SDOI2016 R1做题笔记
SDOI2016 R1做题笔记
经过很久很久的时间,shzr终于做完了SDOI2016一轮的题目。
其实没想到竟然是2016年的题目先做完,因为14年的六个题很早就做了四个了,但是后两个有点开不动...
那么就顺着开始说:
储能表:https://lydsy.com/JudgeOnline/problem.php?id=4513
题意概述:给定一张大表格,i行j列的数是 $i$ $xor$ $j$,多组询问,求
$\sum_{i=0}^{n-1}\sum_{j=0}^{m-1}max((i \bigoplus j)-k,0)$
$T=5000,n≤10^{18},m≤10^{18},k≤10^{18},p≤10^9$
几个月前第一次看这道题的反应:这能做?弃了弃了。今天早上再看时发现也没那么难。
如果想着正面去处理异或值减k这种操作,会非常棘手,因为异或的一个很好的性质就是各位独立,而减法破坏了这样的性质。发现如果异或值小于 $k$ 对答案就没有贡献,所以可以只考虑异或值大于 $k$ 的部分,这样就消除了max操作的影响。把减法拆开,先算前半部分的和,再计算一下需要减掉几个k即可。因为异或的每一位是独立的,可以想到二进制数位dp,状态还是很好设计的:$dp[i][j][k][z]$表示填到第 $i$ 位,是否卡 $n$ 的上界,是否卡 $m$ 的上界,是否卡 $k$ 的下界的方案数,再列一个类似的式子表示和,转移显然。
实际写程序的时候要注意:方案数为0(可能是恰好为模数的倍数),方案值的和不一定为0,这时不要直接跳出循环。第一次交的时候没有注意到这一点,只有10分,要是省选遇上这种事可就...
# include <cstdio>
# include <iostream>
# include <cstring>
# define R register int
# define ll long long using namespace std; int T,n[],m[],k[];
ll a,b,d,s[][][][],c[][][][],t,su,nj,nl,nz,p; void div (ll x,int *a)
{
for (R i=;i<=;++i)
a[-i+]=(x&(1LL<<i))?:;
} ll ad (ll a,ll b,ll p) { a+=b; if(a>=p) a-=p; return a; } int main()
{
scanf("%d",&T);
while(T--)
{
scanf("%lld%lld%lld%lld",&a,&b,&d,&p);
a--,b--;
div(a,n); div(b,m); div(d,k);
memset(s,,sizeof(s)); memset(c,,sizeof(c));
c[][][][]=;
for (R i=;i<=;++i)
for (R j=;j<=;++j)
for (R l=;l<=;++l)
for (R z=;z<=;++z)
{
if(s[i][j][l][z]==&&c[i][j][l][z]==) continue;
t=c[i][j][l][z]%p; su=s[i][j][l][z]%p;
for (R v=;v<=;++v)
for (R w=;w<=;++w)
{
if(j==&&v>n[i+]) continue;
if(l==&&w>m[i+]) continue;
if(z==&&(v^w)<k[i+]) continue;
if(j==&&v==n[i+]) nj=; else nj=;
if(l==&&w==m[i+]) nl=; else nl=;
if(z==&&(v^w)==k[i+]) nz=; else nz=;
c[i+][nj][nl][nz]=ad(c[i+][nj][nl][nz],t,p);
s[i+][nj][nl][nz]=(s[i+][nj][nl][nz]%p+su*2LL+t*(v^w))%p;
}
}
ll ans=;
d%=p;
for (R i=;i<=;++i)
for (R j=;j<=;++j)
for (R l=;l<=;++l)
ans=(ans+s[][i][j][l]-d*c[][i][j][l]%p+p)%p;
printf("%lld\n",(ans+p)%p);
}
return ;
}
D1T1
数字配对:https://lydsy.com/JudgeOnline/problem.php?id=4514
直接粘题面.jpg
“有 $n$ 种数字,第 $i$ 种数字是 $a_i$、有 $b_i$ 个,权值是 $c_i$。
若两个数字 $(a_i,a_j)$ 满足,$a_i$ 是 $a_j$ 的倍数,且 $a_i/a_j$ 是一个质数,
那么这两个数字可以配对,并获得 $c_i×c_j$ 的价值。
一个数字只能参与一次配对,可以不参与配对。
在获得的价值总和不小于 $0$ 的前提下,求最多进行多少次配对。”
...第一次看到以为是一般图的最大权匹配,这能做?后来又复习网络流的时候才发现并不是一般图。
发现两个数如果满足可以匹配的标准,那么它们分解质因数后的指数和必然一奇一偶,所以是二分图,二分图最大匹配就很好做啦。等等,它要求的并不是最大匹配,而是最多能匹配几个。考虑网络流的贪心过程,每次走的增广路都是边权最大的,所以如果某一次发现增广完以后价值和小于0了,那么以后更不可能加回来,这时退出即可。
这题第一次交30...因为我自己yy了一个错误的二分图染色算法...
# include <cstdio>
# include <iostream>
# include <cstring>
# include <queue>
# define inf
# define R register int
# define ll long long using namespace std; const int maxn=;
int n,a[maxn],b[maxn],c[maxn],vis[maxn],h=,firs[maxn],s,t,Fl[maxn],pre[maxn],col[maxn],f[maxn],tot;
ll max_cos,max_flow,d[maxn];
struct edge { int too,nex,cap; ll co; }g[(maxn+maxn*maxn)<<],ed[maxn*maxn*];
queue <int> q; inline int read()
{
R x=,f=;
char c=getchar();
while (!isdigit(c)) { if(c=='-') f=-f; c=getchar(); }
while (isdigit(c)) x=(x<<)+(x<<)+(c^),c=getchar();
return x*f;
} inline void add (int x,int y,int cap,ll co)
{
g[++h].nex=firs[x];
g[h].too=y;
g[h].cap=cap;
g[h].co=co;
firs[x]=h;
g[++h].nex=firs[y];
g[h].too=x;
g[h].cap=;
g[h].co=-co;
firs[y]=h;
} inline bool check (int x)
{
if(x==) return false;
for (R i=;i*i<=x;++i) if(x%i==) return false;
return true;
} bool bfs ()
{
memset(d,,sizeof(d));
int minn=d[];
d[s]=,Fl[s]=inf,pre[s]=;
q.push(s);
int j,beg;
while(q.size())
{
beg=q.front();
q.pop();
vis[beg]=false;
for (R i=firs[beg];i;i=g[i].nex)
{
if(g[i].cap<=) continue;
j=g[i].too;
if(d[beg]+g[i].co<=d[j]) continue;
d[j]=d[beg]+g[i].co;
Fl[j]=min(Fl[beg],g[i].cap);
pre[j]=i;
if(!vis[j]) vis[j]=true,q.push(j);
}
}
if(d[t]==minn) return false;
if(d[t]*Fl[t]+max_cos<)
{
max_flow+=max_cos/(-d[t]);
return false;
}
return true;
} inline void dfs ()
{
int i=,x=t;
while(x!=s)
{
i=pre[x];
g[i].cap-=Fl[t];
g[i^].cap+=Fl[t];
x=g[i^].too;
}
max_flow+=Fl[t];
max_cos+=Fl[t]*d[t];
} inline void ad (int x,int y)
{
ed[++tot].nex=f[x];
ed[tot].too=y;
f[x]=tot;
} void pt (int x)
{
int j;
for (R i=f[x];i;i=ed[i].nex)
{
j=ed[i].too;
if(col[j]!=) continue;
col[j]=-col[x];
pt(j);
}
} int main()
{
n=read();
t=n+;
for (R i=;i<=n;++i) a[i]=read();
for (R i=;i<=n;++i) b[i]=read();
for (R i=;i<=n;++i) c[i]=read();
for (R i=;i<=n;++i)
for (R j=;j<=n;++j)
if(a[i]%a[j]==&&check(a[i]/a[j])) ad(i,j),ad(j,i);
for (R i=;i<=n;++i) if(col[i]==) col[i]=,pt(i);
for (R i=;i<=n;++i)
if(col[i]==) add(s,i,b[i],);
else add(i,t,b[i],);
for (R i=;i<=n;++i)
for (R j=;j<=n;++j)
if(a[i]%a[j]==&&check(a[i]/a[j]))
{
if(col[i]==) add(i,j,inf,1LL*c[i]*c[j]);
else add(j,i,inf,1LL*c[i]*c[j]);
}
while(bfs())
dfs();
printf("%lld",max_flow);
return ;
}
D1T2
游戏:https://lydsy.com/JudgeOnline/problem.php?id=4515
题意概述:给定一棵树,支持在一条路径上添加一次函数,以及询问一条路径上的最大值。$n,m<=10^5$
关于这道题还有一点故事:我刚看到这道题的时候,就跟asuldb说“SDOI2016好像不难,怎么还出个李超树板子啊”,这句话说出去之后如果再做不出来就不大好了。于是写了几乎整整一下午才做出来,“思考5分钟,写题5小时”。
看到这种数据结构题肯定要先写个对拍,然而这道题的暴力挺难写的(当然还是比正解简单得多),写了100多行。
# include <cstdio>
# include <iostream>
# include <cstring>
# define R register int
# define ll long long using namespace std; const int maxn=;
const ll inf=123456789123456789LL;
int n,m,h,firs[maxn],x,y,w,dep[maxn],f[maxn][],s,t;
ll l[maxn],v[maxn],a,b,ans;
struct edge { int too,nex,w; }g[maxn<<]; void add_ed (int x,int y,int w)
{
g[++h].nex=firs[x];
firs[x]=h;
g[h].too=y;
g[h].w=w;
} int lca (int x,int y)
{
if(dep[x]>dep[y]) swap(x,y);
for (R i=;i>=;--i) if(dep[y]-(<<i)>=dep[x]) y=f[y][i];
if(x==y) return x;
for (R i=;i>=;--i) if(f[x][i]!=f[y][i]) x=f[x][i],y=f[y][i];
return f[x][];
} void dfs (int x)
{
int j;
for (R i=firs[x];i;i=g[i].nex)
{
j=g[i].too;
if(dep[j]) continue;
l[j]=l[x]+g[i].w; dep[j]=dep[x]+;
f[j][]=x;
for (R k=;k<=;++k) f[j][k]=f[ f[j][k-] ][k-];
dfs(j);
}
} ll dis (int x,int y)
{
int a=lca(x,y);
return l[x]+l[y]-*l[a];
} void ask (int s,int t)
{
ans=min(ans,v[s]);
ans=min(ans,v[t]);
while(s!=t)
{
if(dep[s]<dep[t]) t=f[t][];
else s=f[s][];
ans=min(ans,v[s]);
ans=min(ans,v[t]);
}
} void add (int s,int t,ll a,ll b)
{
int x=s,y=t;
v[x]=min(v[x],a*dis(s,x)+b);
v[y]=min(v[y],a*dis(s,y)+b);
while(x!=y)
{
if(dep[x]<dep[y]) y=f[y][];
else x=f[x][];
v[x]=min(v[x],a*dis(s,x)+b);
v[y]=min(v[y],a*dis(s,y)+b);
}
} int main()
{
freopen("data.in","r",stdin);
freopen("std.out","w",stdout); scanf("%d%d",&n,&m);
for (R i=;i<n;++i)
{
scanf("%d%d%d",&x,&y,&w);
add_ed(x,y,w); add_ed(y,x,w);
}
for (R i=;i<=n;++i) v[i]=inf;
memset(l,-,sizeof(l));
l[]=; dep[]=;
dfs();
int opt=;
for (R i=;i<=m;++i)
{
scanf("%d",&opt);
if(opt==)
{
scanf("%d%d%lld%lld",&s,&t,&a,&b);
add(s,t,a,b);
}
else
{
scanf("%d%d",&s,&t);
ans=inf;
ask(s,t);
printf("%lld\n",ans);
}
}
return ;
}
对拍
(恭喜这个程序成为我博客里第一篇暴力)
话说回来,这道题真的就是个模板题,只不过是复杂了很多的模板题。李超树套个树剖,完事。细节问题比较复杂。
首先看插入路径:
路径上的点到指定点的距离这一信息比较麻烦,所以将一条路径从LCA处拆开,将距离全部转化为根路径前缀和。细节就不说了,注意分出来的两条路径的ab和之前不同。
对于线段树上的一个节点,如果它有“优势线段”,那么由于一次函数是单调的,最小值必然在端点处取到。除此以外,还有可能是两个子节点的最小值。
然后看查询:
代码里把路径拆开了分别查询,现在想想好像没必要。
一般写的李超树都是单点查询,所以写区间查询时要多注意。首先将区间分为三类:被询问区间包含的,包含了询问区间的,与询问区间有交集但不符合之前两种情况的;
对于第一种,直接返回区间的最小值;
对于第二种,肯定还是要往下分询问的,但还有一种情况,就是此区间的“优势线段”在询问区间上的最小值;
对于第三种,除了上述情况外,还有可能是线段树区间的端点在自己区间的“优势线段”所取到的值(前提是得在询问区间内),也可以是询问区间在这里取到的最小值(当然也得在线段树区间内);
是不是非常复杂...一个比较好写的做法是直接无脑讨论四个端点,像这样:
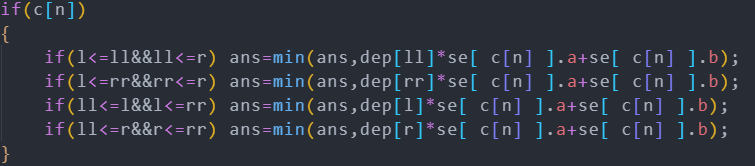
做比较复杂的数据结构题,如果想第一次就多得点分,暴力对拍是必不可少的。利用随机生成的小数据,我查出了10+个细节错误和刚刚那些要注意的细节问题(这么多细节哪能一下子全想到还不都是对拍)。最后分析一下复杂度:树剖一个log,李超树两个log,总的来说三个log,但是常数小,跑不满。
# include <cstdio>
# include <iostream>
# include <cstring>
# define R register int
# define LL long long
# define nl (n<<)
# define nr (n<<|) using namespace std; const int maxn=;
const LL inf=123456789123456789LL;
int n,m,x,y,w,h,firs[maxn],seg_cnt=,c[maxn<<],S,T,d[maxn];
int id[maxn],Top[maxn],siz[maxn],son[maxn],f[maxn],cnt;
LL l[maxn],t[maxn<<],dep[maxn],a,b;
struct edge { int too,nex,w; }g[maxn<<];
struct seg { LL a,b; }se[maxn<<]; void add_ed (int x,int y,int w);
int lca (int x,int y);
LL dis (int x,int y);
void dfs1 (int x);
void dfs2 (int x,int Tp);
void add_p (int x,int y,int v);
void add_t (int n,int l,int r,int v);
void add (int n,int l,int r,int ll,int rr,int v);
LL ask_p (int x,int y);
LL ask (int n,int l,int r,int ll,int rr);
void build (int n,int l,int r);
void update (int n);
LL read(); int main()
{
n=read(),m=read();
for (R i=;i<n;++i)
{
x=read(),y=read(),w=read();
add_ed(x,y,w); add_ed(y,x,w);
}
l[]=; d[]=;
dfs1(); dfs2(,); build(,,n);
int opt=;
for (R i=;i<=m;++i)
{
opt=read();
if(opt==)
{
S=read(),T=read(),a=read(),b=read();
int LA=lca(S,T);
se[++seg_cnt].b=b+l[S]*a; se[seg_cnt].a=-a;
add_p(S,LA,seg_cnt);
se[++seg_cnt].a=a; se[seg_cnt].b=a*l[S]-*l[LA]*a+b;
add_p(LA,T,seg_cnt);
}
else
{
S=read(),T=read();
int LA=lca(S,T);
LL ans=min(ask_p(S,LA),ask_p(LA,T));
printf("%lld\n",ans);
}
}
return ;
} LL read()
{
LL x=,f=;
char c=getchar();
while (!isdigit(c)) { if(c=='-') f=-f; c=getchar(); }
while (isdigit(c)) x=(x<<)+(x<<)+(c^),c=getchar();
return x*f;
} void update (int n)
{
t[n]=min(t[n],t[nl]);
t[n]=min(t[n],t[nr]);
} void build (int n,int l,int r)
{
t[n]=inf;
if(l==r) return;
int mid=(l+r)>>;
build(nl,l,mid); build(nr,mid+,r);
} void add_ed (int x,int y,int w)
{
g[++h].nex=firs[x];
firs[x]=h;
g[h].too=y;
g[h].w=w;
} int lca (int x,int y)
{
while(Top[x]!=Top[y])
{
if(d[ Top[x] ]>d[ Top[y] ]) swap(x,y);
y=f[ Top[y] ];
}
return (d[x]<d[y])?x:y;
} LL dis (int x,int y)
{
int a=lca(x,y);
return l[x]+l[y]-*l[a];
} void dfs1 (int x)
{
int j,maxs=-; siz[x]=;
for (R i=firs[x];i;i=g[i].nex)
{
j=g[i].too;
if(f[x]==j) continue;
l[j]=l[x]+g[i].w;
f[j]=x; d[j]=d[x]+;
dfs1(j);
siz[x]+=siz[j];
if(siz[j]>=maxs) maxs=siz[j],son[x]=j;
}
} void dfs2 (int x,int Tp)
{
id[x]=++cnt; Top[x]=Tp; dep[ cnt ]=l[x];
if(!son[x]) return;
dfs2(son[x],Tp);
int j;
for (R i=firs[x];i;i=g[i].nex)
{
j=g[i].too;
if(son[x]==j||f[x]==j) continue;
dfs2(j,j);
}
} void add_p (int x,int y,int v)
{
while(Top[x]!=Top[y])
{
if(d[ Top[x] ]>d[ Top[y] ]) swap(x,y);
add(,,n,id[ Top[y] ],id[y],v);
y=f[ Top[y] ];
}
if(d[x]>d[y]) swap(x,y);
add(,,n,id[x],id[y],v);
} void add_t (int n,int l,int r,int v)
{
if(!c[n]) { t[n]=min(t[n],min(dep[l]*se[v].a+se[v].b,dep[r]*se[v].a+se[v].b)); c[n]=v; return; }
int x=c[n],mid=(l+r)>>;
if(l!=r) update(n);
t[n]=min(t[n],min(dep[l]*se[v].a+se[v].b,dep[r]*se[v].a+se[v].b));
if(dep[l]*se[v].a+se[v].b>=dep[l]*se[x].a+se[x].b&&dep[r]*se[v].a+se[v].b>=dep[r]*se[x].a+se[x].b) return;
if(dep[l]*se[v].a+se[v].b<=dep[l]*se[x].a+se[x].b&&dep[r]*se[v].a+se[v].b<=dep[r]*se[x].a+se[x].b) { c[n]=v; return; }
if(se[x].a>=se[v].a)
{
if(se[x].a*dep[mid]+se[x].b>=se[v].a*dep[mid]+se[v].b) c[n]=v,add_t(nl,l,mid,x);
else add_t(nr,mid+,r,v);
}
else
{
if(se[x].a*dep[mid]+se[x].b>=se[v].a*dep[mid]+se[v].b) c[n]=v,add_t(nr,mid+,r,x);
else add_t(nl,l,mid,v);
}
if(l!=r) update(n);
} void add (int n,int l,int r,int ll,int rr,int v)
{
if(ll<=l&&r<=rr) add_t(n,l,r,v);
else
{
int mid=(l+r)>>;
if(ll<=mid) add(nl,l,mid,ll,rr,v);
if(rr>mid) add(nr,mid+,r,ll,rr,v);
update(n);
}
} LL ask_p (int x,int y)
{
LL ans=inf;
while(Top[x]!=Top[y])
{
if(d[ Top[x] ]>d[ Top[y] ]) swap(x,y);
ans=min(ans,ask(,,n,id[ Top[y] ],id[y]));
y=f[ Top[y] ];
}
if(d[x]>d[y]) swap(x,y);
ans=min(ans,ask(,,n,id[x],id[y]));
return ans;
} LL ask (int n,int l,int r,int ll,int rr)
{
if(ll<=l&&r<=rr) return t[n];
int mid=(l+r)>>; LL ans=inf;
if(ll<=mid) ans=min(ans,ask(nl,l,mid,ll,rr));
if(rr>mid) ans=min(ans,ask(nr,mid+,r,ll,rr));
if(c[n])
{
if(l<=ll&&ll<=r) ans=min(ans,dep[ll]*se[ c[n] ].a+se[ c[n] ].b);
if(l<=rr&&rr<=r) ans=min(ans,dep[rr]*se[ c[n] ].a+se[ c[n] ].b);
if(ll<=l&&l<=rr) ans=min(ans,dep[l]*se[ c[n] ].a+se[ c[n] ].b);
if(ll<=r&&r<=rr) ans=min(ans,dep[r]*se[ c[n] ].a+se[ c[n] ].b);
}
return ans;
}
D1T3
生成魔咒:https://lydsy.com/JudgeOnline/problem.php?id=4516
题意概述:每次在一个字符串后插入字符,并求出每次操作后本质不同的子串数量。$n<=10^5$
这题挺妙的。SAM应该很好做,因为它本来就是个在线算法。不过还是考虑用SA.(不是模拟退火)
SA计算本质不同子串数量的时候有这么一个公式:
$\sum_{i=1}^nn-sa_i+1-height_i$
理解一下:先求出每个后缀的前缀数量(也就是子串数量),然后减掉相同的。其实为什么大家都用这个公式我并不是很明白,因为完全可以简化很多,不就是所有子串数量减掉ht的和吗?
好的,那我们化简一下,只考虑ht的和。
再说的直白一点,就是每个后缀与排名在它之前一名的后缀的LCP的和。
动态的插入字符,如果反过来看,也就是每次加入一个新的后缀,它的排名在之前已经处理好了,现在需要的就是动态的维护刚刚所说的那个值了。
随便找一个能维护前驱后继的数据结构,插入一个点时,找到它的前驱后继(这两个本来相当于是挨着的),把这一对对答案的贡献消除,再加入新串和前驱后继对答案的贡献。
# include <cstdio>
# include <iostream>
# include <cstring>
# include <map>
# define R register int
# define nl (n<<)
# define nr (n<<|) using namespace std; const int maxn=;
const int inf=1e7;
int n;
int a[maxn],cnt,ta[maxn],tb[maxn],A[maxn],B[maxn],sa[maxn],rk[maxn],ht[maxn];
int st[maxn][],lg[maxn],tl[maxn<<],tr[maxn<<];
map <int,int> M; void build_SA ()
{
for (R i=;i<=n;++i) ta[ a[i] ]++;
for (R i=;i<=;++i) ta[i]+=ta[i-];
for (R i=n;i>=;--i) sa[ ta[ a[i] ]-- ]=i;
rk[ sa[] ]=;
for (R i=;i<=n;++i)
{
rk[ sa[i] ]=rk[ sa[i-] ];
if(a[ sa[i] ]!=a[ sa[i-] ]) rk[ sa[i] ]++;
}
for (R l=;rk[ sa[n] ]!=n;l<<=)
{
for (R i=;i<=n;++i) ta[i]=tb[i]=;
for (R i=;i<=n;++i) ta[ A[i]=rk[i] ]++,tb[ B[i]=(i+l<=n)?rk[i+l]: ]++;
for (R i=;i<=n;++i) ta[i]+=ta[i-],tb[i]+=tb[i-];
for (R i=n;i>=;--i) rk[ tb[ B[i] ]-- ]=i;
for (R i=n;i>=;--i) sa[ ta[ A[ rk[i] ] ]-- ]=rk[i];
rk[ sa[] ]=;
for (R i=;i<=n;++i)
{
rk[ sa[i] ]=rk[ sa[i-] ];
if(A[ sa[i] ]!=A[ sa[i-] ]||B[ sa[i] ]!=B[ sa[i-] ]) rk[ sa[i] ]++;
}
}
int j=;
for (R i=;i<=n;++i)
{
if(j) j--;
while(a[i+j]==a[ sa[ rk[i]- ]+j ]) j++;
ht[ rk[i] ]=j;
}
} void build_ST()
{
for (R i=;i<=n;++i) lg[i]=lg[i>>]+;
for (R i=;i<=n;++i) st[i][]=ht[i];
for (R k=;k<=;++k)
for (R i=;i+(<<k)-<=n;++i) st[i][k]=min(st[i][k-],st[i+(<<(k-))][k-]);
} int lcp (int i,int j)
{
int k=lg[j-i+];
return min(st[i][k],st[j-(<<k)+][k]);
} void build (int n,int l,int r)
{
tr[n]=inf;
if(l==r) return;
int mid=(l+r)>>;
build(nl,l,mid); build(nr,mid+,r);
} int askl (int n,int l,int r,int ll,int rr)
{
if(ll<=l&&r<=rr) return tl[n];
int mid=(l+r)>>,ans=-inf;
if(ll<=mid) ans=max(ans,askl(nl,l,mid,ll,rr));
if(rr>mid) ans=max(ans,askl(nr,mid+,r,ll,rr));
return ans;
} int askr (int n,int l,int r,int ll,int rr)
{
if(ll<=l&&r<=rr) return tr[n];
int mid=(l+r)>>,ans=inf;
if(ll<=mid) ans=min(ans,askr(nl,l,mid,ll,rr));
if(rr>mid) ans=min(ans,askr(nr,mid+,r,ll,rr));
return ans;
} void ins (int n,int l,int r,int pos)
{
if(l==r) { tl[n]=l,tr[n]=l; return; }
int mid=(l+r)>>;
if(pos<=mid) ins(nl,l,mid,pos);
else ins(nr,mid+,r,pos);
tl[n]=max(tl[nl],tl[nr]);
tr[n]=min(tr[nl],tr[nr]);
} int main()
{
scanf("%d",&n);
for (R i=;i<=n;++i)
{
scanf("%d",&a[i]);
if(M[ a[i] ]) a[i]=M[ a[i] ];
else M[ a[i] ]=++cnt,a[i]=cnt;
}
for (R i=;i<=n/;++i) swap(a[i],a[n-i+]);
build_SA();
build_ST();
long long ans=;
build(,,n);
for (R i=n;i>=;--i)
{
int lef=,rig=;
if(rk[i]!=) lef=askl(,,n,,rk[i]-);
if(rk[i]!=n) rig=askr(,,n,rk[i]+,n);
if(lef==-inf) lef=; if(rig==inf) rig=;
if(lef&&rig) ans-=lcp(lef+,rig);
if(lef) ans+=lcp(lef+,rk[i]);
if(rig) ans+=lcp(rk[i]+,rig);
ins(,,n,rk[i]);
printf("%lld\n",1LL*(n-i+)*(n-i+)/-ans);
}
return ;
}
D2T1
排列计数:https://lydsy.com/JudgeOnline/problem.php?id=4517
直接粘题面.jpg
“ 有多少种长度为 n 的序列 A,满足以下条件:
1 ~ n 这 n 个数在序列中各出现了一次
若第 i 个数 A[i] 的值为 i,则称 i 是稳定的。序列恰好有 m 个数是稳定的
满足条件的序列可能很多,序列数对 10^9+7 取模。”
$T=500000,n≤1000000,m≤1000000$
这题十分诡异,因为它的难度和其它几题真的不搭。
那么这题怎么做?$C_n^m$ 表示选出哪些数是稳定的,$\times d_{n-m}$表示其它元素进行错排。没了?没了。
# include <cstdio>
# include <iostream>
# include <queue>
# include <cstring>
# include <string>
# define R register int
# define ll long long
# define mod using namespace std; const int maxn=;
int T;
int n,m;
long long d[maxn+],f[maxn+],inv[maxn+]; ll qui (ll a)
{
ll b=mod-,s=;
while (b)
{
if(b&1LL) s=s*a%mod;
a=a*a%mod;
b>>=1LL;
}
return s;
} ll C (int n,int m)
{
return f[n]*inv[m]%mod*inv[n-m]%mod;
} inline int read ()
{
int x=;
char c=getchar();
while (!isdigit(c)) c=getchar();
while (isdigit(c)) { x=(x<<)+(x<<)+(c^); c=getchar(); }
return x;
} int main()
{
scanf("%d",&T);
d[]=;
d[]=;
for (R i=;i<=maxn;++i)
d[i]=(i-)*(d[i-]+d[i-])%mod;
f[]=;
for (R i=;i<=maxn;++i)
f[i]=f[i-]*i%mod;
inv[maxn]=qui(f[maxn]);
for (R i=maxn-;i>=;--i)
inv[i]=inv[i+]*(i+)%mod;
while(T--)
{
n=read();
m=read();
printf("%lld\n",C(n,m)*d[n-m]%mod);
}
return ;
}
D2T2
征途:https://lydsy.com/JudgeOnline/problem.php?id=4518
题意概述:将一个长度为 $n$ 的序列分成 $m$ 段,使得每一段的方差和最小。$n,m<=3000$
这题做的比较早,也写过blog,在这里;
但是后来有学了一种方法:带权二分;
显然如果不限制分段数量,最优解就是每个数分成一段,这样的答案是0,如果要求必须分成1段,那么答案就是整个序列的方差。
可以发现随着段数的增加,最优解也在变优,所以就有了一种很有趣的做法:给“分段”这件事带上一个权值,每多分一段,就要在最终答案里加上一个常数;
加的数越大,分的段数就会越少,如果某次最优解的段数恰好为所要求的的值,把这个值减掉段数*常数即为答案。需要注意的是有可能一直分不到段数为k,即:二分的常数为c,段数是k+1,常数为c-1,段数就直接跳到了k-1。这里不用实数二分,因为这道题涉及的所有量都是整数,如果出现上述情况,说明k-1段和k段的最优解是相等的,这时的答案就可以作为k段的答案。
不限制段数的dp很好做,利用斜率优化可以做到 $O(N)$,再加上二分的复杂度,还是比之前的那种 $O(NM)$快到不知道哪里去了,有图为证:

# include <cstdio>
# include <iostream>
# define R register int
# define ll long long using namespace std; const int maxn=;
int n,m,s[maxn],c,f[maxn];
ll ans,dp[maxn]; double X (int x) { return s[x]; }
double Y (int x) { return dp[x]+1LL*s[x]*s[x]; }
double K (int x,int y) { return (Y(x)-Y(y))/(X(x)-X(y)); } struct que
{
int q[maxn],h,t;
void init() { h=,t=; }
void ins (int x)
{
int a=q[t-],b=q[t],c=x;
while(h<t&&K(a,b)>K(b,c))
{
t--;
a=q[t-],b=q[t],c=x;
}
q[++t]=x;
}
void del (int x)
{
double k=*s[x];
int a=q[h],b=q[h+];
while(h<t&&K(a,b)<k)
{
h++;
a=q[h],b=q[h+];
}
}
}q; int check (int c)
{
q.init(); int x;
for (R i=;i<=n;++i)
{
q.del(i);
x=q.q[ q.h ];
dp[i]=Y(x)-*s[i]*s[x]+c+s[i]*s[i];
f[i]=f[x]+;
q.ins(i);
}
return f[n];
} int main()
{
scanf("%d%d",&n,&m);
for (R i=;i<=n;++i) scanf("%d",&s[i]),s[i]+=s[i-];
int l=,r=;
while(l<=r)
{
c=r-(r-l)/; int t=check(c);
if(t==m) break;
if(t<m) r=c-; else l=c+;
}
printf("%lld",(dp[n]-1LL*c*m)*m-s[n]*s[n]);
return ;
}
D2T3
总的来说这套题的排题让人挺迷惑的。明明是最简单的“排列计数”却放到D2T2这样的位置,复杂难调的“游戏”放到D1,但题目的质量还是很不错的。
下次再发类似的做题笔记可能就要很久了,因为14年的“向量集”,15年的“道路修建”,17年的“树点涂色”...哪个都不是好做的题。想再做完整一套还是要花一些时间的。
SDOI 2019 rp++;
---shzr
SDOI2016 R1做题笔记的更多相关文章
- SDOI2017 R1做题笔记
SDOI2017 R1做题笔记 梦想还是要有的,万一哪天就做完了呢? 也就是说现在还没做完. 哈哈哈我竟然做完了-2019.3.29 20:30
- SDOI2014 R1做题笔记
SDOI2014 R1做题笔记 经过很久很久的时间,shzr又做完了SDOI2014一轮的题目. 但是我不想写做题笔记(
- SAM 做题笔记(各种技巧,持续更新,SA)
SAM 感性瞎扯. 这里是 SAM 做题笔记. 本来是在一篇随笔里面,然后 Latex 太多加载不过来就分成了两篇. 标 * 的是推荐一做的题目. trick 是我总结的技巧. I. P3804 [模 ...
- C语言程序设计做题笔记之C语言基础知识(下)
C 语言是一种功能强大.简洁的计算机语言,通过它可以编写程序,指挥计算机完成指定的任务.我们可以利用C语言创建程序(即一组指令),并让计算机依指令行 事.并且C是相当灵活的,用于执行计算机程序能完成的 ...
- C语言程序设计做题笔记之C语言基础知识(上)
C语言是一种功能强大.简洁的计算机语言,通过它可以编写程序,指挥计算机完成指定的任务.我们可以利用C语言创建程序(即一组指令),并让计算机依指令行事.并且C是相当灵活的,用于执行计算机程序能完成的几乎 ...
- LCT做题笔记
最近几天打算认真复习LCT,毕竟以前只会板子.正好也可以学点新的用法,这里就用来写做题笔记吧.这个分类比较混乱,主要看感觉,不一定对: 维护森林的LCT 就是最普通,最一般那种的LCT啦.这类题目往往 ...
- java做题笔记
java做题笔记 1. 初始化过程是这样的: 1.首先,初始化父类中的静态成员变量和静态代码块,按照在程序中出现的顺序初始化: 2.然后,初始化子类中的静态成员变量和静态代码块,按照在程序中出现的顺序 ...
- PKUWC/SC 做题笔记
去年不知道干了些啥,什么省选/营题都没做. 现在赶应该还来得及(?) 「PKUWC2018」Minimax Done 2019.12.04 9:38:55 线段树合并船新玩法??? \(O(n^2)\ ...
- POI做题笔记
POI2011 Conspiracy (2-SAT) Description \(n\leq 5000\) Solution 发现可拆点然后使用2-SAT做,由于特殊的关系,可以证明每次只能交换两个集 ...
随机推荐
- SpringMVC 的运行原理
0. 灵魂的拷问 问:SpringMVC 是什么?它有什么作用? 答:SpringMVC 的全称是 Spring Web Model-View-Controller,它是 Spring Fram ...
- JSJ—编译器与虚拟机哪个重要?
阅读本文约“2分钟” 熟悉Java的朋友都知道虚拟机还有编译器,那么它们各自主要的功能是什么?谁比较重要呢?让我们来了解一下这两位美女的故事. 虚拟机可以说就是Java,她能让程序运行起来. 但是编译 ...
- Eclipse中SVN插件的安装和配置(在线安装)
公司项目中用到了svn来管理项目,然后需要在Eclipse中进行配置.网上参考了很多资料,离线安装的方式装上了,但是导入项目后报错,可能是离线安装包的问题.然后又采用了Eclipse在线安装的方式,总 ...
- junit单元测试注意的问题
1.有返回值的方法不能直接测试 2.带参数的方法不能直接测试 3.访问权限在public一下的方法不能直接测试 4.static静态方法不能直接测试 5.不能给出现前四个条件中任意一个的方法添加@Te ...
- Android LiveData使用
LiveData是一个可观察的数据持有者类. 与常规observable不同,LiveData是生命周期感知的,当生命周期处于STARTED或RESUMED状态,则LiveData会将其视为活动状态, ...
- HTML5 常用标签整理
<!--1. html5 文本 --> <div> <header> <hgroup> <h1>h1</h1> <h2& ...
- 我写的Angular相关的文章
此文正在更新中... Angular6的变化 Angular7的变化 No value accessor for form control with path的解决方案
- leaflet计算多边形面积
上一篇介绍了使用leaflet绘制圆形,那如何计算圆形的面积呢? 1.使用数学公式计算,绘制好圆形后,获取中心点以及半径即可 2.使用第三方工具计算,如turf.js. 这里turf的area方法入参 ...
- Linux扩展分区记录
Vmware中新建的Linux虚拟机,数据盘规划太小,数据量超出磁盘大小,本文介绍如何快速扩充空间 参考:https://blog.csdn.net/lyd135364/article/details ...
- Linux Linux下最大文件描述符设置
Linux下最大文件描述符设置 by:授客 QQ:1033553122 1. 系统可打开最大文件描述符设置 查看系统可打开最大文件描述符 # cat /proc/sys/fs/file-max 6 ...