如何用elasticsearch构架亿级数据采集系统(第1集:非生产环境windows安装篇)
(一)做啥的?
基于Elasticsearch,可以为实现,大数据量(亿级)的实时统计查询的方案设计,提供底层数据框架。
本小节jacky会在非生产环境下,在 window 系统下,给大家分享着部分的相关内容。
(二)Elasticsearch的安装
2.1 版本选择:elasticsearch-rtf
第1步:安装java
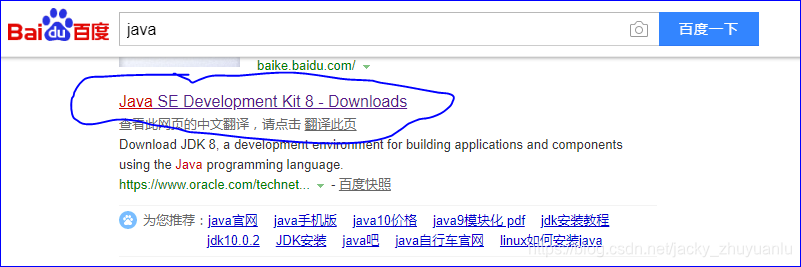
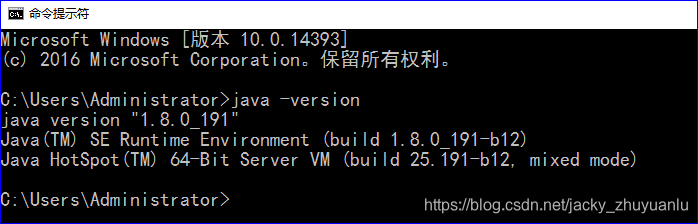
验证java是否安装成功:
- 这里java要兼容elasticsearch,必须安装java8以上的版本
- 这里java要兼容elasticsearch,必须安装java8以上的版本
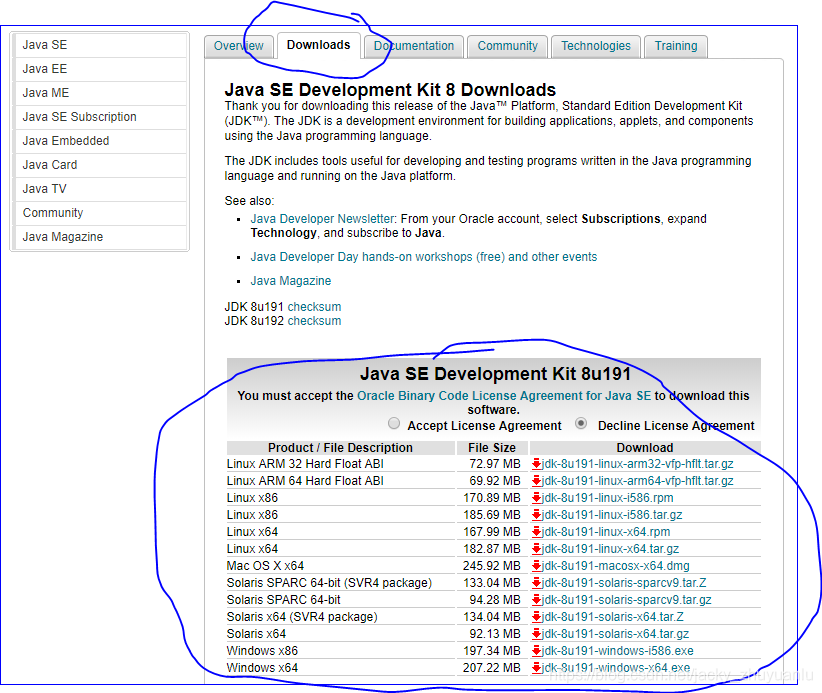
第2步:下载elasticsearch-rtf
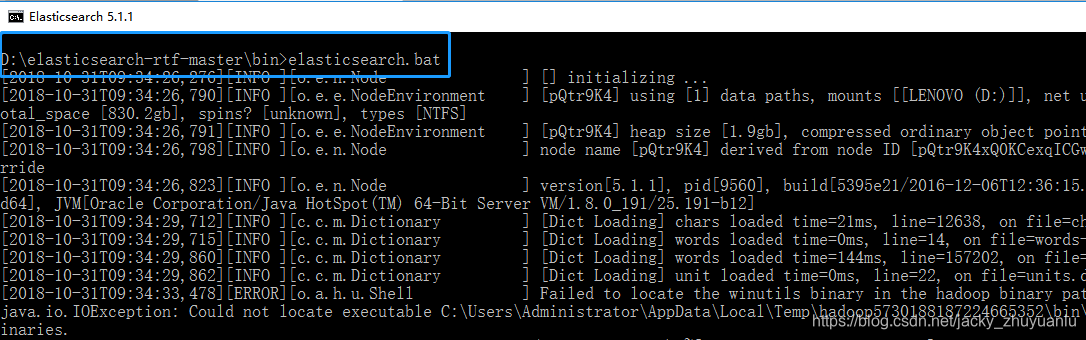
第3步:在bin目录下用命令行安装elasticsearch
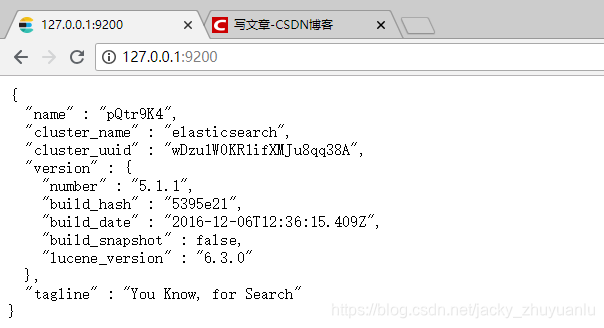
第4步:查看9200访问接口,如果看到以下界面,说明我们的elasticsearch就安装成功了
(三)head 插件的安装
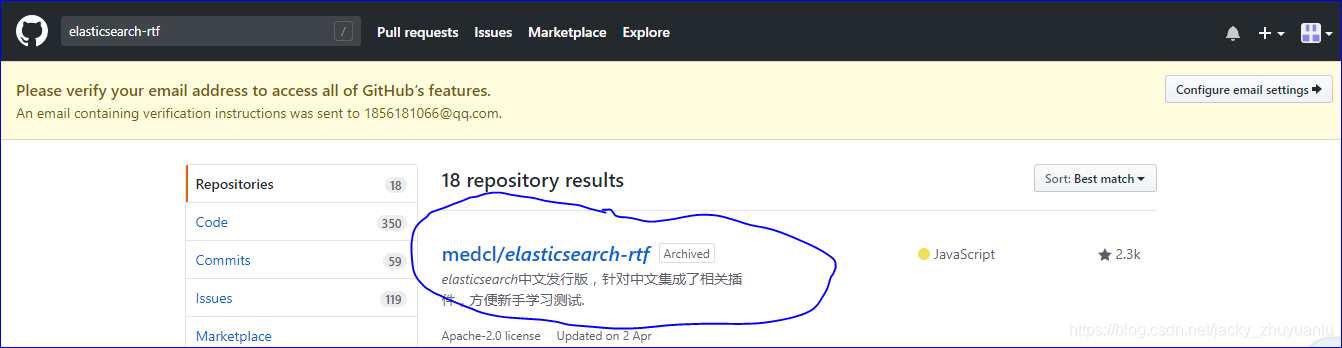
第1步,在github中下载head插件
第二步:下载npm
- 下载安装npm的前置环境-nodejs
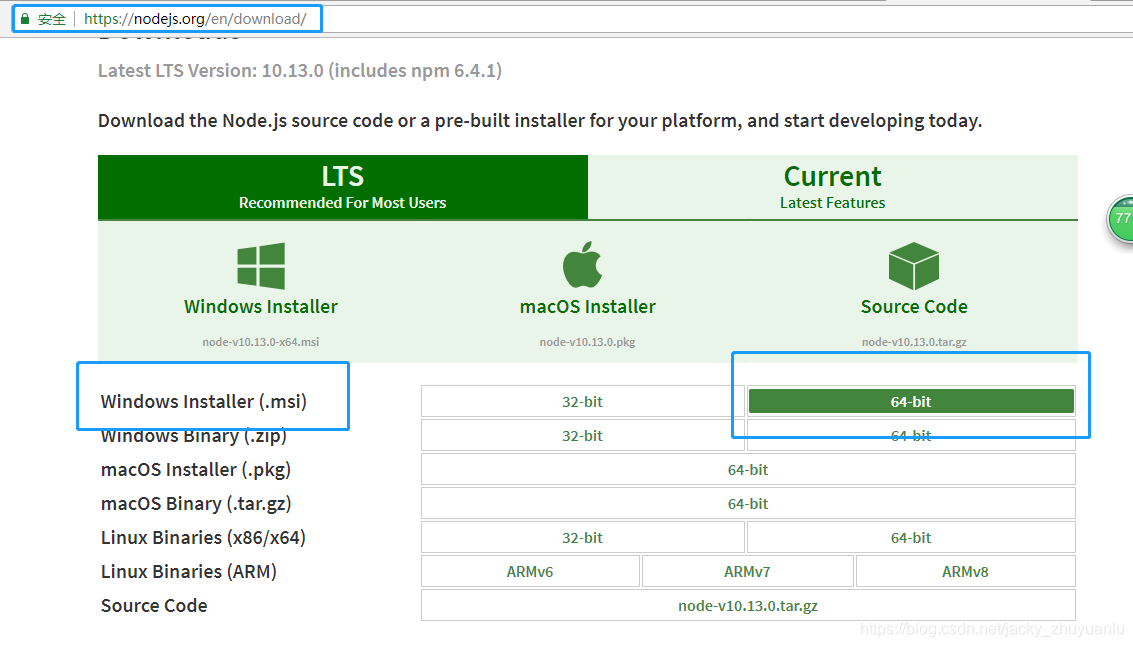
- 下载安装npm的前置环境-nodejs
验证npm是否下载成功
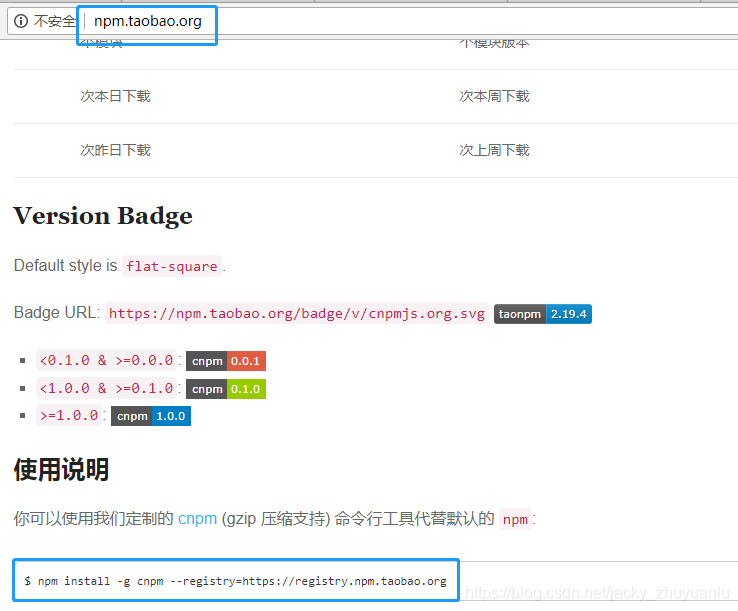
第三步:安装cnpm
npm就相当于python中的pip,中央仓库在国外,下载速度极慢,所以选择淘宝镜像的cnpm代替npm;
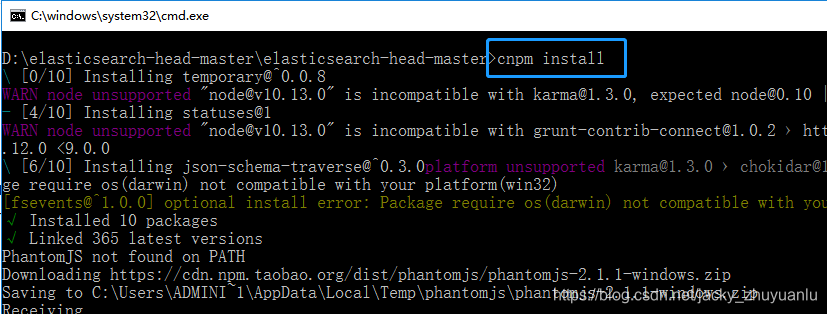
第4步:安装head插件
第5步 : 运行head插件
- head 文件下:cnpm run start

- head 文件下:cnpm run start
elasticsearch安全策略规定:elasitcsearch默认不允许使用第三方的服务,为了可以满足head这个代理服务可以访问elasticsearch,我们要对elasticsearch进行一些配置上的改动;
第6步 : 重新配置elasticsearch
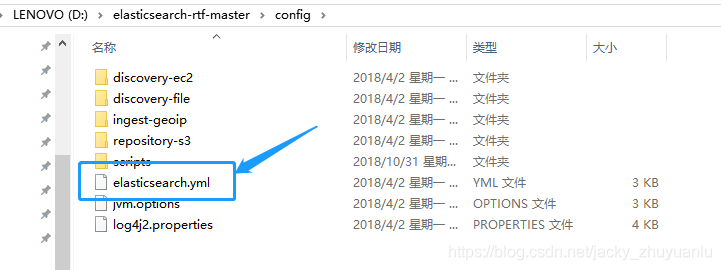
我们看到显示未连接,我们需要配置elasticsearch-rtf(搜索引擎)连接,在elasticsearch-rtf/config/elasticsearch.yml 这个文件里配置,在文件的最后面写入:
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-methods: OPTIONS, HEAD, GET, POST, PUT, DELETE
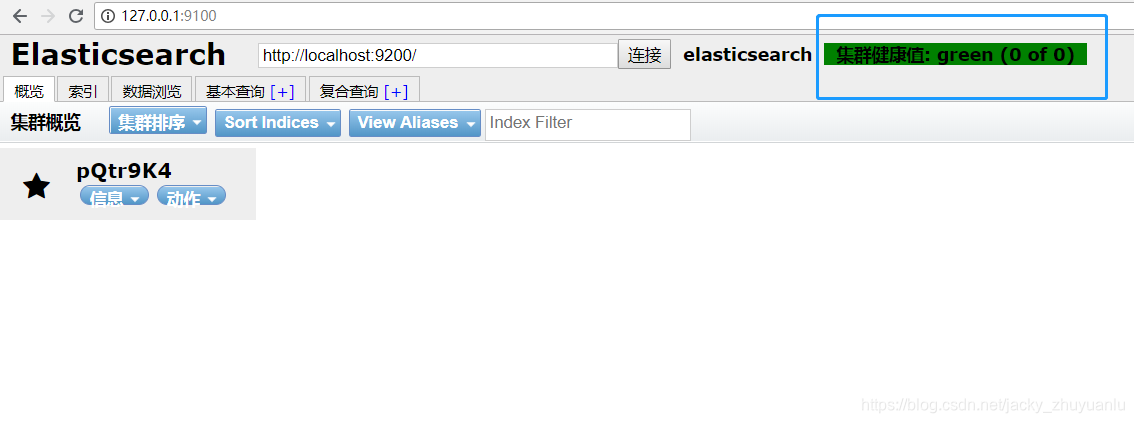
- 第7步:重启elasticsearch-rtf(搜索引擎)后就可以连接了
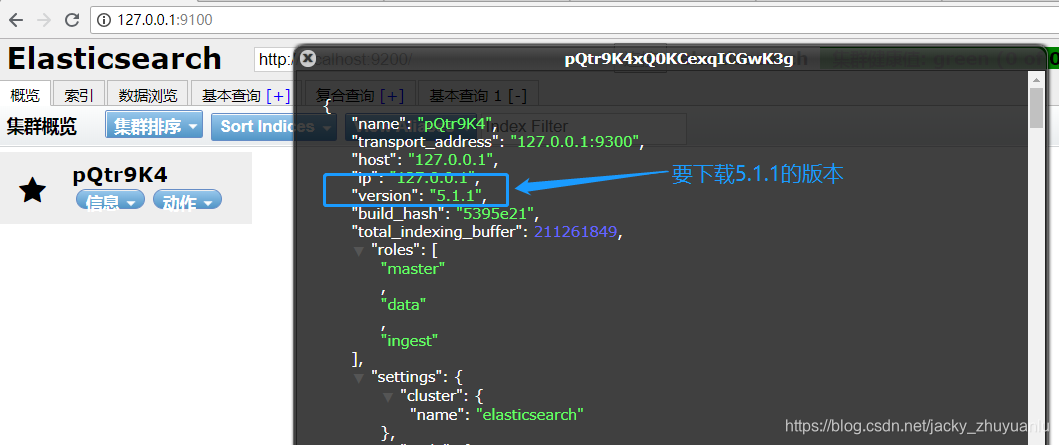
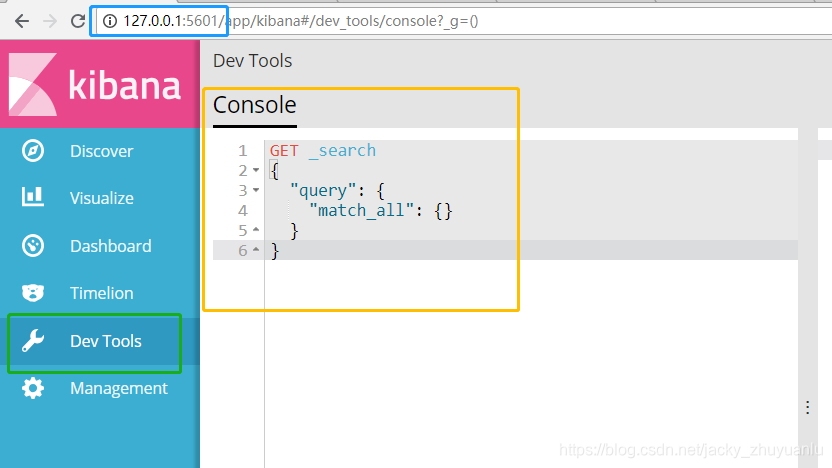
(四)Kibana 插件的安装
- 注意:Kibana的版本要对应elasticsearch-head里信息里的版本
如何用elasticsearch构架亿级数据采集系统(第1集:非生产环境windows安装篇)的更多相关文章
- MySQL使用pt-online-change-schema工具在线修改1.6亿级数据表结构
摘 要:本文阐述了MySQL DDL 的问题现状.pt-online-schema-change的工作原理,并实际利用pt-online-schema-change工具在线修改生产环境下1.6亿级数 ...
- 通用技术 mysql 亿级数据优化
通用技术 mysql 亿级数据优化 一定要正确设计索引 一定要避免SQL语句全表扫描,所以SQL一定要走索引(如:一切的 > < != 等等之类的写法都会导致全表扫描) 一定要避免 lim ...
- 不停机不停服务,MYSQL可以这样修改亿级数据表结构
摘 要:本文阐述了MySQL DDL 的问题现状.pt-online-schema-change的工作原理,并实际利用pt-online-schema-change工具在线修改生产环境下1.6亿级数 ...
- 基于Mysql数据库亿级数据下的分库分表方案
移动互联网时代,海量的用户数据每天都在产生,基于用户使用数据的用户行为分析等这样的分析,都需要依靠数据都统计和分析,当数据量小时,问题没有暴露出来,数据库方面的优化显得不太重要,一旦数据量越来越大时, ...
- Mongodb亿级数据量的性能测试
进行了一下Mongodb亿级数据量的性能测试,分别测试如下几个项目: (所有插入都是单线程进行,所有读取都是多线程进行) 1) 普通插入性能 (插入的数据每条大约在1KB左右) 2) 批量插入性能 ...
- 巧用redis位图存储亿级数据与访问 - 简书
原文:巧用redis位图存储亿级数据与访问 - 简书 业务背景 现有一个业务需求,需要从一批很大的用户活跃数据(2亿+)中判断用户是否是活跃用户.由于此数据是基于用户的各种行为日志清洗才能得到,数据部 ...
- NEO4J亿级数据导入导出以及数据更新
1.添加配置 apoc.export.file.enabled=true apoc.import.file.enabled=true dbms.directories.import=import db ...
- NEO4J亿级数据全文索引构建优化
NEO4J亿级数据全文索引构建优化 一.数据量规模(亿级) 二.构建索引的方式 三.构建索引发生的异常 四.全文索引代码优化 1.Java.lang.OutOfMemoryError 2.访问数据库时 ...
- Mybatis 使用分页查询亿级数据 性能问题 DB使用ORACLE
一般用到了mybatis框架分页就不用自己写了 直接用RowBounds对象就可以实现,但这个性能确实很低 今天我用到10w级得数据分页查询,到后面几页就迭代了很慢 用于记录 1.10万级数据如下 [ ...
随机推荐
- 【洛谷 P2408】 不同子串个数(后缀自动机)
题目链接 裸体就是身体. 建出\(SAM\),\(DAG\)上跑\(DP\),\(f[u]=1+\sum_{(u,v)\in DAG}f[v]\) 答案为\(f[1]-1\)(因为根节点没有字符) # ...
- 如何方便引用自己的python包
有时候想要把一些功能封装成函数然后包装到模块里面最后形成一个包,然后在notebook里面去引用它去处理自己的数据和分析一些有用的部分,比如自己在 之前用到的一个datascience模板就是这样组织 ...
- Mysql 存储过程 + python调用存储过程 (内置函数讲解及定义摘抄)
定义 存储过程:就是为以后的使用而保存的一条或多条 MySQL语句的集合.可将其视为批文件,虽然它们的作用不仅限于批处理. 个人使用存储过程的原因就是因为 存储过程比使用单独的SQL语句要快 有如下表 ...
- LNMP - Warning: require(): open_basedir restriction in effect错误解决方法
LNMP 1.4或更高版本如果不想用防跨目录或者修改.user.ini的防跨目录的目录还需要将 /usr/local/nginx/conf/fastcgi.conf 里面的fastcgi_param ...
- Android笔记(四十五) Android中的数据存储——XML(一)DOM解析器
DOM解析XML在j2ee开发中比较常见,在Dom解析的过程中,是先把dom全部文件读入到内存中,然后使用dom的api遍历所有数据,检索想要的数据,这种方式显然是一种比较消耗内存的方式,对于像手机这 ...
- 基于335X平台Linux交换芯片驱动开发
基于335X平台Linux交换芯片驱动开发 一.软硬件平台资料 1.开发板:创龙AM3359核心板,网口采用RMII形式. 2.Kernel版本:4.4.12,采用FDT 3.交换芯片MARVEL ...
- CentOS7使用阿里yum源安装Docker
yum install -y yum-utils device-mapper-persistent-data lvm2安装所需的包 # yum-config-manager --add-repo ht ...
- 51nod 2497 数三角形
小b有一个仅包含非负整数的数组a,她想知道有多少个三元组(i,j,k),满足i<j<k且a[i],a[j],a[k]可能作为某个三角形的三条边的边长. 收起 输入 第一行输入一个正整数 ...
- CH6401 创世纪
6401 创世纪 0x60「图论」例题 描述 上帝手中有 N(N≤10^6) 种世界元素,每种元素可以限制另外1种元素,把第 i 种世界元素能够限制的那种世界元素记为 A[i].现在,上帝要把它们中的 ...
- iptables常用命令二之如何删除nat规则
删除iptables nat 规则 删除FORWARD 规则: iptables -nL FORWARD --line-number iptables -D FORWARD 1 删除一条nat 规则 ...