Perl6 必应抓取(2):最终版
use HTTP::UserAgent;
use URI::Encode; my $ua = HTTP::UserAgent.new(:user-agent<Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/ Firefox/52.0>);
my $bing_url = 'http://cn.bing.com/search?q=';
my $choose = rx/'<cite>'(.*?)'</cite>'/;#要查的内容
my $filename = ~now.DateTime~'.txt';
$filename = do given $filename {S:g/':'/-/};
my $fp = open $filename, :w;
my $hv;
my $all_data; #进度显示 sub MAIN (Int $page_number) {
say '+';
say '=======================================================================';
say ' By: FireC@t';
say '=======================================================================';
#say '';
my $strings = prompt 'Input String You Want: ';
say 'Search : '~$strings;
$all_data = *$page_number;
say 'Data count(10*'~$page_number~') : '~$all_data; #输出数据数目
my $start_time = now.DateTime;
say 'Start Time : '~$start_time;
say '=======================================================================';
$strings = uri_encode($strings);
my $count = ;
for ..$page_number {
#每一页的结果调用函数
my $url_end = '&first='~$count;
my $targeturl = $bing_url~$strings~$url_end;
#say $targeturl;
#调用函数查询结果URL
Bing_search($targeturl);
$count += ;
}
my $end_time = now.DateTime;
say '=======================================================================';
say 'Finish Time : '~$end_time;
say 'Time Use : '~($end_time-$start_time);
say '=======================================================================';
say 'Data save to : '~$filename;
say '=======================================================================';
} #查询函数
sub Bing_search($url) {
my $html = $ua.get($url).content;#获取结果
loop {
$html ~~ $choose;
last if not $; my $swap_ = ~$;
$html = $/.postmatch;
$swap_ = do given $swap_ {S:g/'<strong>'//};
$swap_ = do given $swap_ {S:g/'</strong>'//};
say '('~$hv~':'~$all_data~')'~$swap_;
$hv++;
$fp.say($swap_);
}
}
说明, 在dos下输入中文, 因为终端编码问题, 程序会报错。
在linux下运行正常, 或dos下设置编为utf8。
用法:
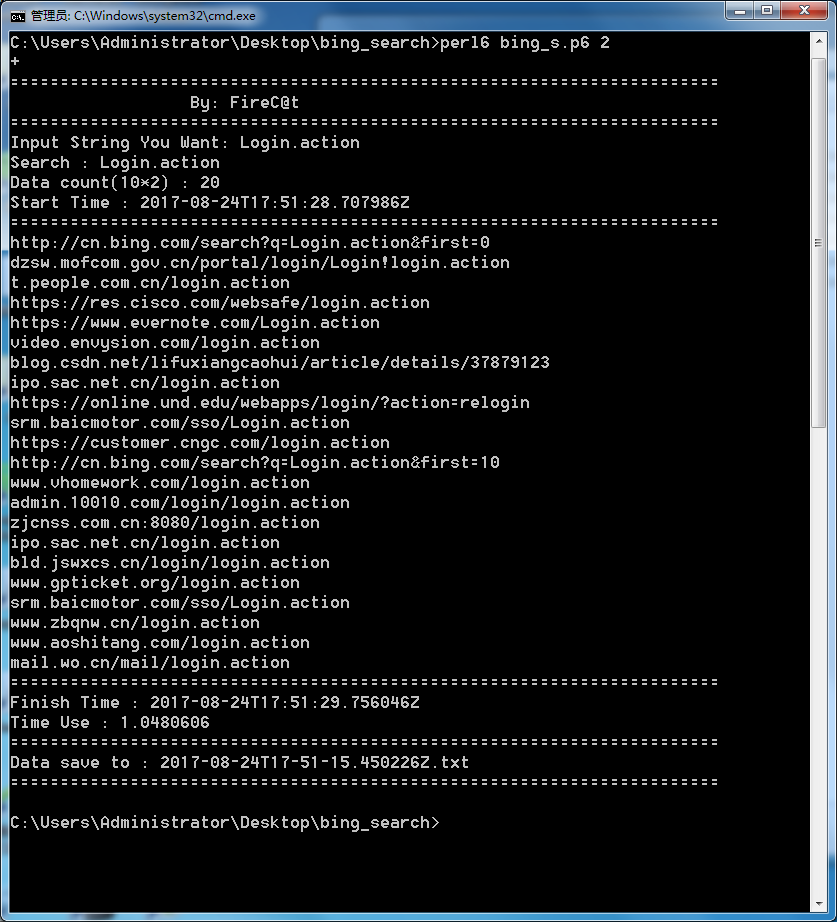
> perl6 bing_s.p6 这里的参数 10为页数, 可随意更改。
BUG:
如果bing中的结果只有 100 条, 而我们向他取 1000 条, 这时我们会取到相同的数据。
修复:
在运行前, 用bing的数据库条目与用户输入的对比。 如果用户请求数目超出bing现有数目, 取bing最大值代替用户输入的最大值。
update: 2017/08/25
修复后代码:
use HTTP::UserAgent;
use URI::Encode; =begin pod
用于国内版bing查询
# by FireC@t
# 2017/08/25
=end pod my $ua = HTTP::UserAgent.new(:user-agent<Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/ Firefox/52.0>);
my $bing_url = 'http://cn.bing.com/search?q=';
my $choose = rx/'<cite>'(.*?)'</cite>'/;#要查的内容
my $filename = ~now.DateTime~'.txt';
$filename = do given $filename {S:g/':'/-/};
my $fp = open $filename, :w;
my $hv=;
my $all_data; #进度显示 sub MAIN (Int $page_number) {
say '+';
say '=======================================================================';
say ' By: FireC@t';
say '=======================================================================';
#say '';
my $strings = prompt 'Input String You Want: ';
say 'Search : '~$strings;
say 'User Data Get Page : '~$page_number; #输出数据数目
my $start_time = now.DateTime; $strings = uri_encode($strings);
#调用用户处理函数, 处理记录数, 防止重复 $all_data = *$page_number;#先计算用户实际要求的数目
#如果用户请求数据过多, 提示
#say 'Test all_data ->'~$all_data; # for test;
my $page_number_swap = User_data_chang($strings);
if $page_number_swap < $page_number {
say 'Not enough Data for bing('~$page_number_swap~' pages), page_number change: '~$page_number~' to '~$page_number_swap;
#改写用户要求的实际数目
$all_data = *$page_number_swap;
} my $count = ;
say 'Start Time : '~$start_time;
say '=======================================================================';
#sleep(100);
for ..$page_number_swap {
#每一页的结果调用函数
my $url_end = '&first='~$count;
my $targeturl = $bing_url~$strings~$url_end;
say '>> '~$targeturl~'';
#调用函数查询结果URL
Bing_search($targeturl);
$count += ;
}
my $end_time = now.DateTime;
say '=======================================================================';
say 'Finish Time : '~$end_time;
say 'Time Use : '~($end_time-$start_time);
say '=======================================================================';
say 'Data('~$hv-~' lines) save to : '~$filename;
say '=======================================================================';
} #查询函数
sub Bing_search($url) {
my $html = $ua.get($url).content;#获取结果
loop {
$html ~~ $choose;
last if not $; my $swap_ = ~$;
$html = $/.postmatch;
$swap_ = do given $swap_ {S:g/'<strong>'//};
$swap_ = do given $swap_ {S:g/'</strong>'//};
say '('~$hv~':'~$all_data~') '~$swap_;
$hv++; #记录数据数目
$fp.say($swap_);
}
} #用于处理用户请求记录数
sub User_data_chang($strings){
#获取所有记录数:
my $start_url = $bing_url~$strings;
my $all_result_number = $ua.get($start_url);
$all_result_number ~~ /'sb_count">'(.*?)\s.*?'</span>'/;
if not $ {
#say 'Not Result';
return ;
#没有结果, 直接返回0个页面
}
#如果有结果
my $data_number = ~$;#123,45
#say $data_number; #test
my $bing_all_data = Int($data_number.subst: /','/,'',:g); #获得结果总数
#test
#say $bing_all_data;
#say $all_data; #$all_data为用户请求总数
if $all_data > $bing_all_data {
#如果用户请求数大于数据已有数目, 那就返回所有请求
#调用分页函数返回一共有多少页
my $user_page = User_page($bing_all_data);
#say 'return page:'~$user_page; sleep(1000);
return $user_page;#返回页数 }else {
#否则返回用户自定义页数
my $user_page = User_page($all_data);
#say 'return page:'~$user_page; sleep(1000);
return $user_page;
}
} #用于处理页数
sub User_page($data_number) {
my $page_check = ~($data_number/);
if $page_check.split('.').elems == {
#说明有小数
return $page_check.split('.')[] + ;
}else {
#没小数, 取整数
return $page_check.split('.')[];
}
}
Perl6 必应抓取(2):最终版的更多相关文章
- Perl6 必应抓取(1):测试版代码
一个相当丑漏的代码, 以后有时间再优化了. 默认所有查找都是15页, 如果结果没有15页这么多估计会有重复.速度还是很快的. sub MAIN() { my $fp = open 'bin_resul ...
- Python爬虫:新浪新闻详情页的数据抓取(函数版)
上一篇文章<Python爬虫:抓取新浪新闻数据>详细解说了如何抓取新浪新闻详情页的相关数据,但代码的构建不利于后续扩展,每次抓取新的详情页时都需要重新写一遍,因此,我们需要将其整理成函数, ...
- 【爬虫】biqukan抓取2.0版
#!python3.7 import requests,sys,time,logging,random from lxml import etree logging.basicConfig(level ...
- php抓取远程数据显示在下拉列表中
前言:周五10月20日的时候,经理让做一个插件,使用的thinkphp做这个demo 使用CURL抓取远程数据时如果出现乱码问题可以加入 header("content-type:text/ ...
- Java、C#双语版HttpHelper类(解决网页抓取乱码问题)
在做一些需要抓取网页的项目时,经常性的遇到乱码问题.最省事的做法是去需要抓取的网站看看具体是什么编码,然后采用正确的编码进行解码就OK了,不过总是一个个页面亲自去判断也不是个事儿,尤其是你需要大量抓取 ...
- 如何使用 Github Actions 自动抓取每日必应壁纸?
如何白嫖 Github 服务器自动抓取必应搜索的每日壁纸呢? 如果你访问过必应搜索网站,那么你一定会被搜索页面的壁纸吸引,必应搜索的壁纸每日不同,自动更换,十分精美.这篇文章会介绍如何一步步分析出必应 ...
- python爬虫beta版之抓取知乎单页面回答(low 逼版)
闲着无聊,逛知乎.发现想找点有意思的回答也不容易,就想说要不写个爬虫帮我把点赞数最多的给我搞下来方便阅读,也许还能做做数据分析(意淫中--) 鉴于之前用python写爬虫,帮运营人员抓取过京东的商品品 ...
- 用正则表达式抓取网页中的ul 和 li标签中最终的值!
获取你要抓取的页面 const string URL = "http://www.hn3ddf.gov.cn/price/GetList.html?pageno=1& ...
- Java版 QQ空间自动登录无需拷贝cookie一天抓取30WQQ说说数据&流程分析
QQ空间说说抓取难度比较大,花了一个星期才研究清楚! 代码请移步到GitHub GitHub地址:https://github.com/20100507/Qzone [没有加入多线程,希望你可以参与进 ...
随机推荐
- HUAS 2017暑假第六周比赛-题解
A.Parenthesis 括号匹配的问题有一种经典的做法. 将左括号看成1,右括号看成-1,做一遍前缀和sum. 括号序列是合法的当且仅当\(sum[n]=Min(sum[1],sum[2].... ...
- Redis 基础:Redis 事件处理
Redis 事件处理 Redis服务器是一个事件驱动程序,服务器需要处理以下两类事件: 文件事件(file event):Redis服务器通过套接字与客户端(或其他Redis服务器)进行连接,而文件事 ...
- BZOJ5212 ZJOI2018历史(LCT)
首先相当于最大化access的轻重边交换次数. 考虑每个点作为战场(而不是每个点所代表的国家与其他国家交战)对答案的贡献,显然每次产生贡献都是该点的子树内(包括自身)此次access的点与上次acce ...
- JUnit中按照顺序执行测试方式
很多情况下,写了一堆的test case,希望某一些test case必须在某个test case之后执行.比如,测试某一个Dao代码,希望添加的case在最前面,然后是修改或者查询,最后才是删除,以 ...
- BZOJ 2194 快速傅立叶变换之二 | FFT
BZOJ 2194 快速傅立叶变换之二 题意 给出两个长为\(n\)的数组\(a\)和\(b\),\(c_k = \sum_{i = k}^{n - 1} a[i] * b[i - k]\). 题解 ...
- Codeforces 914F. Substrings in a String(bitset)
比赛的时候怎么没看这题啊...血亏T T 对每种字符建一个bitset,修改直接改就好了,查询一个区间的时候对查询字符串的每种字符错位and一下,然后用biset的count就可以得到答案了... # ...
- Lnmp上安装Yaf学习(二)
上一节主要实践了在Lnmp上安装Yaf扩展,那么这一节将测试 Yaf 的一个简单demo的运行. 一.通过Lnmp 创建 vhost 文件 [root@localhost yaf-3.0.6]# ln ...
- 目标检测应用化之web页面(YOLO、SSD等)
在caffe源码目录下的examples下面有个web_demo演示代码,其使用python搭建了Flask web服务器进行ImageNet图像分类的演示. 首先安装python的依赖库:pip i ...
- lightoj 1205 数位dp
1205 - Palindromic Numbers PDF (English) Statistics Forum Time Limit: 2 second(s) Memory Limit: 3 ...
- windows下64位python的安装及机器学习相关包的安装(实用)
开通博客已久,想了好久决定写个基础的安装教程,望后人少走弯路,也借此希望跟大家多多交流.文中给出的链接默认是基于对python2.7的前提下的包. 1.首先下载64位Python包,进行安装(默认py ...