转:vw适配中使用伪类选择器遇到的问题
地址:https://blog.csdn.net/perryliu6/article/details/80965734
在使用vue init webpack构建的项目中,一开始我准备使用rem布局,以前使用rem布局,都采用的是AMFE团队发布的lib-flexible,但是在flexible的redeme的一开始 我就读到了这么一段话,官方指引我使用vw实现适配
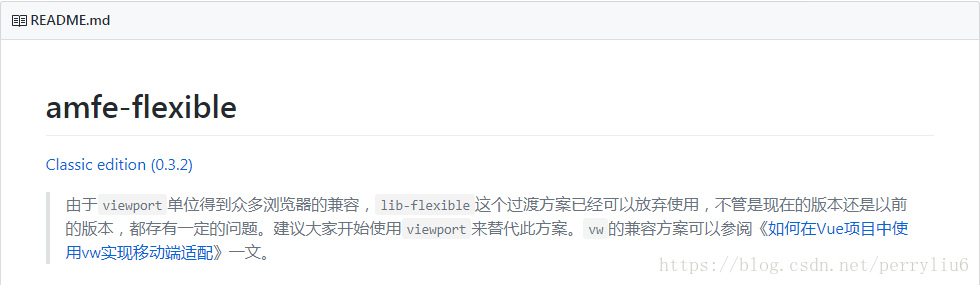
依据引导,我启用了postcss插件,并且学习到了vw适配,vue构建项目的根目录下的.postcssrc.js文件中的配置如下(摘自https://www.w3cplus.com/mobile/vw-layout-in-vue.html):
module.exports = {
"plugins": {
"postcss-import": {},
"postcss-url": {},
"postcss-aspect-ratio-mini": {},
"postcss-write-svg": {
utf8: false
},
"postcss-cssnext": {},
"postcss-px-to-viewport": {
viewportWidth: , // (Number) The width of the viewport.
viewportHeight: , // (Number) The height of the viewport.
unitPrecision: , // (Number) The decimal numbers to allow the REM units to grow to.
viewportUnit: 'vw', // (String) Expected units.
selectorBlackList: ['.ignore', '.hairlines'], // (Array) The selectors to ignore and leave as px.
minPixelValue: , // (Number) Set the minimum pixel value to replace.
mediaQuery: false // (Boolean) Allow px to be converted in media queries.
},
"postcss-viewport-units":{
filterRule: rule => rule.selector.indexOf('::after') === - && rule.selector.indexOf('::before') === - && rule.selector.indexOf(':after') === - && rule.selector.indexOf(':before') === -
},
"cssnano": {
preset: "advanced",
autoprefixer: false,
"postcss-zindex": false
}
}
}
重点来了
与文章内有所不同的是
官方给出的配置项是这样的
"postcss-viewport-units":{}
我写的配置项是这样的
"postcss-viewport-units":{
filterRule: rule => rule.selector.indexOf('::after') === - && rule.selector.indexOf('::before') === - && rule.selector.indexOf(':after') === - && rule.selector.indexOf(':before') === -
}
在转化过程中我加入了过滤器,用来回避伪类选择器
为什么要这么做呢? 举个栗子 看下图
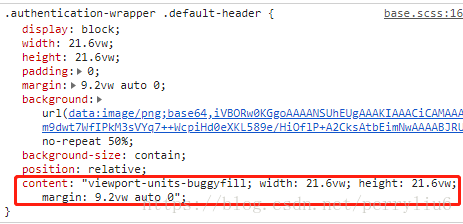
注意到这个content了吗? 每一个元素都带有content属性 我没有写啊
普通div有这个不要紧 但是伪类选择器带有这种东西 是会显示在页面上的,这东西怎么来的?
看它的内容 viewport-units-buggyfill 去github搜一下
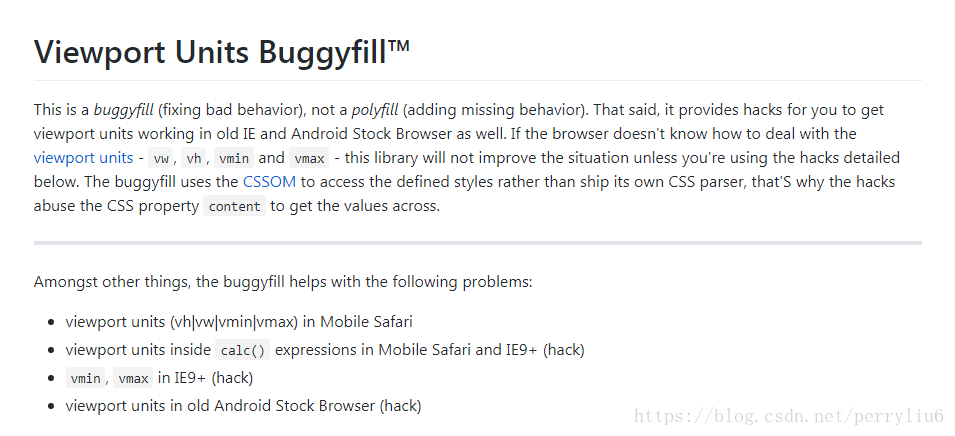
从描述来看 这个插件的主要作用就是 csshack (不知道hack的百度一下,我这就不说了)
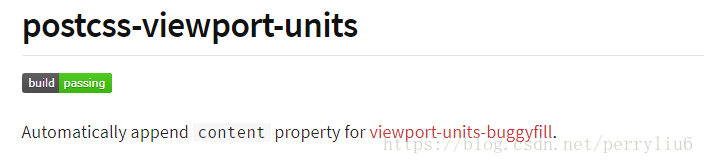
多方查找发现 为了hack而添加content属性的原来是下面这个(截图来自npmjs.com)
关于postcss-viewport-units插件,npm对它的描述是 自动给html元素添加content属性(如下图)
再来看一下这个插件的readme
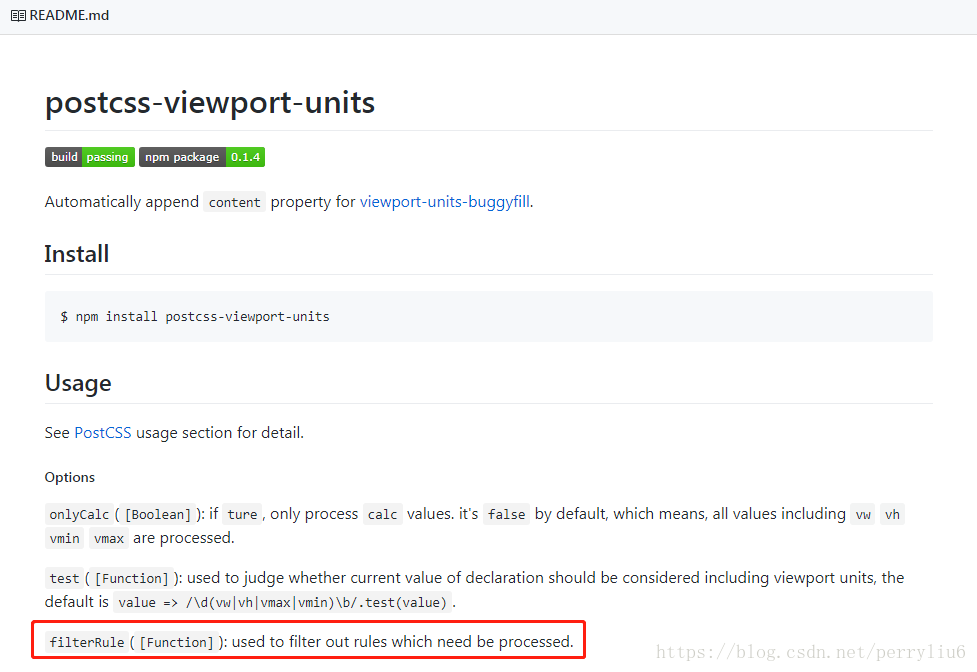
配置一个过滤规则函数是不是就可以回避这个问题了 但是这个函数怎么写?
在源码的test文件夹下 我看到了这个

写上去后发现成功规避掉了::after,那::before呢?
转:vw适配中使用伪类选择器遇到的问题的更多相关文章
- CSS3中的伪类选择器详解
类选择器和伪类选择器区别 类选择器我们可以随意起名,而伪类选择器是CSS中已经定义好的选择器,不可以随意起名. 伪类选择器以及伪元素 我们把它放到这里 p.aaas{ text-align: le ...
- css3中的伪类选择器
一.动态伪类 动态伪类,因为这些伪类并不存在于HTML中,而只有当用户和网站交互的时候才能体现出来,动态伪类包含两种,第一种是我们在链接中常看到的锚点伪类,如":link",&qu ...
- CSS3中结构伪类选择器——root、not、empty、target选择器
1.root选择器 将样式绑定到页面的根元素中.根元素是指位于文档树中最顶层结构的元素,在HTML页面中就是指包含整个页面的<html>部分. <style type="t ...
- CSS3中only-child伪类选择器
<body> <style type="text/css"> //只对li1设置样式 li:nth-child(1):nth-last-child(1){ ...
- css 中的伪类选择器before 与after
.cf:after,.cf:before {content: " "; display: table;} .cf:after {clear: both;} :before是因为ta ...
- Wx-小程序中使用伪类选择器实现border-1px
.borders::before{ position: absolute; left:; top:; content: " "; width: 100%; height: 1px; ...
- H5与CS3权威下.19 选择器(2)结构性伪类选择器
1.CSS中的伪类选择器及伪元素 (1)与自定义的class类选择器不同,伪类选择器是CSS中已经定义好的选择器. eg:a:link{color:#ff0000;} (2)伪元素的使用方法: 选择器 ...
- ie8不支持伪类选择器的解决方案
引用jQuery的插件jquery.pseudo.js插件内容: (function($){ var patterns = { text: /^['"]?(.+?)["']?$/, ...
- js进阶 10-8 伪类选择器有哪几类(自己不用,永远不是自己的)
js进阶 10-8 伪类选择器有哪几类(自己不用,永远不是自己的) 一.总结 一句话总结:自己不用,永远不是自己的. 0.学而不用,却是为何? 自己不用,永远不是自己的,有需求的时候要想到它,然后操作 ...
随机推荐
- Content Security Policy介绍
Content Security Policy https://content-security-policy.com/ The new Content-Security-Policy HTTP re ...
- hadoop3.x的安装
请看https://www.cnblogs.com/garfieldcgf/p/8119506.html
- 遍历页面上的checkbox
$("#Button1").click(function () { $("input[type='checkbox']").each(function () { ...
- 【bzoj 3524】[Poi2014]Couriers
Description 给一个长度为n的序列a.1≤a[i]≤n.m组询问,每次询问一个区间[l,r],是否存在一个数在[l,r]中出现的次数大于(r-l+1)/2.如果存在,输出这个数,否则输出0. ...
- js apply使用
js中apply方法的使用 1.对象的继承,一般的做法是复制:Object.extend prototype.js的实现方式是: Object.extend = function(destinati ...
- zsh,oh-my-zsh,antigen使用记录
关于 'zsh': 又名 z shell,‘z' 是26个字母中的最后一位,故取意为“终极终端”. 关于 'oh-my-zsh': 是一个针对zsh的模板化的z shell配置脚本,目标是配置一个好用 ...
- 函数语法:Js之on和addEventListener的使用与不同
一.addEventListener语法 DOM标准:elem.addEventListener("事件名",函数对象,是否在捕获阶段触发) ---是否在捕获阶段触发= true/ ...
- 第19月第17天 uitextview 文本垂直居中 uiimage中间不拉伸
1. open class VericalCenteringScrollView: UIScrollView { override open var contentOffset: CGPoint { ...
- linux如何查看端口号被哪个进程占用
1.lsof -i:端口号 lsof(list open files) 2.netstat -tunlp |grep 端口号 t:tcp u:udp n:拒绝显示别名 l:仅显示listen的服务状态 ...
- TMS 控件测试
//TMS 控件测试nxflpnl1: TNxFlipPanel; 控件 有一个标题的panel 可以随意收展 TNxBusy; 有很均匀分布的四块区域,但是不像 TFlowPanel nxhtmlb ...