Python学习笔记之爬虫
爬虫调度端:启动爬虫,停止爬虫,监视爬虫运行情况
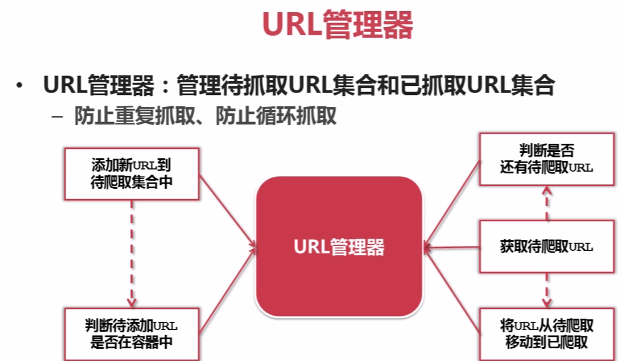
URL管理器:对将要爬取的和已经爬取过的URL进行管理;可取出带爬取的URL,将其传送给“网页下载器”
网页下载器:将URL指定的网页下载,存储成一个字符串,在传送给“网页解析器”
网页解析器:解析网页可解析出①有价值的数据②另一方面,每个网页都包含有指向其他网页的URL,解析出来后可补充进“URL管理器”

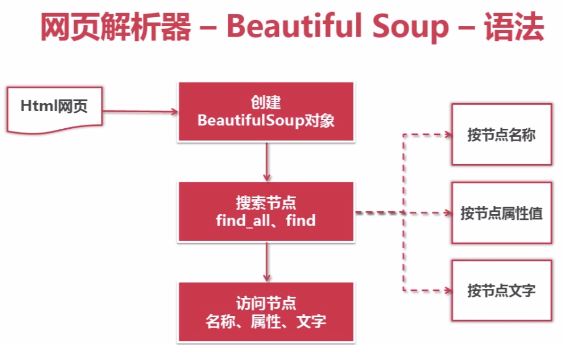
网页解析器——Beautiful Soup-语法:
例如以下代码:

对应的代码:
1、创建BeautifulSoap对象
2、搜索节点(find_all,find)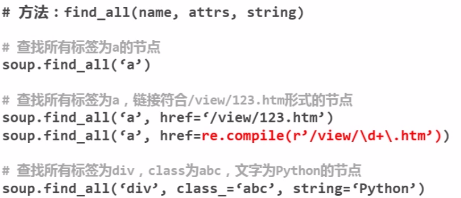
3、访问节点信息
- # -*- coding: UTF-8 -*-
- from bs4 import BeautifulSoup
- import re
- html_doc = """
- <html><head><title>The Dormouse's story</title></head>
- <body>
- <p class="title"><b>The Dormouse's story</b></p>
- <p class="story">Once upon a time there were three little sisters; and their names were
- <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
- <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
- <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
- and they lived at the bottom of a well.</p>
- <p class="story">...</p>
- """
- soup = BeautifulSoup(html_doc,'html.parser', from_encoding='utf-8')#(文档字符串,解析器,指定编码utf-8)
- print('获取所有的连接:')
- links = soup.find_all('a')
- for link in links:
- print link.name, link['href'],link.get_text()
- print('获取Lacie的连接:')
- link_node = soup.find('a', href='http://example.com/lacie')#text='Lacie'
- print link_node.name,link_node['href'],link_node.get_text()
- print('正则匹配')
- link_node = soup.find('a', href=re.compile(r'ill'))
- print link_node.name,link_node['href'],link.get_text()
- print('获取p段落文字:')
- p_node = soup.find('p', class_='title')#class_
- print p_node.name, p_node.get_text()
Python学习笔记之爬虫的更多相关文章
- python学习笔记:"爬虫+有道词典"实现一个简单的英译汉程序
1.有道的翻译 网页:www.youdao.com Fig1 Fig2 Fig3 Fig4 再次点击"自动翻译"->选中'Network'->选中'第一项',如下: F ...
- 吴裕雄--python学习笔记:爬虫基础
一.什么是爬虫 爬虫:一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息. 二.Python爬虫架构 Python 爬虫架构主要由五个部分组成,分别是调度器.URL管理器.网页下载器.网 ...
- Python学习笔记——与爬虫相关的网络知识
1 关于URL URL(Uniform / Universal Resource Locator):统一资源定位符,用于完整地描述Internet上网页和其他资源的地址的一种标识方法 URL是爬虫的入 ...
- 吴裕雄--python学习笔记:爬虫包的更换
python 3.x报错:No module named 'cookielib'或No module named 'urllib2' 1. ModuleNotFoundError: No module ...
- 吴裕雄--python学习笔记:爬虫
import chardet import urllib.request page = urllib.request.urlopen('http://photo.sina.com.cn/') #打开网 ...
- Python学习笔记_爬虫数据存储为xlsx格式的方法
import requests from bs4 import BeautifulSoup import openpyxl wb=openpyxl.Workbook() sheet=wb.active ...
- golang学习笔记17 爬虫技术路线图,python,java,nodejs,go语言,scrapy主流框架介绍
golang学习笔记17 爬虫技术路线图,python,java,nodejs,go语言,scrapy主流框架介绍 go语言爬虫框架:gocolly/colly,goquery,colly,chrom ...
- python学习笔记目录
人生苦短,我学python学习笔记目录: week1 python入门week2 python基础week3 python进阶week4 python模块week5 python高阶week6 数据结 ...
- Python学习笔记之基础篇(-)python介绍与安装
Python学习笔记之基础篇(-)初识python Python的理念:崇尚优美.清晰.简单,是一个优秀并广泛使用的语言. python的历史: 1989年,为了打发圣诞节假期,作者Guido开始写P ...
随机推荐
- 关于thinkpad安装win10操作系统
thinkpad预装的是win8或者win10,会有自己的分区方式是GPT,所以会出现两个引导分区. F2进入tinkpad的bios,F12进入启动选项 我们用pe进入后,用分区工具删除两个分区,然 ...
- asp.net 练习 js 调用webservice
using System; using System.Collections.Generic; using System.Linq; using System.Web; using System.We ...
- 纯javascript代码实现浏览器图片选择预览、旋转、批量上传
工作中遇到的业务场景,和同事一起研究了下,主要是为了兼容IE版本 其实就是一些琐碎的知识点在网上搜集下解决方式,然后集成了下,主要有以下点: 1. IE input type=file的图片预览要用I ...
- 【leetcode 简单】 第八十六题 有效的完全平方数
给定一个正整数 num,编写一个函数,如果 num 是一个完全平方数,则返回 True,否则返回 False. 注意:不要使用任何内置的库函数,如 sqrt. 示例 1: 输入: 16 输出: Tr ...
- Shell基础-通配符
* - 通配符,代表任意字符 ? - 通配符,代表一个字符 # - 注释 | - 分隔两个管线命令的界定 ; - 连续性命令的界定 ~ - 用户的根目录 $ - 变量前需要加的变量值 ! - 逻辑运算 ...
- 兴人类TDD培训札记
兴人类TDD培训札记 恰同学少年,风华正茂:书生意气,挥斥方遒 -- <沁园春 长沙> 幸之 前不久,非常幸运地全程参与了公司与南京5所知名高校合作的"兴人类TDD培训" ...
- 【bzoj题解】2186 莎拉公主的困惑
题目传送门. 题意:求\([1,n!]\)中与\(m!\)互质的数的个数,对质数\(R\)取模,\(n\geq m\). 答案应该等于\(\frac{n!}{m!}\phi(m!)=\frac{n!} ...
- Shell-help格式详解
前言 linux shell命令通常可以通过-h或--help来打印帮助说明,或者通过man命令来查看帮助,有时候我们也会给自己的程序写简单的帮助说明,其实帮助说明格式是有规律可循的 帮助示例 下面是 ...
- Unity教程之-Unity3d中针对Android Apk的签名验证(C#实现)
当Unity开发的游戏以Android Apk的形式发布之后,经常会遇到的一种情况就是别人对我们的游戏进行二次打包,也就是用他们的签名替换掉我们的签名,从而堂而皇之的将胜利果实占为己有.面对这样的情况 ...
- 数据库——mysql如何获取当前时间
1.1 获得当前日期+时间(date + time)函数:now() 除了 now() 函数能获得当前的日期时间外,MySQL 中还有下面的函数: current_timestamp() curren ...