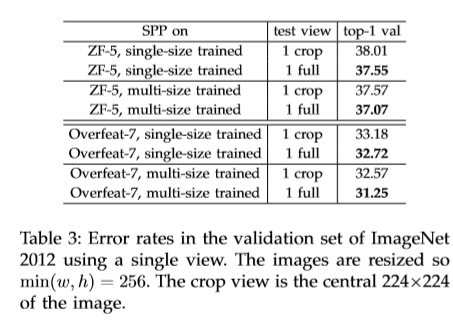
网络的训练:分为单尺寸训练和多尺寸训练,单尺寸训练,送入裁剪后固定大小的图片(224x224),对于输入的图片,可以事先计算好bin的大小。conv5输出的feature map大小为axa(13x13)。而一层含有nxn大小的金字塔层,将池化层看作滑动窗口,大小为[a/n], stride 为[a/n],对有l层金字塔层,将其l个输出进行拼接。win中的[]代表向上取整,而stride中的[]代表向下取整。

多尺寸的训练:该文除了考虑224x224大小的输入,同时考虑了180x180大小的输入,将224x224图片resize至大小为180x180大小。 所以,两者窗宽比相同,内容与外形相同,只有像素不同。 输入图片大小发生改变,通过改变金字塔池化层得到与224x224相同维度的向量输入到全连接层中。网络的参数量相同,这样实现了不同尺寸的输入。先用224x224的图片训练一轮,后使用180x180大小的图片进行迭代,该文还使用[224x180]的进行实验。
分类实验
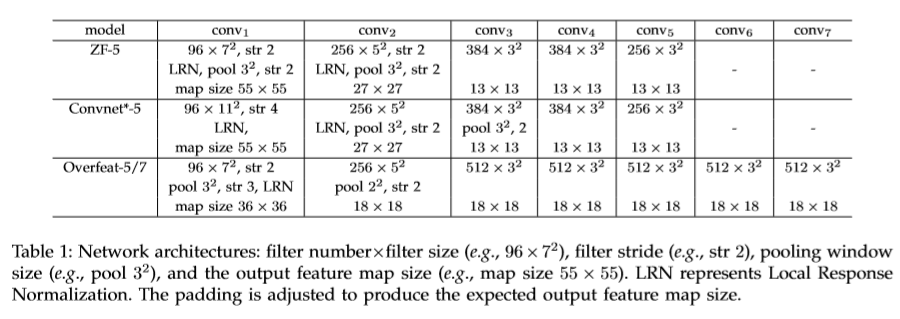
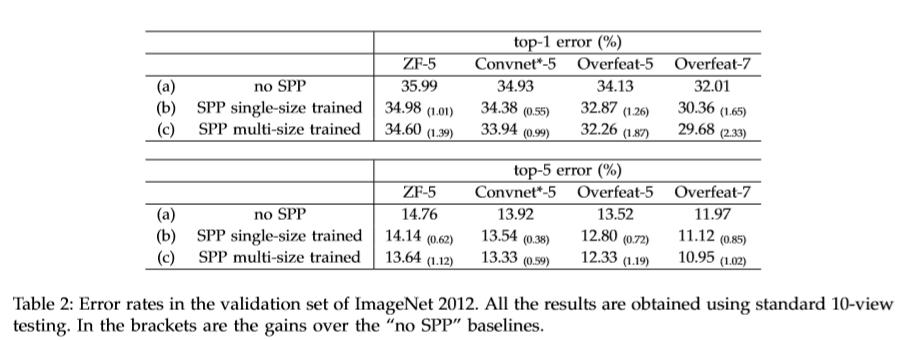
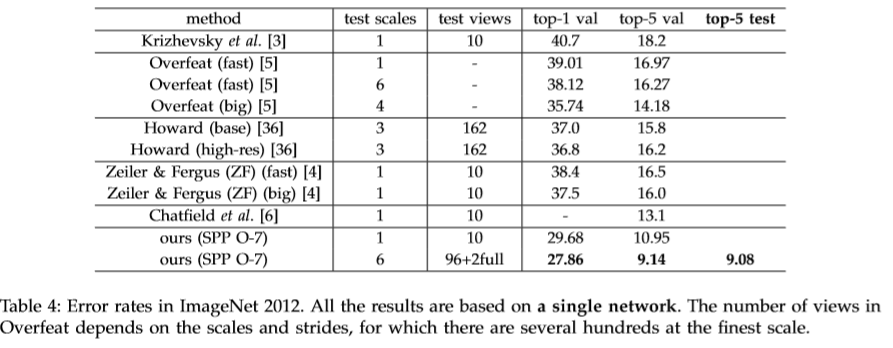
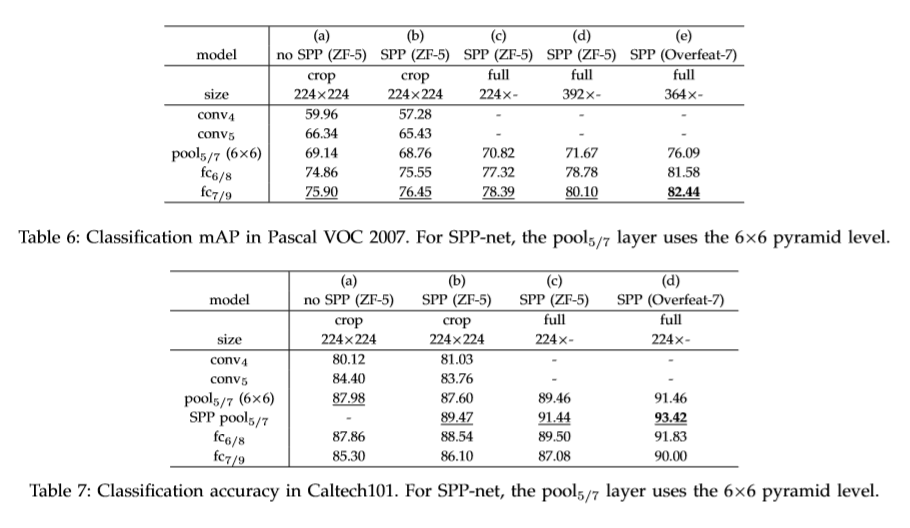
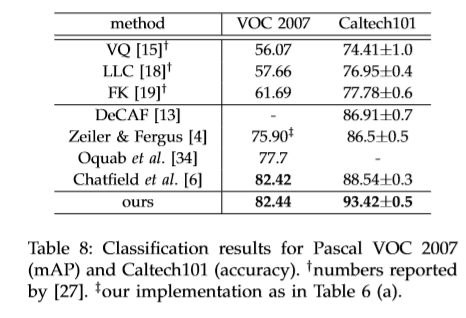
基于ZF-5,Convnet*-5,Overfeat-5/7五个网络结构进行改造,结构如下

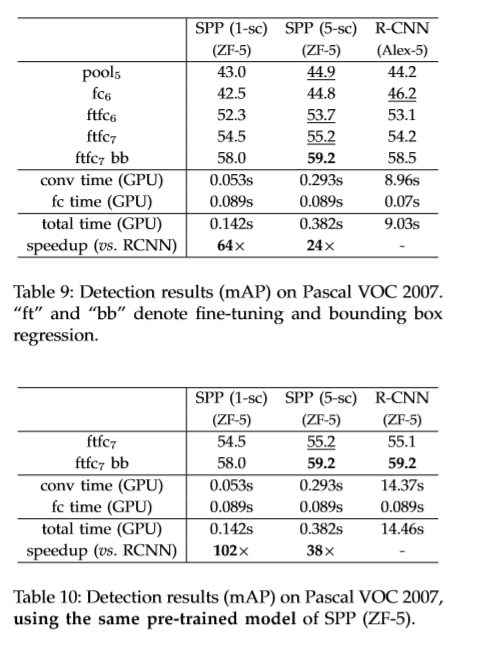
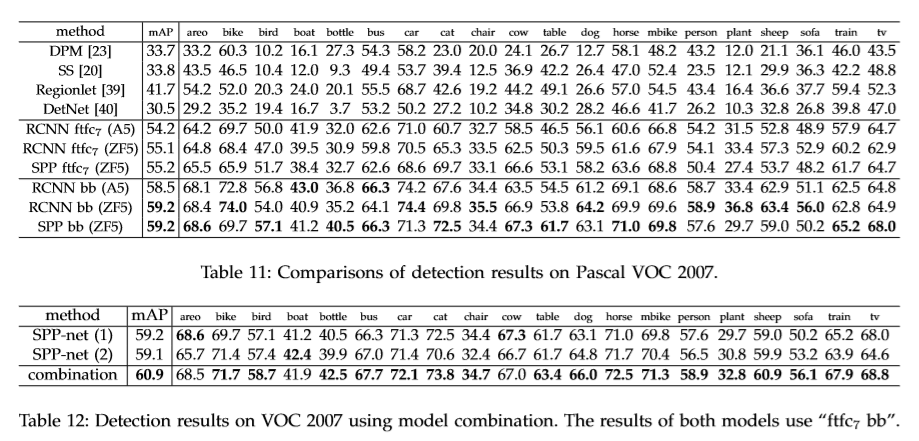
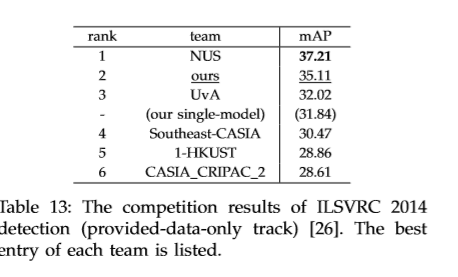
目标检测实验
首先将整幅图像输入网络提取特征,采用快速的SS方法提取候选框,然后在每个候选框上应用SPP层进行特征提取,用训练好的二分类SVM进行分类。

Reference
[1] Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel, “Backpropagation applied to handwritten zip code recognition,” Neural computation, 1989.
[2] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. FeiFei, “Imagenet: A large-scale hierarchical image database,” in CVPR, 2009.
[3] A. Krizhevsky, I. Sutskever, and G. Hinton, “Imagenet classification with deep convolutional neural networks,” in NIPS, 2012.
论文阅读笔记二十五:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition(SPPNet CVPR2014)的更多相关文章
- SPPNet论文翻译-空间金字塔池化Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
http://www.dengfanxin.cn/?p=403 原文地址 我对物体检测的一篇重要著作SPPNet的论文的主要部分进行了翻译工作.SPPNet的初衷非常明晰,就是希望网络对输入的尺寸更加 ...
- 深度学习论文翻译解析(九):Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
论文标题:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition 标题翻译:用于视觉识别的深度卷积神 ...
- 目标检测--Spatial pyramid pooling in deep convolutional networks for visual recognition(PAMI, 2015)
Spatial pyramid pooling in deep convolutional networks for visual recognition 作者: Kaiming He, Xiangy ...
- Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition Kaiming He, Xiangyu Zh ...
- SPP Net(Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition)论文理解
论文地址:https://arxiv.org/pdf/1406.4729.pdf 论文翻译请移步:http://www.dengfanxin.cn/?p=403 一.背景: 传统的CNN要求输入图像尺 ...
- 论文解读2——Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
背景 用ConvNet方法解决图像分类.检测问题成为热潮,但这些方法都需要先把图片resize到固定的w*h,再丢进网络里,图片经过resize可能会丢失一些信息.论文作者发明了SPP pooling ...
- SPP NET (Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition)
1. https://www.cnblogs.com/gongxijun/p/7172134.html (SPP 原理) 2.https://www.cnblogs.com/chaofn/p/9305 ...
- 目标检测(二)SSPnet--Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognotion
作者:Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun 以前的CNNs都要求输入图像尺寸固定,这种硬性要求也许会降低识别任意尺寸图像的准确度. ...
- 论文阅读笔记二十四:Rich feature hierarchies for accurate object detection and semantic segmentation Tech report(R-CNN CVPR2014)
论文源址:http://www.cs.berkeley.edu/~rbg/#girshick2014rcnn 摘要 在PASCAL VOC数据集上,最好的方法的思路是将低级信息与较高层次的上下文信息进 ...
随机推荐
- css3 特效拓展 画个安卓机器人
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- 数字图像处理的Matlab实现(4)—灰度变换与空间滤波
第3章 灰度变换与空间滤波(2) 3.3 直方图处理与函数绘图 基于从图像亮度直方图中提取的信息的亮度变换函数,在诸如增强.压缩.分割.描述等方面的图像处理中扮演着基础性的角色.本节的重点在于获取.绘 ...
- VPS上拖文件(Apache配置、SSH)
场景 下载VPS上的文件 命令 Apache配置 yum install httpd -y /etc/rc.d/init.d/httpd start /sbin/iptables -I INPUT - ...
- 记录一下putty的pscp的用法【转】
转自 记录一下putty的pscp的用法 - 刘荣星的博客 https://www.liurongxing.com/how-use-the-putty-and-pscp.html 以前一直用Secu ...
- 一道搜索题【2013 noip提高组 DAY2 t3】华容道
这篇不多说,具体的解释都在程序里 题目描述 [问题描述] 小 B 最近迷上了华容道,可是他总是要花很长的时间才能完成一次.于是,他想到用编程来完成华容道:给定一种局面, 华容道是否根本就无法完成,如果 ...
- Unity3D之IOS&Android收集Log文件
开发项目的时候尤其在处理与服务器交互这块,如果服务端程序看不到客户端请求的Log信息,那么无法修改BUG.在Windows上Unity会自动讲Log文件写入本地,但是在IOS和Android上确没有这 ...
- WebStorm 关联 TFS(转)
1.下载插件 TFS integration 2.链接TFS 服务器 3.创建工作区 4. 5.选择一个 工作环境 6.最重要的有点是在VCS里面要选择一个默认的提交方式!!!
- linux c 时间函数
1. time() 函数提供了 秒 级的精确度 time_t time(time_t * timer) 函数返回从UTC1970-1-1 0:0:0开始到现在的秒数 2. struct timespe ...
- MySQL数据库char与varchar的区别分析及使用建议
在数据库中,字符 型的数据是最多的,可以占到整个数据库的80%以上.为此正确处理字符型的数据,对于提高数据库的性能有很大的作用.在字符型数据中,用的最多的就是 Char与Varchar两种类型.前面的 ...
- [C]控制外部变量访问权限的extern和static关键字
一.extern 概述 编译器是由上至下编译源文件的,当遇到一些函数引用外部全局变量,而这个变量被定义在该函数声明主体的下方,又或者引用自其它的编译单元,这个情况就需要extern来向编译器表明此变量 ...