【python爬虫】每天统计一遍up主粉丝数!
每天统计一遍up主粉丝数!
第一步,爬取up主的粉丝信息
为了方便,这里我把它写成了一个函数
1.首先导入需要的包
requests是必不可少的!
import requests as req
想要记录下统计的时间,那么就需要用到相应的时间函数
from time import strftime, localtime
2.为了方便,把它写成一个函数
接收两个参数,分别为up主的mid和自定义名字,mid就是up主个人空间网页地址栏最后的那串数字。没有自定义名字的话,会自动显示成mid的,这点不用担心哦~

def fans(mid, name=-1):
mid = str(mid)
name = str(name)
if name == -1:
name = mid
url = "https://api.bilibili.com/x/relation/stat?vmid=" + mid + "&jsonp=jsonp"
resp = req.get(url)# 通过url爬取到我们想要的json数据
info = eval(resp.text)
with open(name + '粉丝数统计.txt', 'a') as f:
f.write(strftime("%Y", localtime()) + "年" + strftime("%m", localtime()) + "月" + strftime("%d",
localtime()) + "日" + name + "粉丝数:" + str(
info['data']['follower']) + '\n')# 获取data中的follower就是粉丝数啦
print(strftime("%Y", localtime()) + "年" + strftime("%m", localtime()) + "月" + strftime("%d",
localtime()) + "日" + name + "粉丝数:" + str(
info['data']['follower']) + '\n')
3.那么就调用一下这个函数吧!
if __name__ == "__main__":
fans(36874384, '谜叔录播机')
fans(673816, "谜之声")
4.运行一下,成功啦!
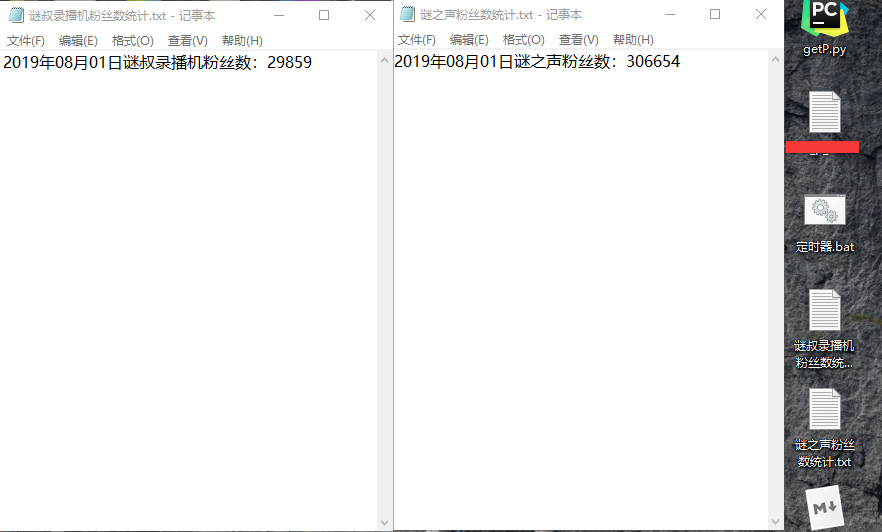
第二,说好的每天统计一遍呢,我要一天点一次吗?
1.当然不!写一个bat文件就好啦!
每当0点的时候就会自动执行一遍python文件哦我给它起名叫'定时器.bat',不用忘记一直挂着它,嘻嘻
if 0 equ %time:~0,2% (
python getP.py
)
timeout 3600
总结
很简单哦,大家都可以去试试,统计一下自己喜欢的up主的粉丝量变化,相信一定是一个增函数吧嘻嘻~
当然也可以不局限于每天监测一次,不过更具体地就需要大家自己去试啦,我只做了一天统计一次的~
【python爬虫】每天统计一遍up主粉丝数!的更多相关文章
- Java + golang 爬取B站up主粉丝数
自从学习了爬虫,就想在B站爬取点什么数据,最近看到一些个up主涨粉很快,于是对up主的粉丝数量产生了好奇,所以就有了标题~ 首先,我天真的以为通过up主个人空间的地址就能爬到 https://spac ...
- 爬取腾讯网的热点新闻文章 并进行词频统计(Python爬虫+词频统计)
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:一棵程序树 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
- Python爬虫(三)——对豆瓣图书各模块评论数与评分图形化分析
文化 经管 ....略 结论: 一个模块的评分与评论数相关,评分为 [8.8——9.2] 之间的书籍评论数往往是模块中最多的
- 【Python】【爬虫】如何学习Python爬虫?
如何学习Python爬虫[入门篇]? 路人甲 1 年前 想写这么一篇文章,但是知乎社区爬虫大神很多,光是整理他们的答案就够我这篇文章的内容了.对于我个人来说我更喜欢那种非常实用的教程,这种教程对于想直 ...
- Python爬虫(四)——开封市58同城数据模型训练与检测
前文参考: Python爬虫(一)——开封市58同城租房信息 Python爬虫(二)——对开封市58同城出租房数据进行分析 Python爬虫(三)——对豆瓣图书各模块评论数与评分图形化分析 数据的构建 ...
- Python爬虫(四)——豆瓣数据模型训练与检测
前文参考: Python爬虫(一)——豆瓣下图书信息 Python爬虫(二)——豆瓣图书决策树构建 Python爬虫(三)——对豆瓣图书各模块评论数与评分图形化分析 数据的构建 在这张表中我们可以发现 ...
- python爬虫--看看虎牙女主播中谁颜值最高
目录 爬虫 百度人脸识别接口 效果演示 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做案例的人,却不知道如何去学习更加高深的知 ...
- [python爬虫] Selenium定向爬取海量精美图片及搜索引擎杂谈
我自认为这是自己写过博客中一篇比较优秀的文章,同时也是在深夜凌晨2点满怀着激情和愉悦之心完成的.首先通过这篇文章,你能学到以下几点: 1.可以了解Python简单爬取图片的一些思路和方法 ...
- Python爬虫 获得淘宝商品评论
自从写了第一个sina爬虫,便一发不可收拾.进入淘宝评论爬虫正题: 在做这个的时候,也没有深思到底爬取商品评论有什么用,后来,爬下来了数据.觉得这些数据可以用于帮助分析商品的评论,从而为用户选择商品提 ...
随机推荐
- Rust中的枚举及模式匹配
这个enum的用法,比c要强,和GO类似. enum Coin { Penny, Nickel, Dime, Quarter, } fn value_in_cents(coin: Coin) -> ...
- Java8——jdk——java.time包
public class TestLocalDateTime { //6.ZonedDate.ZonedTime.ZonedDateTime : 带时区的时间或日期 @Test public void ...
- centos7编译安装php 遇到的问题
centos7 编辑安装php遇到的问题: ./configure 配置遇到的No package 'libxml-2.0' found缺失libxml2.0 库,解决方法: yum -y insta ...
- python27期day07:基础数据类型补充、循环删除的坑、二次编码、作业题。
1.求最大位数bit_length: a = 10 #8421 1010print(a.bit_length())结果:42.capitalize首字母变大写: s = "alex" ...
- Kubernetes 集群分析查看内存,CPU
Kubernetes方式 top命令查看所有pod,nodes中内存,CPU使用情况 查看pod root @ master ➜ ~ kubectl top pod -n irm-server NAM ...
- zz“深度高斯模型”可能为深度学习的可解释性提供概率形式的理论指导
[NIPS2017]“深度高斯模型”可能为深度学习的可解释性提供概率形式的理论指导?亚马逊机器学习专家最新报告 专知 [导读]在NIPS 2017上,亚马逊机器学习专家Neil Lawrence在12 ...
- 2019-2020 ICPC Asia Hong Kong Regional Contest
题解: https://files.cnblogs.com/files/clrs97/19HKEditorial-V1.zip Code:(Part) A. Axis of Symmetry #inc ...
- UVA10559 方块消除 Blocks 题解
设g[i][j][k]为消去区间[i,j]中的方块,只留下k个与a[i]颜色相同的方块的最大价值,f[i][j]为将[i,j]中所有方块消去的价值,转移自己yy一下即可. 为什么这样是对的?因为对于一 ...
- Linux性能优化实战学习笔记:第四十讲
一.上节回顾 上一节,我们学习了碰到分布式拒绝服务(DDoS)的缓解方法.简单回顾一下,DDoS利用大量的伪造请求,导致目标服务要耗费大量资源,来处理这些无效请求,进而无法正常响应正常用户的请求. 由 ...
- 3,[VS] 编程时的有必要掌握的小技巧_______________________________请从下面第 1 篇看起
本文导览: 善用“并排显示窗口”功能 做作业/测试时使用 多项目 多个源文件 多个子函数 使用Visual Studio team代码同步工具,及时把项目文件保存到云端 关闭括号分号自动联想 技巧是提 ...