性能调优6:Spool 假脱机调优
SQL Server的Spool(假脱机)操作符,用于把前一个操作符处理的数据(又称作中间结果集)存储到一个隐藏的临时结构中,以便在执行过程中重用这些数据。这个临时结构都创建在tempdb中,通常的结构是工作表(worktable)和工作文件(workfile)。假脱机运算符会取出表或索引结构中的一部分的数据集,将他们存放在tempdb数据库的临时结构里,我推测:如果这个临时结构用于存储表数据,称作worktable;如果这个临时结构存储的是Hash表,称作workfile。
SQL Server使用Spool操作符的优点是:
- 数据或中间结果集会被多次重用
- 使假脱机数据与源数据保持隔离
一,Spool操作的分类
在执行计划中,Eager Spool和Lazy Spool是逻辑操作符,这两个逻辑操作符之间的区别是:
- Eager Spool:一次性把所有数据存储到临时结构中,它是一个阻塞性的操作符,这意味着它需要读取输入中的所有数据,然后处理完所有的数据行之后,才向下一个操作符返回结果,也就是说,除非Eager Spool把所有的数据行都处理完成,否则无法访问到这些数据。
- Lazy Spool:逐行把数据存储到临时结构中,它是一个非阻塞性的操作符,这意味着它可以边读取数据,边向下一个操作符输出数据,也就是说,在Lazy Spool读取完所有的数据之前,可以访问这些数据。
Spool相关的物理操作符有Spool, Table Spool, Index Spool, Window Spool 和 Row Count Spool,这些物理操作符的作用是:
- Spool运算符用于把查询的中间结果集保存到tempdb数据库中
- Row Count Spool运算符扫描输入,计算现有的行数n,返回行数n,用于描述输入的总行数。
- Index Spool 是把非聚集索引的数据存放到tempdb中的临时结构中,该运算符扫描输入的索引结构,把每行的副本放置在隐藏的Spool文件中(存储在tempdb数据库中的worktable,且只在查询的生命周期内存在),并为这些行创建非聚集索引,这样可以使用索引的seek功能来仅输出那些满足SEEK()谓词的行。
- Table Spool 运算符是把表数据存放到tempdb中的临时结构中,该操作符扫描输入的数据表,把每行的副本放置在隐藏的Spool表中,此表叫做worktable,存储在tempdb数据库中,且只在查询的生命周期内存在
- Window Spool 操作符和OVER() 窗口函数息息相关,因为只有OVER()函数才会使用到Window Spool 操作符。
二,Lazy Spool调优
在查询计划中出现Spool操作符,意味着查询语句需要存储临时数据集,以便在执行过程中重用这些数据。在查询语句执行的生命周期内,SQL Server为了存储数据,会在tempdb中创建临时表,然后把临时数据集存储到临时表中,这个操作会给硬盘带来额外的IO开销。tempdb的使用最终会使查询语句的开销增加,并且常常导致查询性能不佳。
Lazy Spool之所以被成为懒假脱机,这是因为它仅在收到请求时才会把数据加载到临时结构中,并且在加载数据时不会停止数据流。虽然Lazy Spool是一个非阻塞的操作符,但是当有大量的数据需要处理时,它的开销会非常大。
当查询计划中出现多个Lazy Spool操作符时,这种情况可能会导致非常严重的性能问题,例如:
SET STATISTICS IO ON
GO SELECT [InvoiceID], [OrderID]
FROM [Sales].[Invoices] o
WHERE [TotalDryItems] = (SELECT AVG([TotalDryItems])
FROM [Sales].[Invoices] o1
WHERE o.[CustomerID] = o1.[CustomerID]
GROUP BY [CustomerID])
GO
当你执行上述查询之后,从SSMS中你可以看到如下的执行计划图形:
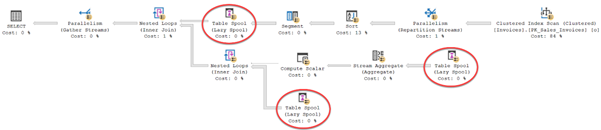
如果你仔细查看这个执行计划,你会发现三个不同的Lazy Spool操作符,每一个操作符的开销都是0%,但是,当你切换到Message Tab,你会看到IO的统计信息,Lazy Spool操作符把大量把大量的数据存储到Worktable中,也就是说,消耗了14.4万的逻辑读操作,把数据写入到tempdb中。
(17214 rows affected)
Table 'Invoices'. Scan count 9, logical reads 11994, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 24, logical reads 143680, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
要对这个查询进行性能调优,必须保证执行计划不会把大量的数据加载到tempdb中,通常修复Lazy Spool性能低下的做法是创建新的索引。
在上述的示例查询中,有两个where子句,一个where子句是关于CustomerID的,另一个是关于TotalDryItems,因此,我们在表[Sales].[Invoices]上创建一个关于这两列的索引,首先查看这两列的选择性(即唯一值的数量),把高选择性的列作为索引的第一列:
SELECT COUNT(DISTINCT [TotalDryItems]) AS [CountTotalDryItems]
,COUNT (DISTINCT [CustomerID]) As [CountCustomerID]
FROM [Sales].[Invoices]
GO
列CustomerID唯一值的数量是663,列TotalDryItems唯一值的数量是6,由于CustomerID列的选择性高,因此,把CustomerID作为索引的第一列:
CREATE NONCLUSTERED INDEX [IX_FirstTry]
ON [Sales].[Invoices]
([CustomerID] ASC, [TotalDryItems] ASC)
INCLUDE ([InvoiceID], [OrderID])
GO
重新执行示例查询语句,得到一下的执行计划图示:
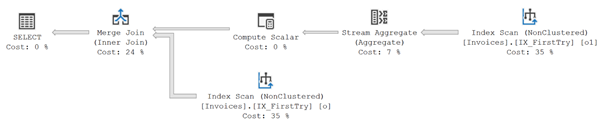
从执行计划图示中可以清楚地看出,对表[Sales].[Invoices]执行Index Scan操作,由于索引IX_FirstTry比聚集索引扫面要窄的多,因此这是一个比Clustered Index Scan快很多的操作。最重要的是,执行计划中没有Lazy Spool操作符,不需要把数据写入tempdb,然后再从tempdb中读取,这大大提升了查询语句的执行性能。
查看Message Tab,检查IO统计:
Table 'Invoices'. Scan count 2, logical reads 396, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
从统计信息中,可以看出,没有worktable,因此查询不需要把数据写入tempdb,再从tempdb中读取数据。另外,由于使用了索引 IX_FirstTry,对Invoices执行的逻辑读的次数,从11994减少到396,因此,查询语句的IO性能成倍提升。
三,Eager Spool 应用场景
在更新语句中,如果执行计划使用聚集索引来查找数据行,那么执行计划不会使用Eager Spool操作符;如果执行计划使用非聚集索引来查找数据,那么执行计划就会使用Eager Spool操作符来与数据源隔离。
例如,下面的语句使用非聚集索引(IX_Price)来查找和读取数据:
UPDATE Inventory SET Price = Price * 1.1
FROM Inventory WITH (INDEX = IX_Price)
WHERE Price < 100.00

从上面的执行计划中,可以看到,从非聚集索引IX_Price读取数据之后,SQL Server使用Table Spool(Eager Spool)阻塞性操作符,它读取Index Seek操作符输入的所有数据之后,把数据写入到tempdb数据库中。这样,Update语句不会从非聚集索引IX_Price读取任何数据,取而代之,Update语句使用Eager Spool操作符来执行数据的读取操作。
From above execution plans, we see that after reading the data from non-clustered in IX_Price SQL Server uses Table Spool(Eager Spool) blocking operator. It reads all data and then moves to next operator. In our example, Eager Spool will read all data from IX_Price then move to tempdb and hence later on UPDATE doesn’t read non-clustered index IX_Price anymore and instead all reads are performed using Eager Spool operator.
如果SQL Server不适用Eager Spool操作符,SQL Server 需要直接从非聚集索引IX_Price中读取数据,定位到目标数据行,然后逐行更新数据。问题是在这种情景下,非聚集索引中行的位置可能被重置,导致数据被多次更新,使用Eager Spool可以避免这个问题。
参考文档:
Performance Tuning Made Easy – Optimizing Lazy Spool
SQL Server Eager Spool operator – Part2
Operator of the Week – Spools, Eager Spool
性能调优6:Spool 假脱机调优的更多相关文章
- OCM_第十四天课程:Section6 —》数据库性能调优_各类索引 /调优工具使用/SQL 优化建议
注:本文为原著(其内容来自 腾科教育培训课堂).阅读本文注意事项如下: 1:所有文章的转载请标注本文出处. 2:本文非本人不得用于商业用途.违者将承当相应法律责任. 3:该系列文章目录列表: 一:&l ...
- 第三篇、调优之路 Apache调优
1. 简介 在第一篇中整合了apache + tomcat ,利用了apache解析静态文件为tomcat解压.但是在测试机上发现两者性能不足,不能充分利用服务器的性能,该篇中将对apache进行性 ...
- LAMP 系统性能调优之网络文件系统调优
LAMP 系统性能调优之网络文件系统调优 2011-03-21 09:35 Sean A. Walberg 网络转载 字号:T | T 使用LAMP系统的用户,都想把自己LAMP性能提高运行的速度提高 ...
- 自动调参库hyperopt+lightgbm 调参demo
在此之前,调参要么网格调参,要么随机调参,要么肉眼调参.虽然调参到一定程度,进步有限,但仍然很耗精力. 自动调参库hyperopt可用tpe算法自动调参,实测强于随机调参. hyperopt 需要自己 ...
- Tomcat性能调优-JVM监控与调优
参数设置 在Java虚拟机的参数中,有3种表示方法用"ps -ef |grep "java"命令,可以得到当前Java进程的所有启动参数和配置参数: 标准参数(-),所有 ...
- 【总结】性能调优:JVM内存调优相关文章
[总结]性能调优:JVM内存诊断工具 [总结]性能调优:CPU消耗分析 [总结]性能调优:消耗分析 JVM性能调优
- 如何利用 JuiceFS 的性能工具做文件系统分析和调优
JuiceFS 是一款面向云原生环境设计的高性能 POSIX 文件系统,在 AGPL v3.0 开源协议下发布.作为一个云上的分布式文件系统,任何存入 JuiceFS 的数据都会按照一定规则拆分成数据 ...
- 一文带你深入了解JVM性能调优以及对JVM调优的全面总结
目录 JVM调优 概念 基本垃圾回收算法 垃圾回收面临的问题 分代垃圾回收详述1 分代垃圾回收详述2 典型配置举例1 典型配置举例2 新一代的垃圾回收算法 调优方法 反思 一.JVM调优的一些概念 数 ...
- Linux性能优化之磁盘I/O调优
I/O指标已介绍,那么如何查看系统的这些指标呢? 一.根据工具查性能 二.根据性能找工具 三.磁盘I/O观察实例 iostat 是最常用的磁盘 I/O 性能观测工具,它提供了每个磁盘的 使用率 . I ...
随机推荐
- SpringBoot-学习笔记
启动方式 运行main方法 @SpringBootApplication public class BootApplication { public static void main(String[] ...
- python使用sax实现xml解析
之前在使用xml解析的时候,在网上搜了很多教程,最终没有能按照网上的教程实现需求. 所以呢,只好自己去看源码,在sax的__init__.py下看到这么一段代码: 1 def parse(source ...
- GPA简介
GPA(Graphics Performance Analyzers)是Intel公司提供的一款免费的跨平台性能分析工具. 填写e-mail.name和country并提交后,就会收到一封有专属下载链 ...
- 口碑订单,ERP本地加/退菜无法回流至手机端的解决办法-订单金额不统一erp本地加菜H5没有
关于 口碑订单,ERP本地加/退菜无法回流至手机端的解决办法-订单金额不统一erp本地加菜H5没有 1. 2. 3. PS:是正餐后付的务必要选择口碑后付 完成以上设置即可
- ORA-1652: unable to extend temp segment by 128 in tablespace xxx Troubleshootin
当收到告警信息ORA-01652: unable to extend temp segment by 128 in tablespace xxxx 时,如何Troubleshooting ORA-16 ...
- [20190213]学习bbed-恢复删除的数据.txt
[20190213]学习bbed-恢复删除的数据.txt --//以前也做过类似测试,当时在用bbed做verify时错误都不处理,当时的想法就是能读出就ok了.--//而且当时也做成功,纯粹是依葫芦 ...
- Linux系统修改日期时间
linux修改时间 服务器时间与网络时间不符: 一.手动修改 1. date命令:查看当前时间 2. date -s 时分秒 :修改时间 还需要把日期改过来 3. date -s 完整日期时间 ...
- C#中的委托和事件 - Part.1
注意:文中代码在VS2005下通过,由于VS2003(.Net Framework 1.1)不支持隐式的委托变量,所以如果在一个接受委托类型的位置直接赋予方法名,在VS2003下会报错,解决办法是显式 ...
- ASYNC_NETWORK_IO和PREEMPTIVE_OS_WAITFORSINGLEOBJECT等待事件
背景环境: SQL Server 2005或以上 Select * from 某个表,表的数据量约为30万行,在执行语句时通过观察sys.dm_exec_requests中的wait_type列发现是 ...
- 打印窗口时,一张A4纸单位为缇的大小
一张A4长297毫米也就是16839.9twip宽210毫米就是11907twip