Hadoop学习之路(二)Hadoop发展背景
Hadoop产生的背景
1. HADOOP最早起源于Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
2. 2003年开始谷歌陆续发表的三篇论文为该问题提供了可行的解决方案。
——分布式文件系统(GFS),可用于处理海量网页的存储
——分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题。
——BigTable 数据库:OLTP 联机事务处理 Online Transaction Processing 增删改
OLAP 联机分析处理 Online Analysis Processing 查询
真正的作用:提供了一种可以在超大数据集中进行实时CRUD操作的功能
3.Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目,迎来了它的快速发展期。
Hadoop是啥
Hadoop的官网:http://hadoop.apache.org/
1、Hadoop是Apache旗下的一套开源软件平台
2、Hadoop提供的功能:利用服务器集群,根据户自定义业逻辑对海量数进行分布式处理
3、Hadoop的核心组件:
1)Hadoop Common:支持其他Hadoop模块的常用工具。
2) Hadoop分布式文件系统(HDFS™):一种分布式文件系统,可提供对应用程序数据的高吞吐量访问。
3) Hadoop YARN:作业调度和集群资源管理的框架。
4) Hadoop MapReduce:一种用于并行处理大型数据集的基于YARN的系统。
大数据的处理主要就是存储和计算。
如果说安装hadoop集群,其实就是安装了两个东西: 一个操作系统YARN 和 一个文件系统HDFS。其实MapReduce就是运行在YARN之上的应用。
操作系统 文件系统 应用程序
win7 NTFS QQ,WeChat
YARN HDFS MapReduce
4、hadoop的概念:
狭义上: 就是apache的一个顶级项目:apahce hadoop
广义上: 就是指以hadoop为核心的整个大数据处理体系
5、Apache的其他Hadoop相关项目包括:
- Ambari™:一种用于供应,管理和监控Apache Hadoop集群的基于Web的工具,其中包括对Hadoop HDFS,Hadoop MapReduce,Hive,HCatalog,HBase,ZooKeeper,Oozie,Pig和Sqoop的支持。Ambari还提供了一个用于查看群集运行状况的仪表板,例如热图和可以直观地查看MapReduce,Pig和Hive应用程序的功能,以及以用户友好的方式诊断其性能特征的功能。
- Avro™:数据序列化系统。
- Cassandra™:无单点故障的可扩展多主数据库。
- Chukwa™:管理大型分布式系统的数据收集系统。
- HBase™:可扩展的分布式数据库,支持大型表格的结构化数据存储。
- Hive™:提供数据汇总和即席查询的数据仓库基础架构。
- Mahout™:可扩展的机器学习和数据挖掘库。
- Pig™:用于并行计算的高级数据流语言和执行框架。
- Spark™:用于Hadoop数据的快速和通用计算引擎。Spark提供了一个简单而富有表现力的编程模型,它支持广泛的应用程序,包括ETL,机器学习,流处理和图计算。
- Tez™:一种基于Hadoop YARN的通用数据流编程框架,它提供了一个强大且灵活的引擎,可执行任意DAG任务来处理批处理和交互式用例的数据。Hado™,Pig™和Hadoop生态系统中的其他框架以及其他商业软件(例如ETL工具)正在采用Tez来替代Hadoop™MapReduce作为底层执行引擎。
- ZooKeeper™:分布式应用程序的高性能协调服务。
HADOOP在大数据、云计算中的位置和关系
1、云计算是分布式计算、并行计算、网格计算、多核计算、网络存储、虚拟化、负载均衡等传统计算机技术和互联网技术融合发展的产物。借助IaaS(基础设施即服务)、PaaS(平台即服务)、SaaS(软件即服务)等业务模式,把强大的计算能力提供给终端用户。1、
2、现阶段,云计算的两大底层支撑技术为“虚拟化”和“大数据技术”
3、 而HADOOP则是云计算的PaaS层的解决方案之一,并不等同于PaaS,更不等同于云计算本身。
Hadoop的技术应用
HADOOP应用于数据服务基础平台建设
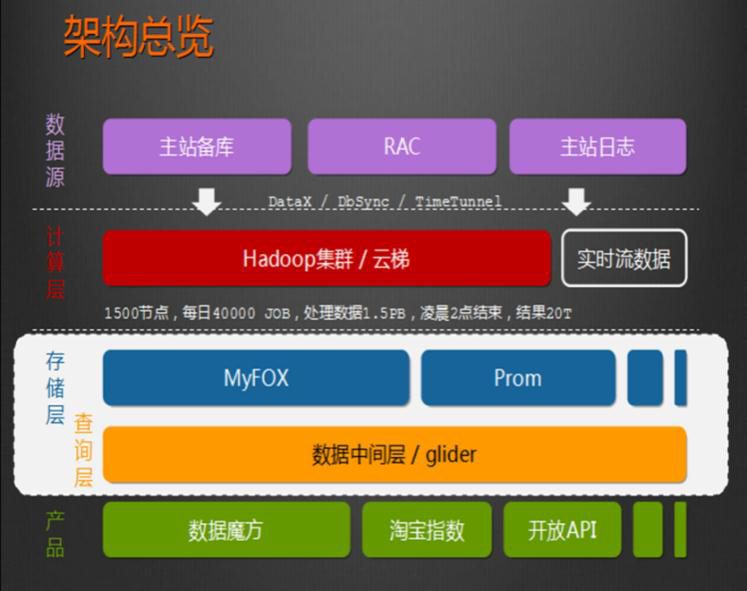
HADOOP用于用户画像
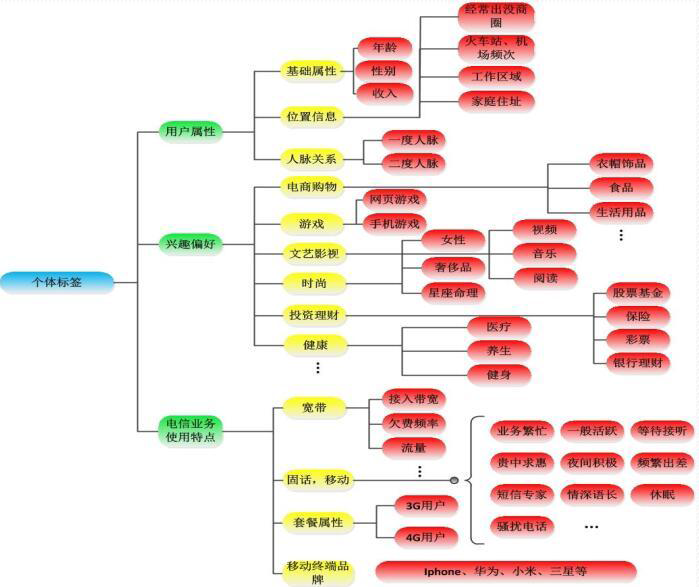
该图是中国电信的用户画像标签体系。
HADOOP用于网站点击流日志数据挖掘
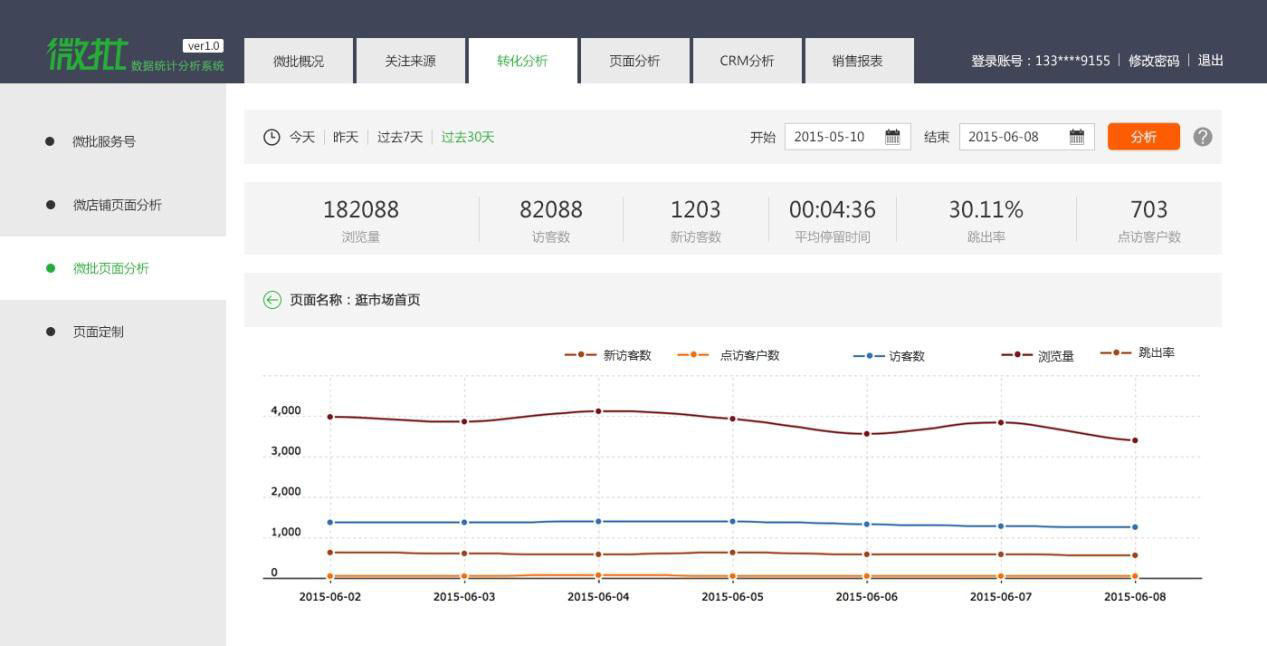
总结:hadoop并不会跟某个具体的行业或者某个具体的业务挂钩,它只是一种用来做海量数据分析处理的工具。
HADOOP生态圈以及各组成部分的简介
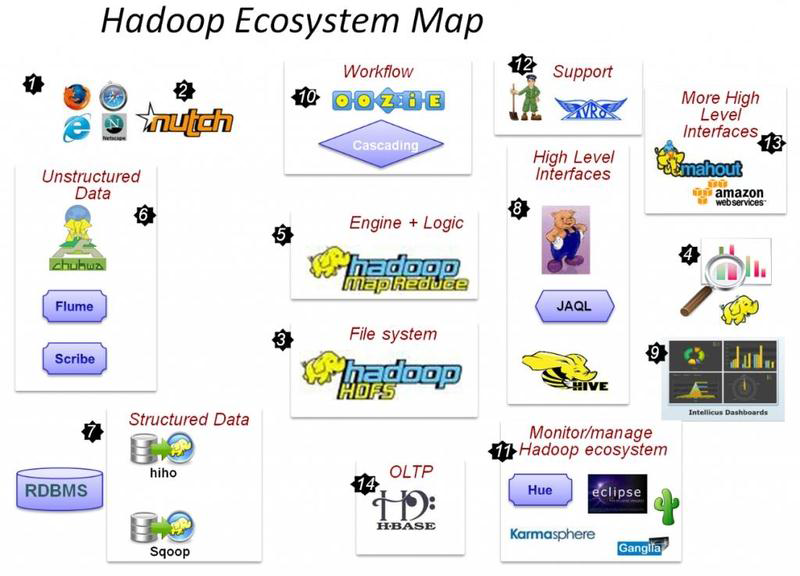
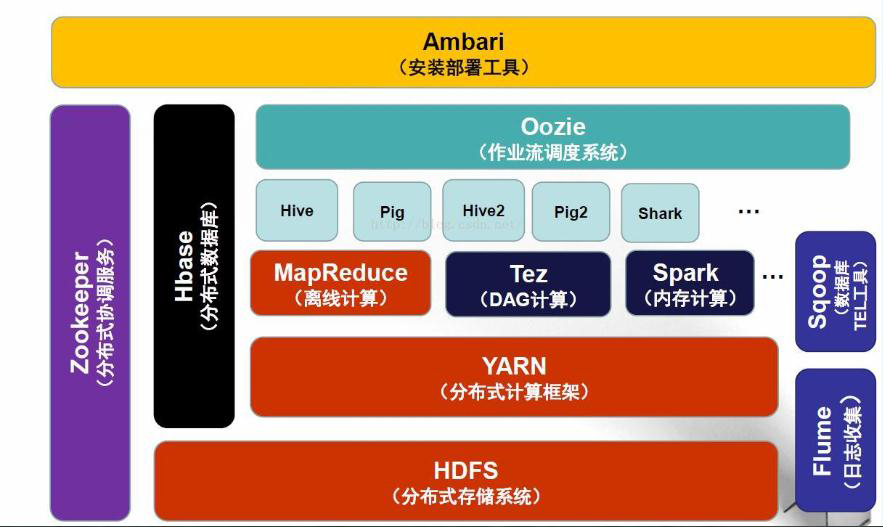
重点组件:
HDFS:Hadoop的分布式文件存储系统。
MapReduce:Hadoop的分布式程序运算框架,也可以叫做一种编程模型。
Hive:基于Hadoop的类SQL数据仓库工具
Hbase:基于Hadoop的列式分布式NoSQL数据库
ZooKeeper:分布式协调服务组件
Mahout:基于MapReduce/Flink/Spark等分布式运算框架的机器学习算法库
Oozie/Azkaban:工作流调度引擎
Sqoop:数据迁入迁出工具
Flume:日志采集工具
获取数据的三种方式
1、自己公司收集的数据--日志 或者 数据库中的数据
2、有一些数据可以通过爬虫从网络中进行爬取
3、从第三方机构购买
国内HADOOP的就业情况分析
1、HADOOP就业整体情况
A. 大数据产业已纳入国家十三五规划
B. 各大城市都在进行智慧城市项目建设,而智慧城市的根基就是大数据综合平台
C. 互联网时代数据的种类,增长都呈现爆发式增长,各行业对数据的价值日益重视
D. 相对于传统JAVAEE技术领域来说,大数据领域的人才相对稀缺
E. 随着现代社会的发展,数据处理和数据挖掘的重要性只会增不会减,因此,大数据技术是一个尚在蓬勃发展且具有长远前景的领域
2、 HADOOP就业职位要求
大数据是个复合专业,包括应用开发、软件平台、算法、数据挖掘等,因此,大数据技术领域的就业选择是多样的,但就HADOOP而言,通常都需要具备以下技能或知识:
硬实力
A. HADOOP分布式集群的平台搭建
B. HADOOP分布式文件系统HDFS的原理理解及使用
C. HADOOP分布式运算框架MAPREDUCE的原理理解及编程
D. Hive数据仓库工具的熟练应用
E. Flume、sqoop、oozie等辅助工具的熟练使用
F. Shell/python等脚本语言的开发能力
软实力
A. 解决问题的能力(调试,阅读文档)
B. 沟通协调能力(寻求帮助)
C. 学习提升自己的能力(自我提高)
D. 组织管控能力(管理能力)
Hadoop学习之路(二)Hadoop发展背景的更多相关文章
- 阿里封神谈hadoop学习之路
阿里封神谈hadoop学习之路 封神 2016-04-14 16:03:51 浏览3283 评论3 发表于: 阿里云E-MapReduce >> 开源大数据周刊 hadoop 学生 s ...
- 《Hadoop学习之路》学习实践
(实践机器:blog-bench) 本文用作博文<Hadoop学习之路>实践过程中遇到的问题记录. 本文所学习的博文为博主“扎心了,老铁” 博文记录.参考链接https://www.cnb ...
- Hadoop学习总结之五:Hadoop的运行痕迹
Hadoop学习总结之五:Hadoop的运行痕迹 Hadoop 学习总结之一:HDFS简介 Hadoop学习总结之二:HDFS读写过程解析 Hadoop学习总结之三:Map-Reduce入门 Ha ...
- Hadoop 学习之路(二)—— 集群资源管理器 YARN
一.hadoop yarn 简介 Apache YARN (Yet Another Resource Negotiator) 是hadoop 2.0 引入的集群资源管理系统.用户可以将各种服务框架部署 ...
- Hadoop学习之路(二)HDFS基础
1.HDFS前言 HDFS:Hadoop Distributed File System,Hadoop分布式文件系统,主要用来解决海量数据的存储问题. 设计思想 分散均匀存储 dfs.blocksiz ...
- 小强的Hadoop学习之路
本人一直在做NET开发,接触这行有6年了吧.毕业也快四年了(6年是因为大学就开始在一家小公司做门户网站,哈哈哈),之前一直秉承着学要精,就一直一门心思的在做NET(也是懒吧).最近的工作一直都和大数据 ...
- Hadoop学习之旅二:HDFS
本文基于Hadoop1.X 概述 分布式文件系统主要用来解决如下几个问题: 读写大文件 加速运算 对于某些体积巨大的文件,比如其大小超过了计算机文件系统所能存放的最大限制或者是其大小甚至超过了计算机整 ...
- 我的hadoop学习之路
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS.HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上. Ha ...
- hadoop学习笔记(二):centos7三节点安装hadoop2.7.0
环境win7+vamvare10+centos7 一.新建三台centos7 64位的虚拟机 master node1 node2 二.关闭三台虚拟机的防火墙,在每台虚拟机里面执行: systemct ...
随机推荐
- SpringMVC 面试题
SpringMVC 面试题 什么是Spring MVC ?简单介绍下你对springMVC的理解? Spring MVC是一个基于MVC架构的用来简化web应用程序开发的应用开发框架,它是Spring ...
- 【转】Apache服务器的下载与安装
PHP的运行必然少不了服务器的支持,何为服务器?通俗讲就是在一台计算机上,安装个服务器软件,这台计算机便可以称之为服务器,服务器软件和计算机本身的操作系统是两码事,计算机自身的操作系统可以为linux ...
- java并发编程的艺术(二)---重排序与volatile、final关键字
本文来源于翁舒航的博客,点击即可跳转原文观看!!!(被转载或者拷贝走的内容可能缺失图片.视频等原文的内容) 若网站将链接屏蔽,可直接拷贝原文链接到地址栏跳转观看,原文链接:https://www.cn ...
- YII中利用urlManager将URL改写成restful风格
这里主要涉及url显示样式 1.打开config文件夹下面的mian.php 2.修改内容 如把地址http://www.test.com/index.php?r=site/page/sid/ ...
- BZOJ4144: [AMPPZ2014]Petrol(最短路 最小生成树)
题意 题目链接 Sol 做的时候忘记写题解了 可以参考这位大爷 #include<bits/stdc++.h> #define Pair pair<int, int> #def ...
- CentOS /lib/ld-linux.so.2: bad ELF interpreter: No such file or directory
使用的时候出现一个错误 bash: /usr/local/bin/rar: /lib/ld-linux.so.2: bad ELF interpreter: No such file or direc ...
- Atitit.resin could not create the java virtual machine问题
Atitit.resin could not create the java virtual machine问题 1. 正常的参数是这样1 2. 错误的cmd运行时候的参数1 3. 输出2 4. 原 ...
- 如何从本地添加项目到Github?(Windows)
有两种方法可以上传项目到Github 一.github在线上传文件夹 在线上传也可以上传完整的文件夹结构,直接拖拽到上传文件页面的框中即可. 点击上传文件 直接拖拽即可上传文件夹及文件夹里面的文件.如 ...
- overload与override的区别
override(重写,覆盖) 1.方法名.参数.返回值相同. 2.子类方法不能缩小父类方法的访问权限. 3.子类方法不能抛出比父类方法更多的异常(但子类方法可以不抛出异常). 4.存在于父类和子类之 ...
- JSON学习笔记-3
JSON 对象 1.对象语法 JSON 对象使用在大括号({})中书写. 对象可以包含多个 key/value(键/值)对. key 必须是字符串,value 可以是合法的 JSON 数据类型(字符串 ...