Hadoop学习笔记(四):Yarn和MapReduce
1. 先关闭掉所有的防火墙(master和所有slave)
2. 配置yarn-site.xml文件(配置所有机器,此时没有启动hadoop服务)
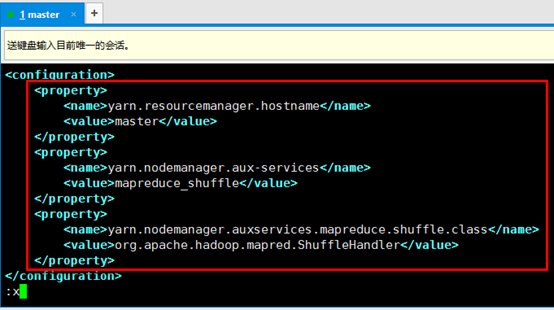
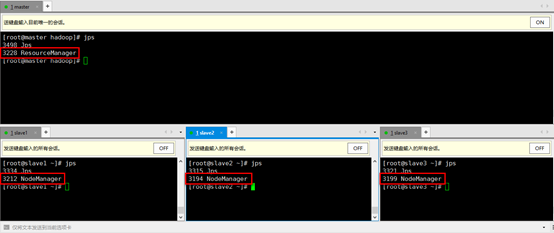
3. 启Yarn,输入要命令start-yarn.sh,用jps检测,看到如下情况表示启动成功
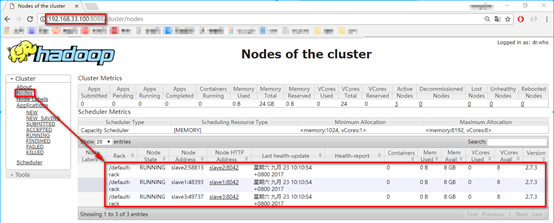
4. 在宿主机浏览器上进行查看,输入地址master:8088,可以看到Yarn的相关情况:
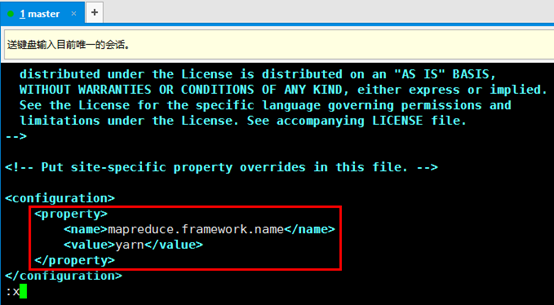
5. 下面我们在Yarn上跑一个计算,由于我们需要计算的文档存放的hdfs上,因此我们首先需要启动hadoop服务。然后需要指定MapReduce跑在Yarn上,配置mapred-site.xml(听老师讲的时候,配置的是这个文件,可是我的机器上没有这个文件,只有mapred-queues.xml.template,于是我copy了它一份,把名字改成了mapred-queues.xml)
6. 首先在本地创建一个文件,用于计算的时候使用:
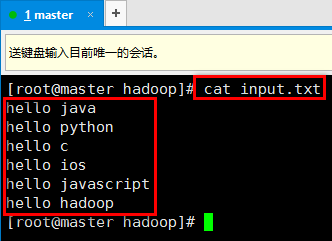
7. 在hadoop根目录下创建一个文件夹input,并将上述创建的文件上传到该目录下:

8. 计算的功能是,计算该文件中有多少个单词,每个单词出现的次数。查找一下该例子程序:
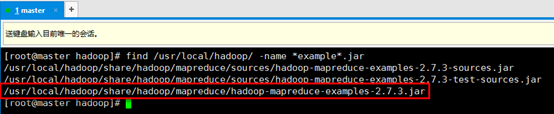
9. 运行该例子程序,输入命令:
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /input/input.txt /output
hadoop jar为运行jar包,后面跟的是jar包的完全路径,wordcount为指定该jar中的方法,/input/input.txt为要操作的文件,也可以指定一个目录,那就hadoop就会统计目录下的所有文件内容,再后边的/output为执行结果的输出目录。
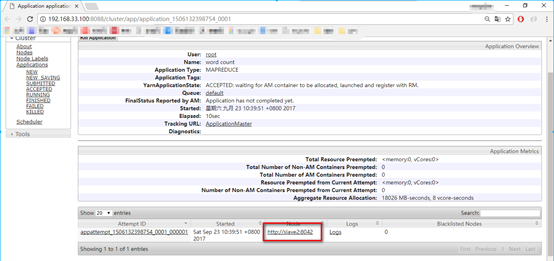
10. 在宿主机浏览器中查看,点击Applicatons,发现有一个任务了

11. 点击该任务的ID,进入查看该任务的详情,发现该任务在slave2上运行,点击该链接进入查看(打不开的话尝试使用slave2的ip加端口8082)
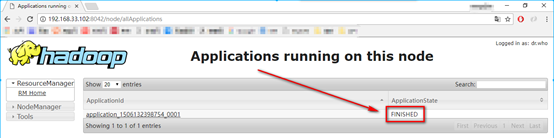
12. 进入slave2后,点击List of,发现该任务已经完成了
13. 查看一下刚才任务的输出目录

14. 查看这个输出文件

Hadoop学习笔记(四):Yarn和MapReduce的更多相关文章
- Hadoop学习笔记四
一.fsimage,edits和datanode的block在本地文件系统中位置的配置 fsimage:hdfs-site.xml中的dfs.namenode.name.dir 值例如file:// ...
- Hadoop 学习笔记 (十一) MapReduce 求平均成绩
china:张三 78李四 89王五 96赵六 67english张三 80李四 82王五 84赵六 86math张三 88李四 99王五 66赵六 77 import java.io.IOEx ...
- Hadoop 学习笔记 (十) MapReduce实现排序 全局变量
一些疑问:1 全排序的话,最后的应该sortJob.setNumReduceTasks(1);2 如果多个reduce task都去修改 一个静态的 IntWritable ,IntWritable会 ...
- hadoop学习笔记(四)——eclipse+maven+hadoop2.5.2源代码
Eclipse同maven进口hadoop源代码 1) 安装和配置maven环境变量 M2_HOME: D:\profession\hadoop\apache-maven-3.3.3 PATH: % ...
- hadoop学习笔记(四):HDFS文件权限,安全模式,以及整体注意点总结
本文原创,转载注明作者和原文链接! 一:总结注意点: 到现在为止学习到的角色:三个NameNode.SecondaryNameNode.DataNode 1.存储的是每一个文件分割存储之后的元数据信息 ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
- Hadoop学习笔记—5.自定义类型处理手机上网日志
转载自http://www.cnblogs.com/edisonchou/p/4288737.html Hadoop学习笔记—5.自定义类型处理手机上网日志 一.测试数据:手机上网日志 1.1 关于这 ...
- Hadoop学习笔记(7) ——高级编程
Hadoop学习笔记(7) ——高级编程 从前面的学习中,我们了解到了MapReduce整个过程需要经过以下几个步骤: 1.输入(input):将输入数据分成一个个split,并将split进一步拆成 ...
- Hadoop学习笔记(6) ——重新认识Hadoop
Hadoop学习笔记(6) ——重新认识Hadoop 之前,我们把hadoop从下载包部署到编写了helloworld,看到了结果.现是得开始稍微更深入地了解hadoop了. Hadoop包含了两大功 ...
- Hadoop学习笔记(2)
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
随机推荐
- Madlibs
name1 = input('请输入一个名字:') name2 = input('再输入一个名字:') animal = input('请输入一种动物:') print('一二三四五{}上山打{}不在 ...
- 20175316盛茂淞 2018-2019-2 《Java程序设计》第6周学习总结
20175316盛茂淞 2018-2019-2 <Java程序设计>第6周学习总结 教材学习内容总结 第7章 内部类与异常类 1.使用 try.catch Java中所有信息都会被打包为对 ...
- .gitignore语法
没嘛用 “#”表示注释 “!”表示取消忽略 空行不作匹配 若匹配语句中无“/ ” ,便将其视为一个 glob匹配,如'abc'可以匹配 ' abc' , 'cd/abc' , 'ef/abcde.tx ...
- 采用Google预训bert实现中文NER任务
本博文介绍用Google pre-training的bert(Bidirectional Encoder Representational from Transformers)做中文NER(Name ...
- LOJ-10096(强连通+bfs)
题目链接:传送门 思路: 强连通缩点,重建图,然后广搜找最长路径. #include<iostream> #include<cstdio> #include<cstrin ...
- Win7 VS2017 NASM编译FFMPEG(2018.12.22)
今天无意中在gayhub发现个牛逼工程,全VS工程编译FFMPEG库,包括依赖库全是VS生成的,无需Mingw等Linux环境. 简单记录下过程,以防将来重装系统等情况,备忘. https://git ...
- elasticsearch 修改磁盘比例限制
命令为:下面也可以单独进行限制,官网说可以设置具体数值,但是无没成功,有成功的大神可以在下面告诉我一下哈 PUT _cluster/settings{ "persistent": ...
- 【转】python3 内循环中遍历map,遍历一遍后再次进入内循环,map为空
今天在使用python map的过程中,发现了一个奇怪问题,map遍历完成后,再次访问map,发现map为空了,特记录下来,以备日后查看. 如下代码,期望的结果是每次从外循环进入内循环,map都从头开 ...
- Debian中配置静态IP
默认安装Debian的时候是用dhcp服务的,有时我们需要设置一下静态IP. 一共涉及两个文件的修改 /etc/network/interfaces auto eth0#iface eth0 inet ...
- 弹性盒子模型属性之flex-grow
在学习弹性盒子模型的时候,有几个属性常常让同学们感觉头痛, 不知到最后得到的效果数值到底是怎样计算得来的,那么不要慌,稳住,我们能赢 !!!今天就让我们先来看看flex-grow这个属性 flex-g ...