Python常用字符编码(转)
Python常用字符编码
字符编码的常用种类介绍

第一种:ASCII码
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是现今最通用的单字节编码系统,并等同于国际标准ISO/IEC 646。如下图所示:

由于计算机是美国人发明的,因此,最早只有127个字母被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母 A的编码是65,小写字母 a的编码是97。后128个称为扩展ASCII码。
在这里,每一位0或者1所占的空间单位为bit(比特),这是计算机中最小的表示单位,每8个bit组成一个字符,这是计算机中最小的存储单位。
常见换算单位:
bit 位,计算机中最小的表示单位
8bit = 1bytes 字节,最小的存储单位,1bytes缩写为1B
1KB=1024B
1MB=1024KB
1GB=1024MB
1TB=1024GB
第二种:GBK 和 GB2312
对于我们来说能在计算机中显示中文字符是至关重要的,然而ASCII表里连一个偏旁部首也没有。所以我们还需要一张关于中文和数字对应的关系表。一个字节只能最多表示256个字符,要处理中文显然一个字节是不够的,所以我们需要采用两个字节来表示,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
第三种:Unicode
但如以来,就会出现一个问题,各个国家都一套自己的编码,就不可避免会有冲突,这是该怎么办呢?
因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
现在,分析一下ASCII编码和Unicode编码的区别:
ASCII编码是1个字节,而Unicode编码通常是2个字节。
字母A用ASCII编码是十进制的65,二进制的01000001;
字符0用ASCII编码是十进制的48,二进制的00110000;
汉字“中”已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001。
但如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
第四种:UTF-8
基于节约的原则,出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间了。如下所示:

从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
我们总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件。如下图:
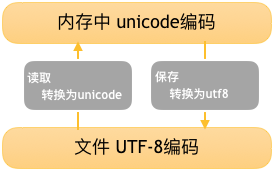
以上内容搬运整理自:https://www.luffycity.com/python-book/di-2-zhang-python-ji-chu-2/23-zi-fu-bian-ma.html
Python常用字符编码(转)的更多相关文章
- Python常用字符编码
字符编码的常用种类介绍 第一种:ASCII码 ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一 ...
- python 3字符编码
python 3字符编码 官方链接:http://legacy.python.org/dev/peps/pep-0263/ 在Python2中默认是ascii编码,Python3是utf-8编码 在p ...
- Python 常用 PEP8 编码规范
Python 常用 PEP8 编码规范 代码布局 缩进 每级缩进用4个空格. 括号中使用垂直隐式缩进或使用悬挂缩进. EXAMPLE: ? 1 2 3 4 5 6 7 8 9 10 11 12 13 ...
- 转:Python常见字符编码及其之间的转换
参考:Python常见字符编码 + Python常见字符编码间的转换 一.Python常见字符编码 字符编码的常用种类介绍 第一种:ASCII码 ASCII(American Standard Cod ...
- Python基础-字符编码与转码
***了解计算机的底层原理*** Python全栈开发之Python基础-字符编码与转码 需知: 1.在python2默认编码是ASCII, python3里默认是utf-8 2.unicode 分为 ...
- Python的字符编码
Python的字符编码 1. Python字符编码简介 1. 1 ASCII Python解释器在加载.py文件的代码时,会对内容进行编码,一般默认为ASCII码.ASCII(American St ...
- Python常见字符编码间的转换
主要内容: 1.Unicode 和 UTF-8的爱恨纠葛 2.字符在硬盘上的存储 3.编码的转换 4.验证编码是否转换正确 5.Python bytes类型 前 ...
- Python 的字符编码
配置: Python 2.7 + Sublime Text 2 + OS X 10.10 本文意在理清各种编码的关系并以此解决 Python 中的编码问题. 1 编码基本概念 只有先了解字符表.编码字 ...
- Python(字符编码)
https://www.cnblogs.com/zihe/p/6993891.html 一 了解字符编码的知识储备 1. 文本编辑器存取文件的原理(nodepad++,pycharm,word) 打开 ...
随机推荐
- *&p理解
要明白这个需明白两个基础: 运算符*优先级高于&, 两个运算符都是从右向左结合运算 所以,*&a 的意思就是先运算 *,得到 指针,再通过 &,获取指针的引用 如果不理解,继续 ...
- Jquery 一个页面多个倒计时 实现
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- c# 程序只能运行一次(多次运行只能打开同一个程序)
转自:https://social.msdn.microsoft.com/Forums/zh-CN/6398fb10-ecc2-4c03-ab25-d03544f5fcc9/2291420309357 ...
- Handlebars.js registerHelper
Handlebars.registerHelper('link', function (text, url) { text = Handlebars.Utils.escapeExpression(te ...
- Java中所涉及到的设计模式小记
一.JAVA设计模式一共有23中.其中这23中大体可以分为3类,具体分法如下所示: 1.创建型模式:涉及到的设计模式共5种,分别是: 工厂方法模式.抽象工厂模式.单例模式.建造者模式.原型模式 2.结 ...
- redis4.0.13主从、哨兵、集群3种模式的 Server端搭建、启动、验证
本文使用的是redis-4.0.13.tar.gz版本. 两个centos7系统虚拟机:192.168.10.140.192.168.10.150 redis各版本下载地址:http://downlo ...
- 必做课下作业MyCP
20175227张雪莹 2018-2019-2 <Java程序设计> 必做课下作业MyCP 要求 编写MyCP.java 实现类似Linux下cp XXX1 XXX2的功能,要求MyCP支 ...
- python数据类型(字符串、列表操作)
一.整形和浮点型整形也就是整数类型(int)的,在python3中都是int类型,没有什么long类型的,比如说存年龄.工资.成绩等等这样的数据就可以用int类型,有正整数.负整数和0,浮点型的也就是 ...
- 面试题_默认传参list
# ###2.值是多少 def extendList(val, list=[]): list.append(val) return list 如果默认形参是列表,会提前在内存中开辟一个空间存储列表 如 ...
- 理解block和inode
什么是block和inode? 定义:block就像是杯子 inode就像是杯子的编号,因为杯子太多了 1.根据文件的大小,在磁盘中储存时会占用一个或多个block:那么究竟多大的文件会使用一个blo ...