SSIS 数据流的执行树和数据管道
数据流组件的设计愿景是快速处理海量的数据,为了实现该目标,SSIS数据源引擎需要创建执行树和数据管道这两个数据结构,而用户为了快速处理数据流,必须知道各个转换组件的阻塞性,充分利用流式处理流程,利用更少的资源,更快地完成数据处理的任务。
一,执行树
执行树(Execution Tree)是数据流组件(转换和适配器)基于同步关系所建立的逻辑分组,每一个分组都是一个执行树的开始和结束,也可以把执行树理解为一个缓冲区的开始和结束,执行树是一个缓冲区的整个生命周期。每一个执行树能被单独的进程执行,并可以和其他执行树同时并发执行。每一个执行树都对应一个数据缓冲区,该缓存区由数据流管道引擎创建,和执行树的生命周期相同。
大家知道,异步转换组件会结束输入缓冲区,创建新的输出缓冲区,所以,执行树的分组实际上通过异步转换组件来划分的,一个异步转换组件意味着上游执行树的结束和下游执行树的开始。当数据流经过异步转换组件,进入一个新的执行树,上一个执行树的缓冲区和相同数据就不再需要了,因为数据已经被传递到一个新的执行树和一组新的缓冲区中。
在执行树运行期间,数据源组件读取数据,把数据存储到缓存区中,然后转换组件逐个处理缓存中的数据,此时,不需要移动缓冲区,只需要变换转换组件。
During execution of the execution tree, the source reads the data, then stores the data to a buffer, executes the transformation in the buffer and passes the buffer to the next execution tree in the path by passing the pointers to the buffers.
1,缓冲区配置文件
在执行Package时,缓冲区管理器根据Package中的执行树来定义缓冲区配置文件。一个特定的执行树中的所有组件使用的缓冲区配置文件是相同的。当为每个执行树定义缓冲区配置文件时,SSIS缓冲区管理器会查看执行树中所有的转换组件,并在缓冲区中包括所有转换组件需要的每一个字段(Column),这就意味着某些列在初始转换或适配器(源和目的组件)中没有被使用,缓冲区仍然会为这些列分配空间。
优化数据流可以看作是优化关系表,列的宽度和数量越少,缓冲区容纳的数据行数越多。
2,EngineThreads 属性
如果线程可用,并且执行树需要较高的CPU利用率,那么线程调度程序可以为单个执行树分配多个线程。每个转换和适配器(源和目的)都可以接收一个线程,所以如果执行树有N个组件,那么它最多可以拥有N个线程。
数据流任务(Task)有 EngineThreads 属性,用于设置数据流任务中所有执行树在同一时刻能够使用的最大线程数。根据执行树的复杂性,为执行树分配单个或多个线程,能够提高数据流的执行效率。
二,数据管道
管道(Pipeline)是一种“链式模型”,按照一定的顺序,串接不同的程序或者不同的组件,把它们组成一条直线的工作流。对于一个完整的输入,经过各个组件的先后协同处理,得到唯一的最终输出。
管道的模型图是流式的,如下图,就像一条生产线一样,各个组件独立完成特定的目的,并把处理的结果上交到下一层。

SSIS的数据管道(Data Pipeline)是数据流处理的关键功能,如下图所示,数据管道使用内存Buffer来提高处理性能,它能够并发处理数据,减少或消除数据的传递,也就是说,多个转换组件使用同一个缓冲区进行数据处理,减少数据的读写操作。而流式处理的特性,使得数据管道有能力处理海量的数据,而不需要很大的内存资源。
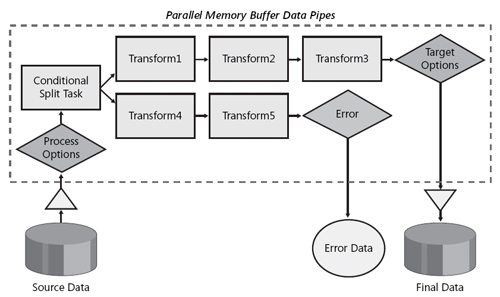
三,转换的阻塞性
根据转换的阻塞性,把转换组件分为阻塞转换和流式转换,或者分为同步转换和异步转换:
- 同步转换,是指组件在处理每个输入行的同时能够把已经处理的数据向下游传递,这意味着,输出行与输入行同步(输入和输出行之间关系是1:1对应的),因此它使用相同的已分配的内存缓冲区,不需要额外的内存。 同步转换需要较低的内存需求,因为它们逐行工作(因此运行速度更快),并且不会阻塞管道中的数据流。 具有同步特性的组件是:查找(Lookup),派生列,数据转换,复制列,多播,行数转换等。
- 异步转换,是指组件要等到所有的输入行都存储到缓存区之后,才开始处理数据,然后把处理完成的数据向下游传递,例如,对于聚合转换,它需要在聚合并生成输出行之前把所有的输入行都加载和存储在内存中。通过这种方式,您可以看到输入行与输出行不同步,并且需要更多内存来存储数据输入和输出的整个数据集(无内存重用)。 这种转换具有更高的内存要求(如果内存不足,缓冲后台处理的可能性很高),并且运行速度通常较慢。 异步转换也称为“阻塞转换”,因为它的性质是阻止输出行,除非所有输入行都被读入内存。
对于异步转换组件,可以进一步细分为两种类型:部分阻塞和全阻塞:
- 部分阻塞转换:在输入数据完全读取之前,转换不会阻塞输出。因为这些变换的输出与输入集不同,因此部分阻塞转换需要分配新的缓冲区来存储新创建的结果集。例如,合并联合转换会连接两个已排序的输入并生成合并输出。 在这种情况下,如果您注意到,数据流管道引擎会创建两个输入内存集,但来自变换的合并输出需要另一组输出缓冲区作为与输入行不同的输出行结构。 这意味着此类转换的内存要求高于转换完成的同步转换。
- 全阻塞转换:除了需要额外的输出缓冲区外,全阻塞转换也会完全阻止输出,除非读取整个输入集合。 例如,排序转换要求所有输入行都加载到缓冲区中,才能开始排序并将有序行传递到输出路径。这些转换是最耗费资源的,只能在不得已的情况下使用,例如,如果您可以从源系统获取已排序的数据,那么请使用该逻辑,而不是使用排序转换对传输到内存中的数据进行排序。
参考文档:
SSIS Architecture and Internals Interview Questions
SSIS 数据流的执行树和数据管道的更多相关文章
- PB数据管道
数据管道提供了一种不同数据库之间传递数据和(或)表结构的方法. 数据管道对象 要完毕数据管道的功能须要提供例如以下内容: 须要数据源和目标数据库,并可以和这两个数据库正常联接 须要源数据库中的哪些表: ...
- SSIS 数据流优化
一,数据流设计优化 数据流有两个特性:流和在内存缓冲区中处理数据,根据数据流的这两个特性,对数据流进行优化. 1,流,同时对数据进行提取,转换和加载操作 流,就是在source提取数据时,转换组件处理 ...
- SSIS 系列 - 在 SSIS 中使用 Multicast Task 将数据源数据同时写入多个目标表,备份数据表,以及写入Audit 信息
转自http://www.cnblogs.com/biwork/p/3328838.html 在 SSIS Data Flow 中有一个 Multicast 组件,它的作用和 Merge, Merge ...
- 微软BI 之SSIS 系列 - 使用 Multicast Task 将数据同时写入多个目标表,以及写入Audit 与增量处理信息
开篇介绍 在 SSIS Data Flow 中有一个 Multicast 组件,它的作用和 Merge, Merge Join 或者 Union All 等合并数据流组件对比起来作用正好相反.非常直观 ...
- Kafka连接器建立数据管道
1.概述 最近,有同学留言咨询Kafka连接器的相关内容,今天笔者给大家分享一下Kafka连接器建立数据管道的相关内容. 2.内容 Kafka连接器是一种用于Kafka系统和其他系统之间进行功能扩展. ...
- c#直接调用ssis包实现Sql Server的数据导入功能
调用ssis包实现Sql Server的数据导入功能网上已经有很多人讨论过,自己参考后也动手实现了一下,上一次笔者的项目中还用了一下这个功能.思前想后,决定还是贴一下增强记忆,高手请54. 1.直接调 ...
- Apache Beam实战指南 | 大数据管道(pipeline)设计及实践
Apache Beam实战指南 | 大数据管道(pipeline)设计及实践 mp.weixin.qq.com 策划 & 审校 | Natalie作者 | 张海涛编辑 | LindaAI 前 ...
- 【tensorflow2.0】数据管道dataset
如果需要训练的数据大小不大,例如不到1G,那么可以直接全部读入内存中进行训练,这样一般效率最高. 但如果需要训练的数据很大,例如超过10G,无法一次载入内存,那么通常需要在训练的过程中分批逐渐读入. ...
- SQL Server 执行计划利用统计信息对数据行的预估原理二(为什么复合索引列顺序会影响到执行计划对数据行的预估)
本文出处:http://www.cnblogs.com/wy123/p/6008477.html 关于统计信息对数据行数做预估,之前写过对非相关列(单独或者单独的索引列)进行预估时候的算法,参考这里. ...
随机推荐
- word用宏命令完美解决列表编号变黑块的问题
相信很多人跟我一样,多次定义新的多级列表,会导致列表编号变成下面这样黑块 在百度搜索结果尝试了鼠标左键选中应用样式,文档关闭后打开问题依旧: 还是得感谢万能的Google,帮我找到了答案. 问题根因: ...
- September 15th 2017 Week 37th Friday
First I need your hand, then forever can begin. 我需要牵着你的手,才能告诉你什么是永远. If you want to shake hands with ...
- fountion 的调用 和 打印返回值 + 占位符
结果: (2) 结果
- [转载并收藏]JavaScript 疲劳终极指南:我们行业的真相
这篇文章说的深得我心,特别是前半段. 特此收藏. 中文译文:http://www.zcfy.cc/article/the-ultimate-guide-to-javascript-fatigue-re ...
- 026.2 网络编程 UDP聊天
实现,通过socket对象 ##############################################################需求建立UDP发送端:###思路:1.建立可以实 ...
- npm使用小结
npm包管理工具使用小结 npm(node package manager)是一个node包管理工具,我们可以方便的从npm服务器下载第三方包到本地使用. 安装: NPM是随同NodeJS一起安装的包 ...
- python decorator的本质
推荐查看博客:python的修饰器 对于Python的这个@注解语法糖- Syntactic Sugar 来说,当你在用某个@decorator来修饰某个函数func时,如下所示: @decorato ...
- BZOJ1022:[SHOI2008]小约翰的游戏John(博弈论)
Description 小约翰经常和他的哥哥玩一个非常有趣的游戏:桌子上有n堆石子,小约翰和他的哥哥轮流取石子,每个人取的时候,可以随意选择一堆石子,在这堆石子中取走任意多的石子,但不能一粒石子也不取 ...
- ElasticSearch 获取es信息以及索引操作
检查集群的健康情况 GET /_cat/health?v green:每个索引的primary shard和replica shard都是active状态的yellow:每个索引的primary sh ...
- macbook下 go 语言的 helloworld
go语言开发的目录 一般go语言$GOPATH 目录约定有三个子目录: src 存放源代码(比如:.go .c .h .s等) pkg 编译后生成的文件(比如:.a) bin 编译后生成的可执行文件( ...