Python之模块和包
一、模块
1.什么是模块?
常见的场景:一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀。
但其实import加载的模块分为四个通用类别:
1 使用python编写的代码(.py文件)
2 已被编译为共享库或DLL的C或C++扩展
3 包好一组模块的包
4 使用C编写并链接到python解释器的内置模块
2.何要使用模块?
如果你退出python解释器然后重新进入,那么你之前定义的函数或者变量都将丢失,因此我们通常将程序写到文件中以便永久保存下来,需要时就通过python test.py方式去执行,此时test.py被称为脚本script。
随着程序的发展,功能越来越多,为了方便管理,我们通常将程序分成一个个的文件,这样做程序的结构更清晰,方便管理。这时我们不仅仅可以把这些文件当做脚本去执行,还可以把他们当做模块来导入到其他的模块中。
使用模块可以提高代码的可维护性和重复使用,还可以避免函数名和变量名冲突。相同名字的函数和变量完全可以分别存在不同的模块中,所以编写自己的模块时,不必考虑名字会与其他模块冲突,但要注意尽量不要与内置函数名字冲突。
3.模块的导入方式
一、直接导入 import module
这里有个大前提,就是你的py执行文件和模块同属于同个目录(父级目录),如下图:
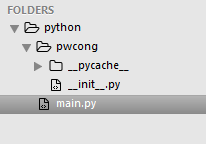
- main.py 和 pwcong模块同在python目录
- 执行文件为main.py
- pwcong文件夹为一个模块
我把pwcong模块提供的函数写在 __init__.py 里,里面只提供一个 hi 函数:
- # pwcong 模块的 __init__.py
- # -*- coding: utf-8 -*-
- def hi():
- print("hi")
执行文件main.py直接import模块:
- # main.py
- # -*- coding: utf-8 -*-
- import pwcong
- pwcong.hi()
接着我们运行一下main.py可以看到命令行窗口输出了一句 hi ,第一种方式完成。
- 使用模块方式为:先导入-》接着输入模块.变量|函数, 如上面例子的 pwcong.hi()
如果要同时导入多个模块,只需要在模块名之前用逗号进行分隔:
import module1,module2,module3.......
在用import语句导入模块时最好按照以下的顺序:
1、python 标准库模块
2、python 第三方模块
3、自定义模块
二、import... as...
import 引入模块格式如下:
- import 模块路径.文件名 as 别名
释:当文件在当前目录下或PATH环境变量下,可以直接import 文件名;否则要从项目根目录下开始指定路径。别名,直接引入文件名可以不用别名,如果带模块路径引入最好加上别名,使用时直接 【别名. 】使用。
三、from ... import ...
from ... import ... 这种引入方式使用一个点号来标识引入类库的精确位置。
格式:
- import 模块路径.文件名 import 变量名\函数\类名
- from module import xx
- from module import xx as rename
- from module import *
把my_module中所有的不是以下划线(_)开头的名字都导入到当前位置,大部分情况下我们的python程序不应该使用这种导入方式,
因为*你不知道你导入什么名字,很有可能会覆盖掉你之前已经定义的名字。而且可读性极其的差,在交互式环境中导入时没有问题。
*如果module.py中的名字前加_,即_money,则from module import *,则_money不能被导入- 也支持导入多行
- from my_module import (read1,
- read2,
- money)
注意:win系统不要使用相对路径。
4.模块的加载与修改
考虑到性能的原因,每个模块只被导入一次,放入字典sys.modules中,如果你改变了模块的内容,你必须重启程序,python不支持重新加载或卸载之前导入的模块,
有的同学可能会想到直接从sys.modules中删除一个模块不就可以卸载了吗,注意了,你删了sys.modules中的模块对象仍然可能被其他程序的组件所引用,因而不会被清除。
特别的对于我们引用了这个模块中的一个类,用这个类产生了很多对象,因而这些对象都有关于这个模块的引用。
如果只是你想交互测试的一个模块,使用 importlib.reload(), e.g. import importlib; importlib.reload(modulename),这只能用于测试环境。
- def func1():
- print('func1')
aa.py
- import time,importlib
- import aa
- time.sleep(20)
- # importlib.reload(aa)
- aa.func1()
测试代码
在20秒的等待时间里,修改aa.py中func1的内容,等待test.py的结果。
打开importlib注释,重新测试
5.把模块当做脚本执行
我们可以通过模块的全局变量__name__来查看模块名:
当做脚本运行:
__name__ 等于'__main__'
当做模块导入:
__name__= 模块名
作用:用来控制.py文件在不同的应用场景下执行不同的逻辑
if __name__ == '__main__':
- def fib(n):
- a, b = 0, 1
- while b < n:
- print(b, end=' ')
- a, b = b, a+b
- print()
- if __name__ == "__main__":
- print(__name__)
- num = input('num :')
- fib(int(num))
6.模块搜索路径
python解释器在启动时会自动加载一些模块,可以使用sys.modules查看
在第一次导入某个模块时(比如my_module),会先检查该模块是否已经被加载到内存中(当前执行文件的名称空间对应的内存),如果有则直接引用
如果没有,解释器则会查找同名的内建模块,如果还没有找到就从sys.path给出的目录列表中依次寻找my_module.py文件。
所以总结模块的查找顺序是:内存中已经加载的模块->内置模块->sys.path路径中包含的模块
sys.path的初始化的值来自于:
The directory containing the input script (or the current directory when no file is specified).
PYTHONPATH (a list of directory names, with the same syntax as the shell variable PATH).
The installation-dependent default.
需要特别注意的是:我们自定义的模块名不应该与系统内置模块重名。虽然每次都说,但是仍然会有人不停的犯错。
在初始化后,python程序可以修改sys.path,路径放到前面的优先于标准库被加载。
- 1 >>> import sys
- 2 >>> sys.path.append('/a/b/c/d')
- 3 >>> sys.path.insert(0,'/x/y/z') #排在前的目录,优先被搜索
注意:搜索时按照sys.path中从左到右的顺序查找,位于前的优先被查找,sys.path中还可能包含.zip归档文件和.egg文件,python会把.zip归档文件当成一个目录去处理。
- #首先制作归档文件:zip module.zip foo.py bar.py
- import sys
- sys.path.append('module.zip')
- import foo,bar
- #也可以使用zip中目录结构的具体位置
- sys.path.append('module.zip/lib/python')
- #windows下的路径不加r开头,会语法错误
- sys.path.insert(0,r'C:\Users\Administrator\PycharmProjects\a')
至于.egg文件是由setuptools创建的包,这是按照第三方python库和扩展时使用的一种常见格式,.egg文件实际上只是添加了额外元数据(如版本号,依赖项等)的.zip文件。
需要强调的一点是:只能从.zip文件中导入.py,.pyc等文件。使用C编写的共享库和扩展块无法直接从.zip文件中加载(此时setuptools等打包系统有时能提供一种规避方法),且从.zip中加载文件不会创建.pyc或者.pyo文件,因此一定要事先创建他们,来避免加载模块是性能下降。
官网解释
- #官网链接:https://docs.python.org/3/tutorial/modules.html#the-module-search-path
- 搜索路径:
- 当一个命名为my_module的模块被导入时
- 解释器首先会从内建模块中寻找该名字
- 找不到,则去sys.path中找该名字
- sys.path从以下位置初始化
- 执行文件所在的当前目录
- PTYHONPATH(包含一系列目录名,与shell变量PATH语法一样)
- 依赖安装时默认指定的
- 注意:在支持软连接的文件系统中,执行脚本所在的目录是在软连接之后被计算的,换句话说,包含软连接的目录不会被添加到模块的搜索路径中
- 在初始化后,我们也可以在python程序中修改sys.path,执行文件所在的路径默认是sys.path的第一个目录,在所有标准库路径的前面。这意味着,当前目录是优先于标准库目录的,需要强调的是:我们自定义的模块名不要跟python标准库的模块名重复,除非你是故意的,傻叉。
7.编译python文件
为了提高加载模块的速度,强调强调强调:提高的是加载速度而绝非运行速度。python解释器会在__pycache__目录中下缓存每个模块编译后的版本,格式为:module.version.pyc。通常会包含python的版本号。例如,在CPython3.3版本下,my_module.py模块会被缓存成__pycache__/my_module.cpython-33.pyc。这种命名规范保证了编译后的结果多版本共存。
Python检查源文件的修改时间与编译的版本进行对比,如果过期就需要重新编译。这是完全自动的过程。并且编译的模块是平台独立的,所以相同的库可以在不同的架构的系统之间共享,即pyc使一种跨平台的字节码,类似于JAVA火.NET,是由python虚拟机来执行的,但是pyc的内容跟python的版本相关,不同的版本编译后的pyc文件不同,2.5编译的pyc文件不能到3.5上执行,并且pyc文件是可以反编译的,因而它的出现仅仅是用来提升模块的加载速度的。
python解释器在以下两种情况下不检测缓存
1 如果是在命令行中被直接导入模块,则按照这种方式,每次导入都会重新编译,并且不会存储编译后的结果(python3.3以前的版本应该是这样)
- python -m my_module.py
2 如果源文件不存在,那么缓存的结果也不会被使用,如果想在没有源文件的情况下来使用编译后的结果,则编译后的结果必须在源目录下
提示:
1.模块名区分大小写,foo.py与FOO.py代表的是两个模块
2.你可以使用-O或者-OO转换python命令来减少编译模块的大小
- 模块可以作为一个脚本(使用python -m compileall)编译Python源
- python -m compileall /module_directory 递归着编译
- 如果使用python -O -m compileall /module_directory -l则只一层
- 命令行里使用compile()函数时,自动使用python -O -m compileall
- 详见:https://docs.python.org/3/library/compileall.html#module-compileall
了解
二、包
包是一种通过使用‘.模块名’来组织python模块名称空间的方式。
1. 无论是import形式还是from...import形式,凡是在导入语句中(而不是在使用时)遇到带点的,都要第一时间提高警觉:这是关于包才有的导入语法
2. 包是目录级的(文件夹级),文件夹是用来组成py文件(包的本质就是一个包含__init__.py文件的目录)
3. import导入文件时,产生名称空间中的名字来源于文件,import 包,产生的名称空间的名字同样来源于文件,即包下的__init__.py,导入包本质就是在导入该文件
强调:
1. 在python3中,即使包下没有__init__.py文件,import 包仍然不会报错,而在python2中,包下一定要有该文件,否则import 包报错
2. 创建包的目的不是为了运行,而是被导入使用,记住,包只是模块的一种形式而已,包即模块
包A和包B下有同名模块也不会冲突,如A.a与B.a来自俩个命名空间
- import os
- os.makedirs('glance/api')
- os.makedirs('glance/cmd')
- os.makedirs('glance/db')
- l = []
- l.append(open('glance/__init__.py','w'))
- l.append(open('glance/api/__init__.py','w'))
- l.append(open('glance/api/policy.py','w'))
- l.append(open('glance/api/versions.py','w'))
- l.append(open('glance/cmd/__init__.py','w'))
- l.append(open('glance/cmd/manage.py','w'))
- l.append(open('glance/db/models.py','w'))
- map(lambda f:f.close() ,l)
创建目录代码
- glance/ #Top-level package
- ├── __init__.py #Initialize the glance package
- ├── api #Subpackage for api
- │ ├── __init__.py
- │ ├── policy.py
- │ └── versions.py
- ├── cmd #Subpackage for cmd
- │ ├── __init__.py
- │ └── manage.py
- └── db #Subpackage for db
- ├── __init__.py
- └── models.py
目录结构
- #文件内容
- #policy.py
- def get():
- print('from policy.py')
- #versions.py
- def create_resource(conf):
- print('from version.py: ',conf)
- #manage.py
- def main():
- print('from manage.py')
- #models.py
- def register_models(engine):
- print('from models.py: ',engine)
文件内容
2.1 注意事项
1.关于包相关的导入语句也分为import和from ... import ...两种,但是无论哪种,无论在什么位置,在导入时都必须遵循一个原则:凡是在导入时带点的,点的左边都必须是一个包,否则非法。可以带有一连串的点,如item.subitem.subsubitem,但都必须遵循这个原则。
2.对于导入后,在使用时就没有这种限制了,点的左边可以是包,模块,函数,类(它们都可以用点的方式调用自己的属性)。
3.对比import item 和from item import name的应用场景:
如果我们想直接使用name那必须使用后者。
2.2 import
我们在与包glance同级别的文件中测试
- import glance.db.models
- glance.db.models.register_models('mysql')
2.3 from ... import ...
需要注意的是from后import导入的模块,必须是明确的一个不能带点,否则会有语法错误,如:from a import b.c是错误语法
我们在与包glance同级别的文件中测试
- from glance.db import models
- models.register_models('mysql')
- from glance.db.models import register_models
- register_models('mysql')
2.4 __init__.py文件
不管是哪种方式,只要是第一次导入包或者是包的任何其他部分,都会依次执行包下的__init__.py文件(我们可以在每个包的文件内都打印一行内容来验证一下),这个文件可以为空,但是也可以存放一些初始化包的代码。
2.5 from glance.api import *
在讲模块时,我们已经讨论过了从一个模块内导入所有*,此处我们研究从一个包导入所有*。
此处是想从包api中导入所有,实际上该语句只会导入包api下__init__.py文件中定义的名字,我们可以在这个文件中定义__all___:
- #在__init__.py中定义
- x=10
- def func():
- print('from api.__init.py')
- __all__=['x','func','policy']
此时我们在于glance同级的文件中执行from glance.api import *就导入__all__中的内容(versions仍然不能导入)。
- glance/
- ├── __init__.py
- ├── api
- │ ├── __init__.py __all__ = ['policy','versions']
- │ ├── policy.py
- │ └── versions.py
- ├── cmd __all__ = ['manage']
- │ ├── __init__.py
- │ └── manage.py
- └── db __all__ = ['models']
- ├── __init__.py
- └── models.py
- from glance.api import *
- policy.get()
from glance.api import *
2.6 绝对导入和相对导入
我们的最顶级包glance是写给别人用的,然后在glance包内部也会有彼此之间互相导入的需求,这时候就有绝对导入和相对导入两种方式:
绝对导入:以glance作为起始
相对导入:用.或者..的方式最为起始(只能在一个包中使用,不能用于不同目录内)
例如:我们在glance/api/version.py中想要导入glance/cmd/manage.py
- 在glance/api/version.py
- #绝对导入
- from glance.cmd import manage
- manage.main()
- #相对导入
- from ..cmd import manage
- manage.main()
测试结果:注意一定要在于glance同级的文件中测试
- from glance.api import versions
注意:在使用pycharm时,有的情况会为你多做一些事情,这是软件相关的东西,会影响你对模块导入的理解,因而在测试时,一定要回到命令行去执行,模拟我们生产环境,你总不能拿着pycharm去上线代码吧!!!
特别需要注意的是:可以用import导入内置或者第三方模块(已经在sys.path中),但是要绝对避免使用import来导入自定义包的子模块(没有在sys.path中),应该使用from... import ...的绝对或者相对导入,且包的相对导入只能用from的形式。
比如我们想在glance/api/versions.py中导入glance/api/policy.py,有的同学一抽这俩模块是在同一个目录下,十分开心的就去做了,它直接这么做
- #在version.py中
- import policy
- policy.get()
没错,我们单独运行version.py是一点问题没有的,运行version.py的路径搜索就是从当前路径开始的,于是在导入policy时能在当前目录下找到
但是你想啊,你子包中的模块version.py极有可能是被一个glance包同一级别的其他文件导入,比如我们在于glance同级下的一个test.py文件中导入version.py,如下
- from glance.api import versions
- '''
- 执行结果:
- ImportError: No module named 'policy'
- '''
- '''
- 分析:
- 此时我们导入versions在versions.py中执行
- import policy需要找从sys.path也就是从当前目录找policy.py,
- 这必然是找不到的
- '''
- glance/
- ├── __init__.py from glance import api
- from glance import cmd
- from glance import db
- ├── api
- │ ├── __init__.py from glance.api import policy
- from glance.api import versions
- │ ├── policy.py
- │ └── versions.py
- ├── cmd from glance.cmd import manage
- │ ├── __init__.py
- │ └── manage.py
- └── db from glance.db import models
- ├── __init__.py
- └── models.py
绝对导入
- glance/
- ├── __init__.py from . import api #.表示当前目录
- from . import cmd
- from . import db
- ├── api
- │ ├── __init__.py from . import policy
- from . import versions
- │ ├── policy.py
- │ └── versions.py
- ├── cmd from . import manage
- │ ├── __init__.py
- │ └── manage.py from ..api import policy
- #..表示上一级目录,想再manage中使用policy中的方法就需要回到上一级glance目录往下找api包,从api导入policy
- └── db from . import models
- ├── __init__.py
- └── models.py
相对导入
2.7 单独导入包
单独导入包名称时不会导入包中所有包含的所有子模块,如
- #在与glance同级的test.py中
- import glance
- glance.cmd.manage.main()
- '''
- 执行结果:
- AttributeError: module 'glance' has no attribute 'cmd'
- '''
解决方法:
- 1 #glance/__init__.py
- 2 from . import cmd
- 3
- 4 #glance/cmd/__init__.py
- 5 from . import manage
执行:
- 1 #在于glance同级的test.py中
- 2 import glance
- 3 glance.cmd.manage.main()
千万别问:__all__不能解决吗,__all__是用于控制from...import *
import glance之后直接调用模块中的方法
- glance/
- ├── __init__.py from .api import *
- from .cmd import *
- from .db import *
- ├── api
- │ ├── __init__.py __all__ = ['policy','versions']
- │ ├── policy.py
- │ └── versions.py
- ├── cmd __all__ = ['manage']
- │ ├── __init__.py
- │ └── manage.py
- └── db __all__ = ['models']
- ├── __init__.py
- └── models.py
- import glance
- policy.get()
import glance
软件开发规范
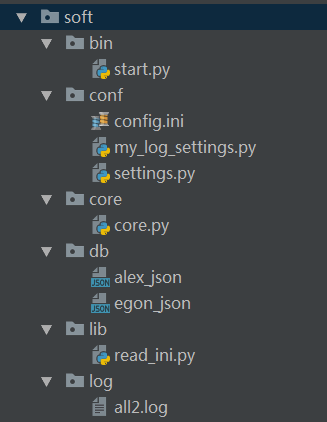
- #=============>bin目录:存放执行脚本
- #start.py
- import sys,os
- BASE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
- sys.path.append(BASE_DIR)
- from core import core
- from conf import my_log_settings
- if __name__ == '__main__':
- my_log_settings.load_my_logging_cfg()
- core.run()
- #=============>conf目录:存放配置文件
- #config.ini
- [DEFAULT]
- user_timeout = 1000
- [egon]
- password = 123
- money = 10000000
- [alex]
- password = alex3714
- money=10000000000
- [yuanhao]
- password = ysb123
- money=10
- #settings.py
- import os
- config_path=r'%s\%s' %(os.path.dirname(os.path.abspath(__file__)),'config.ini')
- user_timeout=10
- user_db_path=r'%s\%s' %(os.path.dirname(os.path.dirname(os.path.abspath(__file__))),\
- 'db')
- #my_log_settings.py
- """
- logging配置
- """
- import os
- import logging.config
- # 定义三种日志输出格式 开始
- standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \
- '[%(levelname)s][%(message)s]' #其中name为getlogger指定的名字
- simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
- id_simple_format = '[%(levelname)s][%(asctime)s] %(message)s'
- # 定义日志输出格式 结束
- logfile_dir = r'%s\log' %os.path.dirname(os.path.dirname(os.path.abspath(__file__))) # log文件的目录
- logfile_name = 'all2.log' # log文件名
- # 如果不存在定义的日志目录就创建一个
- if not os.path.isdir(logfile_dir):
- os.mkdir(logfile_dir)
- # log文件的全路径
- logfile_path = os.path.join(logfile_dir, logfile_name)
- # log配置字典
- LOGGING_DIC = {
- 'version': 1,
- 'disable_existing_loggers': False,
- 'formatters': {
- 'standard': {
- 'format': standard_format
- },
- 'simple': {
- 'format': simple_format
- },
- },
- 'filters': {},
- 'handlers': {
- #打印到终端的日志
- 'console': {
- 'level': 'DEBUG',
- 'class': 'logging.StreamHandler', # 打印到屏幕
- 'formatter': 'simple'
- },
- #打印到文件的日志,收集info及以上的日志
- 'default': {
- 'level': 'DEBUG',
- 'class': 'logging.handlers.RotatingFileHandler', # 保存到文件
- 'formatter': 'standard',
- 'filename': logfile_path, # 日志文件
- 'maxBytes': 1024*1024*5, # 日志大小 5M
- 'backupCount': 5,
- 'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
- },
- },
- 'loggers': {
- #logging.getLogger(__name__)拿到的logger配置
- '': {
- 'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
- 'level': 'DEBUG',
- 'propagate': True, # 向上(更高level的logger)传递
- },
- },
- }
- def load_my_logging_cfg():
- logging.config.dictConfig(LOGGING_DIC) # 导入上面定义的logging配置
- logger = logging.getLogger(__name__) # 生成一个log实例
- logger.info('It works!') # 记录该文件的运行状态
- if __name__ == '__main__':
- load_my_logging_cfg()
- #=============>core目录:存放核心逻辑
- #core.py
- import logging
- import time
- from conf import settings
- from lib import read_ini
- config=read_ini.read(settings.config_path)
- logger=logging.getLogger(__name__)
- current_user={'user':None,'login_time':None,'timeout':int(settings.user_timeout)}
- def auth(func):
- def wrapper(*args,**kwargs):
- if current_user['user']:
- interval=time.time()-current_user['login_time']
- if interval < current_user['timeout']:
- return func(*args,**kwargs)
- name = input('name>>: ')
- password = input('password>>: ')
- if config.has_section(name):
- if password == config.get(name,'password'):
- logger.info('登录成功')
- current_user['user']=name
- current_user['login_time']=time.time()
- return func(*args,**kwargs)
- else:
- logger.error('用户名不存在')
- return wrapper
- @auth
- def buy():
- print('buy...')
- @auth
- def run():
- print('''
- 购物
- 查看余额
- 转账
- ''')
- while True:
- choice = input('>>: ').strip()
- if not choice:continue
- if choice == '':
- buy()
- if __name__ == '__main__':
- run()
- #=============>db目录:存放数据库文件
- #alex_json
- #egon_json
- #=============>lib目录:存放自定义的模块与包
- #read_ini.py
- import configparser
- def read(config_file):
- config=configparser.ConfigParser()
- config.read(config_file)
- return config
- #=============>log目录:存放日志
- #all2.log
- [2017-07-29 00:31:40,272][MainThread:11692][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!]
- [2017-07-29 00:31:41,789][MainThread:11692][task_id:core.core][core.py:25][ERROR][用户名不存在]
- [2017-07-29 00:31:46,394][MainThread:12348][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!]
- [2017-07-29 00:31:47,629][MainThread:12348][task_id:core.core][core.py:25][ERROR][用户名不存在]
- [2017-07-29 00:31:57,912][MainThread:10528][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!]
- [2017-07-29 00:32:03,340][MainThread:12744][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!]
- [2017-07-29 00:32:05,065][MainThread:12916][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!]
- [2017-07-29 00:32:08,181][MainThread:12916][task_id:core.core][core.py:25][ERROR][用户名不存在]
- [2017-07-29 00:32:13,638][MainThread:7220][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!]
- [2017-07-29 00:32:23,005][MainThread:7220][task_id:core.core][core.py:20][INFO][登录成功]
- [2017-07-29 00:32:40,941][MainThread:7220][task_id:core.core][core.py:20][INFO][登录成功]
- [2017-07-29 00:32:47,222][MainThread:7220][task_id:core.core][core.py:20][INFO][登录成功]
- [2017-07-29 00:32:51,949][MainThread:7220][task_id:core.core][core.py:25][ERROR][用户名不存在]
- [2017-07-29 00:33:00,213][MainThread:7220][task_id:core.core][core.py:20][INFO][登录成功]
- [2017-07-29 00:33:50,118][MainThread:8500][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!]
- [2017-07-29 00:33:55,845][MainThread:8500][task_id:core.core][core.py:20][INFO][登录成功]
- [2017-07-29 00:34:06,837][MainThread:8500][task_id:core.core][core.py:25][ERROR][用户名不存在]
- [2017-07-29 00:34:09,405][MainThread:8500][task_id:core.core][core.py:25][ERROR][用户名不存在]
- [2017-07-29 00:34:10,645][MainThread:8500][task_id:core.core][core.py:25][ERROR][用户名不存在]
Python之模块和包的更多相关文章
- Python之模块和包导入
Python之模块和包导入 模块导入: 1.创建名称空间,用来存放模块XX.py中定义的名字 2.基于创建的名称空间来执行XX.py. 3.创建名字XX.py指向该名称空间,XX.名字的操作,都是以X ...
- 一文搞懂 Python 的模块和包,在实战中的最佳实践
最近公司有个项目,我需要写个小爬虫,将爬取到的数据进行统计分析.首先确定用 Python 写,其次不想用 Scrapy,因为要爬取的数据量和频率都不高,没必要上爬虫框架.于是,就自己搭了一个项目,通过 ...
- python 深入模块和包
模块可以包含可执行语句以及函数的定义. 这些语句通常用于初始化模块. 它们只在 第一次 导入时执行.只在第一次导入的时候执行,第一次.妈蛋的第一次...后面再次导入就不执行了. [1](如果文件以脚本 ...
- (Python )模块、包
本节开始学习模块的相关知识,主要包括模块的编译,模块的搜索路径.包等知识 1.模块 如果我们直接在解释器中编写python,当我们关掉解释器后,再进去.我们之前编写的代码都丢失了.因此,我们需要将我们 ...
- Python 基金会 —— 模块和包简介
一.模块(Module) 1.模块的作用 在交互模式下输出的变量和函数定义,一旦终端重新启动后,这些定义就都不存在了,为了持久保存这些变量.函数等的定义,Python中引入了模块(Modul ...
- python基础-------模块与包(一)
模块与包 Python中的py文件我们拿来调用的为之模块:主要有内置模块(Python解释器自带),第三方模块(别的开发者开发的),自定义模块. 目前我们学习的是内置模块与第三方模块. 通过impor ...
- python中模块,包,库的概念
模块:就是.py文件,里面定义了一些函数和变量,需要的时候就可以导入这些模块. 包:在模块之上的概念,为了方便管理而将文件进行打包.包目录下第一个文件便是 __init__.py,然后是一些模块文件和 ...
- python的模块与包的导入
类似于C语言的包含头文件去引用其他文件的函数,python也有类似的机制,常用的引入方法有以下 import 模块名 #模块名就是py文件名 #使用这种方法以后调用函数的时候要使用模块名.函数名()这 ...
- day21 python之模块和包
一 模块 1 什么是模块? 常见的场景:一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀. 但其实import加载的模块分为四个通用类别: 1 使用python编 ...
- python之模块与包
一模块 二包 一模块 常见的场景:一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀. 但其实import加载的模块分为四个通用类别: 1 使用python编写的代 ...
随机推荐
- java学习之—排序
package test3; public class Sort{ /** * 冒泡排序 * @param array */ public void bubbleSort(int[] array) { ...
- 移动端Web界面滚动touch事件
解决办法一: elem.addEventListener( 'touchstart', fn, { passive: false } ); 解决办法二: * { touch-action: pan-y ...
- 我和我的小伙伴们都惊呆了!基于Canvas的第三方库Three.js
What is Three.js three + js 表示运行在浏览器上的3D程序 javascript的计算能力因为google的V8引擎得到了迅猛提升 做服务器都没问题了 更别说3D了 哈哈 ...
- 【转】解决Maxwell发送Kafka消息数据倾斜问题
最近用Maxwell解析MySQL的Binlog,发送到Kafka进行处理,测试的时候发现一个问题,就是Kafka的Offset严重倾斜,三个partition,其中一个的offset已经快200万了 ...
- C#中as运算符
as运算符用于执行引用类型的显式类型转换.如果要转换的类型与指定的类型兼容,转换就会成功进行:如果类型不兼容,as运算符就会返回null值.如下面的代码所示,如果object引用实际上不引用strin ...
- JavaSE从入门到精通
1.JavaSE的安装 windows下安装完成后,配置环境变量如下: JAVA_HOME C:\Program Files (x86)\Java\jdk1.8.0_91 CLASSP ...
- react 入坑笔记(五) - 条件渲染和列表渲染
条件渲染和列表渲染 一.条件渲染 条件渲染较简单,使用 JavaScript 操作符 if 或条件运算符来创建表示当前状态的元素,然后让 React 根据它们来更新 UI. 贴一个小栗子: funct ...
- 【Python练习题】程序5
#题目:输入三个整数x,y,z,请把这三个数由小到大输出. # a = input('请输入整数: \n') # # b = input('请输入整数: \n') # # c = input('请输入 ...
- 洛谷 P2119 魔法阵
题目描述 六十年一次的魔法战争就要开始了,大魔法师准备从附近的魔法场中汲取魔法能量. 大魔法师有mm个魔法物品,编号分别为1,2,...,m1,2,...,m.每个物品具有一个魔法值,我们用X_iXi ...
- Spring 使用介绍(三)—— 资源
一.Resource接口 Spring提供Resource接口,代表底层外部资源,提供对底层外部资源的一致性访问接口 public interface InputStreamSource { Inpu ...