10 ORM 多表操作 查询
1、子查询:基于对象的跨表查询
def query(request):
"""
跨表查询:
1.基于对象查询
2.基于双下划线查询
3.聚合、分组查询
4. F Q 查询
""" # ----基于对象的跨表查询(子查询)
# 1.一对多查询 """
# 一对多查询
正向查询:按字段
反向查询:表名小写_set.all() book_obj.publish
Book(关联属性:publish)对象 --------------> Publish对象
<--------------
publish_obj.book_set.all() # queryset """
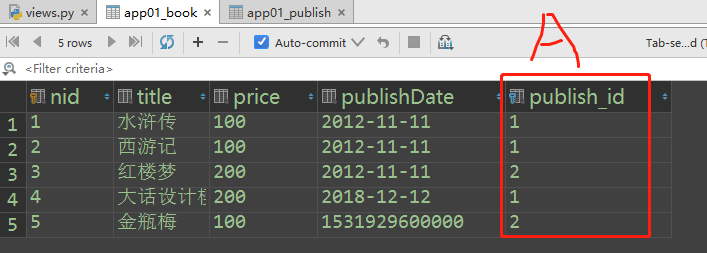
# 正向查询:查询瓶梅这本书的出版社的名字
book_obj = Book.objects.filter(title='瓶梅').first()
publish_obj = book_obj.publish # 与这本书关联的出版社对象
publish_name = publish_obj.name
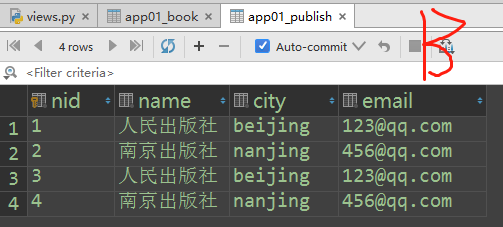
print(publish_name) # 南京出版社 # 反向查询:查询人民出版社出版的书籍名称
publish_obj = Publish.objects.filter(name='人民出版社').first()
books_obj = publish_obj.book_set.all()
print(books_obj) # <QuerySet [<Book: 水浒传>, <Book: 西游记>, <Book: 大话设计模式>]>
# print(books_obj.title) #error 'QuerySet' object has no attribute 'title' # 2.多对多
"""
# 多对多查询
正向查询:按字段
反向查询:表名小写_set.all() book_obj.authors.all()
Book(关联属性:authors)对象 ------------------------> Author对象
<------------------------
author_obj.book_set.all() # queryset """
# 正向查询:查询金2瓶梅这本书的所有作者
book_obj1 = Book.objects.filter(title='金2瓶梅').first()
book_obj2 = Book.objects.filter(title='金2瓶梅')
print('.first()',book_obj1, type(book_obj1))
print('无first()',book_obj2,type(book_obj2)) authors_list = book_obj.authors.all()
print(authors_list) # QuerySet对象 <QuerySet [<Author: alex>, <Author: jack>]> for author in authors_list:
print(author.name) # 反向查询:查询alex出版过的所有书籍名称
author_obj = Author.objects.filter(name='alex').first()
books_list = author_obj.book_set.all()
print(books_list)
for book in books_list:
print(book.title) # 3. 一对一
"""
# 一对一查询 正向查询:按字段
反向查询:表名小写 author.authordetail
Author(关联属性:authordetail)对象 ------------------------>AuthorDetail对象
<------------------------
authordetail.author """
# 正向查询:查询alex的手机号
author_obj = Author.objects.filter(name='alex').first()
phone = author_obj.authordetail.telephone # 与author关联的authordetail对象
print(phone) # 反向查询:查询手机号为110的作者的名字和年龄
ad_obj = AuthorDetail.objects.filter(telephone="").first()
name = ad_obj.author.name # 关联的对象author
age = ad_obj.author.age
print(name, age) return HttpResponse("查询成功")
Views代码
1.简介
核心:book.authors.all()
关键点
一、book_obj.publish = Publish.objects.filter(id=book_obj.publish_id).first()
二、book_obj.authors.all()
关键点: book.authors.all() # 与这本书关联的作者集合
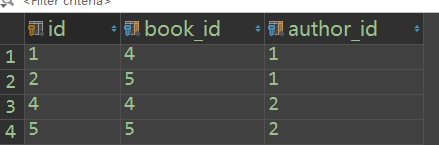
1 book.id=3
2 book_authors
id book_id author_id
3 3 1
4 3 2
3. author
id name
1 alex
2 jack
book_obj.authors.all() -----> [alex,jack]
正向查询 反向查询
A-B
关联属性在A表中 正向查询: A------>B
反向查询: B------>A
2、一对多
语法
# 一对多查询
正向查询:按字段
反向查询:表名小写_set.all() book_obj.publish
Book(关联属性:publish)对象 --------------> Publish对象
<--------------
publish_obj.book_set.all() # queryset
查询
# 正向查询:查询梅瓶jin这本书的出版社的名字
book_obj = Book.objects.filter(title='梅瓶jin').first()
publish_obj = book_obj.publish # 与这本书关联的出版社对象
publish_name = publish_obj.name
print(publish_name) # 南京出版社
# 反向查询:查询人民出版社出版的书籍名称
publish_obj = Publish.objects.filter(name='人民出版社').first()
books_obj = publish_obj.book_set.all()
print(books_obj) # <QuerySet [<Book: 水浒传>, <Book: 西游记>, <Book: 大话设计模式>]>
# print(books_obj.title) #error 'QuerySet' object has no attribute 'title'

3、多对多
规则
# 多对多查询
正向查询:按字段
反向查询:表名小写_set.all() book_obj.authors.all()
Book(关联属性:authors)对象 ------------------------> Author对象
<------------------------
author_obj.book_set.all() # queryset

# 正向查询:查询梅瓶jin这本书的所有作者
book_obj = Book.objects.filter(title='梅瓶jin').first()
authors_list = book_obj.authors.all()
print(authors_list) # QuerySet对象 <QuerySet [<Author: alex>, <Author: jack>]> for author in authors_list:
print(author.name)

# 反向查询:查询alex出版过的所有书籍名称
author_obj = Author.objects.filter(name='alex').first()
books_list = author_obj.book_set.all()
print(books_list)
for book in books_list:
print(book.title)

4、一对一
# 一对一查询
正向查询:按字段
反向查询:表名小写
author.authordetail
Author(关联属性:authordetail)对象 ------------------------>AuthorDetail对象
<------------------------
authordetail.author
查询
# 正向查询:查询alex的手机号
author_obj = Author.objects.filter(name='alex').first()
phone = author_obj.authordetail.telephone # 与author关联的authordetail对象
print(phone)
# 反向查询:查询手机号为110的作者的名字和年龄
ad_obj = AuthorDetail.objects.filter(telephone="").first()
name = ad_obj.author.name # 关联的对象author
age = ad_obj.author.age
print(name, age)
5、基于对象跨表查询的sql语句:setting中log日志
setting中添加logging日志
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}

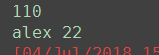
110
(0.001) SELECT "app01_author"."nid", "app01_author"."name", "app01_author"."age", "app01_author"."authordetail_id" FROM "app01_author" WHERE "app01_author"."name" = 'alex' ORDER BY "app01_author"."nid" ASC LIMIT 1; args=('alex',)
(0.000) SELECT "app01_authordetail"."nid", "app01_authordetail"."birthday", "app01_authordetail"."telephone", "app01_authordetail"."addr" FROM "app01_authordetail" WHERE "app01_authordetail"."nid" = 1; args=(1,)
(0.001) SELECT "app01_authordetail"."nid", "app01_authordetail"."birthday", "app01_authordetail"."telephone", "app01_authordetail"."addr" FROM "app01_authordetail" WHERE "app01_authordetail"."telephone" = 110 ORDER BY "app01_authordetail"."nid" ASC LIMIT 1; args=(110,)
alex 22
(0.001) SELECT "app01_author"."nid", "app01_author"."name", "app01_author"."age", "app01_author"."authordetail_id" FROM "app01_author" WHERE "app01_author"."authordetail_id" = 1; args=(1,)
[04/Jul/2018 16:03:47] "GET /app01/query/ HTTP/1.1" 200 12
6.first()区别
# 查询梅瓶jin这本书的所有作者
book_obj1 = Book.objects.filter(title='梅瓶jin').first()
book_obj2 = Book.objects.filter(title='梅瓶jin')
print('.first()',book_obj1, type(book_obj1))
print('无first()',book_obj2,type(book_obj2))
.first() 梅瓶jin <class 'app01.models.Book'>
无first() <QuerySet [<Book: 梅瓶jin>, <Book: 梅瓶jin>]> <class 'django.db.models.query.QuerySet'>
2、join查询:基于双下划线的跨表查询

def joinquery(request):
# ----基于双下划线的跨表查询(join查询)
"""
正向查询按字段, 告诉ORM引擎join哪张表
反向查询按表名小写, 告诉ORM引擎join哪张表
"""
# 1.一对多查询: # 查询金2瓶梅这本书的出版社的名字
# 正向查询:
ret = Book.objects.filter(title='金2瓶梅').values('publish__name')
print(ret) # <QuerySet [{'publish__name': '南京出版社'}]>
# 反向查询:
ret = Publish.objects.filter(book__title='金2瓶梅').values('name')
print(ret) # <QuerySet [{'authors__name': 'alex'}, {'authors__name': 'jack'},
# 2.多对多 查询金2瓶梅这本书的所有作者的名字
# 正向查询:
# 需求:通过Book表join与其关联的Author表,属于正向查询:按字段authors通知ORM引擎join book_author与author表
ret = Book.objects.filter(title='金2瓶梅').values('authors__name')
print(ret)
# 反向查询
# 需求:通过Author表join与其关联的Book表,属于反向查询:按表名小写book通知ORM引擎join book_authors与book表
ret = Author.objects.filter(book__title='金2瓶梅').values('name')
print(ret) # <QuerySet [{'name': 'alex'}, {'name': 'jack'}]>
# 3. 一对一 # 查询alex的手机号
# 正向查询:
# 需求:通过Author表join与其相关联的AuthorDetail表,属于正向查询:按字段authordetail通知ORM join AuthorDetail表
ret = Author.objects.filter(name='alex').values('authordetail__telephone')
print(ret)
# 反向查询:
# 需求:通过AuthorDetail表join与其相关联的Author表,属于反向查询:按表名小写author通知ORM join Author表
ret = AuthorDetail.objects.filter(author__name='alex').values('telephone')
print(ret)
return HttpResponse('join查询成功')
views代码
1、一对多
# 1.一对多查询: # 查询梅ping金这本书的出版社的名字
# 正向查询:
ret = Book.objects.filter(title='梅ping金').values('publish__name')
print(ret) # <QuerySet [{'publish__name': '南京出版社'}]> # 反向查询:
ret = Publish.objects.filter(book__title='梅ping金').values('name')
print(ret) # <QuerySet [{'authors__name': 'alex'}, {'authors__name': 'jack'},
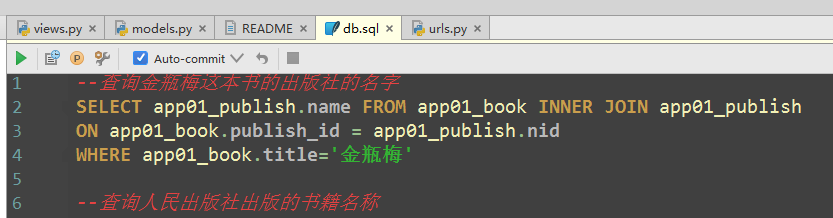
(1)pycharm的sql查询
#查询梅ping金这本书的出版社的名字 SELECT app01_publish.name FROM app01_book INNER JOIN app01_publish
ON app01_book.publish_id = app01_publish.nid
WHERE app01_book.title='梅ping金'

(2)正向查询:正向查询按字段
Book表的publish关联字段,__双下划线 关联到Publish表,__name 取出Publish表的name字段

(0.002) SELECT "app01_publish"."name" FROM "app01_book"
INNER JOIN "app01_publish"
ON ("app01_book"."publish_id" = "app01_publish"."nid")
WHERE "app01_book"."title" = '梅ping金'
LIMIT ; args=('梅ping金',)

(3)反向查询:反向查询按表名小写
Publish关联表名小写book表, __title取出book表的title字段, .values 取出Publish表的值

(0.001) SELECT "app01_publish"."name" FROM "app01_publish" INNER JOIN "app01_book"
ON ("app01_publish"."nid" = "app01_book"."publish_id")
WHERE "app01_book"."title" = '梅ping金' LIMIT ; args=('梅ping金',)
2、多对多
# 2.多对多 查询梅ping金这本书的所有作者的名字
# 正向查询:
# 需求:通过Book表join与其关联的Author表,属于正向查询:按字段authors通知ORM引擎join book_author与author表
ret = Book.objects.filter(title='梅ping金').values('authors__name')
print(ret) # 反向查询
# 需求:通过Author表join与其关联的Book表,属于反向查询:按表名小写book通知ORM引擎join book_authors与book表
ret = Author.objects.filter(book__title='梅ping金').values('name')
print(ret) # <QuerySet [{'name': 'alex'}, {'name': 'jack'}]>
sql语句
# 查询梅ping金这本书的所有作者的名字(join)
SELECT app01_author.name FROM app01_book INNER JOIN app01_book_authors
ON app01_book.nid = app01_book_authors.book_id
INNER JOIN app01_author
ON app01_book_authors.author_id = app01_author.nid

(1)正向查询


(2)反向查询
SELECT "app01_author"."name" FROM "app01_book"
LEFT OUTER JOIN "app01_book_authors"
ON ("app01_book"."nid" = "app01_book_authors"."book_id")
LEFT OUTER JOIN "app01_author"
ON ("app01_book_authors"."author_id" = "app01_author"."nid") WHERE "app01_book"."title" = '梅ping金' LIMIT 21; args=('梅ping金',)
推荐方式:正向查询短句
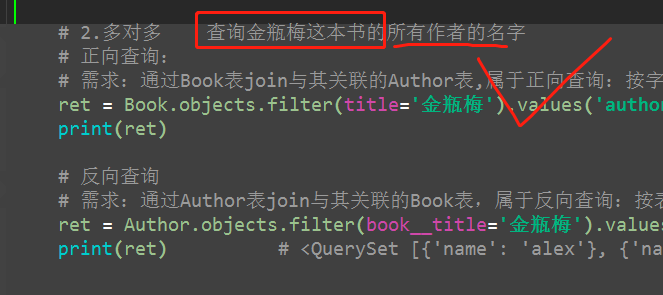
3、一对一
# 3. 一对一 # 查询alex的手机号
# 正向查询:
# 需求:通过Author表join与其相关联的AuthorDetail表,属于正向查询:按字段authordetail通知ORM join AuthorDetail表
ret = Author.objects.filter(name='alex').values('authordetail__telephone')
print(ret) # 反向查询:
# 需求:通过AuthorDetail表join与其相关联的Author表,属于反向查询:按表名小写author通知ORM join Author表
ret = AuthorDetail.objects.filter(author__name='alex').values('telephone')
print(ret)
(1)正向查询
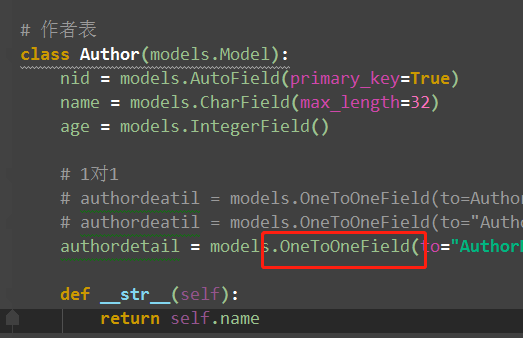

(2)反向查询

4、连续跨表:基于双下划线的
telephone__startswith='110' # 以什么开头的
values('book__title', 'book__publish__name') #5张表join,它的任何字段都可以取出来

# 方式1:
# 手机号以110开头的作者
author_name = Author.objects.filter(authordetail__telephone__startswith='').values('name')
print(author_name) # <QuerySet [{'name': 'alex'}]>
# alex出版过的所有书籍名称
book_name = author_name.values('book__title')
print(book_name)
# 书籍名称对应的书籍出版社名称
publish = author_name.values('book__publish__name')
print(publish) # 合并错误
# list = Author.objects.filter(authordetail__telephone__startswith='110').values('name').values('book__title').values('book__publish__name')
# print(list) # <QuerySet [{'book__publish__name': '人民出版社'}, {'book__publish__name': '南京出版社'}]> list = Author.objects.filter(authordetail__telephone__startswith='').values('book__title', 'book__publish__name')
print(list) # <QuerySet [{'book__title': '大话设计模式', 'book__publish__name': '人民出版社'}, {'book__title': '梅ping金', 'book__publish__name': '南京出版社'}]>

# 方式2:
# 手机号以110开头的作者出版过的所有书籍
books = Book.objects.filter(authors__authordetail__telephone__startswith='').values('title')
print(books) # <QuerySet [{'title': '大话设计模式'}, {'title': '梅ping金'}]>
# 书籍出版社名称
publishs = books.values('publish__name')
print(publishs) # <QuerySet [{'publish__name': '人民出版社'}, {'publish__name': '南京出版社'}]> list = Book.objects.filter(authors__authordetail__telephone__startswith='').values('title','publish__name')
print(list) # <QuerySet [{'title': '大话设计模式', 'publish__name': '人民出版社'}, {'title': '梅ping金', 'publish__name': '南京出版社'}]>
3、聚合查询
# --> 聚合 aggregate:返回值是一个字典,不再是queryset # 查询所有书籍的平均价格
from django.db.models import Avg, Max, Min, Count
#ret = Book.objects.all().aggregate(Avg('price')) # {'price__avg': 150.0}
ret = Book.objects.all().aggregate(avg_price=Avg('price')) # {'avg_price': 150.0}
print(ret) ret = Book.objects.all().aggregate(avg_price=Avg('price'), max_price=Max('price'), min_price=Min('price'))
print(ret) # {'avg_price': 150.0, 'max_price': Decimal('200.00'), 'min_price': Decimal('100.00')}

SELECT AVG("app01_book"."price") AS "price__avg"
FROM "app01_book";
4、分组查询
# -------- 分组查询 annotate, 返回值依旧是个queryset
(1)单表分组查询
思考
"""
单表的分组查询: 查询每一个部门名称以及对应的员工数 emp: id name age salary dep
1 alex 12 2000 销售部
2 egon 22 3000 人事部
3 wen 22 5000 人事部 sql : select Count(id) from emp group by dep; 思考:如何用ORM语法进行分组查询?
语法
# 单表分组查询的ORM语法: 单表模型.objects.values("group by的字段").annotate(聚合函数("统计字段"))
# 在单表分组下,按着主键进行group by是没有任何意义的.
练习
# 单表分组查询:
# 1.查询每一个部门的名称以及员工的平均薪水
# select avg(salary) from emp group by dep ret = Emp.objects.values('dep').annotate(Avg('salary'))
print(ret) # <QuerySet [{'dep': '保安部', 'salary__avg': 20000.0}, {'dep': '教学部', 'salary__avg': 12500.0}]> # 2.查询每一个省份的名称以及员工数
ret = Emp.objects.values('province').annotate(count=Count('id'))
print(ret) # <QuerySet [{'province': '山东省', 'count': 2}, {'province': '河北省', 'count': 1}]> # 3.补充知识点
ret = Emp.objects.all()
print(ret) # select * from emp
ret = Emp.objects.values('name')
print(ret) # select name from emp

(2)跨表分组查询
思考
跨表的分组查询:
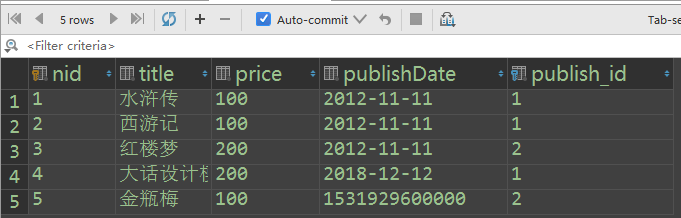
Book表
id title date price publish_id
红楼梦 --
西游记 --
三国演绎 --
金2瓶梅 --
Publish表
id name addr email
人民出版社 北京 @qq.com
南京出版社 南京 @.com
分组查询sql:
select publish.name,Count("title") from Book inner join Publish on book.publish_id=publish.id
group by publish.id,publish.name,publish.addr,publish.email
思考:如何用ORM语法进行跨表分组查询
语法
5 总结:
# 总结 跨表的分组查询的模型:
# 每一个后的表模型.objects.values("pk").annotate(聚合函数(关联表__统计字段)).values("表模型的所有字段以及统计字段") # 推荐pk字段查找
# 每一个后的表模型.objects.annotate(聚合函数(关联表__统计字段)).values("表模型的所有字段以及统计字段")
"""

跨表查询方式1
# 示例1:查询每个出版社的名称以及出版的书籍的个数
ret = Publish.objects.values('nid').annotate(count=Count('book__title'))
print(ret) # <QuerySet [{'nid': 1, 'count': 3}, {'nid': 2, 'count': 3}, {'nid': 3, 'count': 0}, {'nid': 4, 'count': 0}]> ret = Publish.objects.values('name').annotate(count=Count('book__title'))
print(ret) # <QuerySet [{'name': '人民出版社', 'count': 3}, {'name': '南京出版社', 'count': 3}]> # 推荐主键pk查找
Publish.objects.values('pk').annotate(c=Count('book__title')).values('name', 'c')
print(ret) # <QuerySet [{'name': '人民出版社', 'count': 3}, {'name': '南京出版社', 'count': 3}]> # 示例2:查询每一个作者的名字以及出版过的书籍的最高价格
ret = Author.objects.values('pk').annotate(max_price=Max('book__price')).values('name', 'max_price')
print(ret) # <QuerySet [{'name': 'alex', 'max_price': Decimal('200.00')}, {'name': 'jack', 'max_price': Decimal('200.00')}]> # 示例3: 查询每一个书籍的名称以及对应的作者个数
ret = Book.objects.values('pk').annotate(c=Count('authors__nid')).values('title','c')
print(ret) # <QuerySet [{'title': '水浒传', 'c': 0}, {'title': '西游记', 'c': 0}, {'title': '红楼梦', 'c': 0}, {'title': '大话设计模式', 'c': 2}, {'title': '金2瓶梅', 'c': 2}, {'title': '金2瓶梅', 'c': 0}]>



分组查询 group by所有的字段,没有意义

跨表查询方式2
# ---------跨表分组查询的另一种玩法 ------------
# 示例1:查询每个出版社的名称以及出版的书籍的个数
ret = Publish.objects.all().annotate(c=Count('book__title')).values('name','c')
print(ret) # <QuerySet [{'name': '人民出版社', 'c': 3}, {'name': '南京出版社', 'c': 3}, {'name': '人民出版社', 'c': 0}, {'name': '南京出版社', 'c': 0}]> # value为什么可以取出来?取出来的是对象
ret = Publish.objects.values('nid').annotate(c=Count('book__title'))
print(ret) # <QuerySet [{'nid': 1, 'c': 3}, {'nid': 2, 'c': 3}, {'nid': 3, 'c': 0}, {'nid': 4, 'c': 0}]> # values可以取出Publish表的每个字段 + 聚合字段
ret = Publish.objects.values('nid').annotate(c=Count('book__title')).values()
print(ret) # <QuerySet [{'nid': 1, 'name': '人民出版社', 'city': 'beijing', 'email': '123@qq.com', 'c': 3}, {'nid': 2, 'name': '南京出版社', 'city': 'nanjing', 'email': '456@qq.com', 'c': 3}, ]>


练习
# ########## 练习#############
# 每一个后的表模型.objects.values("pk").annotate(聚合函数(关联表__统计字段)).values("表模型的所有字段以及统计字段") # 推荐pk字段查找 # 统计每一本以py开头的书籍的作者个数:
#ret = Book.objects.values('pk').annotate(c=Count('authors__nid')).filter(title__startswith='py').values('c')
ret = Book.objects.filter(title__startswith='金').values('pk').annotate(c=Count('authors__nid')).values('title','c')
print(ret) # <QuerySet [{'name': 'alex', 'book__title': '大话设计模式'}, {'name': 'alex', 'book__title': '金2瓶梅'}, {'name': 'jack', 'book__title': '大话设计模式'}, {'name': 'jack', 'book__title': '金2瓶梅'}]> # 统计不止一个作者的图书
ret = Author.objects.values('pk').annotate(Count('book__nid')).values('name','book__title')
print(ret) # <QuerySet [{'book__title': '大话设计模式'}, {'book__title': '金2瓶梅'}, {'book__title': '大话设计模式'}, {'book__title': '金2瓶梅'}]> ret = Book.objects.values('pk').annotate(c=Count('authors__name')).filter(c__gt=1).values('title','c')
print(ret) # <QuerySet [{'title': '大话设计模式', 'c': 2}, {'title': '金2瓶梅', 'c': 2}]>

5、F查询 Q查询
(1)添加字段的时候要指定默认值



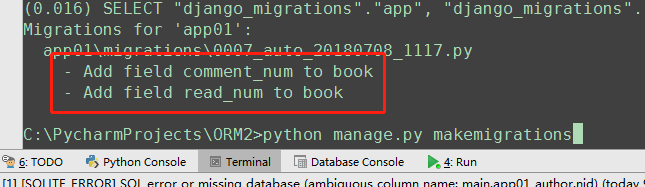
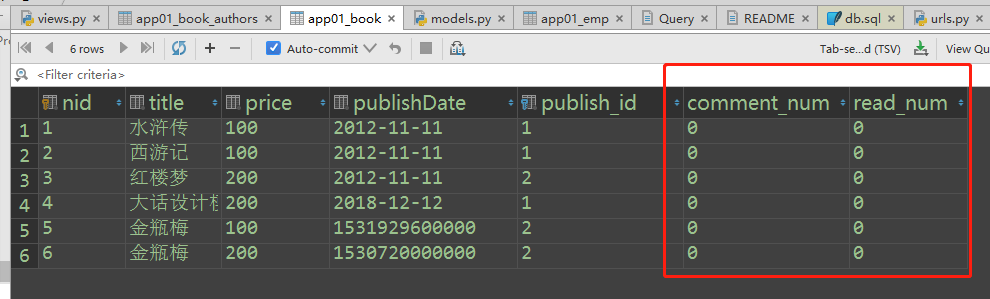
添加数据
(2)F查询:大于,+1
#### F查询与Q查询
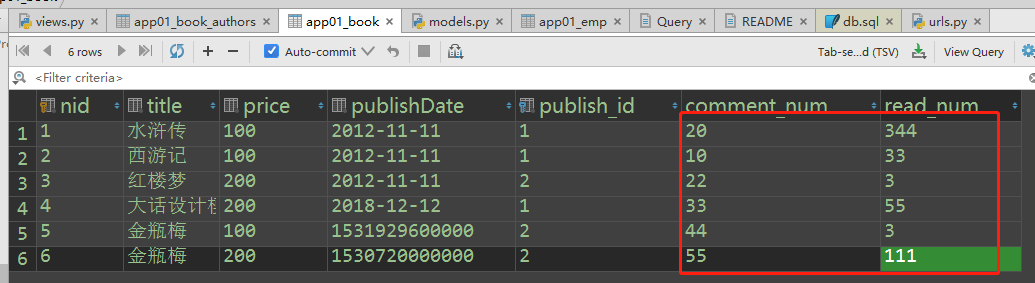
#示例1: 评论数大于阅读数的书籍
# Book.objects.filter(comment_num__gt=read_num)
from django.db.models import F
ret = Book.objects.filter(comment_num__gt=F('read_num'))
print(ret)
# 示例2:所有书籍的价格+1
# Book.objects.all().update(price+=1)
# Book.objects.all().update(price=price+1)
Book.objects.all().update(price=F('price')+1)

(3)Q查询 与或非
# 与或非
from django.db.models import Q # 与
ret1 = Book.objects.filter(title='水浒传', price=106)
print(ret1) # <QuerySet [<Book: 水浒传>]>
ret2 = Book.objects.filter(Q(title='水浒传') & Q(price=106))
print(ret2) # <QuerySet [<Book: 水浒传>]> # 或
ret = Book.objects.filter(Q(title='红楼梦') | Q(price=106))
print(ret) # <QuerySet [<Book: 水浒传>, <Book: 西游记>, <Book: 红楼梦>, <Book: 金2瓶梅>]> # 非
ret = Book.objects.filter(~Q(price=106))
print(ret) # <QuerySet [<Book: 红楼梦>, <Book: 大话设计模式>, <Book: 金2瓶梅>]> # Book.objects.filter(comment_num__gt=100, ~(Q(title='红楼梦') | Q(price=106))) # Q查询需要放到最后面
Book.objects.filter(~(Q(title='红楼梦')|Q(price=106)),comment_num__gt=100)

10 ORM 多表操作 查询的更多相关文章
- ORM 多表操作查询及增删改查
------------------------------------------只有对前途乐观的人,才能不怕黑暗,才能有力量去创造光明.乐观不是目的,而是人生旅途中的一种态度. 多表操作 创建模型 ...
- day53:django:URL别名/反向解析&URL分发&命名空间&ORM多表操作修改/查询
目录 1.URL别名&反向解析 2.URL分发&命名空间 3.ORM多表操作-修改 4.ORM多表操作-查询 4.1 基于对象的跨表查询 4.2 基于双下划线的跨表查询 4.3 聚合查 ...
- day59——orm单表操作
day59 orm单表操作 对象关系映射(object relational mapping) orm语句 -- sql -- 调用pymysql客户端发送sql -- mysql服务端接收到指令并执 ...
- 17-2 orm单表操作和多表操作
参考:https://www.cnblogs.com/liwenzhou/p/8660826.html 一 ORM单表操作 1 增删改查 1. 查询 1. 查所有 models.Publisher. ...
- Django框架05 /orm单表操作
Django框架05 /orm单表操作 目录 Django框架05 /orm单表操作 1. orm使用流程 2. orm字段 3. orm参数 4. orm单表简单增/删/改 5. orm单表查询 5 ...
- Django ORM 多表操作
目录 Django ORM 多表操作 表模型 表关系 创建模型 逆向到表模型 插入数据 ORM 添加数据(添加外键) 一对多(外键 ForeignKey) 一对一 (OneToOneFeild) 多对 ...
- Atitit. 注册表操作查询 修改 api与工具总结 java c# php js python 病毒木马的原理
Atitit. 注册表操作查询 修改 api与工具总结 java c# php js python 病毒木马的原理 1. reg 工具 这个cli工具接口有,优先使用,jreg的要调用dll了,麻烦的 ...
- django框架基础-ORM单表操作-长期维护
############### 单表操作-添加数据 ################ import os if __name__ == '__main__': os.environ.set ...
- Django框架06 /orm多表操作
Django框架06 /orm多表操作 目录 Django框架06 /orm多表操作 1. admin相关操作 2. 创建模型 3. 增加 4. 删除 5. 修改 6. 基于对象的跨表查询 7. 基于 ...
随机推荐
- SQL 中Count()的问题
假如一张表中有如下的数据: 当使用select Count(*) from TableName表示获取表中数据记录的条数: 有时候可以通过select Count(列名) from TableName ...
- Linux 系统的IP与域名解析文件[局域网的DNS]
系统的IP与域名解析文件[局域网的DNS] 局域网的DNS: 域名和主机名对应的工具,服务器直接通过域名,方便迁移 # 修改配置 vim /etc/hosts 直接添加: 192.138.25.129 ...
- 解决由于显卡驱动BUG导致桌面右键卡顿的问题:bat文件源码
@ ECHO OFF%1 mshta vbscript:CreateObject("Shell.Application").ShellExecute("cmd.exe&q ...
- 五十个小技巧提高PHP执行效率
在项目开发过程中,经常遇到了一些PHP处理程序性能底下的情况,程序运行在centos+nginx环境,虽然这个有很多的原因如:服务器本身配置,运行环境nginx服务,php-fpm配置等等,更多有一点 ...
- js和java判断值为空的方式
js方式判断值为空: name == ""; java方式判断值为空: name==null || name.trim().isEmpty();注:name==null要在前面,不 ...
- TFS使用笔记——合并不同分支的代码
问题描述:我们需要把2.37中改动的代码合并到2.38当中. 查看“Pending Changes”,单击“Change”列排序,查看merge的items,然后选中merge的items,最后“Ch ...
- vs环境变量学习
1. 查看vs环境变量: 在项目设置中的任何路径.目录编辑项目下,右下角有个“宏”,点开即可见所有vs环境变量的当前设置...听说还有其它地方,没看到. 2.上边的“宏”,即是英文的vs环境变量 3. ...
- 一篇文章搞懂DOM
学习JavaScript肯定是会遇到DOM操作,那么什么是DOM?它又是干嘛用的?这篇文章为你揭晓答案. DOM是document object model的缩写,简称文档对象模型. 简单的说DOM是 ...
- BZOJ 2424 订货 最小费用流
题目链接: https://www.lydsy.com/JudgeOnline/problem.php?id=2424 题目大意: 某公司估计市场在第i个月对某产品的需求量为Ui,已知在第i月该产品的 ...
- Spark系列-初体验(数据准备篇)
Spark系列-初体验(数据准备篇) Spark系列-核心概念 在Spark体验开始前需要准备环境和数据,环境的准备可以自己按照Spark官方文档安装.笔者选择使用CDH集群安装,可以参考笔者之前的文 ...