RabbitMQ上手记录–part 6-Shovel
上一part《RabbitMQ上手记录–part 5-节点集群高可用(多服务器)》讲到了通过多个服务器来搭建RabbitMQ的节点集群,示例当中提到的服务器都是在同一个局域网中的(实际上是一个机器上的多个不同虚拟机而已),这种使用方式适用于在同一个数据中心的情况。互联网里常常提到异地多活、多数据中心来实现更高级别的高可用。我的理解是当数据或者访问量超过当个数据中心规模时,通过更多的数据中心来提供更多的访问量支持,同时当某地数据中心出问题时,也不会让数据因为都放在同一个数据中心而导致整个系统宕机。
RabbitMQ通过Shovel插件实现节点集群跨多数据中心的需求。下面来简单了解一下Shovel的一些基本概念。
Shovel基本概念
Shovel是RabbitMQ的一个插件,这个插件的功能就是将源节点的消息发布到目标节点,这个过程中Shovel就是一个客户端,它负责连接源节点,读取某个队列的消息,然后将消息写入到目标节点的exchange中。根据这么一个概念,其实也可以自己开发一个简单的程序,负责从一个节点读取数据然后发送到目标节点。
使用Shovel的好处
1.Shovel能在不同数据中心之间传递消息,源节点和目标节点可以使用不同的用户和vhosts,不同的RabbitMQ版本,并且不需要使用相同的cookie token(在上一part实现多服务器节点集群是,我们特意将每个主机的cookie token都设置成一样)
2.客户端的连接允许连接断开的同时不丢失消息
3.支持多个版本的AMQP协议
具体工作方式
Shovel插件通过定义一个或多个shovel来实现消息的传递。
shovel实现了以下功能
1.连接源节点和目标节点
2.读取(或者说是consume)队列里的消息
3.发布消息到目标节点(通过将消息发布到目标节点的exchange,并通过routing_key的方式发布)
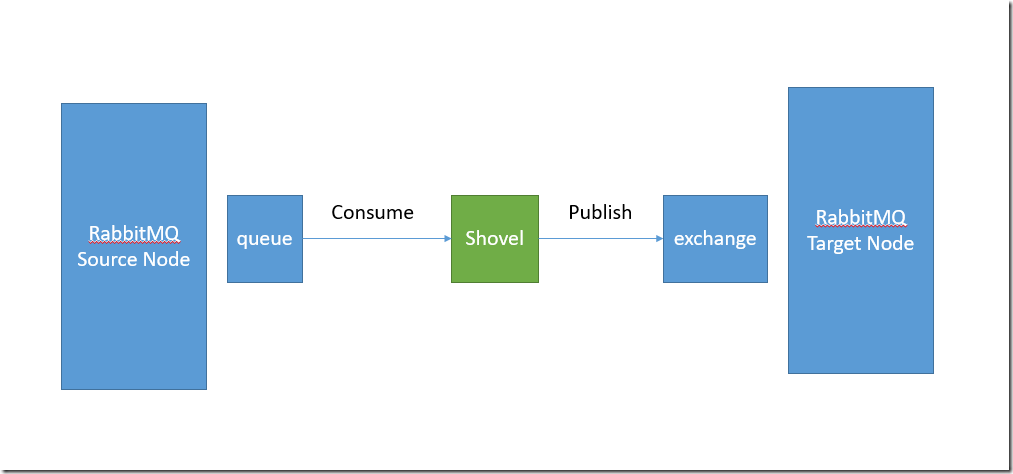 (Shovel的工作过程简要描述)
(Shovel的工作过程简要描述)
使用Shovel
梳理完理论之后,接下来将使用两个不同地域云主机来实践一下(有点小成本,需要自行租用云主机)。
1.准备云主机
1.需要有两台云主机,我这里两个云主机分别来自vulrtr和阿里云(来源不重要,只要是云主机并且分布在不同的地区),练习用最低配的就够了。
云主机信息
| 名称 | 角色 | 主机提供方 | 操作系统 | IP | 端口 | 备注 |
| 主机1 | 来源节点 | vultr | ubuntu1604 | 45.32.250.47 | ||
| 主机2 | 目标节点 | aliyun | ubuntu1604 | 47.106.179.208 | 阿里云需要在安全策略组中单独开放5672端口 |
然后在各个主机安装好RabbitMQ,并且确认5672端口号可被外部访问到。
注意这里我们并没有同步两个机器的cookie token,是为了证明在使用shovel时不需要依赖于cookie token。
2.安装Shovel
Shovel是RabbitMQ的一个插件,在已经安装好RabbitMQ的基础上,把相关的插件启用即可。
我们只需要在主机1,也就是来源节点启用shovel插件即可。
执行如下命令启用Shovel插件
rabbitmq-plugins enable rabbitmq_shovel
看到如下输出即表明启用成功
The following plugins have been enabled:
amqp_client
rabbitmq_shovel
Applying plugin configuration to rabbit@vultr... started 2 plugins.
3.配置和运行Shovel
shovel分成两种
静态shovel:在配置文件中定了源节点和目标节点信息,修改配置后需要重启
动态shovel:通过运行时参数指定,可在运行时创建或删除
这里我使用静态shovel,在配置里定义shovel配置。
首先要找到RabbitMQ使用的配置,默认情况下是没有创建的,我们可以通过启动日志查看目前是否有指定的配置文件。
通常log文件在/var/log/rabbitmq下的rabbit@{hostname}.log文件中,打开文件发现
config file(s) : /etc/rabbitmq/rabbitmq.config (not found)
说明配置文件没有创建。
重新创建一个rabbitmq.config文件太麻烦了,我们从基于官方提供的example配置文件来修改会简单一些。
打开目录/usr/share/doc/rabbitmq-server/
cd /usr/share/doc/rabbitmq-server/
然后找到rabbitmq.config.example.gz,解压后复制到/etc/rabbitmq目录下
gzip -dk rabbitmq.config.example.gz
mv rabbitmq.config.example /etc/rabbitmq/rabbitmq.config
这时候的rabbitmq.config文件里所有配置都是注释的,这里我们现在只关注shovel部分的配置。
a.准备配置信息
在主机1和主机2上分别创建一个RabbitMQ用户,用户名是shovel_user,密码是123456,并设置授权
sudo rabbitmqctl add_user shovel_user 123456
sudo rabbitmqctl set_user_tags shovel_user administrator
sudo rabbitmqctl set_permissions -p / shovel_user ".*" ".*" ".*"
b.配置shovel
在主机1上打开rabbitmq.config文件,修改shovel部分的配置为如下内容
{rabbitmq_shovel,
[{shovels,
[%% A named shovel worker.
{my_test_shovel,
[
% List the source broker(s) from which to consume.
{sources,
[%% URI(s) and pre-declarations for all source broker(s).
{brokers, ["amqp://shovel_user:123456@45.32.250.47:5672"]},
{declarations, [
{'exchange.declare',
[ {exchange, <<"shovel_exchange">>},
{type, <<"direct">>},
durable
]},
{'queue.declare',
[{queue, <<"shovel_outcome_queue">>},durable]},
{'queue.bind',
[ {exchange, <<"shovel_exchange">>},
{queue, <<"shovel_outcome_queue">>},
{routing_key, <<"shovel_key">>}
]}
]}
]},
% List the destination broker(s) to publish to.
{destinations,
[%% A singular version of the 'brokers' element.
{broker, "amqp://shovel_user:123456@47.106.179.208:5672"},
{declarations, [{'exchange.declare',
[ {exchange, <<"shovel_exchange">>},
{type, <<"direct">>},
durable
]},
{'queue.declare',
[{queue, <<"shovel_income_queue">>},durable]},
{'queue.bind',
[ {exchange, <<"shovel_exchange">>},
{queue, <<"shovel_income_queue">>},
{routing_key, <<"shovel_key">>}
]}]}
]},
% Name of the queue to shovel messages from.
{queue, <<"shovel_outcome_queue">>},
% Optional prefetch count.
{prefetch_count, 10},
% when to acknowledge messages:
% - no_ack: never (auto)
% - on_publish: after each message is republished
% - on_confirm: when the destination broker confirms receipt
{ack_mode, no_ack},
% Overwrite fields of the outbound basic.publish.
{publish_fields, [{exchange, <<"shovel_exchange">>},
{routing_key, <<"shovel_key">>}]},
% Static list of basic.properties to set on re-publication.
{publish_properties, [{delivery_mode, 2}]},
% The number of seconds to wait before attempting to
% reconnect in the event of a connection failure.
{reconnect_delay, 2.5}
]} %% End of my_first_shovel
]}
%% Rather than specifying some values per-shovel, you can specify
%% them for all shovels here.
%%
%% {defaults, [{prefetch_count, 0},
%% {ack_mode, on_confirm},
%% {publish_fields, []},
%% {publish_properties, [{delivery_mode, 2}]},
%% {reconnect_delay, 2.5}]}
]}
RabbitMQ的官网的shovel配置示例不可用,这里使用配置的是RabbitMQ在github提供的配置示例基础上修改的(https://github.com/rabbitmq/rabbitmq-server/blob/master/docs/rabbitmq.config.example),然后结合官网文档的说明自己摸索配置出来。
配置说明
简单介绍一下上述配置中的关键部分
shovels之后接着可定义多个shovel,这里只定义了一个shovel,名称是my_test_shovel。
sources:定义了消息的来源
brokers
需要给出来源服务的地址,通常格式为amqp://用户名:密码@主机名(IP):端口号/vhost名称。
之前定义的shovel_user这时候就可以用上了,配置中我们使用的是默认的vhost,所以没有设置vhost名称
amqp://shovel_user:123456@45.32.250.47:5672
declarations:
declarations里面的内容就是执行一些amqp的命令,这些命令跟使用API调用的过程类似,
比如声明队列,Exchange和绑定信息等。
destinations:定义了消息的去向,里面的内容跟sources类似,实际上就是定义接收的exchange和队列
queue:这里单独配置了一个queue,是表示从哪个队列读取消息,这里跟sources里声明的队列一致。
其他一些可选的配置就不详细介绍了,具体可以查看官网文档http://www.rabbitmq.com/configure.html。
我们这里的配置表示从主机1的shovel_outcome_queue队列获取消息,然后转发到主机2的shovel_income_queue队列,两边使用的exchange名称都是shovel_exchange,并且routing_key的值都是shovel_key。
完整的配置请参考
https://github.com/shenba2014/RabbitMQ/blob/master/shovel/rabbitmq.config。
c.验证配置
配置完成之后,重启主机1的RabbitMQ服务
service rabbitmq-server restart
然后在主机1查看shovel的状态
rabbitmqctl eval 'rabbit_shovel_status:status().'
可以看到类似如下输出信息,看到running字样表明shovel服务已正常运行
[{my_test_shovel,static,
{running,[{src_uri,<<"amqp://45.32.250.47:5672">>},
{dest_uri,<<"amqp://47.106.179.208:5672">>}]},
{{2018,5,13},{12,4,48}}}]
输出信息中列出了源节点和目标节点信息,最后一行是时间戳。
4.使用Shovel
接下来我们使用代码来测试Shovel是否可用,我们的代码跟连接普通的RabbitMQ服务类似,只是具体连接的服务器地址不同。
测试的代码包含consumer和producer两部分,consumer将连接主机2,producer将连接到主机1。
分别运行consumer和producer的代码,producer在运行之后会发送消息到队列shovel_outcome_queue,然后consumer会接收到消息。
具体consumer和producer的代码不贴出来,完整代码请参考
https://github.com/shenba2014/RabbitMQ/tree/master/shovel
我们来直接看看运行代码的效果
运行消费者的代码,参数依次是:主机IP,端口,RabbitMQ用户名和密码,这里的我们连接的是主机2(目标节点)。
运行
python shovel_consumer.py 47.106.179.208 5672 shovel_user 123456
输出
Ready for orders!
然后新开一个控制台运行生产者的代码,参数一样,但是生产者连接的是主机1(源节点)。
运行
python shovel_producer.py 45.32.250.47 5672 shovel_user 123456
输出
Sent order message.
然后在消费者的那个控制台应该会看到类似如下输出
Received order 92 for test type.
数字是随机生成的,所以最终会结果可能不同。
好了,到目前为止,整个演练就完成了,前面的准备工作较多,测试的代码很简单,主要是演示shovel的跨数据中心的消息传递功能。
结合实际的IP地址,exchange和queue,最后用一个图来说明使用shovel的消息流向。
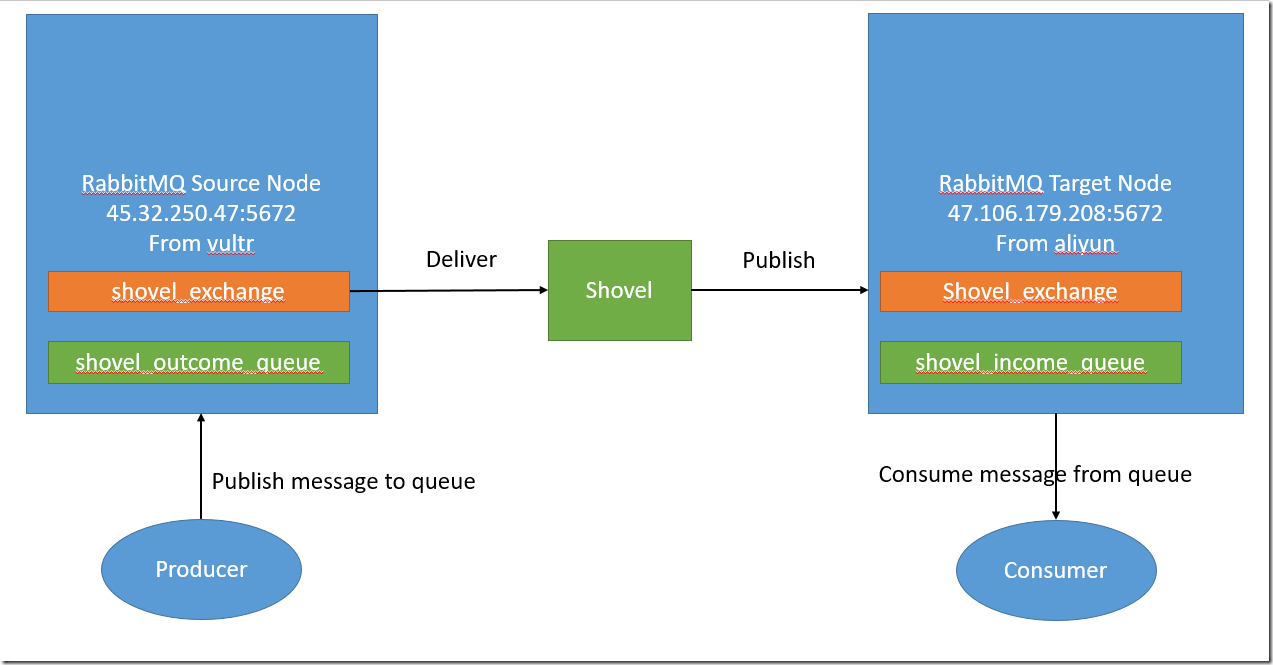
RabbitMQ上手记录–part 6-Shovel的更多相关文章
- RabbitMQ上手记录–part 5-节点集群高可用(多服务器)
上一part<RabbitMQ上手记录–part 4-节点集群(单机多节点)>中介绍了RabbitMQ集群的一些概念以及实现了在单机上运行多个节点,并且将多个节点组成一个集群. 通常情况下 ...
- RabbitMQ上手记录–part 3-发送消息
接上一part<<RabbitMQ上手记录–part 2 - 安装RabbitMQ>>,这里我们来看看如何通过代码实现对RabbitMQ的调用. RabbitMQ通常是安装在服 ...
- RabbitMQ上手记录–part 2 - 安装RabbitMQ
上一篇<<RabbitMQ 上手记录-part 1>>介绍了一些基础知识,整理了一些基础概念.接下来整理一些安装步骤和遇到的问题. 我在CentOS7和Ubuntu16.4上都 ...
- RabbitMQ上手记录–part 4-节点集群(单机多节点)
现在互联网应用动不动就说要HA,好像不搞个HA都不好意思说自己的应用能承载高并发,大用户量访问.RabbitMQ这个经典的消息组件,也必然逃不掉单点失效的尴尬局面.当然在RabbitMQ在被广泛应用于 ...
- RabbitMQ 上手记录-part 1-基础概念
RabbitMQ是什么,不用多介绍了,毕竟名声在那,江湖地位摆着,搜索引擎收录着.为什么突然去学习这个框架了,毕竟工作中没有用得上(说来也惭愧,工作中开发的项目没有使用这个框架).但是作为互联网分布式 ...
- celery+RabbitMQ 实战记录2—工程化使用
上篇文章中,已经介绍了celery和RabbitMQ的安装以及基本用法. 本文将从工程的角度介绍如何使用celery. 1.配置和启动RabbitMQ 请参考celery+RabbitMQ实战记录. ...
- RabbitMQ安装记录(windows10)
RabbitMQ安装记录(windows10) 一.安装包准备 otp_win64_R16B03.exe(这里使用该版本,不支持ssl) otp_win64_19.0.exe(如果要开启ssl,请 ...
- 【RabbitMQ学习记录】- 消息队列存储机制源码分析
本文来自 网易云社区 . RabbitMQ在金融系统,OpenStack内部组件通信和通信领域应用广泛,它部署简单,管理界面内容丰富使用十分方便.笔者最近在研究RabbitMQ部署运维和代码架构,本篇 ...
- RabbitMQ 问题记录
1. rabbitmq安装后无法运行,报错“unable to connect to node rabbit@XXXX: nodedown”. 怀疑局域网内有相同名称的计算机安装了rabbitmq,造 ...
随机推荐
- hsweb 企业后台管理基础框架
hsweb 详细介绍 业务功能 现在: 权限管理: 权限资源-角色-用户. 配置管理: kv结构,自定义配置.可通过此功能配置数据字典. 脚本管理: 动态脚本,支持javascript,groovy, ...
- SQL SERVER 2008 附加数据库出现只读问题。
问题描述 在附加数据库时出现的图片: 解决办法 步骤一,修改文件夹的 1.打开该数据库文件存放的目录或数据库文件的属性窗口,选择"属性"菜单->选择"安全&qu ...
- python 判断是否为中文
python在执行代码过程是不知道这个字符是什么意思的.是否是中文,而是把所有代码翻译成二进制也就是000111这种形式,机器可以看懂的语言. 也就是在计算机中所有的字符都是有数字来表示的.汉字也是有 ...
- Sql 辅助
1.清空数据表 SELECT 'TRUNCATE TABLE '+name AS TruncateSql FROM sys.tables
- Unity3d ugui 实现image代码换图
核心脚本代码 Image IMGE = transform.Find("IMGE").GetComponent<Image>();Sprite sprite1 = Re ...
- C#深入浅出获取时间DateTime
首先,先了解微软.net里面的DateTime的DateTime.Now.DateTime.Now.Date.DateTime.Now.Day.DateTime.Now.DayOfWeek.DateT ...
- C#之使用AutoUpdater自动更新客户端
安装NuGet包 在Visio studio中右击解决方案,选择管理NuGet包,搜索安装Autoupdater.NET.Official. 工作简介 从服务器下载包含更新文件的XML文件,从中获取软 ...
- 内核格式化(C++)
参考<C++ Primer Plus>P788 iostream族支持 程序 与 终端 之间的I/O fstream族支持 程序 与 文件 之间的I/O sstream族支持 程序 与 s ...
- hdu-5875
题目大意: f(l,r)=a[l] l==r f(l,r)=f(l,r-1)%a[r] l<r 思路: 由此可以推出f(l,r)=a[l]%a[l+1]%a[l+2]%....%a[r] ...
- RabbitMQ - Start Up
开始之前 rabbitmq是一个被广泛使用的消息队列,它是由erlang编写的,根据AMQP协议设计实现的. AMQP的主要特征是面向消息.队列.路由(包括点对点和发布/订阅).可靠性.安全. Rab ...