Hadoop学习之路(十四)MapReduce的核心运行机制
概述
一个完整的 MapReduce 程序在分布式运行时有两类实例进程:
1、MRAppMaster:负责整个程序的过程调度及状态协调
2、Yarnchild:负责 map 阶段的整个数据处理流程
3、Yarnchild:负责 reduce 阶段的整个数据处理流程 以上两个阶段 MapTask 和 ReduceTask 的进程都是 YarnChild,并不是说这 MapTask 和 ReduceTask 就跑在同一个 YarnChild 进行里
MapReduce 套路图
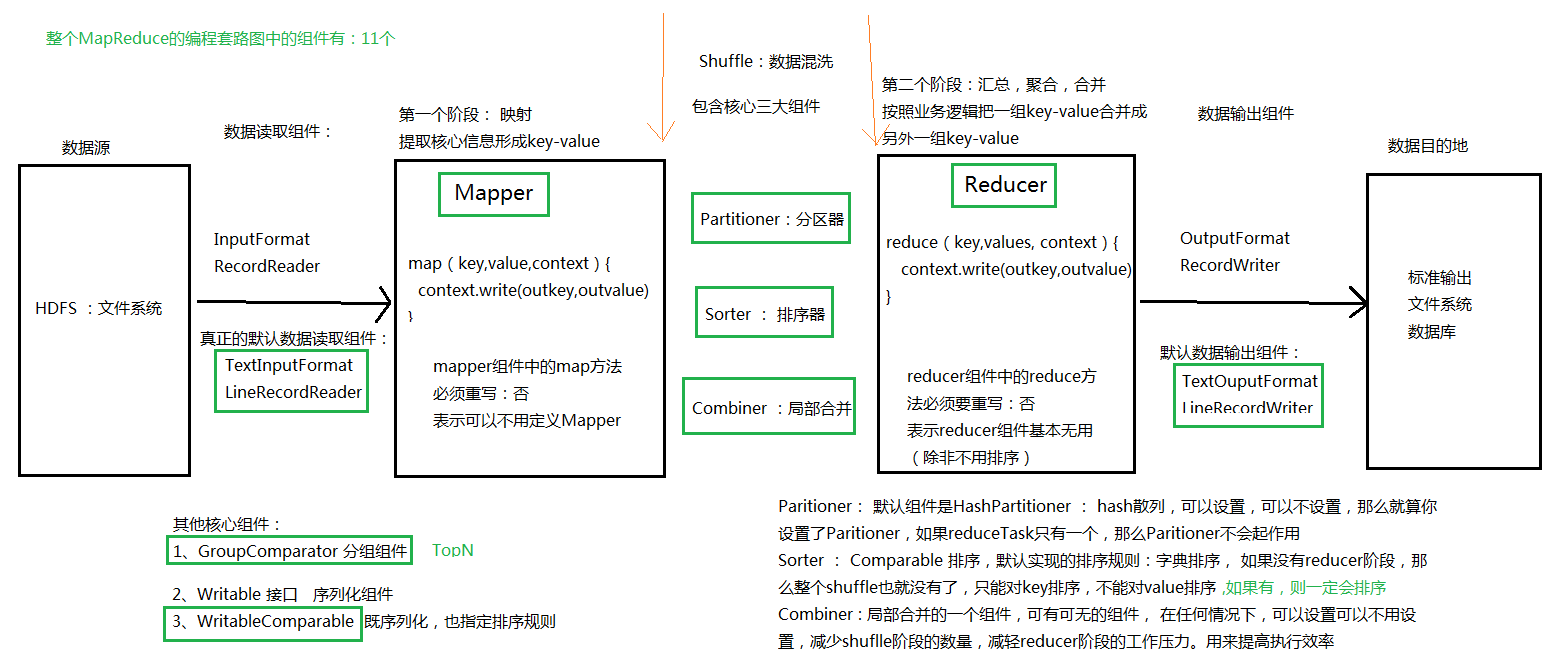
MapReduce 程序的运行
1、一个 mr 程序启动的时候,最先启动的是 MRAppMaster,MRAppMaster 启动后根据本次 job 的描述信息,计算出需要的 maptask 实例数量,然后向集群申请机器启动相应数量的 maptask 进程
2、 maptask 进程启动之后,根据给定的数据切片(哪个文件的哪个偏移量范围)范围进行数 据处理,主体流程为:
A、利用客户指定的 InputFormat 来获取 RecordReader 读取数据,形成输入 KV 对
B、将输入 KV 对传递给客户定义的 map()方法,做逻辑运算,并将 map()方法输出的 KV 对收 集到缓存
C、将缓存中的 KV 对按照 K 分区排序后不断溢写到磁盘文件
3、 MRAppMaster 监控到所有 maptask 进程任务完成之后(真实情况是,某些 maptask 进 程处理完成后,就会开始启动 reducetask 去已完成的 maptask 处 fetch 数据),会根据客户指 定的参数启动相应数量的 reducetask 进程,并告知 reducetask 进程要处理的数据范围(数据 分区)
4、Reducetask 进程启动之后,根据 MRAppMaster 告知的待处理数据所在位置,从若干台 maptask 运行所在机器上获取到若干个 maptask 输出结果文件,并在本地进行重新归并排序, 然后按照相同 key 的 KV 为一个组,调用客户定义的 reduce()方法进行逻辑运算,并收集运 算输出的结果 KV,然后调用客户指定的 OutputFormat 将结果数据输出到外部存储
mapTask的并行度
Hadoop中MapTask的并行度的决定机制。在MapReduce程序的运行中,并不是MapTask越多就越好。需要考虑数据量的多少及机器的配置。如果数据量很少,可能任务启动的时间都远远超过数据的处理时间。同样可不是越少越好。
那么应该如何切分呢?
假如我们有一个300M的文件,它会在HDFS中被切成3块。0-128M,128-256M,256-300M。并被放置到不同的节点上去了。在MapReduce任务中,这3个Block会被分给3个MapTask。
MapTask在任务切片时实际上也是分配一个范围,只是这个范围是逻辑上的概念,与block的物理划分没有什么关系。但在实践过程中如果MapTask读取的数据不在运行的本机,则必须通过网络进行数据传输,对性能的影响非常大。所以常常采取的策略是就按照块的存储切分MapTask,使得每个MapTask尽可能读取本机的数据。
如果一个Block非常小,也可以把多个小Block交给一个MapTask。
所以MapTask的切分要看情况处理。默认的实现是按照Block大小进行切分。MapTask的切分工作由客户端(我们写的main方法)负责。一个切片就对应一个MapTask实例。
MapTask并行度的决定机制
1个job的map阶段并行度由客户端在提交job时决定。
而客户端对map阶段并行度的规划的基本逻辑为:
将待处理数据执行逻辑切片(即按照一个特定切片大小,将待处理数据划分成逻辑上的多个split),然后每一个split分配一个mapTask并行实例处理
这段逻辑及形成的切片规划描述文件,由FileInputFormat实现类的getSplits()方法完成,其过程如下图:
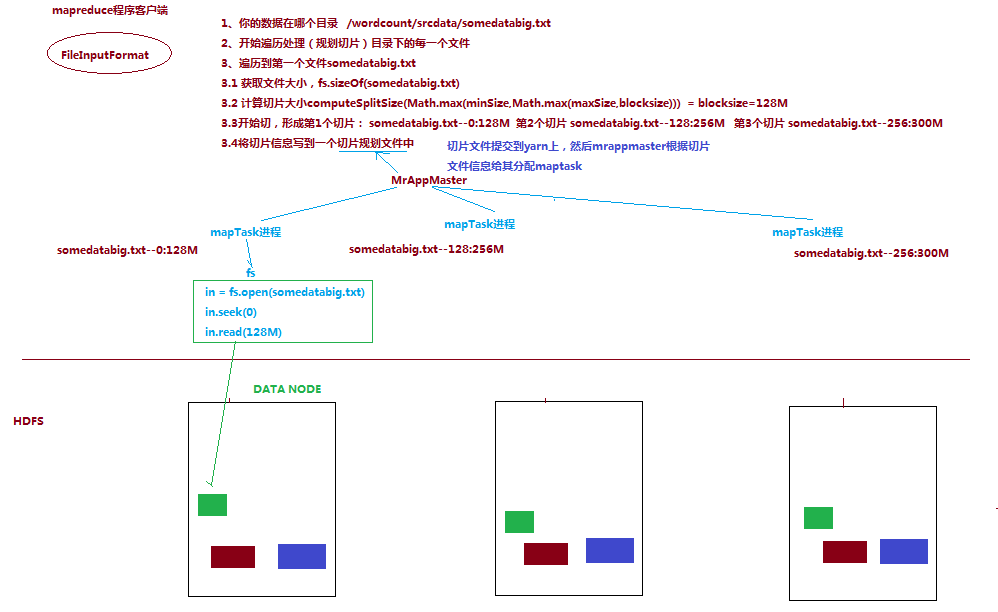
切片机制
FileInputFormat 中默认的切片机制
1、简单地按照文件的内容长度进行切片
2、切片大小,默认等于 block 大小
3、切片时不考虑数据集整体,而是逐个针对每一个文件单独切片 比如待处理数据有两个文件:
File1.txt 200M
File2.txt 100M
经过 getSplits()方法处理之后,形成的切片信息是:
File1.txt-split1 0-128M
File1.txt-split2 129M-200M
File2.txt-split1 0-100M
通过分析源码,在 FileInputFormat 中,计算切片大小的逻辑: long splitSize = computeSplitSize(blockSize, minSize, maxSize),翻译一下就是求这三个值的中 间值
切片主要由这几个值来运算决定:
blocksize:默认是 128M,可通过 dfs.blocksize 修改
minSize:默认是 1,可通过 mapreduce.input.fileinputformat.split.minsize 修改
maxsize:默认是 Long.MaxValue,可通过 mapreduce.input.fileinputformat.split.maxsize 修改
因此,如果 maxsize 调的比 blocksize 小,则切片会小于 blocksize 如果 minsize 调的比 blocksize 大,则切片会大于 blocksize 但是,不论怎么调参数,都不能让多个小文件“划入”一个 split
MapTask 并行度经验之谈
如果硬件配置为 2*12core + 64G,恰当的 map 并行度是大约每个节点 20-100 个 map,最好 每个 map 的执行时间至少一分钟。
1、如果 job 的每个 map 或者 reduce task 的运行时间都只有 30-40 秒钟,那么就减少该 job 的 map 或者 reduce 数,每一个 task(map|reduce)的 setup 和加入到调度器中进行调度,这个 中间的过程可能都要花费几秒钟,所以如果每个 task 都非常快就跑完了,就会在 task 的开 始和结束的时候浪费太多的时间。
配置 task 的 JVM 重用可以改善该问题:
mapred.job.reuse.jvm.num.tasks,默认是 1,表示一个 JVM 上最多可以顺序执行的 task 数目(属于同一个 Job)是 1。也就是说一个 task 启一个 JVM。这个值可以在 mapred-site.xml 中进行更改,当设置成多个,就意味着这多个 task 运行在同一个 JVM 上,但不是同时执行, 是排队顺序执行
2、如果 input 的文件非常的大,比如 1TB,可以考虑将 hdfs 上的每个 blocksize 设大,比如 设成 256MB 或者 512MB
ReduceTask 并行度
reducetask 的并行度同样影响整个 job 的执行并发度和执行效率,但与 maptask 的并发数由 切片数决定不同,Reducetask 数量的决定是可以直接手动设置: job.setNumReduceTasks(4);
默认值是 1,
手动设置为 4,表示运行 4 个 reduceTask,
设置为 0,表示不运行 reduceTask 任务,也就是没有 reducer 阶段,只有 mapper 阶段
如果数据分布不均匀,就有可能在 reduce 阶段产生数据倾斜
注意:reducetask 数量并不是任意设置,还要考虑业务逻辑需求,有些情况下,需要计算全 局汇总结果,就只能有 1 个 reducetask
尽量不要运行太多的 reducetask。对大多数 job 来说,最好 rduce 的个数最多和集群中的 reduce 持平,或者比集群的 reduce slots 小。这个对于小集群而言,尤其重要。
ReduceTask 并行度决定机制
1、job.setNumReduceTasks(number);
2、job.setReducerClass(MyReducer.class);
3、job.setPartitioonerClass(MyPTN.class);
分以下几种情况讨论:
1、如果number为1,并且2已经设置为自定义Reducer, reduceTask的个数就是1
不管用户编写的MR程序有没有设置Partitioner,那么该分区组件都不会起作用
2、如果number没有设置,并且2已经设置为自定义Reducer, reduceTask的个数就是1
在默认的分区组件的影响下,不管用户设置的number,不管是几,只要大于1,都是可以正常执行的。
如果在设置自定义的分区组件时,那么就需要注意:
你设置的reduceTasks的个数,必须要 ==== 分区编号中的最大值 + 1
最好的情况下:分区编号都是连续的。
那么reduceTasks = 分区编号的总个数 = 分区编号中的最大值 + 1
3、如果number为 >= 2 并且2已经设置为自定义Reducer reduceTask的个数就是number
底层会有默认的数据分区组件在起作用
4、如果你设置了number的个数,但是没有设置自定义的reducer,那么该mapreduce程序不代表没有reducer阶段
真正的reducer中的逻辑,就是调用父类Reducer中的默认实现逻辑:原样输出
reduceTask的个数 就是 number
5、如果一个MR程序中,不想有reducer阶段。那么只需要做一下操作即可:
job.setNumberReudceTasks(0);
整个MR程序只有mapper阶段。没有reducer阶段。
那么就没有shuffle阶段
Hadoop学习之路(十四)MapReduce的核心运行机制的更多相关文章
- MapReduce的核心运行机制
MapReduce的核心运行机制概述: 一个完整的 MapReduce 程序在分布式运行时有两类实例进程: 1.MRAppMaster:负责整个程序的过程调度及状态协调 2.Yarnchild:负责 ...
- Hadoop学习之路(四)Hadoop集群搭建和简单应用
概念了解 主从结构:在一个集群中,会有部分节点充当主服务器的角色,其他服务器都是从服务器的角色,当前这种架构模式叫做主从结构. 主从结构分类: 1.一主多从 2.多主多从 Hadoop中的HDFS和Y ...
- Hadoop 学习之路(四)—— Hadoop单机伪集群环境搭建
一.前置条件 Hadoop的运行依赖JDK,需要预先安装,安装步骤见: Linux下JDK的安装 二.配置免密登录 Hadoop组件之间需要基于SSH进行通讯. 2.1 配置映射 配置ip地址和主机名 ...
- Hadoop 学习笔记 (十) MapReduce实现排序 全局变量
一些疑问:1 全排序的话,最后的应该sortJob.setNumReduceTasks(1);2 如果多个reduce task都去修改 一个静态的 IntWritable ,IntWritable会 ...
- 学习之路十四:客户端调用WCF服务的几种方法小议
最近项目中接触了一点WCF的知识,也就是怎么调用WCF服务,上网查了一些资料,很快就搞出来,可是不符合头的要求,主要有以下几个方面: ①WCF的地址会变动,地址虽变,但是里面的逻辑不变! ②不要引用W ...
- 嵌入式Linux驱动学习之路(十四)按键驱动-同步、互斥、阻塞
目的:同一个时刻,只能有一个应用程序打开我们的驱动程序. ①原子操作: v = ATOMIC_INIT( i ) 定义原子变量v并初始化为i atomic_read(v) 返回原子变量 ...
- zigbee学习之路(十四):基于协议栈的无线数据传输
一.前言 上次实验,我们介绍了zigbee原理的应用与使用,进行了基于zigbee的串口发送协议,但是上个实验并没有实现数据的收发.在这个实验中,我们要进行zigbee的接受和发送实验. 二.实验功能 ...
- IOS学习之路十四(用TableView做的新闻客户端展示页面)
最近做的也个项目,要做一个IOS的新闻展示view(有图有文字,不用UIwebview,因为数据是用webservice解析的到的json数据),自己一直没有头绪,可后来听一个学长说可以用listvi ...
- 《Hadoop学习之路》学习实践
(实践机器:blog-bench) 本文用作博文<Hadoop学习之路>实践过程中遇到的问题记录. 本文所学习的博文为博主“扎心了,老铁” 博文记录.参考链接https://www.cnb ...
随机推荐
- 撰写html标签的快捷方式1
一: <ul> <li><a href=""></a></li></ul> 如果要写上面的标签,直接写 ul ...
- 计算机网络:自顶向下方法(第七版)Wireshark实验指南
这本书的每一章后面都提供了一个Wireshark实验,通过使用Wireshark抓包并手动对包进行分析可以帮助我们更好地理解各种协议和相关知识.然而,这个资源在网上好像很难找,我历经千辛万苦找到之后, ...
- java 获取两个日期之间的所有日期(年月日)
前言:直接上代码 java 获取两个日期之间的所有日期(年月日) /** * 获取两个日期之间的日期,包括开始结束日期 * @param start 开始日期 * @param end 结束日期 * ...
- QT的信号和槽机制简介
信号与槽作为QT的核心机制在QT编程中有着广泛的应用,本文介绍了信号与槽的一些基本概念.元对象工具以及在实际使用过程中应注意的一些问题. QT是一个跨平台的C++ GUI应用构架,它提供了丰富的窗口部 ...
- 可缺省的CSS布局——张鑫旭
一.技术不难.意识很难 有些东西的东西的实现,难的不是原料.技术:而是想不到,或者说意识不到. 例如下面这个简单而又神奇的魔术: 是吧.搞通了,才发现,哦~原来这么回事,很简单的嘛,我也可以实现的!其 ...
- PHPCMS V9标签循环嵌套调用数据的方法
PHPCMS V9的标签制作以灵活见长,可以自由DIY出个性的数据调用,对于制作有风格有创意的网站模板很好用,今天就介绍一个标签循环嵌套方法,可以实现对PC标签循环调用,代码如下: 在此文件里/php ...
- ThreeJS两个点作为起始坐标画一个立方体
drawLineBox(new THREE.Vector3(100, 50, 0), new THREE.Vector3(200, 100, 100)); function drawLineBox(s ...
- Fatal error: Call to undefined function curl_init()解决办法
问题描述: 在Windows SERVER 2012RC 64 bit OS, php 5.6.3的环境下,搭建好了php运行环境.但是在调用 curl_init() 方法时却报错了. 检查了一下,p ...
- C++ 判断当前系统x64 or x86
BOOL IsWow64(){ BOOL bIsWow64 = FALSE; //IsWow64Process is not available on all supported versions o ...
- linux rabbitmq 安装
下载 在安装 erlang 时使用的是源码包21.0版本:接着下载 rabbitmq-server/3.7.7 的源码包,编译时报错,说 erlang 版本号不满足条件,erlang版本>=19 ...