转载-reduceByKey和groupByKey的区别
原文链接-https://www.cnblogs.com/0xcafedaddy/p/7625358.html
先来看一下在PairRDDFunctions.scala文件中reduceByKey和groupByKey的源码

/**
* Merge the values for each key using an associative reduce function. This will also perform
* the merging locally on each mapper before sending results to a reducer, similarly to a
* "combiner" in MapReduce. Output will be hash-partitioned with the existing partitioner/
* parallelism level.
*/
def reduceByKey(func: (V, V) => V): RDD[(K, V)] = {
reduceByKey(defaultPartitioner(self), func)
} /**
* Group the values for each key in the RDD into a single sequence. Allows controlling the
* partitioning of the resulting key-value pair RDD by passing a Partitioner.
* The ordering of elements within each group is not guaranteed, and may even differ
* each time the resulting RDD is evaluated.
*
* Note: This operation may be very expensive. If you are grouping in order to perform an
* aggregation (such as a sum or average) over each key, using [[PairRDDFunctions.aggregateByKey]]
* or [[PairRDDFunctions.reduceByKey]] will provide much better performance.
*
* Note: As currently implemented, groupByKey must be able to hold all the key-value pairs for any
* key in memory. If a key has too many values, it can result in an [[OutOfMemoryError]].
*/
def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])] = {
// groupByKey shouldn't use map side combine because map side combine does not
// reduce the amount of data shuffled and requires all map side data be inserted
// into a hash table, leading to more objects in the old gen.
val createCombiner = (v: V) => CompactBuffer(v)
val mergeValue = (buf: CompactBuffer[V], v: V) => buf += v
val mergeCombiners = (c1: CompactBuffer[V], c2: CompactBuffer[V]) => c1 ++= c2
val bufs = combineByKey[CompactBuffer[V]](
createCombiner, mergeValue, mergeCombiners, partitioner, mapSideCombine=false)
bufs.asInstanceOf[RDD[(K, Iterable[V])]]
}
通过源码可以发现:
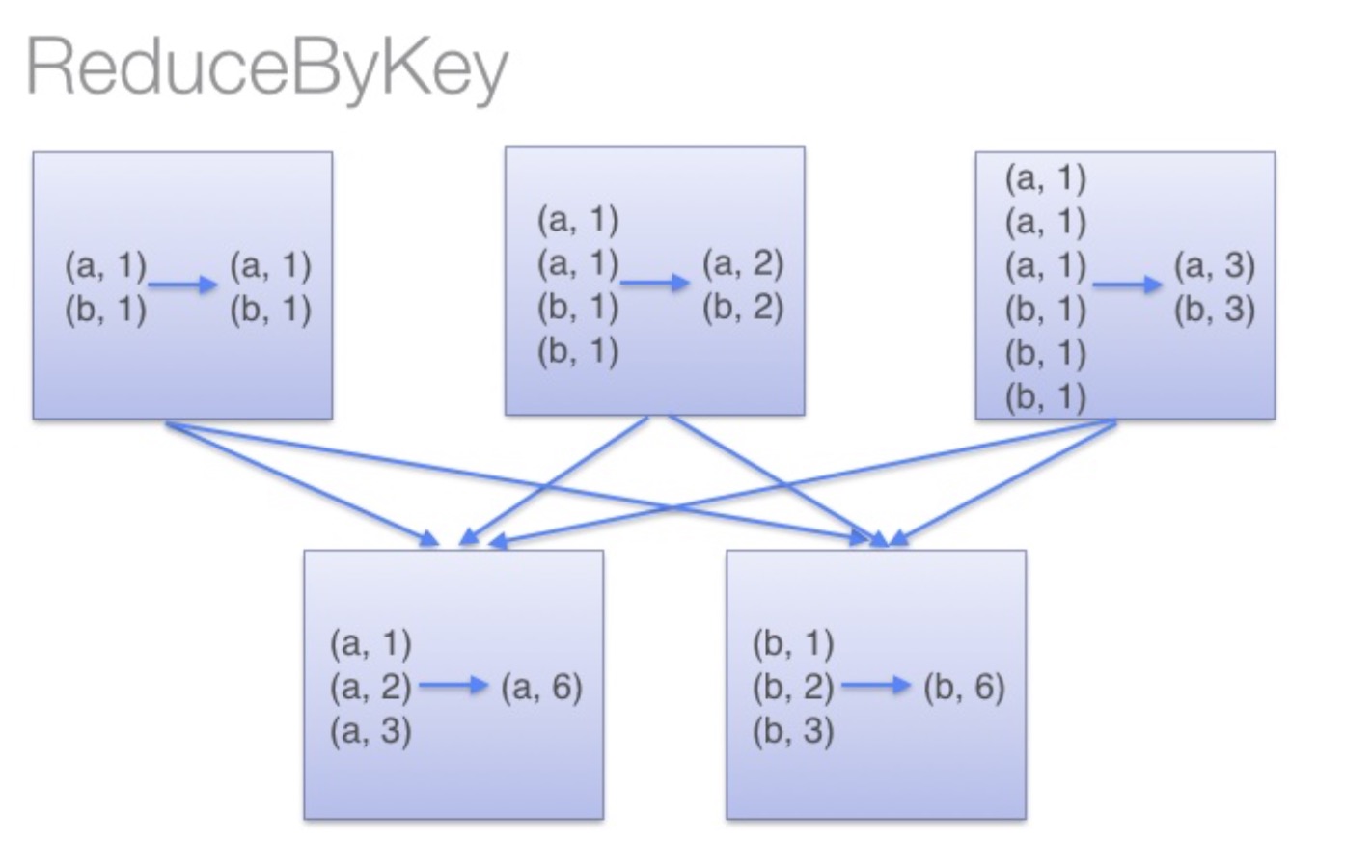
reduceByKey:reduceByKey会在结果发送至reducer之前会对每个mapper在本地进行merge,有点类似于在MapReduce中的combiner。这样做的好处在于,在map端进行一次reduce之后,数据量会大幅度减小,从而减小传输,保证reduce端能够更快的进行结果计算。
groupByKey:groupByKey会对每一个RDD中的value值进行聚合形成一个序列(Iterator),此操作发生在reduce端,所以势必会将所有的数据通过网络进行传输,造成不必要的浪费。同时如果数据量十分大,可能还会造成OutOfMemoryError。
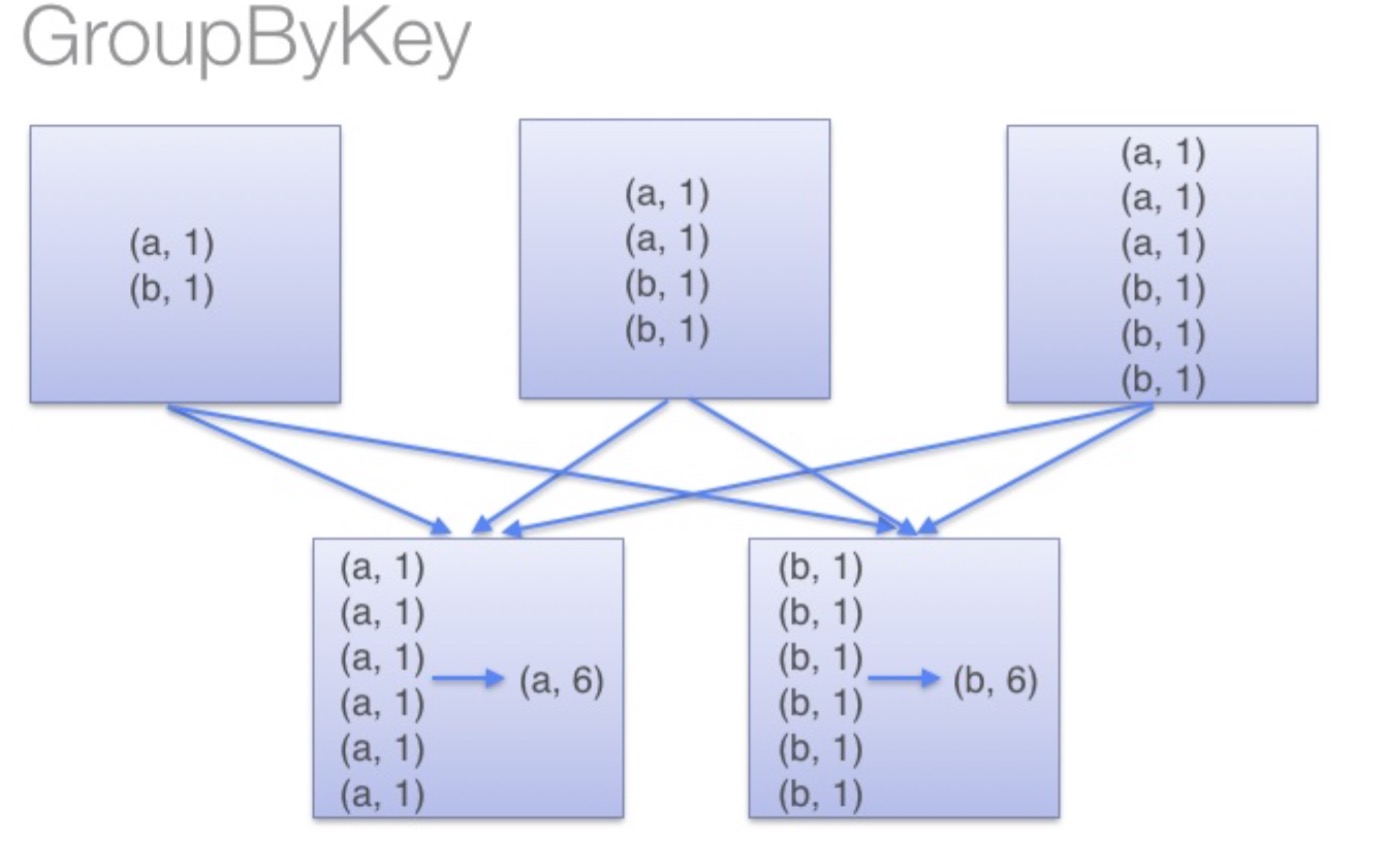
通过以上对比可以发现在进行大量数据的reduce操作时候建议使用reduceByKey。不仅可以提高速度,还是可以防止使用groupByKey造成的内存溢出问题。
转载-reduceByKey和groupByKey的区别的更多相关文章
- reduceByKey和groupByKey的区别
先来看一下在PairRDDFunctions.scala文件中reduceByKey和groupByKey的源码 /** * Merge the values for each key using a ...
- spark:reducebykey与groupbykey的区别
从源码看: reduceBykey与groupbykey: 都调用函数combineByKeyWithClassTag[V]((v: V) => v, func, func, partition ...
- reduceByKey和groupByKey区别与用法
在spark中,我们知道一切的操作都是基于RDD的.在使用中,RDD有一种非常特殊也是非常实用的format——pair RDD,即RDD的每一行是(key, value)的格式.这种格式很像Pyth ...
- 【spark】常用转换操作:reduceByKey和groupByKey
1.reduceByKey(func) 功能: 使用 func 函数合并具有相同键的值. 示例: val list = List("hadoop","spark" ...
- spark RDD,reduceByKey vs groupByKey
Spark中有两个类似的api,分别是reduceByKey和groupByKey.这两个的功能类似,但底层实现却有些不同,那么为什么要这样设计呢?我们来从源码的角度分析一下. 先看两者的调用顺序(都 ...
- 转载>>C# Invoke和BeginInvoke区别和使用场景
转载>>C# Invoke和BeginInvoke区别和使用场景 一.为什么Control类提供了Invoke和BeginInvoke机制? 关于这个问题的最主要的原因已经是dotnet程 ...
- 【Spark算子】:reduceByKey、groupByKey和combineByKey
在spark中,reduceByKey.groupByKey和combineByKey这三种算子用的较多,结合使用过程中的体会简单总结: 我的代码实践:https://github.com/wwcom ...
- spark新能优化之reduceBykey和groupBykey的使用
val counts = pairs.reduceByKey(_ + _) val counts = pairs.groupByKey().map(wordCounts => (wordCoun ...
- 【转载】strlen与sizeof区别
自己小结: sizeof使用时,若是数组变量,则是数组变量占的大小 char a[10]; sizeof(a)=10 若是指针,则为指针大小,数组变量作为函数参数传递时,会退化成指针,且函数内是不知道 ...
随机推荐
- 解题:SDOI2018 战略游戏
题面 先圆方树然后建虚树,答案就是虚树大小.虚树没必要建出来,把原来的点的点权设为1,直接dfs序排序后相邻点求距离加上首尾两个点的距离,最后除以二(画一下可以发现是正反算了两遍),注意还要去掉询问点 ...
- MariaDB安装及基本配置
MariaDB安装及基本配置(CentOS6.9) 数据库基础概念 数据库(Database, DB)是按照数据结构来组织.存储和管理数据的建立在计算机存储设备上的仓库. DBMS: Database ...
- Unable to load script from assets 'index.android.bundle'.make sure you bundle is packaged correctly
解决此问题 以下方法每次都需要执行命令2才能更新 1.创建assets目录 mkdir android/app/src/main/assets 2.执行命令 react-native bundle - ...
- operator new和operator delete
从STL源码剖析中看到了operator new的使用 template<class T> inline void _deallocate(T* buffer) { ::operator ...
- parallels tools 安装
│ - kernel-devel-2.6.32-358.el6.x86_64 │ │ - dkms
- Luogu P3966 [TJOI2013]单词
题目链接 \(Click\) \(Here\) 本题\(AC\)自动机写法的正解之一是\(Fail\)树上跑\(DP\). \(AC\)自动机是\(Trie\)树和\(Fail\)树共存的结构,前者可 ...
- MySQL中IO问题定位
在前面讲过在linux下定位磁盘IO的一个命令:iostat其实还有一个查看linux下磁盘IO读写速度命令:iotop 查看iotop -help,有哪些用法 # iotop -help Usage ...
- linux umask使用方法
A 什么是umask? 当我们登录系统之后创建一个文件总是有一个默认权限的,那么这个权限是怎么来的呢?这就是umask干的事情.umask设置了用户创建文件的默认 权限,它与chmod的效果刚好相 ...
- qml: 多级窗口visible现象;
多级窗口可以通过动态组件进行实现,也可以通过loader加载. 然而,在此要注意窗口显示.隐藏的顺序: 1.当窗口层级为主窗口 - 子窗口A --- 子窗口B: 这种模式, A是B的父窗口,那么在进行 ...
- python自动化开发-[第十二天]-前端html
今日概要: 前端基础之html 1.web服务器的本质: #!/usr/bin/python # -*- coding:utf-8 -*- import socket def handle_reque ...