用 TensorFlow 实现 k-means 聚类代码解析
k-means 是聚类中比较简单的一种。用这个例子说一下感受一下 TensorFlow 的强大功能和语法。
一、 TensorFlow 的安装
按照官网上的步骤一步一步来即可,我使用的是 virtualenv 这种方式。
二、代码功能
在\([0,0]\) 到 \([1,1]\) 的单位正方形中,随机生成 \(N\) 个点,然后把这 \(N\) 个点聚为 \(K\) 类。
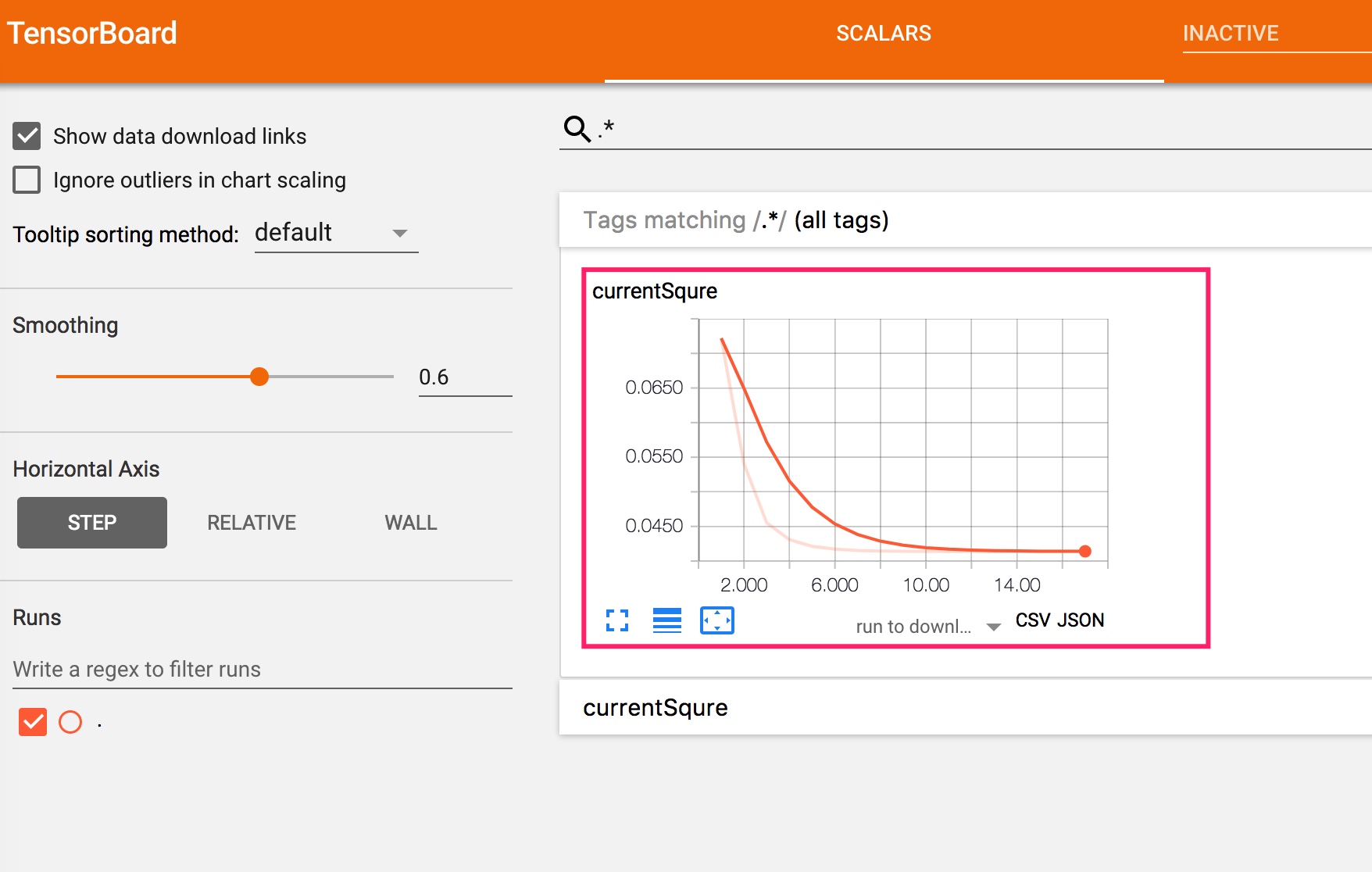
最终结果如下,在 0.29s 内,经过 17 次迭代,找到了4个类的中心,并给出了各个点归属的类。
Found in 0.29 seconds
iterations, 17
Centroids: [[ 0.24536976 0.73962539]
[ 0.25338876 0.23666154]
[ 0.75791192 0.25526255]
[ 0.7544601 0.75478882]]
Cluster assignments: [1 1 2 ..., 0 2 1]
而最小平方误差的变化如下。可以看出逐渐变小。

三、代码解析
引入相应的库
# copy from https://gist.github.com/dave-andersen/265e68a5e879b5540ebc
# add summary
import tensorflow as tf
import numpy as np
import time
定义问题规模以及一些变量
N=10000 # 要被聚类的点的数目
K=4 # 被聚为K类
MAX_ITERS = 1000 #最大迭代数目
test_writer = tf.summary.FileWriter("log") # TensorBorad 数据存储数目
start = time.time() # 起始时间
初始化
points = tf.Variable(tf.random_uniform([N,2])) #随机生成N个点
cluster_assignments = tf.Variable(tf.zeros([N], dtype=tf.int64)) #这个变量表示每个点所属的类别,初始化为第0类 # Silly initialization: Use the first K points as the starting
# centroids. In the real world, do this better.
centroids = tf.Variable(tf.slice(points.initialized_value(), [0,0], [K,2])) # 每个类的中心
下面用数学表达式来说明一下,这里下标不是从 0 开始。
\(N\) 个点points用下面式子来表达。
\[[[x_1,y_1],[x_2,y_2],...[x_n,y_n]]\]
每个点所属类别cluster_assignments用下面式子表达:
\[[\lambda_1,\lambda_2,...\lambda_n]\]
其中,\(\lambda_i<k\)
每个类的中心centroids用下面是式子表达:
\[[[c_1x,c_1y],[c_2x,c_2y],...[c_kx,c_ky]]\]计算每个点距离每个类中心的距离
# Replicate to N copies of each centroid and K copies of each
# point, then subtract and compute the sum of squared distances.
rep_centroids = tf.reshape(tf.tile(centroids, [N, 1]), [N, K, 2])
rep_points = tf.reshape(tf.tile(points, [1, K]), [N, K, 2])
sum_squares = tf.reduce_sum(tf.square(rep_points - rep_centroids),
reduction_indices=2)
先看
tf.tile函数。根据文档,tf.tile(centroids, [N, 1])函数执行完,结果如下:
\[[[c_1x,c_1y],[c_2x,c_2y],...[c_kx,c_ky],[c_1x,c_1y],[c_2x,c_2y],...[c_kx,c_ky],...[c_1x,c_1y],[c_2x,c_2y],...[c_kx,c_ky]]\]
即有 \(NK\)个点。然后经过tf.reshape函数,结果如下:
\[[[[c_1x,c_1y],[c_2x,c_2y],...[c_kx,c_ky]],\\
[[c_1x,c_1y],[c_2x,c_2y],...[c_kx,c_ky]],\\
...\\
[[c_1x,c_1y],[c_2x,c_2y],...[c_kx,c_ky]]]\]
即可以看做一个\(N \times K\)的矩阵,每一个元素是一个点。这就是rep_centroids的大致理解。
同理可得,rep_points结果如下:
\[[[[x_1,y_1],[x_1,y_1],...[x_1,y_1]],\\
[[x_2,y_2],[x_2,y_2],...[x_2,y_2]],\\
...\\
[[x_n,y_n],[x_n,y_n],...[x_n,y_n]]]\]
也可以看做一个\(N \times K\)的矩阵。每一行所有元素都相同,是第\(i\)个点。
tf.square(rep_points - rep_centroids)结果如下:
\[[[[[(x_1-c_1x)^2,(y_1-c_1y)^2],[(x_1-c_2x)^2,(y_1-c_2y)^2],...[(x_1-c_kx)^2,(y_1-c_ky)^2]],\\
[[(x_2-c_1x)^2,(y_2-c_1y)^2],[(x_2-c_2x)^2,(y_2-c_2y)^2],...[(x_2-c_kx)^2,(y_2-c_ky)^2]],\\
...\\
[[(x_n-c_1x)^2,(y_n-c_1y)^2],[(x_n-c_2x)^2,(y_n-c_2y)^2],...[(x_n-c_kx)^2,(y_n-c_ky)^2]]]\]
而sum_squares的结果,是把\(N \times K\)矩阵的每一个元素变为一个值,如下:
\[[[[d_{11},d_{12},...d_{1k}],\\
[d_{11},d_{22},...d_{2k}],\\
...\\
[d_{n1},d_{n2},...d_{nk}]]\]
其中
\[d_{ij} = (x_i-c_jx)^2+(y_i-c_jy)^2 \]
即 \(d_{ij}\) 是第 \(i\) 个点和第 \(k\) 个类的中心的距离。判断点所属的类
# Use argmin to select the lowest-distance point
best_centroids = tf.argmin(sum_squares, 1)
did_assignments_change = tf.reduce_any(tf.not_equal(best_centroids,
cluster_assignments))
best_centroids是一行中,最小的数值的下标,即某个点应该被判定为哪一类。
did_assignments_change表示新判定的类别和上次迭代的类别有没有变化。更新类别的中心
def bucket_mean(data, bucket_ids, num_buckets):
total = tf.unsorted_segment_sum(data, bucket_ids, num_buckets)
count = tf.unsorted_segment_sum(tf.ones_like(data), bucket_ids, num_buckets)
return total / count # 新的分簇点
means = bucket_mean(points, best_centroids, K)
currentSqure = tf.reduce_sum(tf.reduce_min(sum_squares,1))/N
tf.summary.scalar('currentSqure', currentSqure)
merged = tf.summary.merge_all()
先看
bucket_mean函数。data被传入了被聚类的\(N\)个点,bucket_ids被传入了每个点所属的类别,num_buckets是类别的数目。
tf.unsorted_segment_sum可以理解为根据第二个参数(bucket_ids),把data分为不同的集合,然后分别对每一个集合求和。
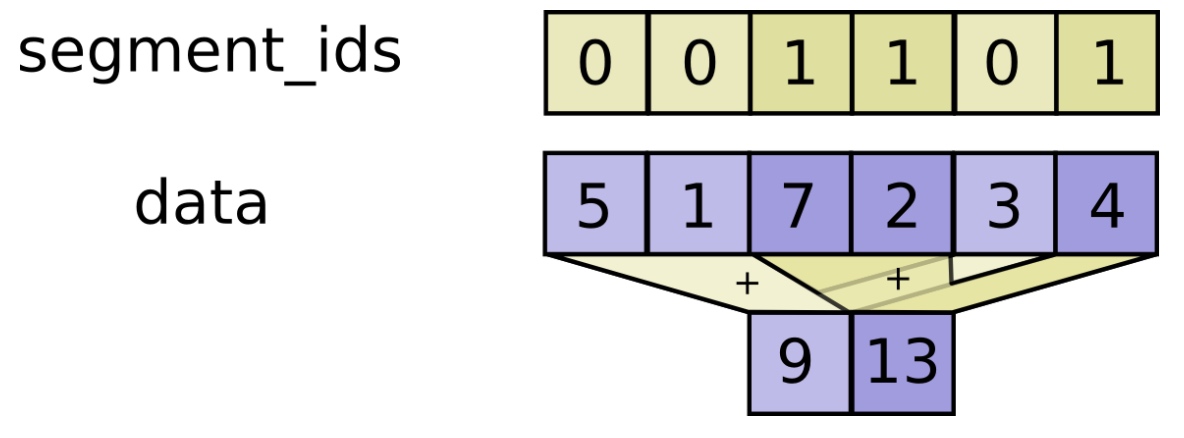 

因此total即把\(N\)个点分为\(K\)个集合,然后对每一个集合求和。count则是求出每一个集合的个数。相除即得到每一个集合(即每一个类)的中心。
means即新划分的各个类的中心。
currentSqure是当前划分的最小平方误差。然后把变量计入日志中。指定迭代结构
# Do not write to the assigned clusters variable until after
# computing whether the assignments have changed - hence with_dependencies
with tf.control_dependencies([did_assignments_change]):
do_updates = tf.group(
centroids.assign(means),
cluster_assignments.assign(best_centroids))
如果
did_assignments_change有变化,那么把means赋值给centroids,把best_centroids赋值给cluster_assignments。启动 session
init = tf.initialize_all_variables()
sess = tf.Session()
sess.run(init) changed = True
iters = 0
进行迭代
while changed and iters < MAX_ITERS:
iters += 1
[summary,changed, _] = sess.run([merged,did_assignments_change, do_updates])
test_writer.add_summary(summary,iters) #写入日志 test_writer.close()
[centers, assignments] = sess.run([centroids, cluster_assignments])
end = time.time()
print ("Found in %.2f seconds" %(end-start))
print( "iterations,",iters )
print("Centroids: " ,centers)
print( "Cluster assignments:",assignments)
print("cluster_assignments",cluster_assignments)
指定最多迭代次数。值得注意的是,每一次迭代,都要把数据显式写入log中。
四、感受
- 机器学习的计算量太大了,并行性也很明显。
- 对结果要有评估,否则意义不大。
这个例子中,随机生成的数据,根据算也可以进行聚类。但是意义显然不大。 - 有一个图形化的界面很重要。TensorBoard 可以直观看出平方误差在不断变化
五、参考
用 TensorFlow 实现 k-means 聚类代码解析的更多相关文章
- k均值聚类算法原理和(TensorFlow)实现
顾名思义,k均值聚类是一种对数据进行聚类的技术,即将数据分割成指定数量的几个类,揭示数据的内在性质及规律. 我们知道,在机器学习中,有三种不同的学习模式:监督学习.无监督学习和强化学习: 监督学习,也 ...
- Tensorflow版Faster RCNN源码解析(TFFRCNN) (2)推断(测试)过程不使用RPN时代码运行流程
本blog为github上CharlesShang/TFFRCNN版源码解析系列代码笔记第二篇 推断(测试)过程不使用RPN时代码运行流程 作者:Jiang Wu 原文见:https://hom ...
- Tensorflow版Faster RCNN源码解析(TFFRCNN) (3)推断(测试)过程使用RPN时代码运行流程
本blog为github上CharlesShang/TFFRCNN版源码解析系列代码笔记第三篇 推断(测试)过程不使用RPN时代码运行流程 作者:Jiang Wu 原文见:https://hom ...
- 机器学习算法与Python实践之(五)k均值聚类(k-means)
机器学习算法与Python实践这个系列主要是参考<机器学习实战>这本书.因为自己想学习Python,然后也想对一些机器学习算法加深下了解,所以就想通过Python来实现几个比较常用的机器学 ...
- ML: 聚类算法-K均值聚类
基于划分方法聚类算法R包: K-均值聚类(K-means) stats::kmeans().fpc::kmeansruns() K-中心点聚类(K-Medoids) ...
- GraphSAGE 代码解析(四) - models.py
原创文章-转载请注明出处哦.其他部分内容参见以下链接- GraphSAGE 代码解析(一) - unsupervised_train.py GraphSAGE 代码解析(二) - layers.py ...
- GraphSAGE 代码解析(三) - aggregators.py
原创文章-转载请注明出处哦.其他部分内容参见以下链接- GraphSAGE 代码解析(一) - unsupervised_train.py GraphSAGE 代码解析(二) - layers.py ...
- 5-Spark高级数据分析-第五章 基于K均值聚类的网络流量异常检测
据我们所知,有‘已知的已知’,有些事,我们知道我们知道:我们也知道,有 ‘已知的未知’,也就是说,有些事,我们现在知道我们不知道.但是,同样存在‘不知的不知’——有些事,我们不知道我们不知道. 上一章 ...
- 机器学习实战5:k-means聚类:二分k均值聚类+地理位置聚簇实例
k-均值聚类是非监督学习的一种,输入必须指定聚簇中心个数k.k均值是基于相似度的聚类,为没有标签的一簇实例分为一类. 一 经典的k-均值聚类 思路: 1 随机创建k个质心(k必须指定,二维的很容易确定 ...
随机推荐
- 1、GDB程序调试
GDB是GNU开源组织发布的一个强大的Linux下的程序调试工具.一般来说GDB主要完成下面四个部分的功能. 1)启动你的程序,可以按照你的自定义的要求运行程序. 2)可让被调试程序在你所指定的调试的 ...
- VS快捷键以及Reshaper快捷键
VS快捷键: Resharper 快捷键(此图是保存他人的[具体是谁忘记了]): 参考: http://msdn.microsoft.com/zh-cn/library/da5kh0wa.aspx
- 命名空间namespace ,以及重复定义的问题解析
名字空间是用来划分冲突域的,把全局名字空间划分成几个小的名字空间.全局函数,全局变量,以及类的名字是在同一个全局名字空间中,有时为了防止命名冲突,会把这些名字放到不同的名字空间中去. 首先我们看一下名 ...
- Spring Boot的自动配置的原理浅析
一.原理描述 Spring Boot在进行SpringApplication对象实例化时会加载META-INF/spring.factories文件,将该配置文件中的配置载入到Spring容器. 二. ...
- 如何更改myecelipse、eclipse的Project Explorer的背景颜色
这个是我研究了很久发现的,因为myecelipse.eclipse本身是随着系统的颜色改变而改变的,windows系统都会随着系统改变而改变的,所以找了很多资料都没能改变它的背景色,今天发现了一个不错 ...
- changetoutf-8
import chardet import os # ANSI文件转UTF-8 import codecs import os def strJudgeCode(str): return charde ...
- UltraEdit配置
1.如何在vivado中调用UltraEdit 1.语法高亮 支持不同的编程语言,但是要添加相就的文件,这样不同语言的关键字就可以高亮显示. 在高级-> 配置 –> 语法高亮,选择文档 2 ...
- jbpm(流程管理)
1.jbpm是什么 JBPM,全称是Java Business Process Management(业务流程管理),它是覆盖了业务流程管理.工作流.服务协作等领域的一个开源的.灵活的.易扩展的可执行 ...
- hdu 2845 Beans 2016-09-12 17:17 23人阅读 评论(0) 收藏
Beans Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total Subm ...
- 章文嵩博士和他背后的负载均衡(LOAD BANLANCER)帝国
案首语: 阿里集团技术大牛,@正明,淘宝基础核心软件研发负责人.LVS创始人.阿里云首席科学家章文嵩博士从阿里离职,去追求技术人生另一段历程,让阿里像我一样的很多热爱技术的工程师都有一丝牵动和感触. ...