课程回顾-Convolutional Neural Networks
padding
Strided convolution
多维卷积
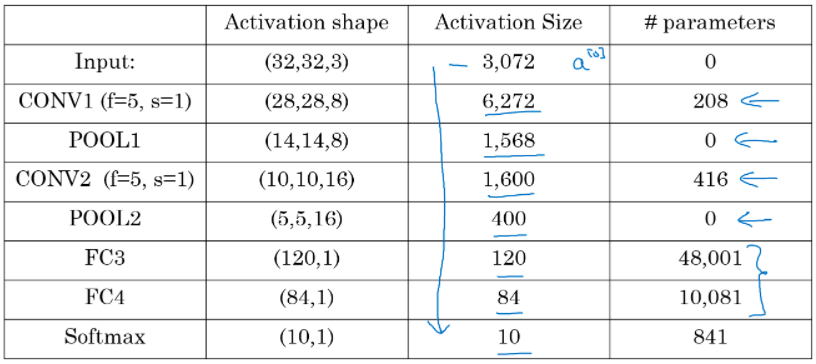
LeNet 参数
卷积网络的好处
参数共享
稀疏连接
经典网络实现
LeNet-5
AlexNet
VGG
ResNet
残差块
identity block
convolutional block
残差网络
为什么残差网络有用
Network in Network & 1*1 convolutions
Inception network motivation
GoogleNet
Data Augmentation
Object Detection
几种技术的的区别
标签设计
landmark detection
sliding windows
基于卷积的滑动窗口
Bounding box Prediction
Intersection Over Union
Non-max Suppression
Anchor Box
YOLO 算法
Region Proposal(R-CNN)
Face Recognition
verification和recognition
One Shot Learning
Siamese Network
Triplet Loss
Face Verification and Binary Classification
风格迁移
content loss
style loss
Keras
Reference
为什么卷积层计算量更低
全连接的话权重太多
padding
padding的存在是因为我们做卷积操作的时候会引发数据急剧减少,padding可以解决
Strided convolution
步长的设置问题
p = (n*s - n + f - s) / 2
When s = 1 ==> P = (f-1) / 2
多维卷积
卷积层也有长、宽和通道数,其中卷基层的通道数需要和图像一致
LeNet 参数
卷积网络的好处
参数共享
一个探测器在某个部分有用那么在另一个部分也很可能有用
稀疏连接
每一层中,每个输出值只和部分的输入有关
经典网络实现
LeNet-5
为了识别32321
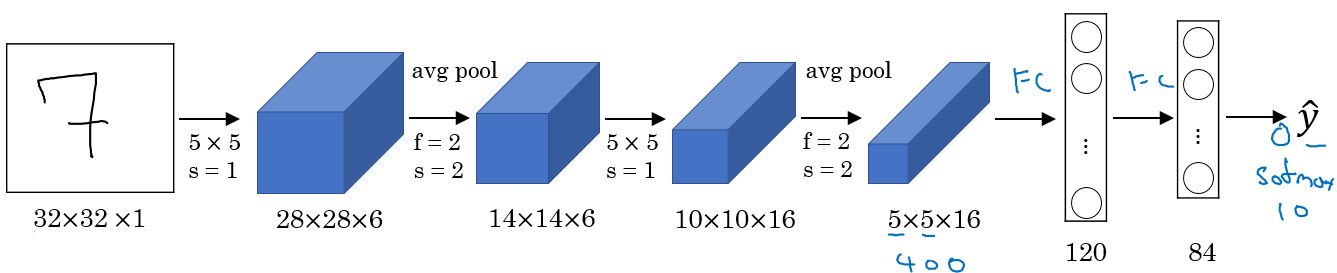
Conv ==> Pool ==> Conv ==> Pool ==> FC ==> FC ==> softmax
AlexNet
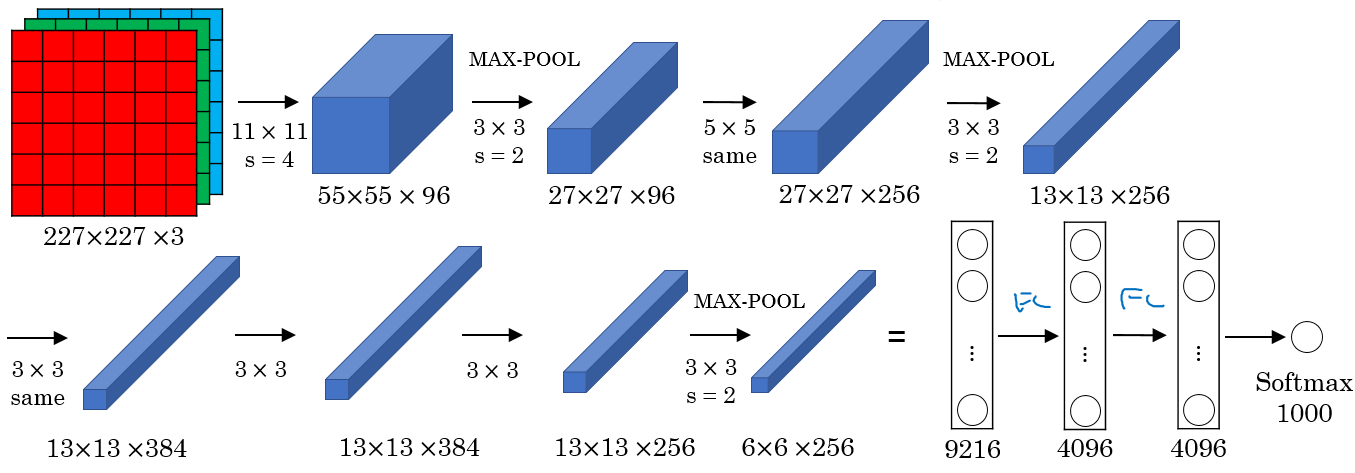
Conv => Max-pool => Conv => Max-pool => Conv => Conv => Conv => Max-pool ==> Flatten ==> FC ==> FC ==> Softmax
VGG

ResNet
残差块
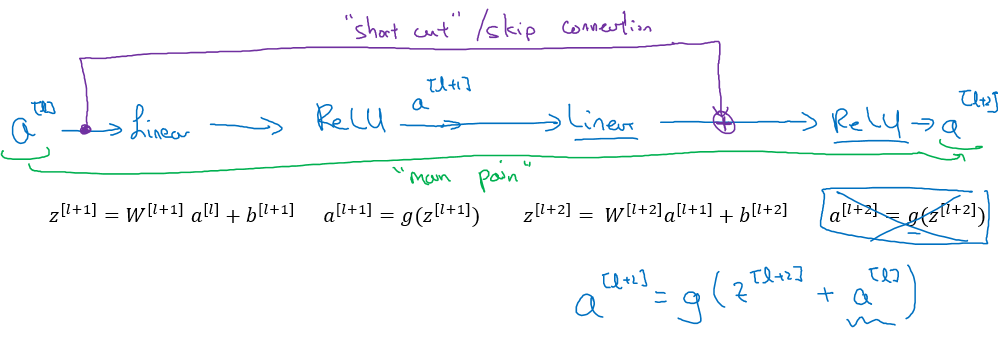
如上图,实际上就是在网络中加入了一些shortcut
identity block
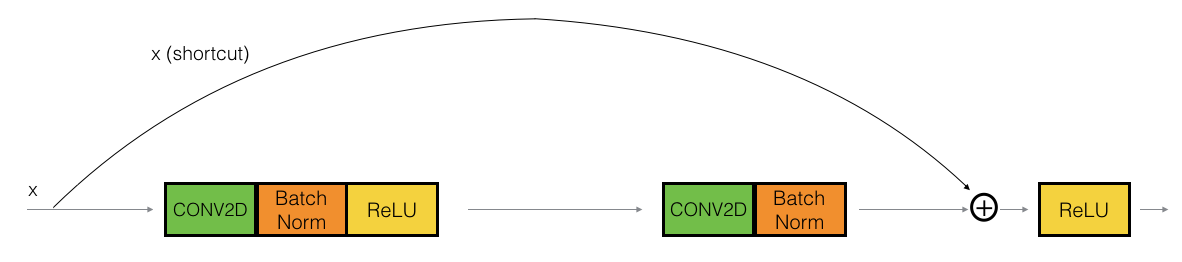
这个是保持不变的
convolutional block
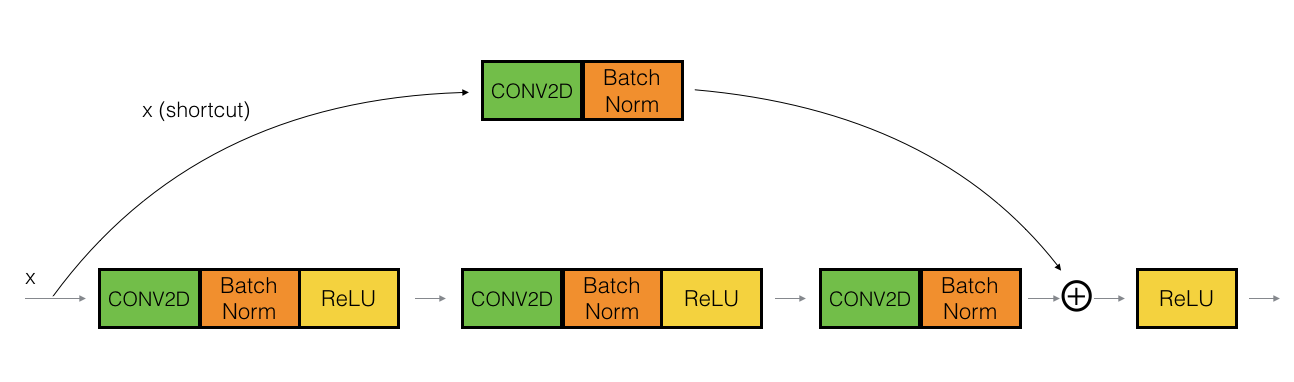
残差网络
就是用了残差单元的网络

为什么残差网络有用
加入了易于学到的线性映射
Network in Network & 1*1 convolutions
1*1的卷积单元,也叫network in network
这种结构在以下情况下有用:
- 我们想要减少通道数
- 节省计算量
- 如果1*1的卷积单元和原来的通道数一样的话,我们就能够保持原有的通道数,并做一些非线性的变换。
Inception network motivation
Inception的基本思想是:在网络的构造中,我们不是去选择使用什么层(比如说是11的卷积还是33的卷积还是pooling等),而是把它们都用上,让算法自己选
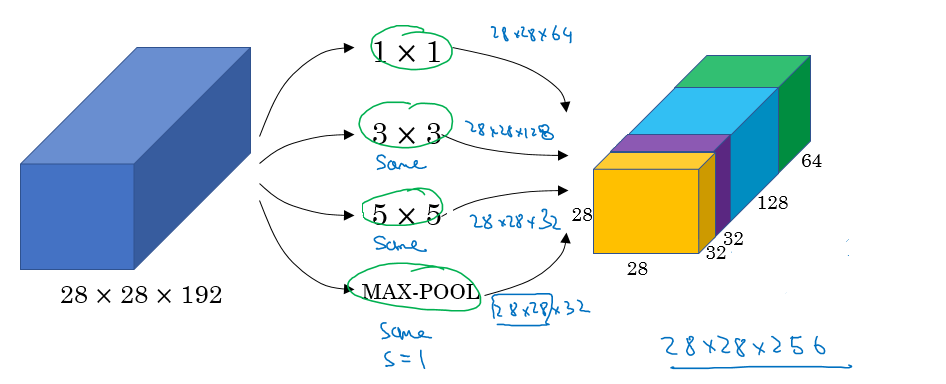
很容易想到这个时候计算量会很大,所以一般会采用1*1的卷积层来降低计算量。并且实践表明这种对于性能影响很小。

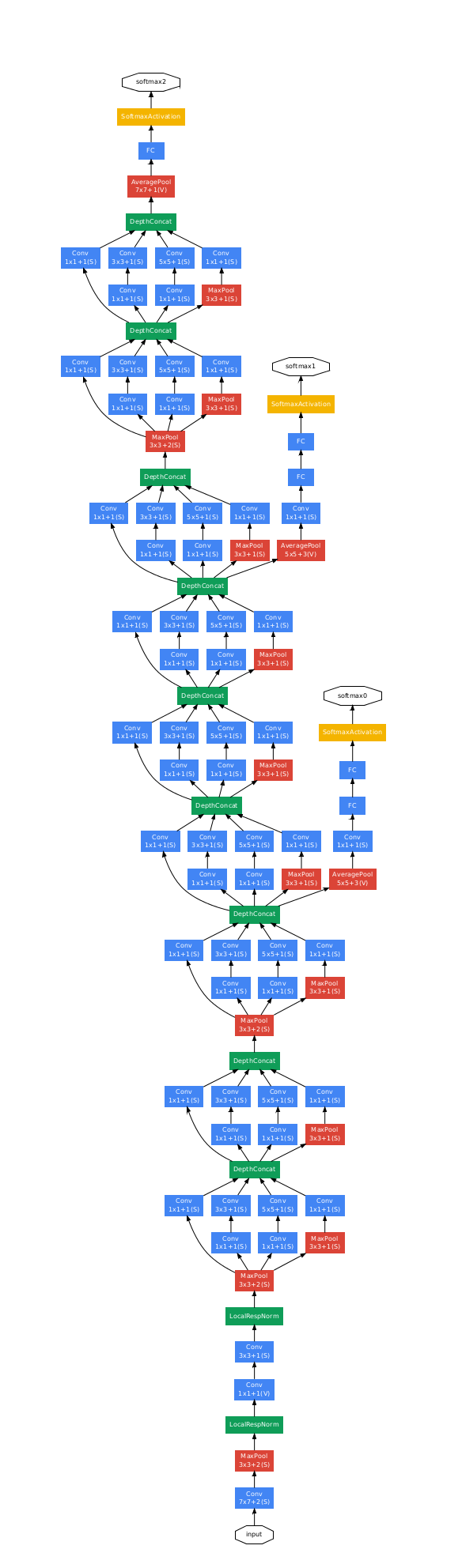
GoogleNet
Data Augmentation
图像可以使用翻转、截取、颜色变换等技巧进行数据增强
Object Detection
几种技术的的区别
- classification:对整张图进行分类

- localization
学习出定位

- detection
有多个物体,给出定位和类别

- semantic segmentation
区分每一个像素的类别,所有有重叠的时候我们无法分出他们

- instance segmentation
不仅是给出框,我们要给出他们的每个像素,并分开他们

标签设计
学习出定位
有多个物体,给出定位和类别
区分每一个像素的类别,所有有重叠的时候我们无法分出他们
不仅是给出框,我们要给出他们的每个像素,并分开他们
做object detection我们不光要在标签给出类别,还要给出bounding box的位置
Y = [
Pc # Probability of an object is presented
bx # Bounding box
by # Bounding box
bh # Bounding box
bw # Bounding box
c1 # The classes
c2
…
]- 损失函数
L(y',y) = {
(y1'-y1)^2 + (y2'-y2)^2 + … if y1 = 1
(y1'-y1)^2 if y1 = 0
}- 一般来说对于概率,我们用logloss,对于bounding box我们用MSE
landmark detection
对于某些应用,如人脸检测的时候,你希望把眼睛位置一起标记出来,这时候就可以在label中把这些坐标也加进去
sliding windows
简单的说就是你选个窗口大小,然后按照一定重复进行划窗,选用分类器对这些进行分类,然后合并一些有物体重复的窗,最后选出来最佳的窗格。
对于传统算法一般选择线性分类器,这样的话速度才够。但是这样精度不太好,深度学习则复杂度会太高。所以一般有两种方案:
- 采用一种卷积的方式做
- 压缩网络
基于卷积的滑动窗口

本质上就是将传统卷积网的最后的全连接层也换成是卷积层,然后其实就可以一起把移动窗口做了
Bounding box Prediction

先把图像分块,然后每个地方用上面的卷积滑动窗口预测得到窗口
Intersection Over Union

IoU,即评价detection的方式,等于交集除以并集
如上图,红色的是真实值,紫色的是预测值,然后可以计算
如果IoU> 0.5就说明表现还不错
Non-max Suppression
用前面的方法我们可以会多次检测到同一个物体,这个方法可以解决这个问题
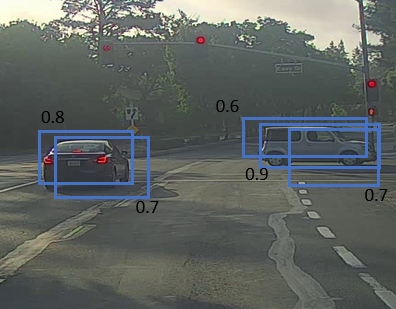
- 首先丢弃预测概率小于0.6的结果
- 如果还有多个box,选择概率最大的,丢弃前一步中任何IoU小于0.5
如果有多个类别,我们就需要重复以上多次
Anchor Box
上面的技巧只能解决单个物体,如果有多个重合的物体就会比较难办。
anchor box感觉上就是把多个单个的box连接起来。也可以使用聚类的方式来做
YOLO 算法
YOLO算法其实就是综合用了上面的这些技巧
首先用基于卷积的移动窗口

移除预测概率低的

移除IoU低的
YOLO在识别小物体时效果不是太好
Region Proposal(R-CNN)
其他的检测算法还有R-CNN、SSD等
Face Recognition
verification和recognition
verification就是给你一个人和他的id,判断是不是这个人。recognition就是给一个人的图片,如果他是库中k个人之一就输出其id
One Shot Learning
从这个人的一张图片就能够学习出识别他的系统。这个其实是基于相似度函数。即我通过一个网络抽取特征(这个网络是提前训练好的),然后比较新来的人的特征和这里的是不是吻合。也可以直接预训练一个分类器
Siamese Network
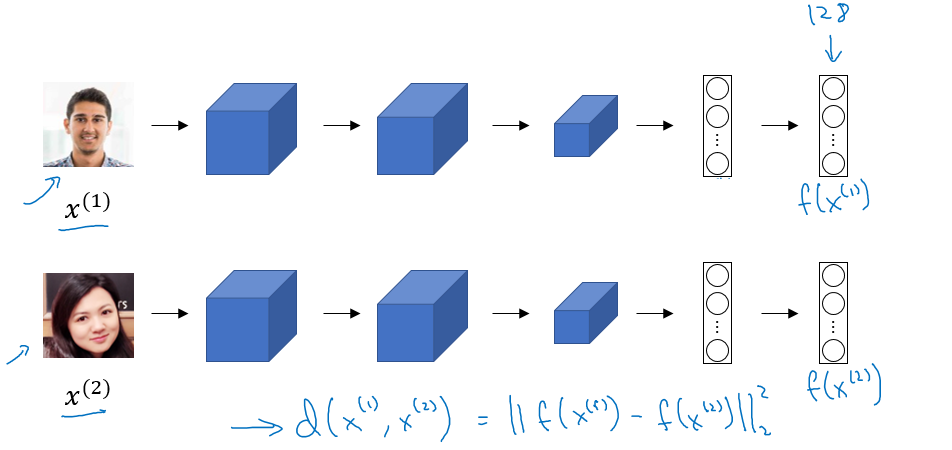
Triplet Loss
给定三个图片A(目标图片)、P(正样本)、N(负样本)
L(A, P, N) = max (||f(A) - f(P)||2 - ||f(A) - f(N)||2 + alpha , 0)
Face Verification and Binary Classification
得到特征算距离
风格迁移
这个问题其实有两方面意义:
- 相当于神经网络可以做“创作”
- 可以从这个理解到卷积层的特征是什么样的
这里的损失函数是通过style cost function和content cost function
content loss
用来衡量生成的图像G和原始内容提供图像C之间的不同,这里通过训练好的神经网络来衡量两个图像content的相似度。其基本想法是,神经网络的每一层可以提取图像的一些特征,那么我用图片在某一层的激活值就可以表示图像的内容。然后两个图像C和G都经过这个神经网络取同一层就可以了(这里一般是取中间层的结果,我猜测是太浅的话不能抓住足够的信息,太深的话就过于细节化了而不会和风格迁移;然后最终一般也是算几层取个加权平均,而在content里面则不会取平均)。最后loss表示为:
style loss
用来衡量生成的图像G和风格提供图像S之间的风格的不同。基本思想是首先对于每一幅图构建一个 style matrix(数学上叫做Gram matrix),然后比较这两个matrix的差距,计算公式如下
Keras
模型的构建遵循:Create->Compile->Fit/Train->Evaluate/Test
Reference
https://github.com/mbadry1/DeepLearning.ai-Summary
课程回顾-Convolutional Neural Networks的更多相关文章
- 课程四(Convolutional Neural Networks),第一周(Foundations of Convolutional Neural Networks) —— 3.Programming assignments:Convolutional Model: application
Convolutional Neural Networks: Application Welcome to Course 4's second assignment! In this notebook ...
- 课程四(Convolutional Neural Networks),第一周(Foundations of Convolutional Neural Networks) —— 2.Programming assignments:Convolutional Model: step by step
Convolutional Neural Networks: Step by Step Welcome to Course 4's first assignment! In this assignme ...
- 课程四(Convolutional Neural Networks),第四 周(Special applications: Face recognition & Neural style transfer) —— 2.Programming assignments:Art generation with Neural Style Transfer
Deep Learning & Art: Neural Style Transfer Welcome to the second assignment of this week. In thi ...
- 课程四(Convolutional Neural Networks),第二 周(Deep convolutional models: case studies) —— 0.Learning Goals
Learning Goals Understand multiple foundational papers of convolutional neural networks Analyze the ...
- 课程四(Convolutional Neural Networks),第二 周(Deep convolutional models: case studies) ——3.Programming assignments : Residual Networks
Residual Networks Welcome to the second assignment of this week! You will learn how to build very de ...
- 课程四(Convolutional Neural Networks),第二 周(Deep convolutional models: case studies) —— 2.Programming assignments : Keras Tutorial - The Happy House (not graded)
Keras tutorial - the Happy House Welcome to the first assignment of week 2. In this assignment, you ...
- 课程四(Convolutional Neural Networks),第一周(Foundations of Convolutional Neural Networks) —— 0.Learning Goals
Learning Goals Understand the convolution operation Understand the pooling operation Remember the vo ...
- 课程四(Convolutional Neural Networks),第四 周(Special applications: Face recognition & Neural style transfer) —— 3.Programming assignments:Face Recognition for the Happy House
Face Recognition for the Happy House Welcome to the first assignment of week 4! Here you will build ...
- 课程四(Convolutional Neural Networks),第四 周(Special applications: Face recognition & Neural style transfer) —— 1.Practice quentions
[解释] This allows us to learn to predict a person’s identity using a softmax output unit, where the n ...
随机推荐
- final,finally,finalize
final:可以修饰属性,可以修饰方法(方法不能被重写,可以继承),可以修饰类(该类不能被继承,不能产生子类) finally:无论什么情况,都会执行 finalize:垃圾回收时,调用此方法
- homework1-201521410029
姓名:孙浩学号: 201521410029指导教师:高见 实验日期:2018年8月9日 1. 虚拟机安装与调试 安装好xp和kali虚拟机之后,查看这三者(包括主机)的i ...
- C语言在宏定义中使用语句表达式和预处理器运算符
语句表达式的亮点在于定义复杂功能的宏.使用语句表达式来定义宏,不仅可以实现复杂的功能,而且还能避免宏定义带来的歧义和漏洞.下面以一个简单的最小值的宏为例子一步步说明. 1.灰常简单的么,使用条件运算符 ...
- 转 Java并发之锁的升级
说明:本文大部分内容来自<并发编程的艺术>,再加上自己网络整理和理解 以下内容来自<java并发编程的艺术>作者:方鹏飞 魏鹏 程晓明 在多线程并发编程中synchronize ...
- Injection
what java EE提供了注入机制,使您的对象能够获取对资源和其他依赖项的引用,而无需直接实例化它们.通过使用将字段标记为注入点的注释之一来装饰字段或方法,可以在类中声明所需的资源和其他依赖项.然 ...
- centos7.6 ssh远程链接配置
1.firewall增加22端口号 增加方式有两种,直接编辑firewall的public.xml增加 vi /etc/firewalld/zones/public.xml 进入后按i健光标移动到zo ...
- JMeter接口压测——ServerAgent监控服务端性能指标
ServerAgent作为一个服务端性能监控插件,结合JMeter自身插件PerfMon可以实现JMeter压测的图形化实时监控,具有良好的实用性.下面讲解一个应用实例 思路: 1. 插件准备 2.打 ...
- abaqus的umat在vs中debug调试
配置参考:https://www.jishulink.com/content/post/333909 常见错误:http://blog.sina.com.cn/s/blog_6116bc050100e ...
- 如何理解Unity组件化开发模式
Unity的开发模式核心:节点和组件,组件可以加载到任何节点上,每个组件都有 gameobject 属性,可以通过这个属性获取到该节点,即游戏物体. 也就是说游戏物体由节点和组件构成,每个组件表示物体 ...
- MAC帧和PPP帧区别