Tensorflow学习:(三)神经网络优化
一、完善常用概念和细节
1、神经元模型:
之前的神经元结构都采用线上的权重w直接乘以输入数据x,用数学表达式即 ,但这样的结构不够完善。
,但这样的结构不够完善。
完善的结构需要加上偏置,并加上激励函数。用数学公式表示为: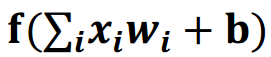 。其中f为激励函数。
。其中f为激励函数。
神经网络就是由以这样的神经元为基本单位构成的。
2、激活函数
引入非线性激活因素,提高模型的表达力。
常用的激活函数有:
(1)relu函数,用 tf.nn.relu()表示
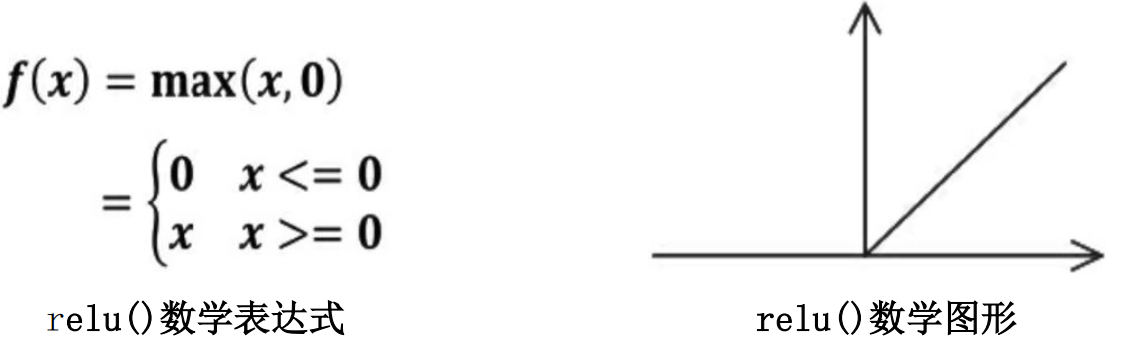
(2)sigmoid函数,用 tf.nn.sigmoid()表示

(3)tanh函数,用 tf.nn.tanh()表示

3、神经网络的复杂度
可以用神经网络的层数和神经网络待优化的参数个数来表示
4、神经网络的层数
层数=n个隐藏层 + 1个输出层
注意:一般不计入输入层
5、神经网络待优化的参数
神经网络所有参数w、b的个数
举例:下图为神经网络示意图
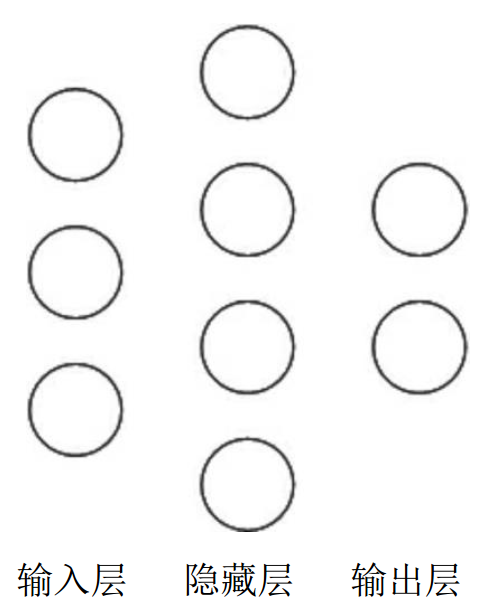
在该神经网络中,包含1个输入层、1个隐藏层和1个输出层,该神经网络的层数为2层。(不计入输入层)
在该神经网络中,参数的个数是所有参数w的个数加上所有参数b的总数,第一层参数用三行四列的二阶张量表示(即12个线上的权重w)再加上4个偏置b;第二层参数是四行两列的二阶张量(即8个线上的权重w)再加上2个偏置b。总参数=3*4+4+4*2+2=26。
二、神经网络优化
上一节讲了神经网络前向传播和后向传播大体框架,这一节讨论神经网络的优化问题。
1、损失函数(loss)
用来表示预测值(y)与已知答案(y_)的差距。在训练神经网络时,通过不断改变神经网络中所有参数,使损失函数不断减小,从而训练出更高准确率的神经网络模型。
常用的损失函数有:
(1)均方误差(mse)
之前的随笔有提到过,所谓均方误差就是n个样本的预测值y与已知答案y_之差的平方和,再求平均值
数学公式为 ,在Tensorflow中表示为 tf.reduce_mean(tf.square(y-y_))
,在Tensorflow中表示为 tf.reduce_mean(tf.square(y-y_))
在本篇文章中我们用一个预测酸奶日销量 y 的例子来验证神经网络优化的效果。x1、x2是影响日销量的两个因素。由于目前没有数据集,所以利用随机函数生成x1、x2,制造标准答案y_=x1+x2,为了更真实,求和后还添加了正负0.05的随机噪声。
选择mse的损失函数,把自制的数据集喂入神经网络,构建神经网络,看训练出来的参数是否和标准答案y_ = x1+x2
代码如下:
import tensorflow as tf
import numpy as np BATCH_SIZE = 8
SEED = 23455 # 构造数据集
rdm = np.random.RandomState(SEED)
X = rdm.rand(32,2)
Y_ = [[x1+x2+(rdm.rand()/10.0-0.05)] for (x1, x2) in X] # rand()会构造0-1的随机数,/10之后构造0-0.1的随机数,0~0.1-0.05相当于构造了-0.05~+0.05的随机数,也就是我们需要的噪声 #1定义神经网络的输入、参数和输出,定义前向传播过程。
x = tf.placeholder(tf.float32, shape=(None, 2))
y_ = tf.placeholder(tf.float32, shape=(None, 1))
w1= tf.Variable(tf.random_normal([2, 1], stddev=1, seed=1))
y = tf.matmul(x, w1) #2定义损失函数及反向传播方法。
#定义损失函数为MSE,反向传播方法为梯度下降。
loss_mse = tf.reduce_mean(tf.square(y_ - y))
train_step = tf.train.GradientDescentOptimizer(0.001).minimize(loss_mse) #3生成会话,训练STEPS轮
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
STEPS = 20000
for i in range(STEPS):
start = (i*BATCH_SIZE) % 32
end = (i*BATCH_SIZE) % 32 + BATCH_SIZE
sess.run(train_step, feed_dict={x: X[start:end], y_: Y_[start:end]})
if i % 500 == 0:
print("After %d training steps, w1 is: " % (i))
print(sess.run(w1), "\n")
print("Final w1 is: \n", sess.run(w1))
最后的训练结果为:
Final w1 is:
[[0.98019385]
[1.0159807 ]]
显然w1、w2是趋近于答案1的。这部分的NN和上一篇笔记没什么太多不一样的地方,只是训练了两个权重而已。
(2)自定义
上面的模型中,损失函数采用的是MSE,但根据事实情况我们知道,销量预测问题不是简单的成本和利润相等问题。如果预测多了,卖不出去,损失的是成本,反之预测少了,损失的是利润,现实情况往往利润和成本是不相等的。因此,需要使用符合该问题的自定义损失函数。
自定义损失函数数学公式为:loss = Σnf(y_,y)
到本问题中可以定义成分段函数:

用tf的函数表示为:loss = tf.reduce_sum(tf.where(tf.greater(y,y_),cost(y-y_),PROFIT(y_-y)))
现在假设酸奶成本为1元,利润为9元,显然希望多预测点,这样我们只需改变上面代码中的损失函数,指定一下cost和profit的值就可以了。代码训练结果为:
Final w1 is:
[[1.0296593]
[1.0484141]]
显然要比单纯的y=x1+x2要多预测。
那么如果现在假设酸奶成本为9元,利润为1元,又会得到怎样的参数呢。训练结果为:
Final w1 is:
[[0.9600407]
[0.9733418]]
显然比y=x1+x2要少预测。这是符合我们想法的。
因此,综上所述,采用自定义损失函数的方法可能更符合预测结果。
(3)交叉熵(Cross Entropy)
表示两个概率分布之间的距离,交叉熵越大,说明两个概率分布距离越远,两个概率分布越相异;
交叉熵越小,说明两个概率分布距离越近,两个概率分布越相似。
交叉熵计算公式为:H(y_,y)=-Σy_ * log10 y
在tf中表示为:ce = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y,1e-12,1.0))) # 确保y<1e-12为1e-2,y>1为1
举一个数学的例子,比如标准答案y_=(1,0)。y1=(0.6,0.4 ) y2=(0.8,0.2),哪个更接近标准答案呢。

但是为了能够将输出变为满足概率分布在(0,1)上,我么们需要使用softmax函数

在tf中,一般让模型的输出经过softmax函数,进而获得输出分类的概率分布,再与标准答案对比,求得交叉熵,得到损失函数,并且有专门的函数。
ce = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
cem = tf.reduce_mean(ce)
这也就代替了ce = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y,1e-12,1.0))) 这句函数
2、学习率
上一篇笔记中有讨论过学习率的问题,得到的大致结论是:学习率过大,会导致待优化参数在最小值附近波动,不收敛;学习率过小,导致训练次数增大,收敛缓慢
在这里我们需要展开讨论有关学习率的问题。
(1)随机梯度下降算法更新参数
首先随机梯度下降方法更新参数的公式为:wn+1=wn - learning_rate * ▽ (▽表示损失函数关于参数的偏导)
如果参数初值为5,学习率为0.2,则参数更新情况为:

再举个例子,如果损失函数为loss=(w+1)2,画出函数图像为:
 能看的出来,如果损失函数使用随机梯度下降优化器,loss的最小值应该是0,此时参数w为-1 。
能看的出来,如果损失函数使用随机梯度下降优化器,loss的最小值应该是0,此时参数w为-1 。
(2)指数衰减学习率
指数衰减学习率就是指学习率会随着训练轮数变化而实现动态更新,它不再是一个定值。
计算公式为:learning_rate = learning_rate_base * learning_rate_decay global_step/learning_rate_step
这里面的概念:
learning_rate_base:学习率基数,一般认为和学习率初始值相等
learning_rate_decay:学习率衰减率,范围是(0,1)
global_step:运行了几轮batch_size
learning_rate_step:多少论更新一次学习率=总样本数/batch_size
在tensorflow中,我们用这样的函数来表示:
首先要有一个值指向当前的训练轮数,这是一个不可训练参数,作为一个“线索”
global_step = tf.Variable(0,trainable=False)
再来就是一个学习率的函数:
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,
LEARNING_RATE_STEP,
LEARNING_RATE_DECAY,
staircase=True/False) # 其他的参数已经在上面提到过,最后一个参数staircase,当设置为True时,表示global_step/learning_rate_step取整数,学习率阶梯型衰减;若为False,学习率是一条平滑下降的曲线。
在代码中展示指数衰减学习率:
#设损失函数 loss=(w+1)^2, 令w初值是常数10。反向传播就是求最优w,即求最小loss对应的w值
#使用指数衰减的学习率,在迭代初期得到较高的下降速度,可以在较小的训练轮数下取得更有收敛度。
import tensorflow as tf LEARNING_RATE_BASE = 0.1 #最初学习率
LEARNING_RATE_DECAY = 0.99 #学习率衰减率
LEARNING_RATE_STEP = 1 #喂入多少轮BATCH_SIZE后,更新一次学习率,一般设为:总样本数/BATCH_SIZE #运行了几轮BATCH_SIZE的计数器,初值给0, 设为不被训练
global_step = tf.Variable(0, trainable=False)
#定义指数下降学习率
learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE, global_step, LEARNING_RATE_STEP, LEARNING_RATE_DECAY, staircase=True)
#定义待优化参数,初值给10
w = tf.Variable(tf.constant(10, dtype=tf.float32))
#定义损失函数loss
loss = tf.square(w+1)
#定义反向传播方法
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
#生成会话,训练40轮
with tf.Session() as sess:
init_op=tf.global_variables_initializer()
sess.run(init_op)
for i in range(40):
sess.run(train_step)
learning_rate_val = sess.run(learning_rate)
global_step_val = sess.run(global_step) # global_step也要放在会话中运行,要不然怎么更新
w_val = sess.run(w)
loss_val = sess.run(loss)
print("After %s steps: global_step is %f, w is %f, learning rate is %f, loss is %f" % (i, global_step_val, w_val, learning_rate_val, loss_val))
运行显示结果为
After 0 steps: global_step is 1.000000, w is 7.800000, learning rate is 0.099000, loss is 77.440002
After 1 steps: global_step is 2.000000, w is 6.057600, learning rate is 0.098010, loss is 49.809719
After 2 steps: global_step is 3.000000, w is 4.674170, learning rate is 0.097030, loss is 32.196201
After 3 steps: global_step is 4.000000, w is 3.573041, learning rate is 0.096060, loss is 20.912704
After 4 steps: global_step is 5.000000, w is 2.694472, learning rate is 0.095099, loss is 13.649124
After 5 steps: global_step is 6.000000, w is 1.991791, learning rate is 0.094148, loss is 8.950812
After 6 steps: global_step is 7.000000, w is 1.428448, learning rate is 0.093207, loss is 5.897362
After 7 steps: global_step is 8.000000, w is 0.975754, learning rate is 0.092274, loss is 3.903603
After 8 steps: global_step is 9.000000, w is 0.611131, learning rate is 0.091352, loss is 2.595742
After 9 steps: global_step is 10.000000, w is 0.316771, learning rate is 0.090438, loss is 1.733887
After 10 steps: global_step is 11.000000, w is 0.078598, learning rate is 0.089534, loss is 1.163375
After 11 steps: global_step is 12.000000, w is -0.114544, learning rate is 0.088638, loss is 0.784033
After 12 steps: global_step is 13.000000, w is -0.271515, learning rate is 0.087752, loss is 0.530691
After 13 steps: global_step is 14.000000, w is -0.399367, learning rate is 0.086875, loss is 0.360760
After 14 steps: global_step is 15.000000, w is -0.503726, learning rate is 0.086006, loss is 0.246287
After 15 steps: global_step is 16.000000, w is -0.589091, learning rate is 0.085146, loss is 0.168846
After 16 steps: global_step is 17.000000, w is -0.659066, learning rate is 0.084294, loss is 0.116236
After 17 steps: global_step is 18.000000, w is -0.716543, learning rate is 0.083451, loss is 0.080348
After 18 steps: global_step is 19.000000, w is -0.763853, learning rate is 0.082617, loss is 0.055765
After 19 steps: global_step is 20.000000, w is -0.802872, learning rate is 0.081791, loss is 0.038859
After 20 steps: global_step is 21.000000, w is -0.835119, learning rate is 0.080973, loss is 0.027186
After 21 steps: global_step is 22.000000, w is -0.861821, learning rate is 0.080163, loss is 0.019094
After 22 steps: global_step is 23.000000, w is -0.883974, learning rate is 0.079361, loss is 0.013462
After 23 steps: global_step is 24.000000, w is -0.902390, learning rate is 0.078568, loss is 0.009528
After 24 steps: global_step is 25.000000, w is -0.917728, learning rate is 0.077782, loss is 0.006769
After 25 steps: global_step is 26.000000, w is -0.930527, learning rate is 0.077004, loss is 0.004827
After 26 steps: global_step is 27.000000, w is -0.941226, learning rate is 0.076234, loss is 0.003454
After 27 steps: global_step is 28.000000, w is -0.950187, learning rate is 0.075472, loss is 0.002481
After 28 steps: global_step is 29.000000, w is -0.957706, learning rate is 0.074717, loss is 0.001789
After 29 steps: global_step is 30.000000, w is -0.964026, learning rate is 0.073970, loss is 0.001294
After 30 steps: global_step is 31.000000, w is -0.969348, learning rate is 0.073230, loss is 0.000940
After 31 steps: global_step is 32.000000, w is -0.973838, learning rate is 0.072498, loss is 0.000684
After 32 steps: global_step is 33.000000, w is -0.977631, learning rate is 0.071773, loss is 0.000500
After 33 steps: global_step is 34.000000, w is -0.980842, learning rate is 0.071055, loss is 0.000367
After 34 steps: global_step is 35.000000, w is -0.983565, learning rate is 0.070345, loss is 0.000270
After 35 steps: global_step is 36.000000, w is -0.985877, learning rate is 0.069641, loss is 0.000199
After 36 steps: global_step is 37.000000, w is -0.987844, learning rate is 0.068945, loss is 0.000148
After 37 steps: global_step is 38.000000, w is -0.989520, learning rate is 0.068255, loss is 0.000110
After 38 steps: global_step is 39.000000, w is -0.990951, learning rate is 0.067573, loss is 0.000082
After 39 steps: global_step is 40.000000, w is -0.992174, learning rate is 0.066897, loss is 0.000061
根据损失函数的公式,我们知道理论上w在-1时,loss取最小值为0.显然结果是符合理论的。
这里留下一个待解决的问题,改变指数衰减学习率公式中的几个参数, 会对训练次数,权重更新,学习率,损失值分别有什么影响?
3、滑动平均(影子)
滑动平均值(也有人称为影子值),记录了一段时间内模型中所有的参数w和b各自的平均值。使用影子值可以增强模型的泛化能力。就感觉是给参数加了影子,参数变化,影子缓慢跟随。
影子 = 衰减率*影子 + (1-衰减率)*参数
其中,影子初值 = 参数初值;衰减率 = min{moving_average_decay , (1+轮数)/(10+轮数) }
例如,moving_average_decay赋值为0.99,参数w设置为0,影子值为0
(1) 开始时,训练轮数为0,参数更新为1,则w的影子值为:
影子 = min(0.99,1/10)*0+(1-min(0.99,1/10))*1=0.9
(2) 当训练轮数为100时,参数w更新为10,则w的影子值为:
影子 = min(0.99,101/110)*0.9+(1– min(0.99,101/110)*10 = 0.826+0.818=1.644
(3) 当训练轮数为100时,参数w更新为1.644,则w的影子值为:
影子 = min(0.99,101/110)*1.644+(1– min(0.99,101/110)*10 = 2.328
(4) 当训练轮数为100时,参数w更新为2.328,则w的影子值为:
影子 = 2.956
用tensorflow函数可以表示为以下内容:(相关注释在完整代码中写)
ema = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
ema_op = ema.apply(tf.trainable_variables())
with tf.control_dependencies([train_step, ema_op]):
train_op = tf.no_op(name='train')
所以上面的例子用完整的滑动平均代码为:
import tensorflow as tf # 1. 定义变量及滑动平均类
# 定义一个32位浮点变量,初始值为0.0 这个代码就是不断更新w1参数,优化w1参数,滑动平均做了个w1的影子
w1 = tf.Variable(0, dtype=tf.float32)
# 定义num_updates(NN的迭代轮数),初始值为0,不可被优化(训练),这个参数不训练
global_step = tf.Variable(0, trainable=False)
# 实例化滑动平均类,给衰减率为0.99,一般赋值为接近1的值
MOVING_AVERAGE_DECAY = 0.99
ema = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step) # ema.apply后的括号里是更新列表,每次运行sess.run(ema_op)时,对更新列表中的元素求滑动平均值。
# ema.apply()函数实现对括号内参数求滑动平均
# 在实际应用中会使用tf.trainable_variables()自动将所有待训练的参数汇总为列表
# ema_op = ema.apply([w1])
ema_op = ema.apply(tf.trainable_variables()) # 2. 查看不同迭代中变量取值的变化。
with tf.Session() as sess:
# 初始化
init_op = tf.global_variables_initializer()
sess.run(init_op)
# 用ema.average(w1)获取w1滑动平均值 (要运行多个节点,作为列表中的元素列出,写在sess.run中)
# 打印出当前参数w1和w1滑动平均值
print("current global_step:", sess.run(global_step))
print("current w1", sess.run([w1, ema.average(w1)])) # 参数w1的值赋为1
sess.run(tf.assign(w1, 1))
sess.run(ema_op)
print("current global_step:", sess.run(global_step))
print("current w1", sess.run([w1, ema.average(w1)])) # 更新global_step和w1的值,模拟出轮数为100时,参数w1变为10, 以下代码global_step保持为100,每次执行滑动平均操作,影子值会更新
sess.run(tf.assign(global_step, 100))
sess.run(tf.assign(w1, 10))
sess.run(ema_op)
print("current global_step:", sess.run(global_step))
print("current w1:", sess.run([w1, ema.average(w1)])) # 每次sess.run会更新一次w1的滑动平均值
sess.run(ema_op)
print("current global_step:", sess.run(global_step))
print("current w1:", sess.run([w1, ema.average(w1)])) sess.run(ema_op)
print("current global_step:", sess.run(global_step))
print("current w1:", sess.run([w1, ema.average(w1)]))
多次执行训练轮数为100的ema_op,观察影子值,运行结果为:
current global_step: 0
current w1 [0.0, 0.0]
current global_step: 0
current w1 [1.0, 0.9]
current global_step: 100
current w1: [10.0, 1.6445453]
current global_step: 100
current w1: [10.0, 2.3281732]
current global_step: 100
current w1: [10.0, 2.955868]
current global_step: 100
current w1: [10.0, 3.532206]
current global_step: 100
current w1: [10.0, 4.061389]
current global_step: 100
current w1: [10.0, 4.547275]
current global_step: 100
current w1: [10.0, 4.9934072]
能够看得出来,训练轮数不变的时候,影子值一直在逼近于10,说明影子值随参数的改变而改变。有一个“影子追随“的感觉。
4、正则化
正则化是解决神经网络过拟合的有效方法。自然要先提一下过拟合问题。
过拟合:神经网络模型在训练集上准确率高,在测试集进行预测或分类时准确率吧较低,说明模型的泛化能力差
正则化:在损失函数中给每个参数w加上权重,引入模型复杂度指标,从而抑制模型噪声,减小过拟合。
根据正则化的定义,我们可以得出新的损失函数值:、
loss = loss(y-y_) + regularizer* loss(w) 第一项是预测结果与标准答案的差距,第二项是正则化计算结果
正则化有两种计算方法:
(1)L1正则化:lossL1 = ∑i |wi| , tf函数表示为:loss(w) = tf.contrib.layers.l1_regularizer(regularizer)(w)
(2)L2正则化:lossL2 = ∑i |wi|2 , tf函数表示为:loss(w) = tf.contrib.layers.l2_regularizer(regularizer)(w)
正则化实现用tensorflow可以表示为:
tf.add_to_collection('losses', tf.contrib.layers.l2_regularizer(regularizer)(w)
loss = cem + tf.add_n(tf.get_collection('losses')) # cem即交叉熵损失函数的值
举例:
随机生成300个符合正态分布的点(x0,x1),当x02+x12<2 时,y_=1,标注为红色,x02+x12≥2时,y_=0,标注为蓝色。使用matplotlib模块分别画出无正则化和有正则化的拟合曲线
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt BATCH_SIZE = 30
seed = 2
# 基于seed产生随机数
rdm = np.random.RandomState(seed)
# 随机数返回300行2列的矩阵,表示300组坐标点(x0,x1)作为输入数据集
# randn()函数是从正态分布中返回样本值,rand()函数是从(0,1)中返回样本值
X = rdm.randn(300, 2)
# 从X这个300行2列的矩阵中取出一行,判断如果两个坐标的平方和小于2,给Y赋值1,其余赋值0
# 作为输入数据集的标签(正确答案)
Y_ = [int(x0 * x0 + x1 * x1 < 2) for (x0, x1) in X]
# 遍历Y中的每个元素,1赋值'red'其余赋值'blue',这样可视化显示时人可以直观区分
Y_c = [['red' if y else 'blue'] for y in Y_]
# 对数据集X和标签Y进行shape整理,第一个元素为-1表示,随第二个参数计算得到,第二个元素表示多少列,把X整理为n行2列,把Y整理为n行1列
X = np.vstack(X).reshape(-1, 2)
Y_ = np.vstack(Y_).reshape(-1, 1)
print(X)
print(Y_)
print(Y_c)
# 用plt.scatter画出数据集X各行中第0列元素和第1列元素的点即各行的(x0,x1),用各行Y_c对应的值表示颜色(c是color的缩写)
plt.scatter(X[:, 0], X[:, 1], c=np.squeeze(Y_c))
plt.show() # 定义神经网络的输入、参数和输出,定义前向传播过程
def get_weight(shape, regularizer):
w = tf.Variable(tf.random_normal(shape), dtype=tf.float32)
tf.add_to_collection('losses', tf.contrib.layers.l2_regularizer(regularizer)(w))
return w def get_bias(shape):
b = tf.Variable(tf.constant(0.01, shape=shape))
return b x = tf.placeholder(tf.float32, shape=(None, 2))
y_ = tf.placeholder(tf.float32, shape=(None, 1)) w1 = get_weight([2, 11], 0.01)
b1 = get_bias([11])
y1 = tf.nn.relu(tf.matmul(x, w1) + b1) w2 = get_weight([11, 1], 0.01)
b2 = get_bias([1])
y = tf.matmul(y1, w2) + b2 # 定义损失函数
loss_mse = tf.reduce_mean(tf.square(y - y_))
loss_total = loss_mse + tf.add_n(tf.get_collection('losses')) # 定义反向传播方法:不含正则化
train_step = tf.train.AdamOptimizer(0.0001).minimize(loss_mse) with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
STEPS = 40000
for i in range(STEPS):
start = (i * BATCH_SIZE) % 300
end = start + BATCH_SIZE
sess.run(train_step, feed_dict={x: X[start:end], y_: Y_[start:end]})
if i % 2000 == 0:
loss_mse_v = sess.run(loss_mse, feed_dict={x: X, y_: Y_})
print("After %d steps, loss is: %f" % (i, loss_mse_v))
# xx在-3到3之间以步长为0.01,yy在-3到3之间以步长0.01,生成二维网格坐标点
xx, yy = np.mgrid[-3:3:.01, -3:3:.01]
# 将xx , yy拉直,并合并成一个2列的矩阵,得到一个网格坐标点的集合
grid = np.c_[xx.ravel(), yy.ravel()]
# 将网格坐标点喂入神经网络 ,probs为输出
probs = sess.run(y, feed_dict={x: grid})
# probs的shape调整成xx的样子
probs = probs.reshape(xx.shape)
print("w1:\n", sess.run(w1))
print("b1:\n", sess.run(b1))
print("w2:\n", sess.run(w2))
print("b2:\n", sess.run(b2)) plt.scatter(X[:, 0], X[:, 1], c=np.squeeze(Y_c))
plt.contour(xx, yy, probs, levels=[.5])
plt.show() # 定义反向传播方法:包含正则化
train_step = tf.train.AdamOptimizer(0.0001).minimize(loss_total) with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
STEPS = 40000
for i in range(STEPS):
start = (i * BATCH_SIZE) % 300
end = start + BATCH_SIZE
sess.run(train_step, feed_dict={x: X[start:end], y_: Y_[start:end]})
if i % 2000 == 0:
loss_v = sess.run(loss_total, feed_dict={x: X, y_: Y_}) # 与未正则化相比,这个地方的loss_mse换成了loss_total
print("After %d steps, loss is: %f" % (i, loss_v)) xx, yy = np.mgrid[-3:3:.01, -3:3:.01]
grid = np.c_[xx.ravel(), yy.ravel()]
probs = sess.run(y, feed_dict={x: grid})
probs = probs.reshape(xx.shape)
print("w1:\n", sess.run(w1))
print("b1:\n", sess.run(b1))
print("w2:\n", sess.run(w2))
print("b2:\n", sess.run(b2)) plt.scatter(X[:, 0], X[:, 1], c=np.squeeze(Y_c))
plt.contour(xx, yy, probs, levels=[.5])
plt.show()
分别画出有无正则化的图
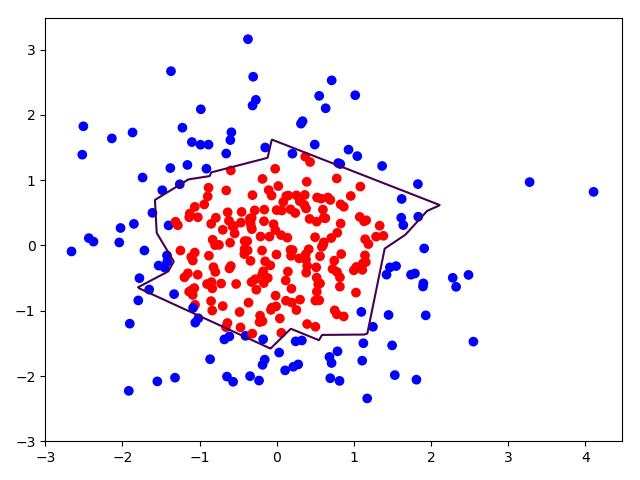

右图加入了正则化,显然正则化模型的拟合曲线平滑,泛化能力强一点。
留下待解决问题,更改正则化参数,观察拟合变化?
本人初学者,有任何错误欢迎指出,谢谢。
Tensorflow学习:(三)神经网络优化的更多相关文章
- TensorFlow学习笔记(二)深层神经网络
一.深度学习与深层神经网络 深层神经网络是实现“多层非线性变换”的一种方法. 深层神经网络有两个非常重要的特性:深层和非线性. 1.1线性模型的局限性 线性模型:y =wx+b 线性模型的最大特点就是 ...
- tensorflow学习笔记——常见概念的整理
TensorFlow的名字中已经说明了它最重要的两个概念——Tensor和Flow.Tensor就是张量,张量这个概念在数学或者物理学中可以有不同的解释,但是这里我们不强调它本身的含义.在Tensor ...
- TensorFlow学习笔记——深层神经网络的整理
维基百科对深度学习的精确定义为“一类通过多层非线性变换对高复杂性数据建模算法的合集”.因为深层神经网络是实现“多层非线性变换”最常用的一种方法,所以在实际中可以认为深度学习就是深度神经网络的代名词.从 ...
- tensorflow学习笔记——使用TensorFlow操作MNIST数据(2)
tensorflow学习笔记——使用TensorFlow操作MNIST数据(1) 一:神经网络知识点整理 1.1,多层:使用多层权重,例如多层全连接方式 以下定义了三个隐藏层的全连接方式的神经网络样例 ...
- tensorflow学习笔记——图像识别与卷积神经网络
无论是之前学习的MNIST数据集还是Cifar数据集,相比真实环境下的图像识别问题,有两个最大的问题,一是现实生活中的图片分辨率要远高于32*32,而且图像的分辨率也不会是固定的.二是现实生活中的物体 ...
- tensorflow学习笔记——自编码器及多层感知器
1,自编码器简介 传统机器学习任务很大程度上依赖于好的特征工程,比如对数值型,日期时间型,种类型等特征的提取.特征工程往往是非常耗时耗力的,在图像,语音和视频中提取到有效的特征就更难了,工程师必须在这 ...
- tensorflow学习笔记——使用TensorFlow操作MNIST数据(1)
续集请点击我:tensorflow学习笔记——使用TensorFlow操作MNIST数据(2) 本节开始学习使用tensorflow教程,当然从最简单的MNIST开始.这怎么说呢,就好比编程入门有He ...
- 【零基础】神经网络优化之Adam
一.序言 Adam是神经网络优化的另一种方法,有点类似上一篇中的“动量梯度下降”,实际上是先提出了RMSprop(类似动量梯度下降的优化算法),而后结合RMSprop和动量梯度下降整出了Adam,所以 ...
- TensorFlow学习笔记10-卷积网络
卷积网络 卷积神经网络(Convolutional Neural Network,CNN)专门处理具有类似网格结构的数据的神经网络.如: 时间序列数据(在时间轴上有规律地采样形成的一维网格): 图像数 ...
随机推荐
- GitHub更新已经fork的项目
clone 自己的 fork 分支到本地 可以直接使用 GitHub 客户端,clone 到本地,如果使用命令行,命令为: $ git clone git@github.com:morethink/g ...
- MapReduce (MRV1)设计理念与基本架构
MapReduce 是一个分布式计算框架,主要由两部分组成:编程模型和运行时环境. 其中,编程模型为用户提供了非常易用的编程接口,用户只需要像编写串行程序一样实现几个简单的函数即可实现一个分布式程序, ...
- anonymous namespace V.S. static variant
[anonymous namespace V.S. static variant] 在C语言中,如果我们在多个tu(translation unit)中使用了同一个名字做为函数名或者全局变量名,则在链 ...
- SQL Server 数据库备份失败解决方法
问题:System.Data.SqlClient.SqlError: 无法使用备份文件 'D:\20160512.bak',因为原先格式化该文件时所用扇区大小为 512,而目前所在设备的扇区大小为 4 ...
- python实现梯度下降法
# coding:utf-8 import numpy as np import matplotlib.pyplot as plt x = np.arange(-5/2,5/2,0.01) y = - ...
- 2015.07.15——prime素数
prime素数 1.素数也叫质数,定义是一个数只能被1和它自身整除. 素数从2开始,0,1都不是素数. 2.素数的判断(C++) 3.给定某个数,求小于这个数的所有素数 2.素数的判断(C++) bo ...
- 重写Java Object对象的hashCode和equals方法实现集合元素按内容判重
Java API提供的集合框架中Set接口下的集合对象默认是不能存储重复对象的,这里的重复判定是按照对象实例句柄的地址来判定的,地址相同则判定为重复,地址不同不管内容如何都判定为不重复,这有时与需求不 ...
- Oracle基础结构认知—初识oracle【转】
Oracle服务器(oracle server)由实例和数据库组成.其中,实例就是所谓的关系型数据库管理系统(Relational Database Management System,RDBMS), ...
- 深入理解MySQL的并发控制、锁和事务【转】
本文主要是针对MySQL/InnoDB的并发控制和加锁技术做一个比较深入的剖析,并且对其中涉及到的重要的概念,如多版本并发控制(MVCC),脏读(dirty read),幻读(phantom read ...
- 记录一款Unity VR视频播放器插件的开发
效果图 先上一个效果图: 背景 公司最近在做VR直播平台,VR开发我们用到了Unity,而在Unity中播放视频就需要一款视频插件,我们调研了几个视频插件,记录两个,如下: Unity视频插件调研 网 ...