简单ORACLE分区表、分区索引
前一段听说CSDN.COM里面很多好东西,同事建议看看合适自己也可以写一写,呵呵,今天第一次开通博客,随便写点东西,就以第一印象分区表简单写第一个吧。
ORACLE对于分区表方式其实就是将表分段存储,一般普通表格是一个段存储,而分区表会分成多个段,所以查找数据过程都是先定位根据查询条件定位分区范围,即数据在那个分区或那几个内部,然后在分区内部去查找数据,一个分区一般保证四十多万条数据就比较正常了,但是分区表并非乱建立,而其维护性也相对较为复杂一点,而索引的创建也是有点讲究的,这些以下尽量阐述详细即可。
1、类型说明:
range分区方式,也算是最常用的分区方式,其通过某字段或几个字段的组合的值,从小到大,按照指定的范围说明进行分区,我们在INSERT数据的时候就会存储到指定的分区中。
List分区方式,一般是在range基础上做的二级分区较多,是一种列举方式进行分区,一般讲某些地区、状态或指定规则的编码等进行划分。
Hash分区方式,它没有固定的规则,由ORACLE管理,只需要将值INSERT进去,ORACLE会自动去根据一套HASH算法去划分分区,只需要告诉ORACLE要分几个区即可。
分区可以进行两两组合,ORACLE 11G以前两两组合都必须以range作为一级分区的开头,ORACLE目前最多支持2级别分区,但这个级别已经够我们使用了。
我这只以最简单的分区方式创建分区来说明问题,就拿range分区来说明问题吧(基本创建语句如下):
- CREATE TABLE TABLE_PARTITION(
- COL1 NUMBER,
- COL2 VARCHAR2(10)
- )
- partition by range(COL1)(
- partition TAB_PARTOTION_01 values less than (450000),
- partition TAB_PARTOTION_02 values less than (900000),
- partition TAB_PARTOTION_03 values less than (1350000),
- partition TAB_PARTOTION_04 values less than (1800000),
- partition TAB_PARTOTION_OTHER values less THAN (MAXVALUE)
- );
这个分区表创建了四个定长分区,理想情况下,存储450000条数据,扩展分区是超过这个数额的分区,当发现扩展分区有数据的时候,可以进行将扩展分区做SPLIT操作,这个后面说明,这里先说一下一些常用的分区表查询功能,我们先插入一些数据进去。
- INSERT INTO TABLE_PARTITION(COL1,COL2)
- VALUES(1,'数据测试');
- INSERT INTO TABLE_PARTITION(COL1,COL2)
- VALUES(23,'数据测试');
- INSERT INTO TABLE_PARTITION(COL1,COL2)
- VALUES(449000,'数据测试');
- INSERT INTO TABLE_PARTITION(COL1,COL2)
- VALUES(450000,'数据测试');
- INSERT INTO TABLE_PARTITION(COL1,COL2)
- VALUES(1350000,'数据测试');
- INSERT INTO TABLE_PARTITION(COL1,COL2)
- VALUES(900000,'数据测试');
- INSERT INTO TABLE_PARTITION(COL1,COL2)
- VALUES(1800000-1,'数据测试');
- COMMIT;
为了检测哪些分区中有哪些数据分别按照分区去查询数据(应用开发中基本不会用到,因为不会把分区写死)
- SQL> SELECT * FROM TABLE_PARTITION partition(TAB_PARTOTION_01);
- COL1 COL2
- ---------- ---------------
- 1 数据测试
- 23 数据测试
- 449000 数据测试
说明第一个分区有:1、23、44900这些数据,也就是插入时,ORACLE是自己去找分区的,其实分区这种子表管理自己也可以通过程序去完成,ORACLE给你提供了一套,就可以自己去完成了。其余的数据就自己查了,都是一个道理。
2、分区应用:
一般一张表超过2G的大小,ORACLE是推荐使用分区表的,分区一般都需要创建索引,说到分区索引,就可以分为:全局索引、分区索引,即:global索引和local索引,前者为默认情况下在分区表上创建索引时的索引方式,并不对索引进行分区(索引也是表结构,索引大了也需要分区,关于索引以后专门写点)而全局索引可修饰为分区索引,但是和local索引有所区别,前者的分区方式完全按照自定义方式去创建,和表结构完全无关,所以对于分区表的全局索引有以下两幅网上常用的图解:
2.1、对于分区表的不分区索引(这个有点绕,不过就是表分区,但其索引不分区):
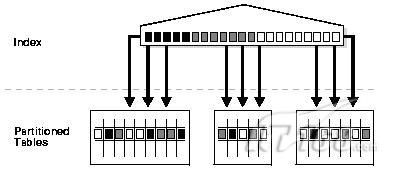
创建语法(直接创建即可):
CREATE INDEX <index_name> ON <partition_table_name>(<column_name>);
2.2、对于分区表的分区索引:
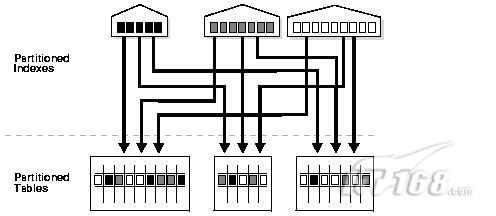
创建语法为:
- CREATE INDEX INX_TAB_PARTITION_COL1 ON TABLE_PARTITION(COL1)
- GLOBAL PARTITION BY RANGE(COL1)(
- PARTITION IDX_P1 values less than (1000000),
- PARTITION IDX_P2 values less than (2000000),
- PARTITION IDX_P3 values less than (MAXVALUE)
- );
2.3、LOCAL索引结构:
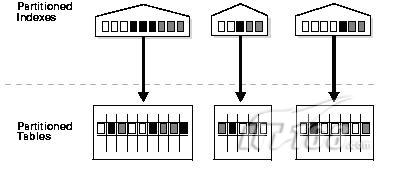
创建语法为:
- CREATE INDEX INX_TAB_PARTITION_COL1 ON TABLE_PARTITION(COL1) LOCAL;
也可按照分区表的的分区结构给与一一定义,索引的分区将得到重命名。
分区上的位图索引只能为LOCAL索引,不能为GLOBAL全局索引。
2.4、对比索引方式:
一般使用LOCAL索引较为方便,而且维护代价较低,并且LOCAL索引是在分区的基础上去创建索引,类似于在一个子表内部去创建索引,这样开销主要是区分分区上,很规范的管理起来,在OLAP系统中应用很广泛;而相对的GLOBAL索引是全局类型的索引,根据实际情况可以调整分区的类别,而并非按照分区结构一一定义,相对维护代价较高一些,在OLTP环境用得相对较多,这里所谓OLTP和OLAP也是相对的,不是特殊的项目,没有绝对的划分概念,在应用过程中依据实际情况而定,来提高整体的运行性能。
3、常用视图:
- 1、查询当前用户下有哪些是分区表:
- SELECT * FROM USER_PART_TABLES;
- 2、查询当前用户下有哪些分区索引:
- SELECT * FROM USER_PART_INDEXES;
- 3、查询当前用户下分区索引的分区信息:
- SELECT * FROM USER_IND_PARTITIONS T
- WHERE T.INDEX_NAME=?
- 4、查询当前用户下分区表的分区信息:
- SELECT * FROM USER_TAB_PARTITIONS T
- WHERE T.TABLE_NAME=?;
- 5、查询某分区下的数据量:
- SELECT COUNT(*) FROM TABLE_PARTITION PARTITION(TAB_PARTOTION_01);
- 6、查询索引、表上在那些列上创建了分区:
- SELECT * FROM USER_PART_KEY_COLUMNS;
- 7、查询某用户下二级分区的信息(只有创建了二级分区才有数据):
- SELECT * FROM USER_TAB_SUBPARTITIONS;
4、维护操作:
4.1、删除分区
- ALTER TABLE TABLE_PARTITION DROP PARTITION TAB_PARTOTION_03;
- 如果是全局索引,因为全局索引的分区结构和表可以不一致,若不一致的情况下,会导致整个全局索引失效,在删除分区的时候,语句修改为:
- ALTER TABLE TABLE_PARTITION DROP PARTITION TAB_PARTOTION_03 UPDATE GLOBAL INDEXES
4.2、分区合并(从中间删除掉一个分区,或者两个分区需要合并后减少分区数量)
合并分区和删除中间的RANGE有点像,但是合并分区是不会删除数据的,对于LIST、HASH分区也是和RANGE分区不一样的,其语法为:
- ALTER TABLE TABLE_PARTITION MERGE PARTITIONS TAB_PARTOTION_01,TAB_PARTOTION_02 INTO PARTITION MERGED_PARTITION;
4.3、分隔分区(一般分区从扩展分区从分隔)
- ALTER TABLE TABLE_PARTITION SPLIT PARTITION TAB_PARTOTION_OTHERE AT(2500000)
- INTO (PARTITION TAB_PARTOTION_05,PARTITION TAB_PARTOTION_OTHERE);
4.4、创建新的分区(分区数据若不能提供范围,则插入时会报错,需要增加分区来扩大范围)
一般有扩展分区的是都是用分隔的方式,若上述创建表时没有创建TAB_PARTOTION_OTHER分区时,在插入数据较大时(按照上述建立规则,超过1800000就应该创建新的分区来存储),就可以创建新的分区,如:
为了试验,我们将扩展分区先删除掉再创建新的分区(因为ORACLE要求,分区的数据不允许重叠,即按照分区字段同样的数据不能同时存储在不同的分区中):
- ALTER TABLE TABLE_PARTITION DROP PARTITION TAB_PARTOTION_OTHER;
- ALTER TABLE TABLE_PARTITION ADD PARTITION TAB_PARTOTION_06 VALUES LESS THAN(2500000);
在分区下创建新的子分区大致如下(RANGE分区,若为LIST或HASH分区,将创建方式修改为对应的方式即可):
- ALTER TABLE <table_name> MODIFY PARTITION <partition_name> ADD SUBPARTITION <user_define_subpartition_name> VALUES LESS THAN(....);
4.5、修改分区名称(修改相关的属性信息)
- ALTER TABLE TABLE_PARTITION RENAME PARTITION MERGED_PARTITION TO MERGED_PARTITION02;
4.6、交换分区(快速交换数据,其实是交换段名称指针)
首先创建一个交换表,和原表结构相同,如果有数据,必须符合所交换对应分区的条件:
- CREATE TABLE TABLE_PARTITION_2
- AS SELECT * FROM TABLE_PARTITION WHERE 1=2;
然后将第一个分区的数据交换出去:
- ALTER TABLE TABLE_PARTITION EXCHANGE PARTITION TAB_PARTOTION_01
- WITH TABLE TABLE_PARTITION_2 INCLUDING INDEXES;
此时会发现第一个分区的数据和表TABLE_PARTITION_2做了瞬间交换,比TRUNCATE还要快,因为这个过程没有进行数据转存,只是段名称的修改过程,和实际的数据量没有关系。
如果是子分区也可以与外部的表进行交换,只需要将关键字修改为:SUBPARTITION 即可。
4.7、清空分区数据
- ALTER TABLE <table_name> TRUNCATE PARTITION <partition_name>;
- ALTER TABLE <table_name> TRUNCATE subpartition <subpartition_name>;
9、磁盘碎片压缩
对分区表的某分区进行磁盘压缩,当对分区内部数据进行了大量的UPDATE、DELETE操作后,一定时间需要进行磁盘压缩,否则在查询时,若通过FULL SCAN扫描数据,将会把空块也会扫描到,对表进行磁盘压缩需要进行行迁移操作,所以首先需要操作:
- ALTER TABLE <table_name> ENABLE ROW MOVEMENT ;
- 对分区表的某分区压缩语法为:
- ALTER TABLE <table_name>
- modify partition <partition_name> shrink space;
- 对普通表压缩:
- ALTER TABLE <table_name> shrink space;
- 对于索引也需要进行压缩,索引也是表:
- ALTER INDEX <index_name> shrink space;
10、分区表重新分析以及索引重新分析
对表进行压缩后,需要对表和索引进行重新分析,对表进行重新分析,一般有两种方式:
在ORACLE 10G以前,使用:
- BEGIN
- dbms_stats.gather_table_stats(USER,UPPER('<table_name>'));
- END;
- ORACLE 10G后,可以使用:
- ANALYZE TABLE <table_name> COMPUTE STATISTICS;
索引重新分析,将上述两种方式分别修改一下,如第一种可以使用:gather_index_stats,而第二种修改为:ANALYZE INDEX即可,不过一般比较常用的是重新编译:
对于分区表并进行了索引分区的情况,需要对每个分区的索引进行重新编译,这里以LOCAL索引为例子(其每个索引的分区和表分区结构相同,默认分区名称和表分区名称相同):
- ALTER INDEX <index_name> REBUILD PARTITION <partition_name>;
- 对于全局索引,根据全局索引锁定义的分区名称修改即可,若没有分区,和普通单表索引重新编译方式相同:
- ALTER INDEX <index_name> REBUILD;
11、关联对象重新编译
上述对表、索引进行重新编译,尤其对表进行了压缩后会产生行迁移,这个过程可能会导致一些视图、过程对象的失效,此时要将其重新编译一次。
12、扩展:HASH分区中,如果创建了新的分区,可以将其进行重新HASH分布:
- ALTER TABLE <table_name> COALESCA PARTITION
5、回归总结:何时建分区,分区类别,索引,如何对应SQL
1、创建时机
上述已经说明,2G以上的表,ORACLE推荐创建分区。
分区的方式根据实际情况而定,才能提高整体性能。
分区的字段一定要是经常用以提取数据的字段,否则会在提取过程中导致遍历多个分区,这样比没有分区还要慢。
分区字段要选择合适,数据较为均匀分布到各个分区,不要太多也不要太少,而且根据分区字段可以很快定位到分区范围。
一般情况下,尽量然业务操作在同一个分区内部完成。
2、分区类别
分区主要有RANGE、LIST、HASH;
RANGE通过值的范围分区,也是最常用的分区,这种分区注意在一种变长数字字符串中,很多人会导致认为是数字类型,而按照数字区分区,这样会分布十分不均匀的现象发生。
LIST是列举方式进行分区,一般作为二级分区而存在(当然也可以自己分区,ORACLE 11G后在分区上也可以作为主分区而存在),在RANGE基础上,若数据需要继续分区,并且在RANGE基础上数据量较为固定,只是较大,可以按照一定规则进一步分区。
HASH只指定分区个数,分区细节由ORACLE完成,增加HASH分区可以重新分布数据。
注意:分区字段不能使用函数转换后在分区,如,将某数字字符串字段,先TO_NUMER(COL_NAME)后分区。
3、索引类别
大致分:GLOBAL索引和LOCAL索引,钱和可以分:GLOBAL不分区索引,和GLOBAL分区索引。
GLOBAL不分区索引一般不太推荐,因为是用一颗大的索引树来映射一个表,这个过程,这样速度不见得比不分区快。
GLOBAL分区索引,查找数据若通过要通过索引,是先定位了索引内部的分区,然后在这个分区索引中找到ROWID,然后回表提取数据。
LOCAL索引是和分区的个数逐个对应的,可以说先定位分区表的分区也可以说先定位索引的分区,因为他们是一一对应的,找到对应分区后,分区内部索引数据集合。
4、对应应用
分区表、索引、分区索引,要利用其性能优势,最基本就是要提取数据时,要通过它首先将数据的范围缩小到一个即使做全盘扫描也不会太慢的情况。
所以SQL一定要有分区上的这个字段的一个WHERE条件,将数据迅速定位到分区内部,而且尽量定位到一个分区里面(这个和创建分区的规则有关系)。
建立分区本身不提要性能,要用好才可提高性能,在必要的RAC集群中,若存在多分区提取数据,适当采用并行提取可以提高提取的速度。
对于索引部分,这里也只提到分区索引的创建方式以及常见索引的维护方式,对于索引原理理解后会更容易认识到提取数据时的技巧。
简单ORACLE分区表、分区索引的更多相关文章
- Oracle 分区表的索引、分区索引
对于分区表,可以建立不分区索引.也就是说表分区,但是索引不分区.以下着重介绍分区表的分区索引. 索引与表一样,也可以分区.索引分为两类:locally partition index(局部分区索引). ...
- (转)Oracle分区表和索引的创建与管理
今天用到了Oracle表的分区,就顺便写几个例子把这个表的分区说一说: 一.创建分区表 1.范围分区 根据数据表字段值的范围进行分区 举个例子,根据学生的不同分数对分数表进行分区,创建一个分区表如下: ...
- oracle 重建分区索引
分区表的所有分区相当于一个单独的表. 创建在分区表上的索引,就相当于在所有分区上单独创建的索引(主键索引除外). 重建分区表的索引回报: ORA-14086:不能将分区索引作为整体重建. so,重建语 ...
- Oracle非分区索引,全局分区索引和本地分区索引。
1.如果按照索引是否分区作为划分依据,Oracle 的索引类型可以分为非分区索引,全局分区索引和本地分区索引. 2.创建演示实例 --创建非分区表create table test_partition ...
- Oracle 分区表中索引失效
当对分区表进行 一些操作时,会造成索引失效. 当有truncate/drop/exchange 操作分区 时全局索引 会失效. exchange 的临时表没有索引,或者有索引,没有用includin ...
- 记一次Oracle分区表全局索引重建的过程
1.查询数据库各个表空间利用率: SELECT Upper(F.TABLESPACE_NAME) "表空间名", D.TOT_GROOTTE_MB "表空间大小(M)&q ...
- oracle分区表分区栏位NULL值测试
实验在分区栏位为NULL时,分区表的反应 1.创建普通的分区表 CREATE TABLE MONKEY.TEST_PART_NULL_NORMAL ( ID NUMBER, ADD_DATE DATE ...
- [Oracle]分区索引
上一节学习了分区表,接着学习分区索引. (一)什么时候对索引进行分区 · 为了避免移动数据时重建整个索引,可对索引分区,在重建索引时,只需重建与数据分区相关的索引: · 在对分区表进行维护时,为了避免 ...
- Oracle分区表之分区范围扫描(PARTITION RANGE ITERATOR)与位图范围扫描(BITMAP INDEX RANGE SCAN)
一.前言: 一开始分区表和位图索引怎么会挂钩呢?可能现实就是这么的不期而遇:比如说一张表的字段是年月日—‘yyyy-mm-dd’,重复率高吧,适合建位图索引吧,而且这张表数据量也不小,也适合转换成分区 ...
随机推荐
- 单点登录(十七)----cas4.2.x登录mongodb验证方式成功后返回更多信息更多属性到客户端
我们在之前已经完成了cas4.2.x登录使用mongodb验证方式登录成功了.也解决了登录名中使用中文乱码的问题. 单点登录(十三)-----实战-----cas4.2.X登录启用mongodb验证方 ...
- 怎样将Android SDK源码 导入到Eclipse中?
在Eclipse中导入android sdk源码 http://blog.csdn.net/hahahacff/article/details/8590649
- vue入门教程
vue视频教程(对vue有个概览,要掌握vue-cli的用法,对vue-router,vuex有基本的概念) https://www.imooc.com/learn/1091 1. vue-cli v ...
- 解题:CF570D Tree Requests
题面 DSU on tree确实很厉害,然后这变成了一道裸题(逃 还是稍微说一下流程吧,虽然我那个模板汇总里写过 DSU on tree可以以$O(n\log n)$的复杂度解决树上子树统计问题,它这 ...
- url参数中有+、空格、=、%、&、#等特殊符号的问题解决
url出现了有+,空格,/,?,%,#,&,=等特殊符号的时候,可能在服务器端无法获得正确的参数值,如何是好?解决办法将这些字符转化成服务器可以识别的字符,对应关系如下:URL字符转义 用其它 ...
- js子节点children和childnodes的用法
想要获取子节点的数量,有几种办法. childNodes 它会把空的文本节点当成节点, <ul> 文本节点 <li>元素节点</li> 文本节点 <li> ...
- Spring Cloud微服务实战阅读笔记(一) 基础知识
本文系<Spring Cloud微服务实战>作者:翟永超,一书的阅读笔记. 一:基础知识 1:什么是微服务架构 是一种架构设计风格,主旨是将一个原本独立的系统拆分成多个小型服务 ...
- linux下项目上线配置nginx+tomcat
nginx.conf server { listen 80; server_name www.examples.com; client_max_body_size 300m; #charset koi ...
- C++的一些不错开源框架,可以学习和借鉴
from https://www.cnblogs.com/charlesblc/p/5703557.html [本文系外部转贴,原文地址:http://coolshell.info/c/c++/201 ...
- React基础笔记
参考文章: http://www.ruanyifeng.com/blog/2015/03/react.html https://segmentfault.com/a/1190000002767365 ...