CUDA编程模型——组织并行线程3 (2D grid 1D block)
当使用一个包含一维块的二维网格时,每个线程都只关注一个数据元素并且网格的第二个维数等于ny,如下图所示:
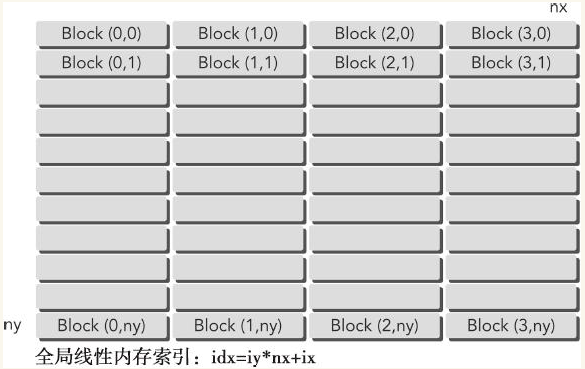
这可以看作是含有二维块的二维网格的特殊情况,其中块儿的第二个维数是1。因此,从块儿和线程索引到矩阵坐标的映射就变成:
ix = threadIdx.x + blockIdx.x * blockDim.x;
iy = blockIdx.y;
从矩阵坐标到全局线性内存偏移量的映射保持不变。核函数如下:
__global__ void sumMatrixOnGPUMix(float *MatA,float *MatB,float *MatC,int nx,int ny)
{
unsigned int ix=threadIdx.x+blockIdx.x*blockDim.x;
unsigned int iy=blockIdx.y;
unsigned int idx=iy*nx+ix;
if(ix<nx&&iy<ny)
MatC[idx]=MatA[idx]+MatB[idx];
}
与二维核函数sumMatrixOnGPU2D不同的是,这个新的核函数的唯一优点是每个线程省去了一次整数乘法和整数加法的运算。将块尺寸设置为32,并在此基础上计算网格大小。
dim3 block();//x方向上有32个线程块
dim3 grid((nx-)/block.x+,ny);
实验运行结果如下图:

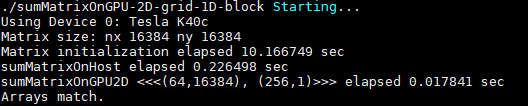
将线程块的大小增加到256,实验表现出目前为止最佳的性能:
下表是不同核函数实现的结果比较,执行配置都是对应核函数性能较优的参数。
| 内核函数 | 执行配置 | 运行时间 |
| sumMatrixOnGPU2D | (512,1024),(32,16) | 0.197 sec |
| sumMatrixOnGPU1D | (512,1),(32,1) | 0.032 sec |
| sumMatrixOnGPUMix | (64,16384),(256,1) | 0.0178 sec |
从矩阵加法的例子中看出:
- 改变执行配置对内核性能有影响;
- 传统的核函数实现一般不能获得最佳性能;
- 对于一个给定的核函数,尝试使用不同的网络和线程块大小可以获得更好的性能。
主要参考文献:
- 《 CUDA C编程权威指南》
CUDA编程模型——组织并行线程3 (2D grid 1D block)的更多相关文章
- CUDA编程模型——组织并行线程2 (1D grid 1D block)
在”组织并行编程1“中,通过组织并行线程为”2D grid 2D block“对矩阵求和,在本文中通过组织为 1D grid 1D block进行矩阵求和.一维网格和一维线程块的结构如下图: 其中,n ...
- 【CUDA 基础】2.3 组织并行线程
title: [CUDA 基础]2.3 组织并行线程 categories: CUDA Freshman tags: Thread Block Grid toc: true date: 2018-03 ...
- CUDA编程模型
1. 典型的CUDA编程包括五个步骤: 分配GPU内存 从CPU内存中拷贝数据到GPU内存中 调用CUDA内核函数来完成指定的任务 将数据从GPU内存中拷贝回CPU内存中 释放GPU内存 *2. 数据 ...
- CUDA刷新器:CUDA编程模型
CUDA刷新器:CUDA编程模型 CUDA Refresher: The CUDA Programming Model CUDA,CUDA刷新器,并行编程 这是CUDA更新系列的第四篇文章,它的目标是 ...
- CUDA编程模型之内存管理
CUDA编程模型假设系统是由一个主机和一个设备组成的,而且各自拥有独立的内存. 主机:CPU及其内存(主机内存),主机内存中的变量名以h_为前缀,主机代码按照ANSI C标准进行编写 设备:GPU及其 ...
- CUDA学习笔记(一)——CUDA编程模型
转自:http://blog.sina.com.cn/s/blog_48b9e1f90100fm56.html CUDA的代码分成两部分,一部分在host(CPU)上运行,是普通的C代码:另一部分在d ...
- CUDA编程之快速入门
CUDA(Compute Unified Device Architecture)的中文全称为计算统一设备架构.做图像视觉领域的同学多多少少都会接触到CUDA,毕竟要做性能速度优化,CUDA是个很重要 ...
- CUDA编程之快速入门【转】
https://www.cnblogs.com/skyfsm/p/9673960.html CUDA(Compute Unified Device Architecture)的中文全称为计算统一设备架 ...
- cuda编程基础
转自: http://blog.csdn.net/augusdi/article/details/12529247 CUDA编程模型 CUDA编程模型将CPU作为主机,GPU作为协处理器(co-pro ...
随机推荐
- Spring Boot程序的执行流程
Spring Boot的执行流程如下图所示:(图片来源于网络) 上图为SpringBoot启动结构图,我们发现启动流程主要分为三个部分,第一部分进行SpringApplication的初始化模块,配置 ...
- 查看win10系统产品密钥
查看win10系统产品密钥 1.win+R 输入Regedit运行注册表 2.找到(在HKEY_LOCAL_MACHINE–>SOFTWARE–>Microsoft–>Windows ...
- JAVA IO流 InputStream流 Read方法
read()首先我们来看这个没有参数的read方法,从(来源)输入流中(读取的内容)读取数据的下一个字节到(去处)java程序内部中,返回值为0到255的int类型的值,返回值为字符的ACSII值(如 ...
- laravel 修改时邮箱字段唯一性验证时忽略指定 ID
- poi 工具类
<!--POI--> <dependency> <groupId>org.apache.poi</groupId> <artifactId> ...
- 2018-2019-2 20165313 《网络对抗技术》 Exp6 信息搜集与漏洞扫描
一.实践目标 掌握信息搜集的最基础技能与常用工具的使用方法. 二.实践内容. (1)各种搜索技巧的应用 (2)DNS IP注册信息的查询 (3)基本的扫描技术:主机发现.端口扫描.OS及服务版本探测. ...
- Ubuntu网络不通解决办法
如下问题: 尝试和Host主机互ping也不通, Ubuntu: vmware 桥接模式 IP:192.168.1.202/24 gateway:192.168.1.1 Host主机:网络正常 IP: ...
- java_集合类_简
Collection 来源于Java.util包,实用常用的数据结构,字面意思就是容器 主要方法 boolean add(Object o)添加对象到集合 boolean remove(Object ...
- SOFARPC —— SPI 解析
一.前言 我之前研究过微博的Motan框架(当时接触的第一个RPC框架),当时懵懵懂懂,现在,上手SOFARPC框架,感觉比较轻松,事物的本质都是相通的.以前写博文,会逐行分析源码,慢慢地发现,源码其 ...
- 关于定时器setTimeout()方法的实践--巧解bug
_使用开发环境:UAP:_ _框架:JQuery.MX:_ 最近的开发的页面中,有一处需要在提交的 datagrid里启用行编辑,就会发生奇怪的bug,编辑过程中如图所示不移开焦点直接点保存,那么已输 ...