多流向算法GPU并行化
和导师在Computers & Geosciences上发表的关于多流向算法GPU并行化的文章(SCI, IF=1.834)。
论文:http://sourcedb.igsnrr.cas.cn/zw/lw/201207/P020120717506311161951.pdf
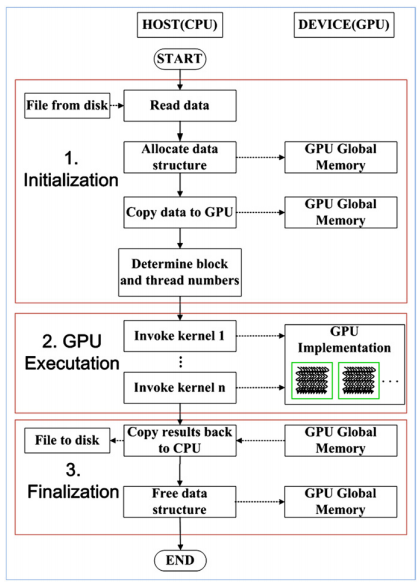
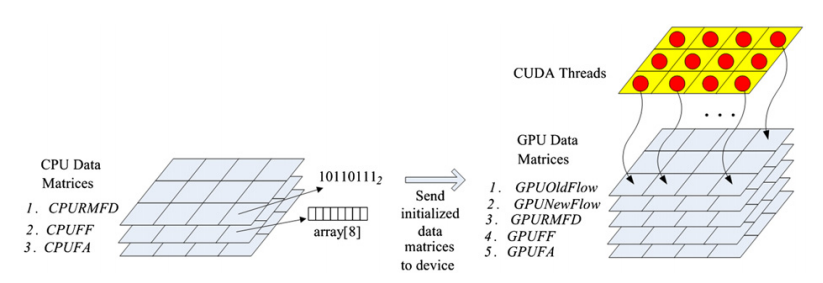
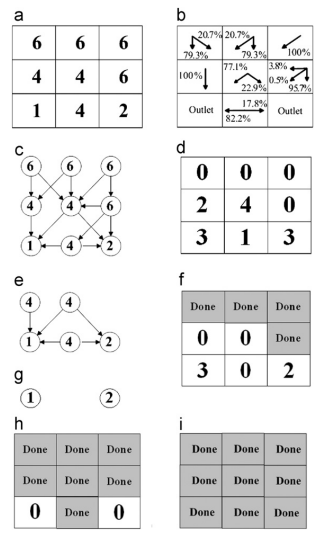
As one of the important tasks in digital terrain analysis, the calculation of flow accumulations from gridded digital elevation models (DEMs) usually involves two steps in a real application: (1) using an iterative DEM preprocessing algorithm to remove the depressions and flat areas commonly contained in real DEMs, and (2) using a recursive flow-direction algorithm to calculate the flow accumulation for every cell in the DEM. Because both algorithms are computationally intensive, quick calculation of the flow accumulations from a DEM (especially for a large area) presents a practical challenge to personal computer (PC) users. In recent years, rapid increases in hardware capacity of the graphics processing units (GPUs) provided in modern PCs have made it possible to meet this challenge in a PC environment. Parallel computing on GPUs using a compute-unified-device-architecture (CUDA) programming model has been explored to speed up the execution of the single-flow-direction algorithm (SFD). However, the parallel implementation on a GPU of the multiple-flow-direction (MFD) algorithm, which generally performs better than the SFD algorithm, has not been reported. Moreover, GPU-based parallelization of the DEM preprocessing step in the flow-accumulation calculations has not been addressed. This paper proposes a parallel approach to calculate flow accumulations (including both iterative DEM preproces- sing and a recursive MFD algorithm) on a CUDA-compatible GPU. For the parallelization of an MFD algorithm (MFD-md), two different parallelization strategies using a GPU are explored. The first parallelization strategy, which has been used in the existing parallel SFD algorithm on GPU, has the problem of computing redundancy. Therefore, we designed a parallelization strategy based on graph theory. The application results show that the proposed parallel approach to calculate flow accumula- tions on a GPU performs much faster than either sequential algorithms or other parallel GPU-based algorithms based on existing parallelization strategies.
多流向算法GPU并行化的更多相关文章
- 分布式机器学习:PageRank算法的并行化实现(PySpark)
1. PageRank的两种串行迭代求解算法 我们在博客<数值分析:幂迭代和PageRank算法(Numpy实现)>算法中提到过用幂法求解PageRank. 给定有向图 我们可以写出其马尔 ...
- GPU:并行计算利器
http://blog.jobbole.com/87849/ 首页 最新文章 IT 职场 前端 后端 移动端 数据库 运维 其他技术 - 导航条 - 首页 最新文章 IT 职场 前端 - Ja ...
- 基于GPU的算法并行化
GPU计算的目的即是计算加速.相比于CPU,其具有以下三个方面的优势: l 并行度高:GPU的Core数远远多于CPU(如G100 GPU有240个Cores),从而GPU的任务并发度也远高于CPU ...
- 基于spark实现并行化Apriori算法
详细代码我已上传到github:click me 一. 实验要求 在 Spark2.3 平台上实现 Apriori 频繁项集挖掘的并行化算法.要求程序利用 Spark 进行并行计算. ...
- 玩深度学习选哪块英伟达 GPU?有性价比排名还不够!
本文來源地址:https://www.leiphone.com/news/201705/uo3MgYrFxgdyTRGR.html 与“传统” AI 算法相比,深度学习(DL)的计算性能要求,可以说完 ...
- 【并行计算-CUDA开发】浅谈GPU并行计算新趋势
随着GPU的可编程性不断增强,GPU的应用能力已经远远超出了图形渲染任务,利用GPU完成通用计算的研究逐渐活跃起来,将GPU用于图形渲染以外领域的计算成为GPGPU(General Purpose c ...
- mahout中kmeans算法和Canopy算法实现原理
本文讲一下mahout中kmeans算法和Canopy算法实现原理. 一. Kmeans是一个很经典的聚类算法,我想大家都非常熟悉.虽然算法较为简单,在实际应用中却可以有不错的效果:其算法原理也决定了 ...
- 标签传播算法(Label Propagation)及Python实现
众所周知,机器学习可以大体分为三大类:监督学习.非监督学习和半监督学习.监督学习可以认为是我们有非常多的labeled标注数据来train一个模型,期待这个模型能学习到数据的分布,以期对未来没有见到的 ...
- Weka算法Classifier-meta-AdaBoostM1源代码分析(一)
多分类器组合算法简单的来讲经常使用的有voting,bagging和boosting,当中就效果来说Boosting略占优势,而AdaBoostM1算法又相当于Boosting算法的"经典款 ...
随机推荐
- Java实现WordCount
GitHub项目地址:https://github.com/happyOwen/SoftwareEngineering wordcount项目要求: 程序处理用户需求的模式为:wc.exe [para ...
- spring集成struts2
Struts2前身是WebWork,核心并没有改变,其实就是把WebWork改名为struts2,与Struts1一点关系没有. Struts2中通过ObjectFactory接口实现创建及获取Act ...
- Delphi Language Overview
Delphi is a high-level, compiled, strongly typed language that supports structured and object-orient ...
- Android-ByteUtil工具类
Byte处理转换相关的工具类: public class ByteUtil { private ByteUtil(){} /** * 把byte[] 转成 Stirng * @param bytes ...
- 使用Java web工程建立Maven Web Module工程
1. 前言 之前有一篇关于搭建S2SH的文章中提到建立Maven Web Module工程,有人反馈说这个方面不会.那还是唠叨一下,写篇文章说明一下吧. 建立Maven Web Module的方式有多 ...
- Mono For Android 之 配置环境
下载 Xamarin Mono For Android 4.6.07004 完整离线破解版 (包括除 Android SDK 外的所有文件) Android SDK. 资源源自 http://www. ...
- ActiveMq 总结(二)
4.2.6 MessageConsumer MessageConsumer是一个由Session创建的对象,用来从Destination接收消息. 4.2.6.1 创建MessageConsumer ...
- Linux - 修改文件编码
enca -L zh_CN -x UTF- file
- 在kolla中配置cinder ceph多后端
原文链接:在kolla中配置cinder ceph多后端
- HTML+Javascript制作拼图小游戏详解(终)
上次我们已经讲解了制作的原理,并且展示了主要代码. 这次我将完整的代码给大家,仅供参考. HTML部分如下: <!DOCTYPE html> <html lang="en& ...